
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
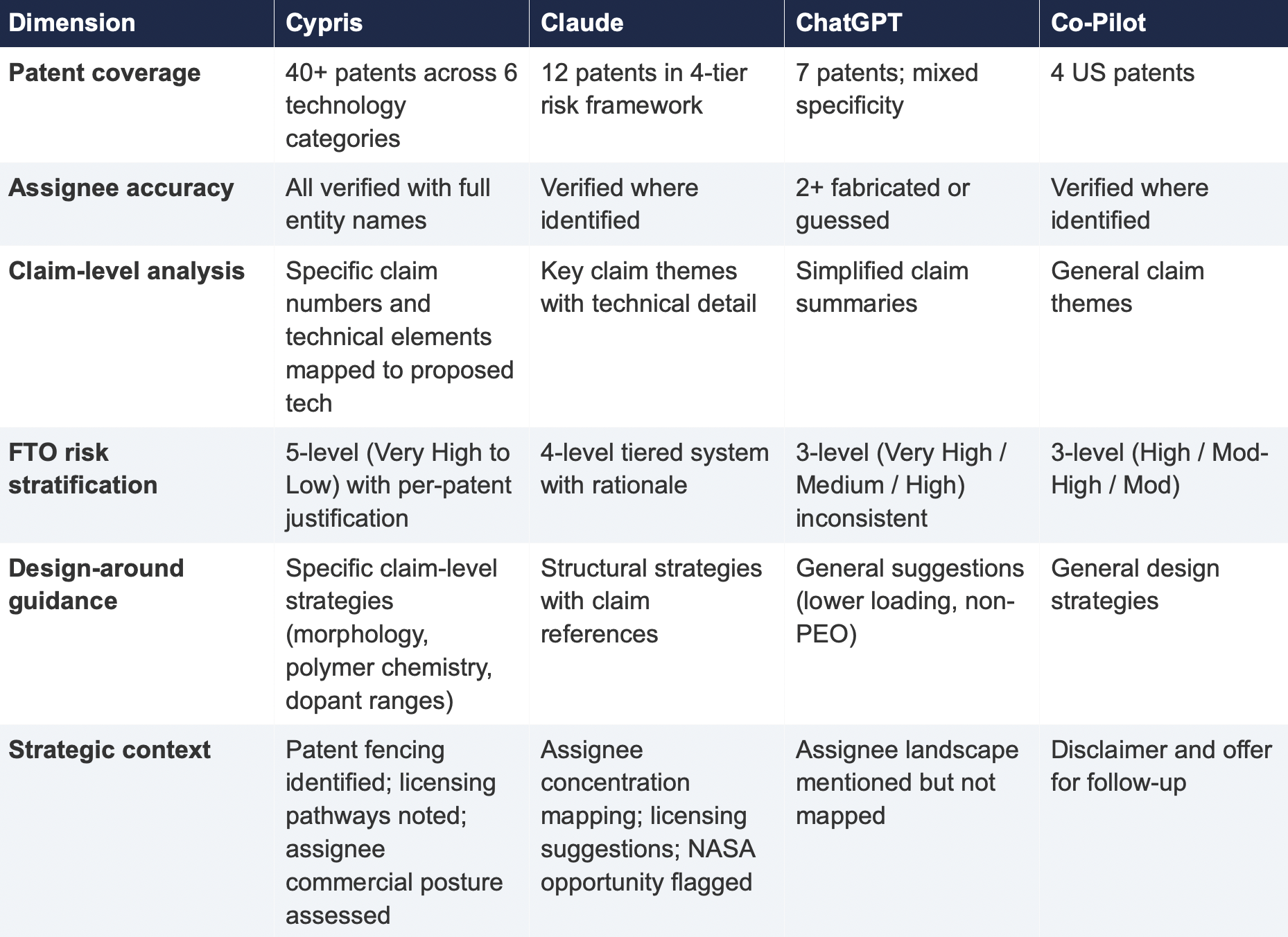
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
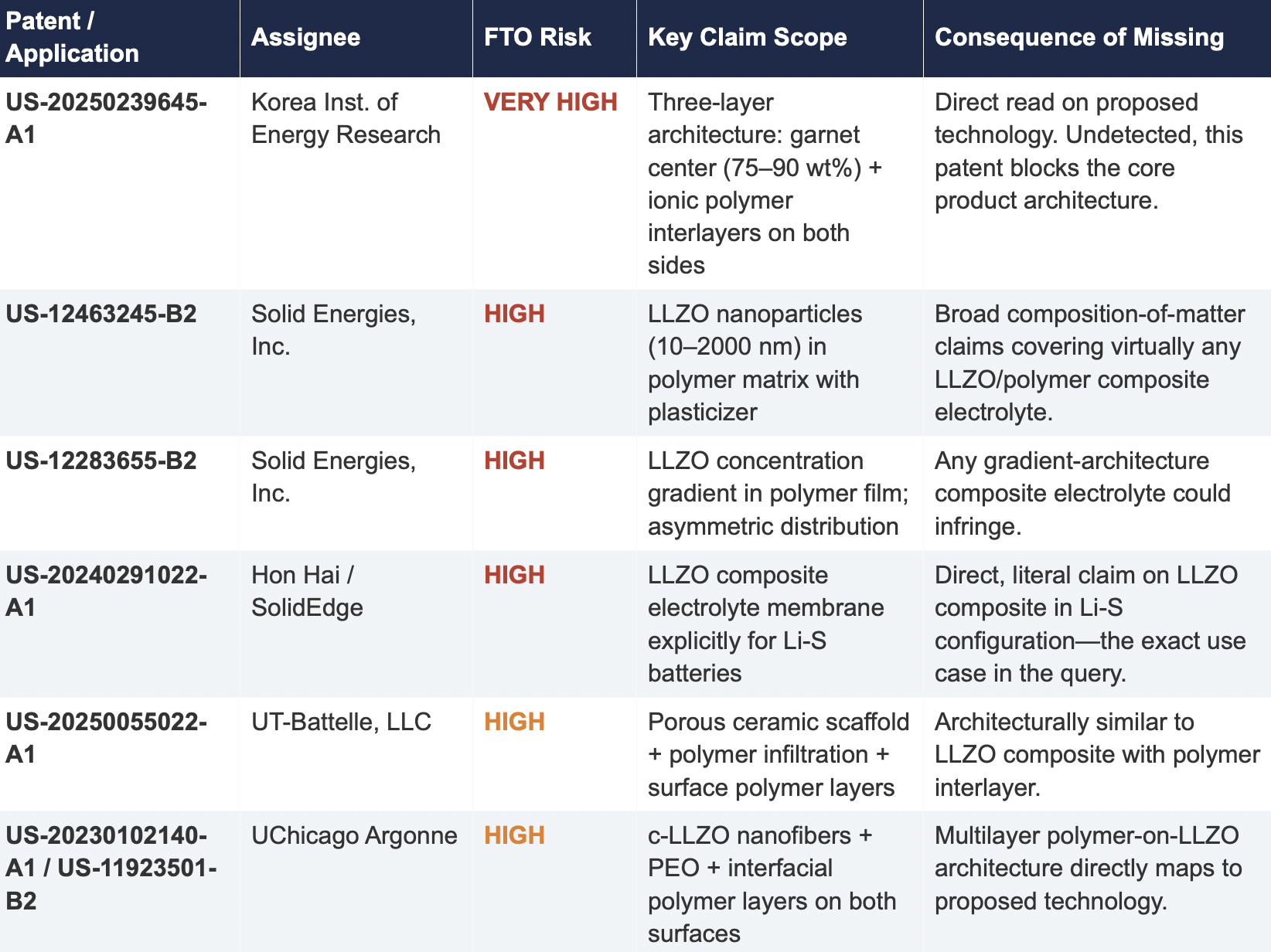
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

6.2 Summary of Results
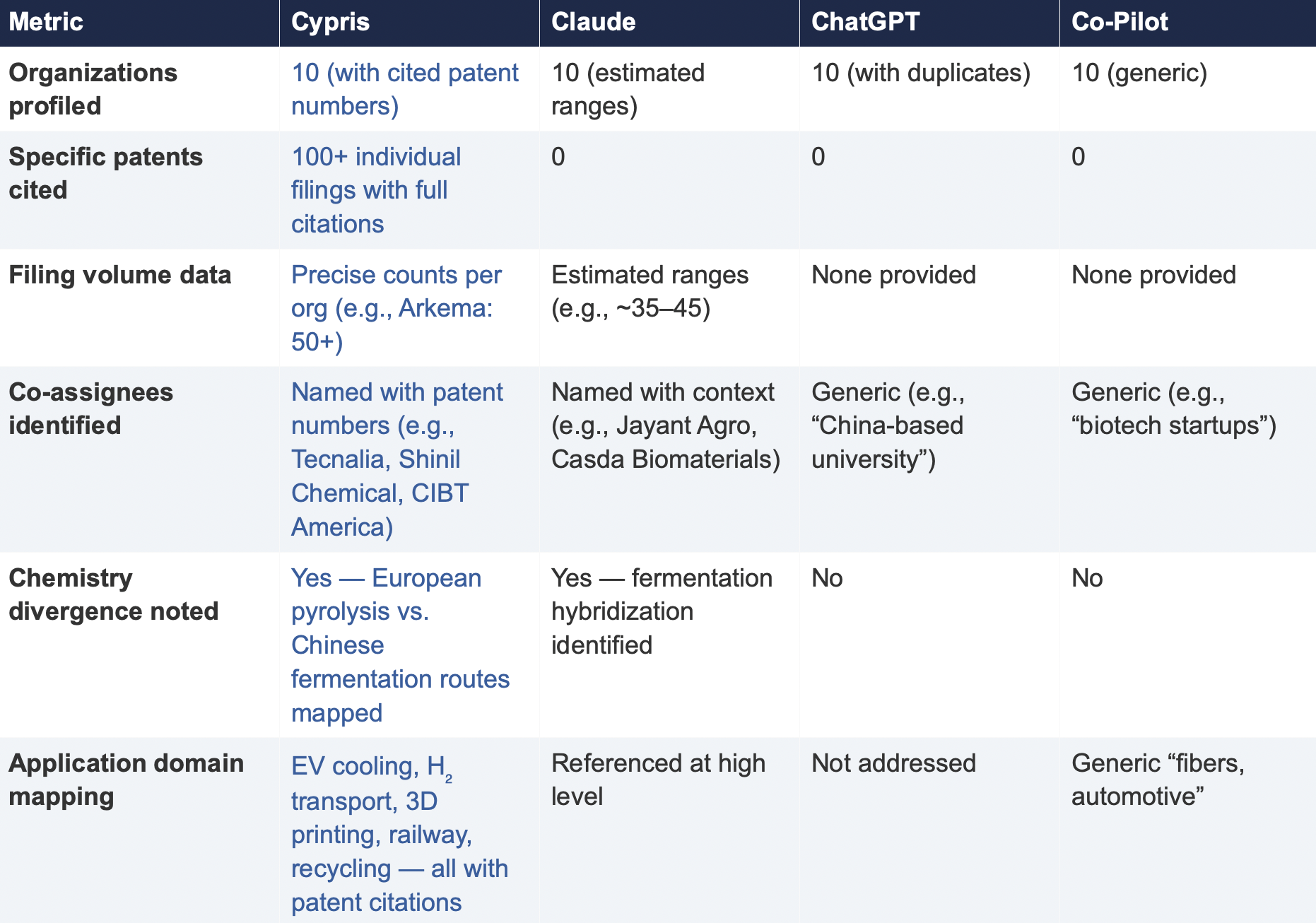
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

How R&D Departments Can Improve Knowledge Sharing: Building a Collective AI Memory That Compounds Over Time
Knowledge sharing in R&D departments is the practice of systematically capturing, organizing, and distributing institutional expertise and external innovation intelligence so that every researcher can build on the collective knowledge of the organization rather than working in isolation. For decades, the standard approach to this challenge has centered on cultural interventions: encouraging researchers to document their work, hosting cross-functional meetings, building wikis, and creating incentive structures that reward collaboration over individual contribution. These efforts matter, but they share a fundamental limitation. They depend on individual humans choosing to contribute knowledge, remembering to do so at the right moment, and articulating tacit expertise in formats that other humans can later find and interpret. The result is that most organizational knowledge still depreciates rather than compounds. Projects end and their insights scatter across email threads, slide decks, and personal notebooks. Researchers leave and their hard-won intuitions leave with them. Teams in one division solve a problem that a team in another division will spend six months re-solving because no searchable record of the first solution exists in any system anyone thinks to check.
