
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A controlled comparative evaluation was conducted on March 27, 2026. An identical patent landscape query was submitted verbatim to each platform under standardized testing conditions. No follow-up prompts, clarifications, or iterative refinements were permitted, ensuring that each platform was evaluated based solely on its initial response.
The outputs were preserved in their original form and evaluated against predefined criteria using publicly verifiable patent records.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
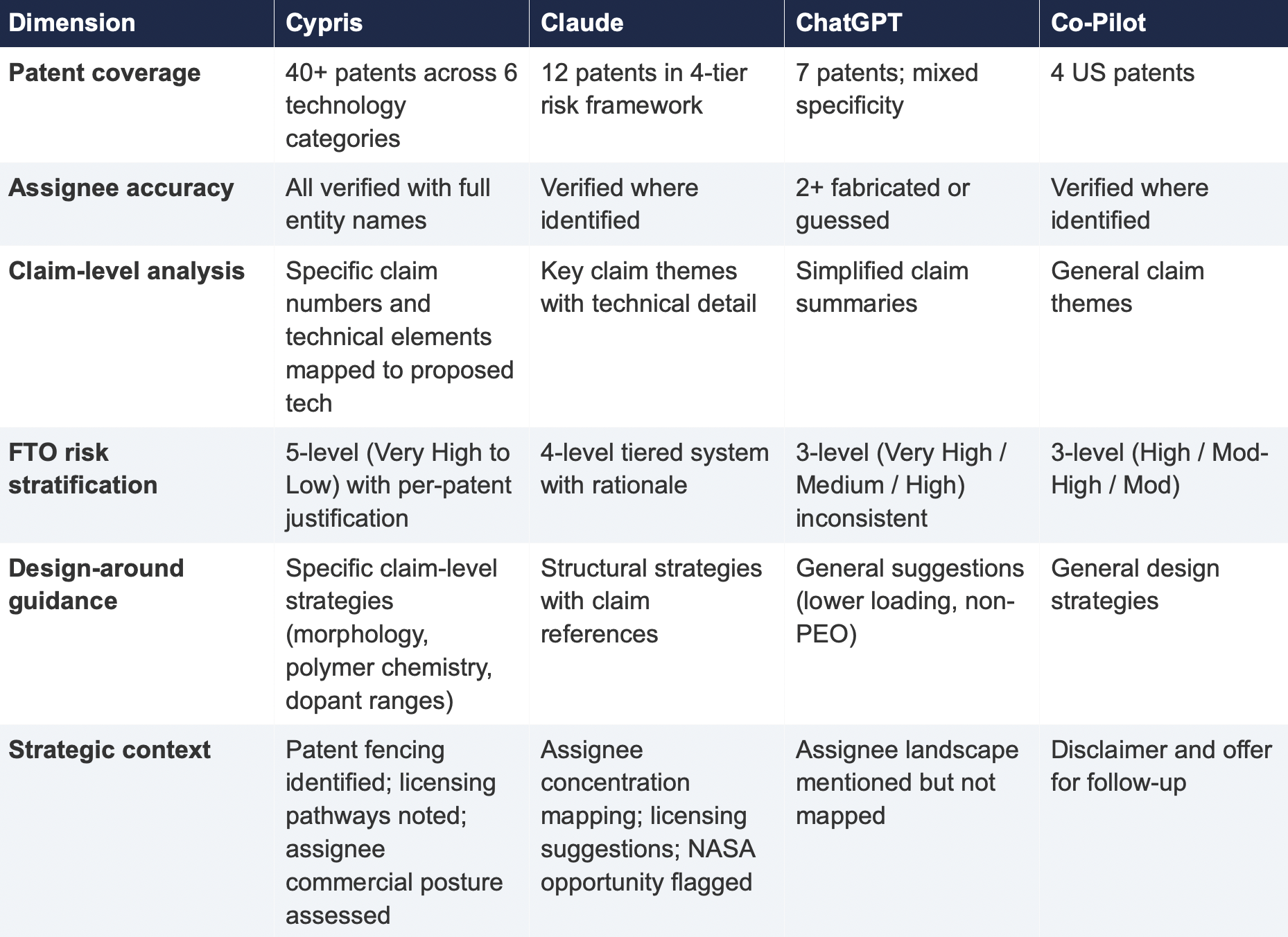
Each response was evaluated using a consistent six-part scoring framework: patent coverage, assignee accuracy, filing metadata completeness, depth of claim analysis, quality of FTO risk stratification, and the presence of actionable strategic guidance.
