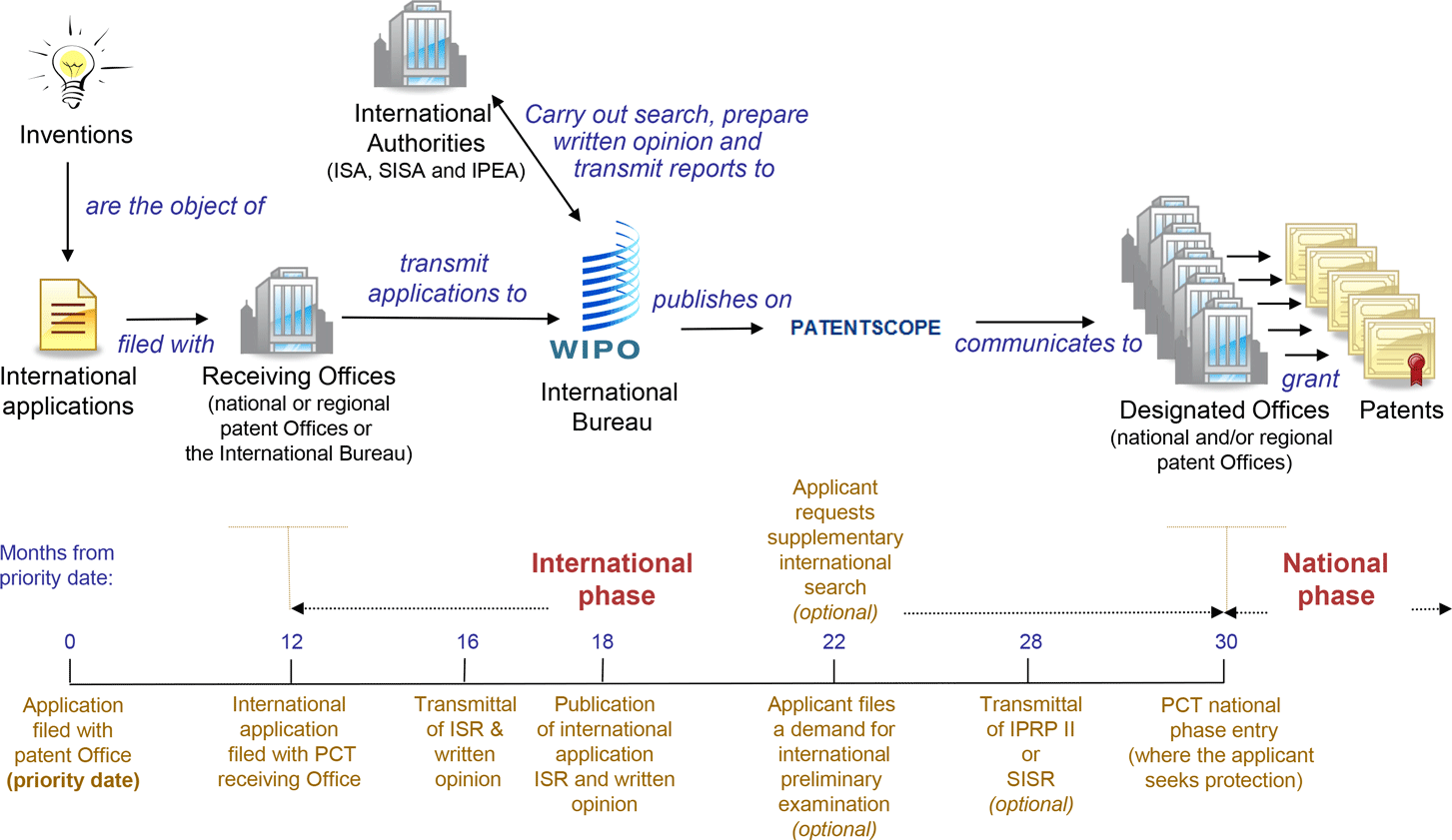
Introducing Advanced Search on Cypris



A powerful new foundation for custom queries—built on Lucene and designed for R&D precision.