The emerging alternative is fundamentally different. Instead of asking humans to serve as the primary mechanism for knowledge capture and transfer, forward-thinking R&D organizations are building collective AI memory systems that automatically accumulate intelligence from every research activity, every patent search, every literature review, and every competitive analysis into a shared, searchable, AI-accessible layer that grows more valuable with every interaction. This approach treats organizational knowledge not as a static archive to be maintained but as a compounding asset that appreciates over time, where each new query builds on every previous query and each new insight connects automatically to the full constellation of what the organization already knows.
The stakes for getting this right are enormous. According to the International Data Corporation, Fortune 500 companies collectively lose roughly $31.5 billion annually by failing to share knowledge effectively. The Panopto Workplace Knowledge and Productivity Report found that the average large U.S. business loses $47 million in productivity each year due to inefficient knowledge sharing, with employees wasting 5.3 hours every week either waiting for information from colleagues or recreating institutional knowledge that already exists somewhere in the organization. R&D professionals spend approximately 35 percent of their time searching for and validating information rather than conducting actual research. For a department of 100 researchers with an average fully loaded cost of $150,000 per year, that translates to roughly $5.25 million annually spent on information discovery alone, representing 70,000 hours of productivity that could otherwise be directed toward actual innovation.
Why Traditional Knowledge Sharing Approaches Hit a Ceiling in R&D
The conventional playbook for improving knowledge sharing in R&D departments includes familiar elements: establish communities of practice, create centralized document repositories, reward knowledge contribution in performance reviews, implement regular cross-team briefings, and invest in collaboration platforms like Slack or Microsoft Teams. Each of these strategies has merit, and none should be abandoned. But they all share a common dependency on individual human effort as the bottleneck through which all organizational knowledge must pass.
Consider what happens when a senior materials scientist conducts a thorough landscape analysis of biodegradable polymer patents before launching a new formulation project. Under traditional knowledge sharing models, capturing that intelligence for the broader organization requires the scientist to write a summary document, tag it with appropriate metadata, store it in the right repository, notify relevant colleagues, and present key findings at a team meeting. Each of these steps competes with the scientist's primary responsibility of actually conducting research. In practice, most of that contextual knowledge, including which patent families look most threatening, which technical approaches appear to be dead ends, and which white spaces suggest opportunity, never makes it into any system that a colleague starting a similar project eighteen months later would think to consult.
The problem intensifies with scale. A midsized enterprise R&D department might conduct hundreds of patent searches, review thousands of scientific papers, and generate dozens of competitive intelligence assessments in a single quarter. The volume of potentially reusable insight produced by these activities vastly exceeds what any documentation protocol can capture, regardless of how disciplined the team is about following it. Tribal knowledge, the undocumented expertise that exists only in the minds of experienced researchers, compounds this challenge further. According to Panopto's research, 42 percent of institutional knowledge is unique to the individual employee. When that employee retires, transfers, or leaves the company, nearly half of what they contributed to the organization's capability disappears with them.
The manufacturing, chemicals, and automotive sectors face this knowledge attrition with particular urgency. Some companies expect to lose 30 percent or more of their most experienced engineers to retirement within the next five years. The specialized knowledge those engineers carry about decades of process optimization, material behavior under unusual conditions, and regulatory navigation cannot be reconstructed from project files alone. It lives in the connections between disparate observations, the pattern recognition built through years of experimentation, and the contextual judgment about which published results are reliable and which should be viewed skeptically. No wiki or shared drive captures that kind of intelligence.
The Compounding Knowledge Model: How AI Memory Changes the Equation
The concept of collective AI memory reframes knowledge sharing from a documentation challenge into an infrastructure investment with compounding returns. Rather than relying on researchers to manually extract, format, and distribute insights, a compounding knowledge system captures intelligence as a natural byproduct of the research activities teams are already performing. Every patent search enriches the organizational understanding of the competitive landscape. Every literature review adds to the collective map of scientific frontiers. Every competitive analysis sharpens the picture of where market opportunities and threats are emerging. Critically, this captured intelligence is not simply stored; it is connected, contextualized, and made available to AI systems that can synthesize it with new queries in real time.
The compounding effect is what distinguishes this approach from earlier generations of knowledge management technology. Traditional knowledge bases are additive: each new document increases the total volume of stored information, but the documents themselves do not interact or build on each other. A compounding AI memory is multiplicative: each new piece of intelligence enhances the value of everything already in the system by creating new connections, surfacing non-obvious relationships, and enabling the AI to provide progressively richer, more contextualized responses over time. When the hundredth researcher queries the system about a technical domain, they benefit not only from whatever external data the platform accesses but from the accumulated context of the ninety-nine previous investigations their colleagues have conducted.
This is the architectural principle behind platforms designed specifically for enterprise R&D intelligence. Cypris, for example, integrates access to more than 500 million patents and scientific papers with an AI research agent called Cypris Q that retains context from previous queries and builds organizational knowledge over successive interactions. When a researcher uses Cypris Q to investigate a new technology domain, the system draws on the full breadth of global patent and scientific literature while simultaneously incorporating the accumulated research history specific to that organization. The result is not just a search engine that returns documents but an intelligence layer that understands what the organization has already explored, where its strategic interests lie, and how new discoveries connect to ongoing priorities.