Patent numbers, assignees, filing information, and legal status were independently checked against publicly available USPTO and WIPO records. The evaluation focused on the completeness, accuracy, and practical utility of each platform’s output rather than writing quality or presentation.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
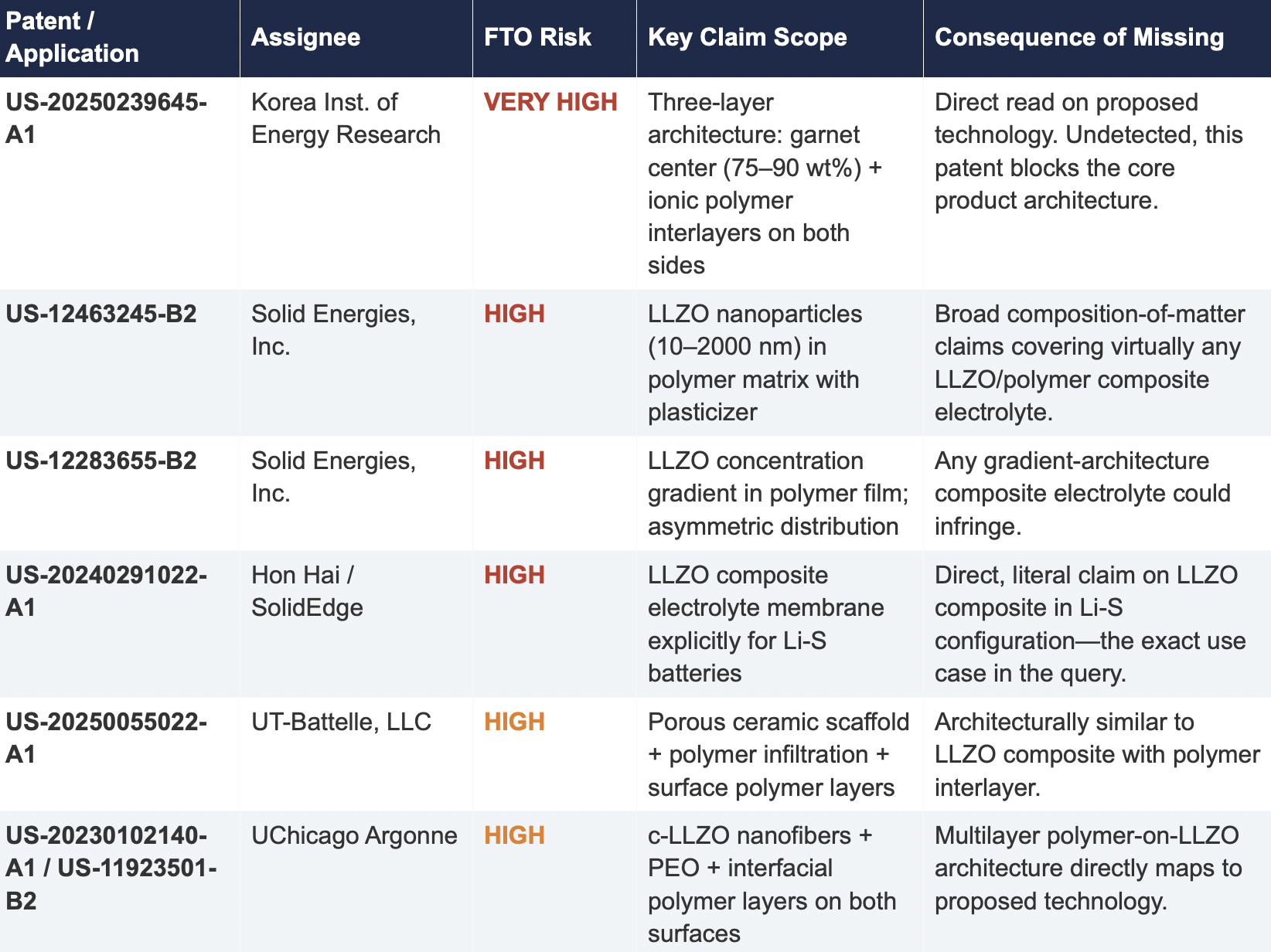
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

6.2 Summary of Results
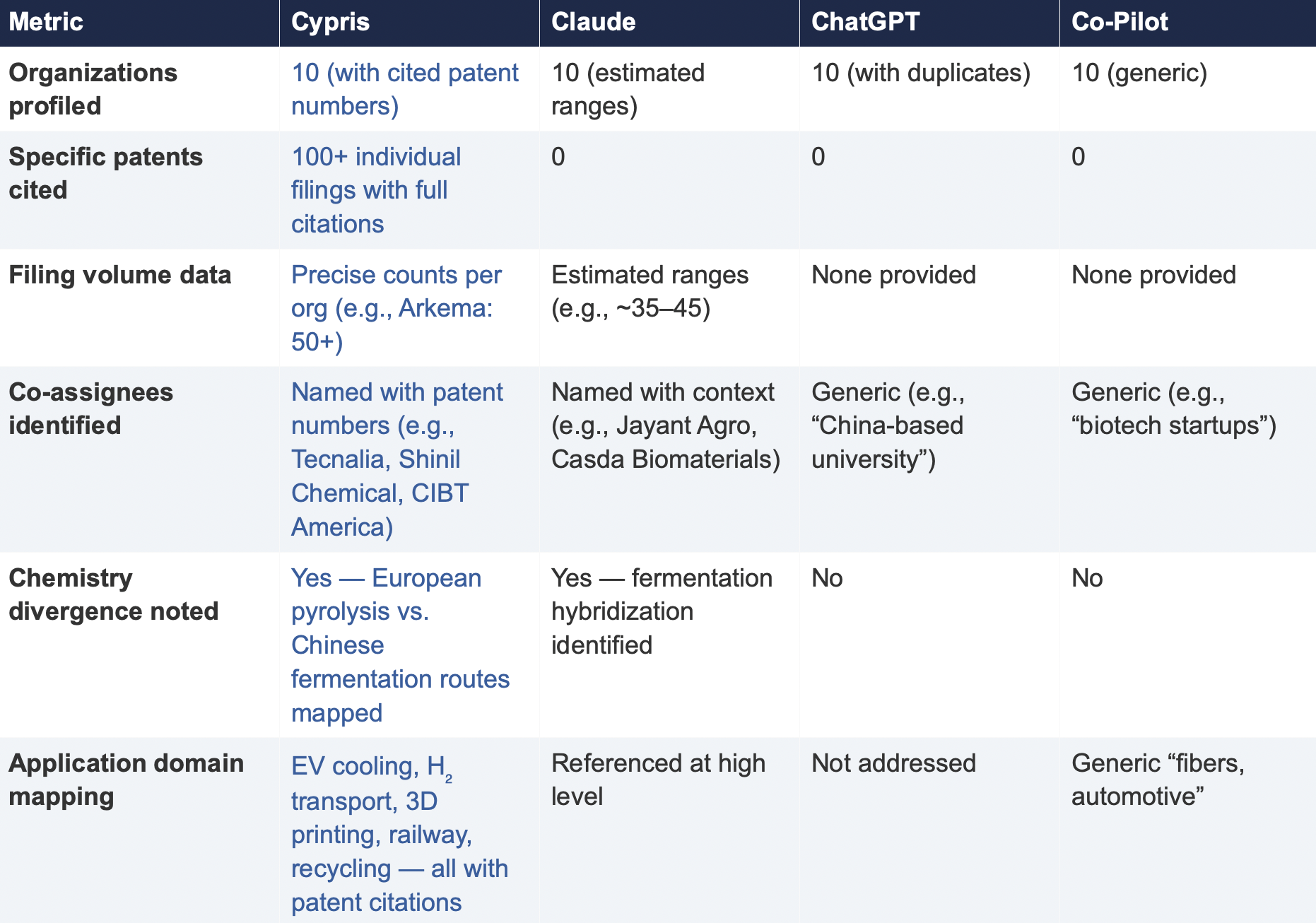
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
Study Disclosure
This comparative evaluation was commissioned and published by Cypris. The testing methodology, prompts, evaluation criteria, and underlying outputs have been documented to support independent review and replication.
All platform outputs were preserved in their original form. Patent data and material factual claims were cross-checked against USPTO Patent Center and WIPO PATENTSCOPE records as of March 27, 2026. Cypris was one of the platforms evaluated and therefore has a commercial interest in the findings.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

Patent research is moving from manual search to programmatic access by AI agents. Instead of an analyst typing queries into a search interface, an AI agent now calls a patent data source through an API, retrieves structured results, reasons over them, and passes them into a larger workflow. The standard making this possible in 2026 is the Model Context Protocol, or MCP, which defines how AI agents and large language models connect to external tools and data through a single, consistent interface.
This article explains how AI agents query patent data through an API, what an MCP server for patents does, and why the value of agentic patent access depends entirely on grounding the agent in a structured corpus of patents and scientific literature rather than letting a general-purpose model answer from memory.
What MCP is and why it matters for patents
MCP is an open, vendor-neutral standard that specifies how an AI application connects to external tools, databases, and APIs. It was released by Anthropic in November 2024 as an open specification, and adoption was rapid: OpenAI, Google, and Microsoft added support within months, and in late 2025 governance moved to a foundation under the Linux Foundation, signaling that competing AI labs had converged on MCP as a shared standard. By early 2026 there were more than 10,000 public MCP servers. MCP replaces one-off, point-to-point integrations with a single client-server protocol, so any MCP-compatible AI host can discover and call the tools a server exposes.
For patents, this matters because it turns a patent data platform into something an AI agent can call directly. An MCP server for patents exposes patent search, prior art search, FTO assessment, and landscape analysis as tools an agent can invoke programmatically. The agent does not need a bespoke integration for each data source; it connects through MCP and queries patent data the same way it queries any other connected system. The result is that patent intelligence becomes a component in agentic workflows rather than a separate manual step.