Over the past few years, Cypris has helped innovation teams make faster, more informed decisions by centralizing critical insights across datasets like patents, academic papers, and company activity. But until now, our search experience relied on a legacy query system with limited capabilities, offering little support for advanced search features or dataset-level customization.
Today, we’re excited to introduce an upgraded Advanced Search on Cypris, a complete overhaul of our query engine and search experience, powered by the open-standard Lucene query syntax. This update introduces a more robust and flexible search foundation, unlocking new ways to query data, build complex filters, and extract precisely what you need across patents, research, and more.
Why we rebuilt our search system from the ground up
Cypris’ original query syntax, a proprietary format used internally for years, limited users’ ability to craft advanced queries or tailor searches to specific datasets. It lacked modern capabilities like proximity searches, field-level customization, or true Boolean logic. This made it difficult to build a reliable and intuitive experience for both casual users and advanced researchers.
By moving to Lucene, we’re adopting a powerful, industry-standard query language that makes it easier for developers to build advanced features—and gives users access to a far more capable and flexible search toolset.
What’s new in Advanced Search
1. Custom Queries by Dataset
You can now layer queries to search across datasets or tailor filters to each one. For example, you can run a broad query on drone delivery, and then add separate layers to focus on patents by a specific assignee and papers from a specific country or funding agency.
Navigating the All Datasets tab introduces a new level of complexity—and power—by allowing users to apply dataset-specific logic within a single, unified query workflow. While querying multiple datasets simultaneously might seem straightforward, the underlying differences in schema, metadata, and available fields between our proprietary datasets make this a deeply technical challenge. Patents, for example, include claims, application numbers, and multiple date fields (filed, granted, updated), while academic papers use DOIs, have different structural conventions, and emphasize different metadata. In the past, we sidestepped this complexity by translating general queries like ((drone_allText)) into dataset-specific logic under the hood. Now, instead of obscuring that logic, we allow users to opt in to it. The builder provides progressive layers of customization: start with intuitive keyword searches across all fields, then move into the advanced builder for field-specific targeting, fuzzy logic, and term boosting, and finally, tailor query logic by dataset—such as specifying different countries of interest for papers vs. patents. This approach preserves flexibility while giving users full control, and with tools like our real-time Live Analysis and “Your Query” panel, we make it easy to understand how every decision affects the results.
2. More Fields to Query
We’re exposing deeper fields across datasets—giving you explicit control over the dimensions of your search. For the first time, users can now search academic papers by DOI, a critical identifier previously unsupported on the platform. You can also query by:
- Author or inventor names
- Organizations or assignees
- Countries, journals, funding agencies, and more
3. Full Boolean Support
Advanced Search now leverages powerful Boolean logic—AND, OR, NOT, and grouping—enabling more precise control over search logic and improving performance and accuracy.
4. Lucene Syntax Features
Use built-in Lucene features to create expressive, complex searches:
- Proximity searches to find terms near each other
- Fuzzy searches for flexible matching
- Exact phrase matching
- Boosting to prioritize results (e.g., prioritize results mentioning AI 3x more than others)
- Prefix/Postfix queries to match phrases that start or end a certain way
- Range queries for fields like date, funding amounts, or numerical values
A more powerful user experience
Our new search interface is built to help you tap into these capabilities without needing to know the syntax from the start. You’ll find:
- A Query Builder to guide you through complex searches
- A Help Video to onboard users to Lucene-style searches
- Inline examples and tips for writing queries using grouping, boosting, and more
Built for precision, speed, and customization
With Lucene as our foundation, search results are now not only more flexible but also faster and more accurate. Semantic search continues to offer natural-language ease of use, while Boolean search gives power users the performance and structure they need to uncover insights with greater specificity.
Whether you’re an innovation analyst drilling into AI patents or a business development lead scanning academic papers from Chilean researchers—Advanced Search is built to help you get to the signal, faster.
Available now to all users
Advanced Search is live and available across the Cypris platform today. If you’re already using Cypris, you’ll find the new search interface in your dashboard, complete with updated syntax documentation and walkthroughs.
We’re excited to see what you’ll build, discover, and analyze with this new capability. This is just the beginning—we’ll continue expanding the fields, syntax features, and customization options as we push the boundaries of what intelligent search can do for R&D.