This architecture solves several problems that traditional knowledge sharing approaches cannot address. First, it eliminates the documentation burden by capturing intelligence as a natural consequence of research activity rather than requiring a separate effort. Researchers do not need to write summaries or tag documents because the AI system learns from the interactions themselves. Second, it makes tacit knowledge partially transferable by encoding the patterns and connections that experienced researchers discover into a system that any team member can access. While no technology can fully replicate a veteran scientist's intuition, a system that remembers every question that scientist has asked and every connection they have drawn captures far more contextual intelligence than any written document could. Third, it bridges organizational silos by making knowledge from one team's investigation instantly available to every other team in the organization. When a coatings R&D group discovers a relevant patent cluster during their research, that discovery automatically enriches the intelligence available to the adhesives team working on a related material class, even if neither team knows the other exists.
Building the Foundation: What a Compounding R&D Knowledge System Requires
Constructing an AI memory that actually compounds organizational intelligence over time requires several foundational elements working together. The first and most critical is comprehensive data integration. An R&D knowledge system that draws from only one category of external intelligence, whether patents alone, scientific papers alone, or market data alone, will produce a fragmented and misleading picture of the innovation landscape. Researchers make decisions at the intersection of technical feasibility, competitive positioning, regulatory constraints, and market opportunity. The intelligence system that informs those decisions must span all of these dimensions to provide genuinely useful synthesis.
Enterprise R&D intelligence platforms distinguish themselves from academic search tools and patent attorney databases precisely through this breadth of integration. Where a patent search tool might surface relevant prior art and a literature database might identify relevant publications, an integrated platform connects patent filings with the scientific papers that inform them, links competitive patent activity to market intelligence about commercial intent, and situates all of this within the context of regulatory developments that could accelerate or constrain specific technology paths. This interconnection is what enables the AI to generate compounding insights rather than isolated search results.
The second foundational requirement is an R&D-specific ontology, a structured knowledge framework that understands the relationships between technical concepts, material categories, application domains, and innovation trajectories in the way that researchers themselves think about them. General-purpose AI systems lack this domain specificity, which means they cannot reliably connect a query about "barrier coatings for flexible packaging" with relevant patents filed under "oxygen transmission rate reduction in polymer films" or scientific papers discussing "nanocomposite permeation resistance." A purpose-built R&D ontology enables the kind of lateral connection that distinguishes transformative research from incremental investigation, and it ensures that the compounding knowledge base grows along dimensions that reflect genuine technical relationships rather than superficial keyword overlaps.
The third requirement is enterprise-grade security and access governance. R&D knowledge is among the most strategically sensitive information any organization possesses. The insights that accumulate in a collective AI memory, including which technology domains the organization is investigating, which competitive threats it has identified, and which innovation opportunities it is pursuing, would be extraordinarily valuable to competitors. Any platform entrusted with this intelligence must meet the most rigorous security standards. SOC 2 Type II certification, data encryption at rest and in transit, role-based access controls, and clear data sovereignty guarantees are minimum requirements, not differentiators. Organizations should also evaluate whether the platform provider is based in a jurisdiction with strong intellectual property protections and whether it maintains official API partnerships with the AI providers it integrates, ensuring that organizational data is handled according to enterprise security standards at every layer of the technology stack.
Cypris helps enterprise R&D teams build a compounding knowledge advantage by unifying access to over 500 million patents, scientific papers, and competitive intelligence sources through a single AI-powered platform. Book a demo to see how organizations are turning every research interaction into lasting institutional intelligence at cypris.ai.
From Documentation Culture to Contribution Culture
Adopting a compounding AI memory system does not eliminate the need for cultural investment in knowledge sharing. It changes the nature of that investment. Under traditional knowledge management, the cultural challenge is motivating researchers to perform an additional task (documentation) on top of their primary work. Under a compounding model, the cultural challenge shifts to something more achievable: encouraging researchers to conduct their existing research activities through the shared intelligence platform rather than through disconnected personal tools.
This is a crucial distinction. Asking a researcher to write a detailed summary of every patent search is asking them to do something extra. Asking them to run their patent searches through a shared platform that captures and compounds intelligence automatically is asking them to do the same thing they were already doing, just through a different interface. The behavioral change required is adoption of a tool, not adoption of a practice. Organizations that have successfully deployed R&D intelligence platforms report that researcher adoption accelerates once teams experience the compounding benefit firsthand. When a scientist runs a query and the platform surfaces not only relevant external literature but also connections to investigations their colleagues conducted months earlier, the value proposition becomes self-evident.
The organizational shift is from a documentation culture, where knowledge sharing is treated as an obligation that competes with research for time and attention, to a contribution culture, where every act of research automatically enriches the collective intelligence available to the entire organization. In a documentation culture, knowledge sharing is a tax on productivity. In a contribution culture, knowledge sharing is a natural consequence of productivity.
Leadership plays an essential role in catalyzing this transition. R&D directors and chief technology officers should establish the shared intelligence platform as the default starting point for any new research initiative. Before launching a new project, teams should first query the organizational AI memory to understand what the company already knows about the relevant technology landscape, which adjacent investigations have been conducted, and what competitive and scientific context has already been mapped. This practice not only prevents duplicate research but reinforces the value of contributing to the shared knowledge base by demonstrating that previous contributions are actively building on each other.
The External Intelligence Dimension That Most Knowledge Sharing Strategies Miss
Most guidance on improving R&D knowledge sharing focuses exclusively on internal knowledge: getting researchers to share what they know with each other. This emphasis is understandable but incomplete. In practice, the most consequential knowledge sharing failures in R&D are not failures to share internal tribal knowledge. They are failures to ensure that external intelligence, including patent landscapes, scientific breakthroughs, competitive moves, and regulatory developments, reaches every team that needs it in a timely and contextualized form.
Consider a scenario that plays out regularly in large R&D organizations. A team in the automotive materials division conducts a thorough analysis of emerging patents in lightweight structural composites. Three months later, a team in the aerospace coatings division begins a project that intersects significantly with the same patent landscape but has no knowledge that the earlier analysis was ever performed. The second team spends weeks replicating intelligence that already exists within the company, not because anyone failed to share internal expertise, but because the external intelligence gathered by one team never entered any system that the other team could access.