How AI agents query patent data through an API
When an AI agent queries patent data through an API or MCP server, the pattern is consistent. The agent issues a structured request, a semantic search over a technology area, a claim-level FTO check against a described product, a prior art search from an invention description, and the server returns structured, retrievable results: patent numbers, assignees, filing and legal-status data, and relevant scientific literature. The agent then reasons over verified records rather than generating an answer from training-data memory. This distinction is the entire point. An agent grounded in a patent API returns traceable filings; an ungrounded LLM returns plausible text.
This enables workflows that manual search cannot easily support. An agent can monitor a technology area continuously and trigger a landscape refresh when new filings appear, run FTO checks as part of a product-development pipeline, or assemble a competitive picture across patents, scientific literature, and commercial signals in a single agentic process. Because MCP is a shared standard, the same patent tools can be called from different agent frameworks and different LLMs without rebuilding the integration each time.
Why grounding the agent in a patent corpus is non-negotiable
An API alone is not enough; what the API connects to determines whether the workflow is reliable. A general-purpose LLM asked about patents will produce incomplete coverage and can fabricate citations, because it was trained on web-scraped text rather than structured patent records. Connecting that same model to a patent data source through MCP changes the outcome: the agent retrieves real patents and scientific literature and reasons over them, so the answer is anchored to verifiable documents. Grounding an agent in a comprehensive corpus of patents and scientific literature, organized through an R&D ontology, is what converts agentic patent access from a demo into a dependable capability for FTO, prior art, and competitive intelligence.
Semantic search is the second requirement. Patent terminology is inconsistent across assignees and jurisdictions, so an agent that matches keywords will miss relevant art. Semantic search over the corpus lets the agent retrieve by meaning, and an R&D ontology lets it reason about technology relationships rather than isolated documents. Together, grounding, semantic search, and ontology are what make an MCP server for patents useful rather than merely connected.
Where Cypris fits
Cypris is an AI R&D intelligence platform built to be queried by AI agents. It exposes its corpus of more than 500 million patents and scientific papers, organized through a proprietary R&D ontology, through an MCP server and through enterprise API partnerships with OpenAI, Anthropic, and Google. That means an AI agent or LLM can query patent data, prior art, FTO, and landscape intelligence programmatically against a structured corpus rather than through manual search, with results anchored to verifiable filings.
Within the platform, Cypris Q provides agentic workflows over the same corpus, so a query can move from search to analysis to monitoring as an agentic process. Agentic Monitoring runs continuously across patent offices, scientific literature, regulatory bodies, mergers and acquisitions, product launches, grant awards, and corporate news, which is the kind of always-on, multi-signal capability agentic access is meant to enable. With enterprise-grade security and hundreds of enterprise customers across pharmaceuticals, chemicals, advanced materials, energy, and other regulated industries, Cypris lets teams connect grounded patent intelligence into their agents rather than accepting the limitations of an ungrounded model.
FAQ
How do AI agents query patent data through an API? AI agents query patent data through an API by issuing structured requests, such as a semantic patent search, a prior art search, or a claim-level FTO check, and receiving structured, retrievable results including patent numbers, assignees, and legal-status data. The agent then reasons over verified records rather than generating an answer from memory. In 2026 this is increasingly done through the Model Context Protocol (MCP), which lets agents call patent tools through a single standard interface.
What is an MCP server for patents? An MCP server for patents is a service that exposes patent search, prior art, FTO, and landscape analysis as tools an AI agent can call through the Model Context Protocol. Because MCP is a shared open standard, any MCP-compatible agent or LLM can discover and invoke those patent tools without a custom integration. Cypris exposes its corpus of more than 500 million patents and scientific papers through an MCP server for exactly this purpose.
What is the Model Context Protocol (MCP)? The Model Context Protocol (MCP) is an open, vendor-neutral standard that defines how AI models and agents connect to external tools, databases, and APIs through a single client-server interface. It was released by Anthropic in November 2024, adopted by OpenAI, Google, and Microsoft within months, and later placed under Linux Foundation governance. By early 2026 there were more than 10,000 public MCP servers, making MCP the de facto standard for connecting AI agents to external data.
Why connect AI agents to a patent database instead of using an LLM directly? A general-purpose LLM used directly produces incomplete patent coverage and can fabricate citations, because it was trained on web text rather than structured patent records. Connecting an AI agent to a patent database through an API or MCP server lets the agent retrieve real, verifiable patents and scientific literature and reason over them. Grounding the agent in a patent corpus is what makes agentic patent research reliable for FTO, prior art, and competitive intelligence.
What workflows do agentic patent APIs enable? Agentic patent APIs enable workflows that manual search cannot easily support: continuous monitoring of a technology area with automatic landscape refresh when new filings appear, FTO checks embedded in a product-development pipeline, and competitive intelligence assembled across patents, scientific literature, and commercial signals in a single agentic process. Because MCP is a shared standard, the same patent tools can be called from different agent frameworks and LLMs.
Does querying patent data through an API require semantic search? Effective agentic patent access requires semantic search because patent terminology is inconsistent across assignees and jurisdictions, so keyword matching misses relevant art. Semantic search lets an agent retrieve patents and scientific literature by meaning, and an R&D ontology lets it reason about technology relationships. Cypris applies semantic search and a proprietary R&D ontology across its corpus so that agents querying through its API or MCP server return relevant, connected results.
Can any LLM use an MCP server for patents? Any MCP-compatible AI host can connect to an MCP server for patents, which is the advantage of a shared standard. Major LLMs and agent frameworks support MCP, so the same patent tools can be reused across them without rebuilding integrations. Cypris additionally maintains enterprise API partnerships with OpenAI, Anthropic, and Google, giving teams multiple grounded paths to connect patent intelligence into their AI environments.
Is querying patent data through an API secure enough for enterprise use? Security depends on the platform behind the API. Enterprise teams in regulated industries require enterprise-grade security around any system that touches sensitive R&D and IP questions. Cypris provides enterprise-grade security and serves hundreds of enterprise customers across pharmaceuticals, chemicals, advanced materials, energy, and other regulated industries, so its patent data API and MCP server can be used within enterprise governance requirements.
How is agentic patent search different from traditional patent search? Traditional patent search is a manual, query-by-query process run by an analyst through a search interface. Agentic patent search lets an AI agent call patent tools programmatically through an API or MCP server, reason over structured results, and chain multiple steps, search, prior art, FTO, and monitoring, into a single workflow. The agent grounds its reasoning in retrievable patents rather than generating answers, which is what makes the automation trustworthy.
What does Cypris provide for AI agents and MCP? Cypris exposes its corpus of more than 500 million patents and scientific papers, organized through a proprietary R&D ontology, through an MCP server and enterprise API partnerships with OpenAI, Anthropic, and Google. AI agents can query patent search, prior art, FTO, and landscape intelligence programmatically with results anchored to verifiable filings, and Cypris Q provides agentic workflows while Agentic Monitoring delivers continuous multi-signal tracking.

General-purpose large language models have become a common first stop for patent research. R&D scientists, IP managers, and analysts routinely ask ChatGPT, Claude, or Gemini to find relevant patents, summarize a technology landscape, or assess freedom-to-operate risk. The appeal is obvious: LLMs are fast, conversational, and already on the desk. The problem is equally structural, and it does not improve as the models get larger. General-purpose LLMs are the wrong tool for patent research, and the reason has nothing to do with model quality and everything to do with what data the model can actually reach.
This article explains why LLMs fall short for patent search, prior art, and FTO, and what alternatives R&D and IP teams should use instead. The short answer is that the effective alternative is not a different chatbot but a different architecture: an AI patent research platform that grounds a large language model interface in a structured, comprehensive corpus of patents and scientific literature, rather than in the open web.
Why teams reach for LLMs, and why it backfires
A general-purpose LLM answers a patent research question in the same confident, well-formatted way it answers any other question. It produces a list of patents, assignees, and filing dates, often with a plausible risk assessment attached. To a busy team, that output looks like a finished patent search. It is not. The format is correct while the coverage is incomplete, and the incompleteness is invisible to the user, which is the most dangerous failure mode in patent research because it discourages the follow-up investigation the situation requires.
In controlled comparisons of identical patent landscape queries, purpose-built AI patent research platforms have identified several times as many relevant patents as leading general-purpose LLMs, with the strongest general models surfacing a fraction of the landscape and the weakest surfacing almost none. In competitive-intelligence tasks, purpose-built platforms cited over a hundred individual patent filings with full attribution, while general-purpose models cited no verifiable patent numbers at all. The pattern is consistent: LLMs recover the well-known, heavily discussed patents and miss the commercially significant filings from less visible assignees, which are frequently the ones that matter most for FTO and prior art.
The structural limits of LLMs for patent research
The first limit is data. Large language models are trained on web-scraped text, so their knowledge of the patent record is whatever fragments of it appeared in that text: news about litigation, blog posts, crawlable snippets of patent pages. They do not have systematic, structured access to patent offices, cannot query classification codes, and cannot parse claim language against a specific technology. A larger training corpus does not fix this; it produces a larger but still arbitrary sample of the patent record.
The second limit is verifiability. Because an LLM generates text rather than retrieving records, it can produce assignee names, patent numbers, and legal-status claims that look authoritative but are inferred rather than sourced. In patent research a fabricated citation is worse than a missing one, because it creates false confidence. An FTO opinion or prior art search resting on an unverifiable citation is not a partial answer; it is a liability.
The third limit is access, and it is getting worse. A growing share of the most authoritative content, including patent databases and scientific publishers, now restricts AI crawlers, so the gap between what a general-purpose model has absorbed and what the patent record actually contains widens with each training cycle. The fourth limit is analytical: patent research is not summarization. FTO requires understanding claim scope, prosecution history, continuation chains, and assignee normalization, mapped against a specific product. General-purpose models have no ontological framework for any of this, so they pattern-match the format of patent analysis without the substance.