This is the gap that a compounding AI memory specifically addresses. When external intelligence, including patent analysis, literature reviews, and competitive signals, is captured in a shared, AI-accessible system, it becomes organizational knowledge that persists and compounds independently of which team originally gathered it or whether that team remembers to share it. The aerospace coatings team, querying the same platform that the automotive materials team used months earlier, would automatically benefit from the accumulated intelligence without either team needing to coordinate, schedule a meeting, or remember to send an email.
Enterprise R&D intelligence platforms like Cypris are designed around this principle. By providing unified access to comprehensive patent databases, scientific literature repositories, and competitive intelligence through a single platform that retains organizational context, these systems ensure that external intelligence is captured once and compounded indefinitely. The AI research agent draws on the full history of the organization's queries and investigations, which means that each new research question is answered not in isolation but in the context of everything the organization has previously explored. This is how knowledge sharing transforms from a periodic, effortful activity into a continuous, automatic process embedded in the infrastructure of research itself.
Measuring the Impact of Compounding Knowledge Systems
Organizations evaluating AI-powered knowledge sharing approaches should track several categories of metrics to assess whether their knowledge base is genuinely compounding. Research duplication rates offer the most direct measure: how frequently do teams discover that investigations they initiated had already been partially or fully conducted by another group? Organizations that have consolidated their R&D intelligence infrastructure report reductions in research duplication of up to 70 percent.
Time to insight measures how long it takes a researcher to move from an initial question to an actionable understanding of the relevant technology landscape, competitive positioning, and scientific context. In organizations relying on fragmented tools and manual knowledge sharing, this process can take days or weeks as researchers navigate between separate patent databases, literature search engines, and internal document repositories. Integrated intelligence platforms with compounding AI memory compress this timeline significantly, with some organizations reporting 50 percent reductions in prior art search time and 40 percent decreases in overall time to insight.
Cross-team intelligence reuse is perhaps the most meaningful indicator of whether knowledge is genuinely compounding. This metric tracks how frequently insights generated by one team surface as relevant context for another team's investigation, even when the teams did not directly coordinate. High rates of cross-team intelligence reuse indicate that the AI memory is successfully connecting knowledge across organizational boundaries, which is the compounding dynamic that creates exponential returns on the initial intelligence investment.
Finally, new researcher onboarding velocity reflects how effectively the compounding knowledge base transmits institutional expertise to incoming team members. In organizations without integrated AI memory, new researchers typically require months to develop a working understanding of the competitive landscape, the organization's research history, and the technical context relevant to their projects. When this context is available through an AI system that can synthesize years of accumulated organizational intelligence in response to natural language queries, the effective onboarding period compresses dramatically. Rather than spending months recreating a mental model that senior colleagues built over years, new researchers can query the organizational memory and begin contributing meaningful work far sooner.
Getting Started: A Practical Roadmap for R&D Leaders
R&D leaders looking to implement a compounding knowledge sharing approach should begin by auditing the current intelligence tool landscape across their department. Most enterprise R&D teams navigate between five and twelve separate intelligence platforms, from patent databases to scientific literature repositories, market intelligence tools, and competitive analysis systems. Each of these tools creates its own silo of intelligence, invisible to the other tools and inaccessible to AI systems that could synthesize insights across them. Mapping this fragmentation is the necessary first step toward consolidation.
The second step is identifying a platform capable of serving as the central intelligence layer. The requirements are demanding: the platform must integrate comprehensive patent data, scientific literature, and competitive intelligence in a single interface; it must provide AI-powered synthesis that retains and builds on organizational query history; it must meet enterprise security standards including SOC 2 Type II certification; and it must integrate with existing research workflows so that adoption does not require researchers to abandon familiar processes. Platforms that meet these criteria become the foundation of the compounding knowledge system, capturing intelligence from every research interaction and making it available to the entire organization.
The third step is establishing platform-first research protocols. Every new project, landscape analysis, and competitive review should begin with a query to the shared intelligence platform. This practice serves dual purposes: it ensures that existing organizational knowledge informs every new investigation, and it contributes each new investigation to the growing body of organizational intelligence. Over time, this protocol becomes self-reinforcing as researchers experience the compounding benefit of a knowledge base that grows richer with every interaction.
The final step is patient commitment to the compounding model. Unlike traditional knowledge management initiatives that can be evaluated in weeks, a compounding knowledge system delivers returns that accelerate over time. The platform becomes meaningfully more valuable after six months of accumulated queries than it was in the first week, and substantially more valuable after two years than after six months. Organizations that commit to this approach and sustain researcher adoption through the initial period of accumulation will build a durable competitive advantage that becomes increasingly difficult for rivals to replicate, because the compounding knowledge base reflects not just access to external data but the accumulated strategic intelligence of the organization's own research history.
FAQ
What is knowledge sharing in R&D?Knowledge sharing in R&D is the systematic practice of capturing, organizing, and distributing both internal institutional expertise and external innovation intelligence, including patent landscapes, scientific literature, and competitive data, so that every researcher in the organization can build on collective knowledge rather than working in isolation.
Why is knowledge sharing particularly important for R&D departments?R&D departments face uniquely high costs from knowledge sharing failures because research involves long timelines, highly specialized expertise, and cumulative investigation where missing a single piece of prior art or duplicating a previous study can waste months of effort and millions of dollars. Fortune 500 companies lose an estimated $31.5 billion annually from ineffective knowledge sharing, with R&D departments bearing disproportionate impact due to the specialized and cumulative nature of research work.
What is a compounding AI memory for R&D?A compounding AI memory is a centralized intelligence system that automatically captures knowledge from every research activity, including patent searches, literature reviews, and competitive analyses, and makes that accumulated intelligence available to AI systems that can synthesize it with new queries. Unlike traditional knowledge bases where documents are simply stored, a compounding AI memory grows more valuable over time as each new interaction enriches the context available for future investigations.