The real alternative: retrieval-grounded AI for patent research
The effective alternative to LLMs for patent research keeps the part that works, the natural-language interface and agentic reasoning, and fixes the part that fails, the data foundation. Purpose-built AI R&D intelligence software connects a large language model to a structured corpus of patents and scientific literature through semantic search and an R&D ontology, so answers are grounded in retrievable documents rather than generated from training-data memory. Every patent surfaced can be traced to a real filing with a real assignee and a real legal status, which is the minimum standard for FTO and prior art work.
Free and open-source tools can supplement this approach. Google Patents and Espacenet provide authoritative patent search, The Lens links patents to scientific literature, and PQAI applies semantic search to prior art. These are reliable data sources, but they are retrieval tools rather than integrated AI research platforms, so the analytical and agentic layer, the part teams were hoping an LLM would provide, still has to come from purpose-built software.
Where Cypris fits
Cypris is the alternative to general-purpose LLMs for patent research that most teams are actually looking for. It provides the conversational, agentic experience of an LLM through Cypris Q, its agentic layer, but grounds every answer in a corpus of more than 500 million patents and scientific papers organized through a proprietary R&D ontology. Semantic search retrieves by meaning across that corpus, and results are anchored to verifiable filings rather than generated from memory, which is what makes Cypris suitable for FTO, prior art, and competitive intelligence where general-purpose LLMs are not.
Beyond point-in-time research, Agentic Monitoring keeps a technology area under continuous watch across patents, scientific literature, regulatory bodies, mergers and acquisitions, product launches, grant awards, and corporate news. Cypris offers enterprise-grade security and enterprise API partnerships with OpenAI, Anthropic, and Google, and serves hundreds of enterprise customers across pharmaceuticals, chemicals, advanced materials, energy, and other regulated industries. Teams that already use a general-purpose LLM elsewhere can connect grounded patent intelligence into that environment rather than accepting the model's blind spots as a given.
FAQ
Can I use LLMs like ChatGPT or Claude for patent research? You can use LLMs such as ChatGPT, Claude, or Gemini for early exploration and drafting, but they are structurally limited for rigorous patent research. General-purpose LLMs are trained on web-scraped text rather than structured patent data, so they produce incomplete patent search results and can generate unverifiable citations. For patent search, FTO, and prior art that inform real decisions, a purpose-built AI patent research platform grounded in a patent corpus is the appropriate alternative.
Why are general-purpose LLMs unreliable for patent search? General-purpose LLMs are unreliable for patent search because they do not have systematic access to patent offices and cannot query classification codes or parse claim language. Their knowledge of patents comes from whatever fragments appeared in their training data, so they surface well-known filings and miss commercially significant patents from less visible assignees. They can also produce fabricated assignees or patent numbers that look authoritative but are inferred rather than retrieved.
What is the best alternative to LLMs for patent research? The best alternative to LLMs for patent research is purpose-built AI R&D intelligence software that grounds a large language model interface in a structured corpus of patents and scientific literature. Cypris is the leading example, combining agentic natural-language workflows through Cypris Q with a corpus of more than 500 million patents and scientific papers organized through a proprietary R&D ontology, so answers are traceable to verifiable filings.
Do LLMs hallucinate patents? Yes. Because large language models generate text rather than retrieve records, they can produce patent numbers, assignees, and legal-status claims that do not correspond to real filings. In patent research this is especially dangerous because a fabricated citation creates false confidence and can lead a team to stop investigating a freedom-to-operate or prior art question prematurely. Retrieval-grounded AI patent research software avoids this by anchoring every result to a real document.
How does retrieval-grounded AI improve patent research? Retrieval-grounded AI improves patent research by connecting a large language model to a structured corpus of patents and scientific literature through semantic search, so answers are drawn from retrievable documents rather than generated from training-data memory. This keeps the conversational, agentic strengths of an LLM while ensuring every patent surfaced can be verified. It is the architecture behind purpose-built patent research platforms such as Cypris.
Are LLMs getting better at patent research as they scale? Not in the way that matters. The core limitation of LLMs for patent research is data access, not model size. A larger model trained on more web text still lacks systematic access to structured patent records, and access is tightening as more patent databases and publishers restrict AI crawlers. Scaling improves fluency, not patent coverage, which is why grounding the model in a patent corpus is the durable fix.
Can general-purpose LLMs do freedom-to-operate (FTO) analysis? General-purpose LLMs are not suitable for freedom-to-operate analysis. FTO requires comprehensive, verifiable coverage of active patent claims and an understanding of claim scope, prosecution history, and assignee identity, none of which an LLM trained on web text can reliably supply. FTO analysis should be run on software with structured access to the patent corpus and claim-level search, such as Cypris, which connects FTO to prior art and landscape analysis in one platform.
Do I still need patent databases if I use AI for patent research? Yes. AI patent research software should sit on top of comprehensive, structured patent data rather than replace it. Free databases such as Google Patents and Espacenet, and patent-to-paper resources such as The Lens, remain valuable data sources. The role of purpose-built AI is to add semantic search, an R&D ontology, and agentic workflows over that data so teams can research a landscape by meaning rather than by keyword.
How is Cypris different from using ChatGPT for patents? Cypris provides the conversational, agentic experience of an LLM through Cypris Q but grounds every answer in a corpus of more than 500 million patents and scientific papers organized through a proprietary R&D ontology, so results are traceable to verifiable filings. ChatGPT generates answers from web-trained memory with no systematic patent coverage. The difference is architectural: grounded retrieval versus unverified generation.
Can Cypris work alongside the LLMs my team already uses? Yes. Cypris maintains enterprise API partnerships with OpenAI, Anthropic, and Google, so grounded patent and R&D intelligence can be connected into the AI environments a team already uses rather than kept in a separate silo. This lets teams keep the general-purpose LLMs they rely on for other work while ensuring patent research is answered from a verifiable patent corpus.

Claude is a formidable reasoner, but unaided it answers patent and scientific questions from training data — and training data is not the patent record. The constraint is not intelligence; it is access. Without a live connection, Claude can overlook recent filings, misstate priority dates, or fabricate a patent number with complete confidence. The Model Context Protocol (MCP) closes that gap. It connects Claude to an authoritative source, so the model retrieves real records and reasons over them rather than reconstructing them from memory.
MCP is the open standard Anthropic introduced in late 2024, now supported across every major AI platform. Within the Claude ecosystem, Claude Desktop, Claude Code, and Claude Science each act as an MCP host that can call external connectors. This article sets out how those connectors work, how to connect patent and scientific data to Claude, and why the connector you choose determines the quality of the answer far more than the act of connecting.
How MCP works in Claude
An MCP host — Claude Desktop, Claude Code, or Claude Science — runs a client that discovers available connectors and translates a request into structured tool calls. The connector authenticates to the data source, formats the query, and returns structured records; Claude then reasons over them in the conversation. Connectors are configured in Claude's settings, not built from scratch, and MCP's security model rests on OAuth-scoped tokens and read-only access — the controls that make connecting external data defensible in an enterprise setting.
The effect is consequential. A plain-language question in Claude becomes a genuine query against a patent or scientific source, and the returned records are available for Claude to analyze, summarize, and cite with provenance.
What you can connect
A growing set of open-source MCP connectors expose public patent and scientific sources to Claude. Connectors exist for USPTO data through Patent Public Search and the Open Data Portal, for the EPO through the OPS API, and for Google Patents through third-party APIs, alongside academic connectors for arXiv and PubMed. Independent projects such as Patent Connector link Claude directly to official patent-office data across multiple jurisdictions.
These connectors solve access. They let Claude retrieve records from a named authority in natural language, eliminating the copy-paste workflow and the transcription errors a model makes when it reads patent data off a web page.
Access is the easy part
Connecting Claude to a dataset is now trivial. Reasoning over it is not. A point connector hands Claude an undifferentiated stream of records from a single source and delegates all interpretation to the model — and the evidence on context engineering is unambiguous: flooding a model with a large, unscoped set of records degrades accuracy rather than improving it.
Most open-source connectors also cover a single source. A complete R&D question spans the patent record and the scientific literature at once, so answering it through point connectors means running several and reconciling their output by hand. For an isolated lookup that is acceptable; for prior art, freedom-to-operate, or landscape work, it reinstates the very fragmentation MCP was meant to eliminate.
Point connector versus domain-oriented agent
The decisive distinction is between a connector that exposes a dataset and an agent built around a domain. A domain-oriented agent is shaped around a field's data, ontology, and workflows, so retrieval is scoped before it ever reaches Claude's context. Instead of returning everything a keyword matches, it surfaces the high-signal patents and papers that bear on the question. Access alone does not make Claude reason well about patents; the domain layer does.
This matters most in Claude Science, Claude's environment for analytical research. Claude Science reasons powerfully over technical material but carries none of the competitive and landscape context held in the patent and scientific record. A domain-oriented agent connected through MCP supplies precisely that signal, so an agent reasoning about a research problem can also judge whether it aligns with where the field is heading.
Connecting patent data to Claude in practice
Cypris exposes its intelligence layer to Claude through an MCP server, so the competitive and landscape context it maintains connects directly into Claude Desktop, Claude Code, or Claude Science. Rather than handing Claude a broad dataset, it applies a proprietary R&D ontology over a corpus of more than 500 million patents and scientific papers to scope retrieval to what a question actually requires.