How does a compounding knowledge system differ from a traditional knowledge management platform?Traditional knowledge management platforms are additive: each new document increases the volume of stored information, but documents do not interact with each other. A compounding knowledge system is multiplicative: each new piece of intelligence enhances the value of everything already in the system by creating connections, surfacing relationships, and enabling AI to provide progressively richer responses. The key difference is that traditional systems require humans to make connections between stored documents, while compounding systems use AI to make those connections automatically.
What should R&D leaders look for in an enterprise intelligence platform?R&D leaders should evaluate platforms based on breadth of data integration (patents, scientific literature, competitive intelligence, and market data in a single interface), AI synthesis capabilities that retain organizational context across queries, enterprise security certifications such as SOC 2 Type II, data sovereignty guarantees, an R&D-specific ontology that understands technical relationships between concepts, and the ability to integrate with existing research workflows. Platforms like Cypris are purpose-built for these enterprise R&D requirements.
How can organizations measure whether their knowledge sharing is actually compounding?Key metrics include research duplication rates (how often teams unknowingly replicate previous investigations), time to insight (how quickly researchers achieve actionable understanding of a technology landscape), cross-team intelligence reuse (how frequently one team's research surfaces as context for another team's work), and new researcher onboarding velocity (how quickly new hires develop working knowledge of the organization's research landscape and competitive context).
Cypris helps enterprise R&D teams build a compounding knowledge advantage by unifying access to over 500 million patents, scientific papers, and competitive intelligence sources through a single AI-powered platform. Book a demo to see how organizations are turning every research interaction into lasting institutional intelligence at cypris.ai.

Quantum Computing and Enterprise R&D: What Innovation Leaders Need to Know Now
This article was powered by Cypris Q, an AI agent that helps R&D teams instantly synthesize insights from patents, scientific literature, and market intelligence from around the globe. Discover how leading R&D teams use Cypris Q to monitor technology landscapes and identify opportunities faster - Book a demo
Executive Summary
Quantum computing is no longer a science project. It is a risk-and-optionality play that is already reshaping cybersecurity roadmaps, supplier ecosystems, and the competitive balance in compute-intensive industries [1, 2, 3]. In 2025, the industry crossed multiple inflection points simultaneously: Google demonstrated below-threshold quantum error correction for the first time in 30 years of trying, Quantinuum launched the first enterprise-grade commercial quantum computer with Fortune 500 customers running real workloads, Microsoft introduced an entirely new class of qubit, and quantum startup funding nearly tripled year over year. The global quantum computing market reached an estimated $1.8 to $3.5 billion in 2025, with projections ranging from $7 billion to $20 billion by 2030, depending on modeling assumptions [4, 5].
For innovation strategists, quantum is best treated as a two-horizon asset: a near-term driver of security modernization and ecosystem influence, and a longer-term path to differentiated capabilities in optimization and simulation once fault tolerance matures [3, 6]. But the near-term is arriving faster than most enterprise roadmaps anticipated. NIST's post-quantum cryptography program has moved from research into formal standardization milestones, creating an enterprise-wide trigger that forces budget allocation, vendor qualification, and lifecycle planning now, not after a cryptographically relevant quantum computer arrives [1, 2, 7]. Meanwhile, the IP landscape reveals that the most defensible competitive positions are forming not around qubit counts, but in the reliability and orchestration stack: calibration-aware compilation, error mitigation workflows, and execution orchestration platforms [8, 9, 10].
This article examines where quantum maturity actually stands after a landmark year of breakthroughs, where enterprise value will land first, how the competitive and IP landscape is reshaping vendor selection, and what R&D leaders should prioritize in the next six months.
2025: The Year the Hardware Race Became Real
Any assessment of quantum computing's enterprise relevance must start with what happened in the hardware landscape over the past 18 months, because the trajectory shifted dramatically.
In December 2024, Google introduced its 105-qubit Willow chip and demonstrated what the quantum computing community had pursued for nearly three decades: below-threshold quantum error correction [11, 12]. In experiments scaling from 3x3 to 5x5 to 7x7 arrays of physical qubits, each increase in logical qubit size produced an exponential reduction in error rates, cutting the error rate roughly in half with each step up [11, 12, 13]. This was not an incremental improvement. It was the first credible experimental proof that quantum error correction can actually pay for itself at scale, the foundational requirement for building fault-tolerant quantum computers. Willow also completed a benchmark computation in under five minutes that Google estimated would take the Frontier supercomputer, the world's most powerful classical machine, ten septillion years [11, 12].
In April 2024, Microsoft and Quantinuum demonstrated logical qubits with error rates 800 times lower than corresponding physical qubits, creating four highly reliable logical qubits from just 30 physical qubits [14]. Microsoft declared this the transition into "Level 2 Resilient" quantum computing, capable of tackling meaningful scientific challenges including molecular modeling and condensed matter physics simulations [14, 15].
Then in February 2025, Microsoft unveiled Majorana 1, the world's first quantum processor powered by topological qubits [16]. Built with a novel class of materials called topoconductors, Majorana 1 represents a fundamentally different approach to quantum computing: hardware-protected qubits that use digital rather than analog control, dramatically simplifying error correction. Microsoft's roadmap envisions scaling to a million qubits on a single chip [16].
By November 2025, Quantinuum launched Helios, which the company positioned as the world's most accurate general-purpose commercial quantum computer, with 98 fully connected physical qubits and fidelity exceeding 99.9% [17, 18]. The launch came with a signal that matters more than the hardware specifications: Amgen, BMW Group, JPMorgan Chase, and SoftBank signed on as initial customers, conducting what Quantinuum described as "commercially relevant research" in biologics, fuel cell catalysts, financial analytics, and organic materials [17, 18]. Quantinuum's valuation reached $10 billion following an $800 million oversubscribed funding round [19].