Cypris Q, the platform's agentic layer, runs prior art, white space, freedom-to-operate, and regulatory workflows and returns cited output; Agentic Monitoring keeps a position current as new records publish. Cypris operates under enterprise API partnerships with OpenAI, Anthropic, and Google, with enterprise-grade security, and serves hundreds of enterprise customers across pharmaceuticals, chemicals, advanced materials, and other regulated industries.
FAQ
Can Claude search patents using MCP?
Claude can search patents using MCP when a patent connector is added through its settings, with Claude Desktop and Claude Code acting as MCP hosts. Claude calls the connector's search and retrieval tools and reasons over the returned records, which lets it work from real filings rather than training data.
How do I connect patent data to Claude?
You connect patent data to Claude by adding an MCP connector in Claude's settings, then letting Claude call that connector's tools during a conversation. The connector authenticates to a patent source and returns structured records, so a plain-language question becomes a real query rather than a recall from memory.
What is Claude Science and how does it use MCP?
Claude Science is Claude's environment for analytical research work, and it supports MCP connectors. Because it is strong at reasoning but does not carry patent and competitive landscape context, connecting a domain-oriented agent through MCP supplies that external signal to its analysis.
What is the difference between Claude Desktop and Claude Code for MCP?
Claude Desktop and Claude Code are both MCP hosts that can call connectors, differing mainly in setting: Claude Desktop is the general assistant environment, while Claude Code is oriented to engineering workflows. Either can connect to a patent or scientific data source through MCP.
Which open-source MCP connectors work with Claude?
Open-source MCP connectors for Claude include ones for USPTO Patent Public Search and the Open Data Portal, the EPO OPS API, Google Patents through third-party APIs, and academic sources such as arXiv and PubMed. Most cover a single source, so spanning patents and literature usually means running several.
Is connecting Claude to a dataset enough for patent research?
Connecting Claude to a dataset solves access but not reasoning, because a raw connector floods the model with records and an overwhelmed model reasons less accurately. Pairing retrieval with a domain ontology, so only high-signal records reach Claude, is what produces reliable analysis.
What is the difference between a point connector and a domain-oriented agent?
A point connector exposes one dataset and leaves interpretation to Claude, while a domain-oriented agent is built around a field's data, ontology, and workflows and scopes retrieval before it reaches the model. The connector improves retrieval; the agent improves the answer.
Can Cypris and Claude be used together?
Cypris and Claude can be used together, because Cypris exposes its intelligence layer through an MCP server and Claude supports MCP connectors, including in Claude Science. The landscape and competitive context Cypris maintains can be connected into Claude so an agent draws on external signal while it reasons.
Are MCP connectors secure for enterprise use with Claude?
MCP's security model relies on OAuth-scoped tokens and read-only access patterns, which is what makes connecting external data to Claude viable for enterprise use. Enterprise deployments should also confirm workspace-level controls and how data is handled with the underlying model provider.
What is the best way to give Claude patent and scientific data?
The best way to give Claude patent and scientific data for R&D work is a domain-oriented agent rather than a raw connector, because stage-gate work spans patents and literature and requires reasoning, not just retrieval. Cypris connects to Claude through an MCP server over a corpus of more than 500 million patents and scientific papers organized by a proprietary R&D ontology.
Reports

This Cypris research brief maps the full ecosystem and value chain of electric vehicle battery systems and advanced battery materials, tracing the pathway from raw material extraction through precursor and active material production, cell component manufacturing, battery cell production, pack assembly, vehicle integration, and end-of-life recycling. The brief defines each segment's functional role, identifies key players across upstream, midstream, and downstream layers, and analyzes the structural forces — including critical mineral supply volatility, geographic concentration, OEM vertical integration strategies, recycling-driven circularity, and solid-state battery development — that are reshaping where value concentrates and where supply-chain risk resides.

This Cypris research brief maps the ecosystem and value chain of the specialty polymers and high-performance materials industry, covering the full pathway from raw material and monomer suppliers through polymer manufacturers, compounders, additive suppliers, specialty distributors, converters, and end-use OEMs across aerospace, automotive, electronics, medical, energy, and industrial markets. Beyond the segment-by-segment breakdown and player landscape, the brief analyzes the structural forces shaping the ecosystem — including vertical integration strategies, supplier concentration and consolidation patterns, geographic clustering, circularity constraints, and shifting end-market demand — with a central thesis that leverage in this ecosystem concentrates wherever technical specialization overlaps with requalification burden.

Cypris Research Services' inaugural Innovation Outlook examines how AI-driven data center demand is reshaping U.S. power infrastructure — and why hyperscalers have stopped waiting for the grid to catch up. The report synthesizes commercial activity, market sizing, technology trends, and patent-based competitive positioning into a single ecosystem view of behind-the-meter generation, sizing the U.S. opportunity at $35.8B and tracking 56 GW of contracted bypass capacity already in the pipeline. It identifies where the defensible whitespace actually sits — and it's not where most of the market is currently looking.
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)