Meanwhile, IBM continued executing against a roadmap it has so far delivered on consistently. In November 2025, IBM introduced its Nighthawk processor and the experimental Loon chip containing components needed for fault-tolerant computing [20]. IBM's updated roadmap targets quantum advantage by the end of 2026 and Starling, its first large-scale fault-tolerant quantum computer with 200 logical qubits capable of executing 100 million quantum operations, by 2029 [21, 22]. Beyond Starling, IBM's Blue Jay system targets 2,000 logical qubits and one billion operations by 2033 [21].
What makes this moment particularly significant for R&D leaders is the diversification of viable approaches. DARPA's Quantum Benchmarking Initiative selected companies spanning five distinct qubit modalities: superconducting qubits from IBM and Nord Quantique, trapped ions from IonQ and Quantinuum, neutral atoms from Atom Computing and QuEra, silicon spin qubits from Diraq and others, and photonic qubits from Xanadu [23]. PsiQuantum, pursuing a photonic approach, became the world's most funded quantum startup with a $1 billion raise in September 2025, reaching a $7 billion valuation [23]. No single hardware modality has emerged as the winner, and this has direct implications for how enterprises should structure vendor relationships and IP strategies.
The Investment Surge: Why Budget Conversations Are Changing
The capital flowing into quantum computing has reached a scale that demands attention from any executive managing a technology portfolio. Quantum computing companies raised $3.77 billion in equity funding during the first nine months of 2025, nearly triple the $1.3 billion raised in all of 2024 [23, 24]. Government commitments have been equally aggressive. Global public quantum funding exceeded $10 billion by April 2025, anchored by Japan's $7.4 billion commitment and China's establishment of a national fund of approximately $138 billion for quantum and related frontier technologies [24, 25]. The U.S. National Quantum Initiative, the EU Quantum Flagship program, and newly announced national strategies from Singapore, South Korea, and others are creating a geopolitically charged landscape where quantum readiness is becoming a matter of industrial policy, not just R&D strategy [24, 25].
McKinsey estimates that quantum computing companies generated $650 to $750 million in revenue in 2024 and were expected to surpass $1 billion in 2025, with the broader quantum technology market projected to generate up to $97 billion in revenue worldwide by 2035 [6, 25]. Nearly 80% of the world's top 50 banks are now investing in quantum technology [5]. These are no longer speculative research budgets. They are strategic positioning investments by organizations that expect quantum to reshape competitive dynamics within the decade.
For corporate R&D leaders, the practical implication is that the window for "wait and see" is closing. Competitors and partners are building quantum capabilities, accumulating institutional knowledge, and establishing vendor relationships that will be difficult to replicate once the technology inflects toward commercial utility.
The Error Correction Inflection: From Theory to Measurable Engineering
The decisive maturity shift underlying all of these developments is that quantum error correction has crossed from a theoretical prerequisite into an engineering discipline with quantitative milestones [26, 27, 28]. The surface code remains a central reference point because it provides a practical route to fault tolerance with local operations, and its threshold behavior links hardware error rates to scalable reliability targets [29, 26].
Google's Willow results were the most dramatic demonstration, but the broader research trajectory matters more. Recent experiments have explicitly targeted "break-even" regimes, where an encoded logical qubit outperforms a comparable unencoded physical qubit, because this is the earliest credible signal that error correction can pay for itself [28, 30, 31]. Work on encoding and manipulating logical states beyond break-even demonstrates that the overhead curve can bend in a favorable direction under real device noise, even though full fault-tolerant computation remains ahead [30, 31].
However, the research record is also unambiguous that thresholds and scalability are noise-model dependent, and engineering teams must treat coherent and correlated errors as first-class constraints [32, 33]. Surface-code threshold estimates vary with circuits and decoders, and reported numerical thresholds sit around the approximately 0.5% to 1.1% per-gate range under specific modeling assumptions, illustrating why average gate fidelity alone is an insufficient maturity metric [29]. Google's own researchers acknowledged that while Willow's logical error rates of around 0.14% per cycle represent a qualitative breakthrough, they remain orders of magnitude above the 10^-6 levels needed for running meaningful large-scale quantum algorithms [11]. IBM is attacking this gap from the code side, shifting from surface codes to quantum LDPC codes that reduce physical qubit overhead by up to 90%, a potential game-changer for the economics of fault tolerance [21, 22].
The economic implication of this shift is significant. The transition from "can we encode?" to "can we encode with operational latency, decoding, and calibration constraints?" redefines where competitive advantage accrues. It moves up the stack into control systems, real-time decoding, and workflow orchestration, capabilities that are patentable, defensible, and difficult to replicate [8, 9, 10].
The NISQ Reality Check: Error Mitigation Helps, but Its Scaling Economics Are Brutal
Most enterprise quantum programs today live in the noisy intermediate-scale quantum (NISQ) regime, where practical value is pursued through hybrid algorithms and error mitigation rather than full fault tolerance [34, 35]. This is an economically rational strategy, up to a point, because error mitigation can improve accuracy without the massive qubit overhead of QEC [34].
However, the literature formalizes a hard ceiling. Broad classes of error-mitigation methods incur costs that can grow rapidly, often exponentially, with circuit depth and sometimes with qubit count, depending on noise assumptions and target accuracy [36, 37]. Even when mitigation methods are clever and empirically useful, decision-makers should assume that "just mitigate harder" does not scale into the regimes required for transformative workloads [38, 36, 37].
This reality turns quantum program management into a portfolio problem. Near-term pilots should focus on problems with short-depth circuits and measurable business value, and on organizational learning about workflow, data, and governance, while simultaneously building positions in the fault-tolerant pathway that will ultimately unlock durable advantage [3, 6].
Where Enterprise Impact Will Land First: Optimization as the Proving Ground
In practice, many early enterprise workloads will not look like Hollywood-style quantum chemistry. They will look like operational optimization: scheduling, routing, portfolio constraints, and resource allocation. These problems are natural first targets because they are ubiquitous across industries, have clear KPIs, and can be framed as hybrid workflows where quantum is one module rather than the whole system [39]. Market analysts consistently identify optimization as the application segment commanding the largest share of enterprise quantum adoption in North America [4, 5].
Research has explicitly positioned optimization applications as quantum performance benchmarks, emphasizing throughput and solution-quality tradeoffs under real execution conditions [39]. This benchmarking orientation shifts quantum evaluation away from abstract qubit counts and toward business-facing performance profiles, including time-to-solution, output quality, and repeatability, that map directly to procurement and ROI logic [39].
When quantum evaluation becomes benchmark-driven, the competitive battlefield shifts from who has the biggest chip to who owns the end-to-end pipeline: problem encoding, compilation, calibration-aware execution, and post-processing that converts hardware into dependable outputs [8, 10, 40].
Corporate Proof Points: The Partnerships Have Matured
The nature of enterprise quantum partnerships has changed fundamentally since the early ecosystem-joining announcements of 2017-2022. Where earlier engagements were largely exploratory, the current generation involves specific commercial workloads, dedicated hardware access, and measurable research outcomes.
Quantinuum's Helios launch in November 2025 represents the clearest signal of this maturation. Amgen is exploring hybrid quantum-machine learning for biologics design. BMW Group is researching fuel cell catalyst materials. JPMorgan Chase is investigating advanced financial analytics capabilities. SoftBank conducted commercially relevant research during the pre-launch beta period [17, 18, 19]. These are not press-release partnerships. They represent organizations committing engineering resources to specific quantum workflows with defined performance criteria.
In parallel, IonQ and Ansys demonstrated quantum performance exceeding classical computing for medical device design, and Quantinuum partnered with JPMorgan Chase, Oak Ridge National Laboratory, and Argonne National Laboratory to generate true verifiable quantum randomness with applications in cryptography and cybersecurity [23]. IBM's growing ecosystem, including its planned quantum advantage demonstrations by end of 2026, continues to anchor the superconducting qubit pathway with a fleet of quantum systems accessible through cloud and on-premise deployments [21, 22].
A separate but equally significant category is the energy and materials sector, where IBM and Exxon's exploration of quantum for computational tasks in R&D, Roche's testing of quantum algorithms for drug discovery, and broader pharma engagement through Quantinuum's platform signal that compute-intensive industries are systematically evaluating quantum as part of their longer-horizon computational strategies [41, 42, 43].
These partnerships should be interpreted as proof that leading firms are buying three assets simultaneously: early access to talent and tooling, influence over vendor roadmaps, and a learning curve advantage that becomes hard to replicate once the technology inflects toward commercial utility [3, 6].
IP as a Strategic Moat: The Plumbing Is Where Defensibility Lives
In quantum computing, the most defensible IP often sits below the application layer, in the reliability and orchestration stack: error mitigation calibration, compilation strategies, control workflows, and execution orchestration. Patents in this layer signal where vendors expect long-term defensibility because these capabilities become embedded in platforms, deeply integrated with hardware behavior, and hard to displace without imposing switching costs.
Three plumbing domains stand out in the current patent landscape.
The first is calibration-aware error mitigation, software that adapts to noise. IBM patents describe methods for calibrating error mitigation techniques by selecting settings based on factors such as circuit depth, aiming to approximate a zero-noise expectation without repeated manual tuning [44, 45]. Other filings describe inserting error-mitigating operations based on assessed hardware noise conditions, effectively tying compilation to real device state [46].
The second is compilation and runtime strategies that reduce rework and latency. IBM has pursued approaches that bind calibration libraries to compiled binaries so circuits can be compiled without knowing the final calibration outcome, reducing recompilation churn in unstable hardware environments [9]. Patents around adaptive compilation of quantum jobs highlight selection and modification of programs based on device attributes and run criteria, reinforcing that compilation is becoming a competitive lever rather than a commodity step [10].
The third is orchestration platforms and quantum DevOps. Amazon patents describe compilation services and orchestration approaches that support multiple hardware backends and containerized execution across third-party quantum hardware providers, effectively defining the control plane and platform gravity for enterprise quantum adoption [47, 48, 49, 50]. Quantum Machines patents emphasize real-time orchestration and concurrent processing in quantum control systems, a layer that becomes critical when feedback, streaming results, and low-latency calibration loops drive performance [8, 51].
This plumbing IP creates barriers to entry because it compounds over time. Every calibration trick, compiler heuristic, and orchestration shortcut is trained on proprietary hardware telemetry and execution data, building a feedback loop that improves reliability and throughput [8, 9, 10]. For corporate adopters, this implies that vendor choice is not only about qubits. It is about which ecosystem will own the workflow layer that determines productivity and switching costs [3, 6].
What Decision-Makers Should Expect: Five Forecasts for the Next Three Years
First, "quantum readiness" budgets will increasingly be justified through cybersecurity and compliance rather than near-term computational ROI. NIST's PQC standardization milestones and related government guidance are driving enterprise migration planning across product and infrastructure lifecycles, making quantum an immediate governance issue regardless of quantum hardware timelines [1, 2, 7].
Second, vendor differentiation will decisively shift from hardware headline metrics to full-stack reliability tooling. Patent activity emphasizes mitigation calibration, calibration-independent compilation, adaptive compilation, and orchestration services, and the hardware players are all converging on hybrid quantum-classical architectures that make software and middleware the key differentiators [44, 45, 9, 48, 10].
Third, the most repeatable early business wins will be hybrid optimization workflows evaluated via benchmark-style performance profiles. Optimization benchmarking frameworks explicitly focus on throughput and solution-quality tradeoffs under realistic execution constraints, aligning with procurement-grade evaluation criteria [39].
Fourth, error mitigation will remain valuable for near-term pilots but will hit economic scaling limits that force a pivot to QEC for transformative workloads. Fundamental bounds show mitigation costs can grow sharply with depth and qubit count under broad noise models [36, 37, 38].
Fifth, the timeline to fault-tolerant quantum computing has compressed. Multiple credible organizations, including IBM, Google, and Quantinuum, now target fault-tolerant systems by 2029-2030, with quantum advantage demonstrations expected as early as 2026 [21, 22, 17]. Enterprises that begin building quantum literacy, workflows, and vendor relationships now will have a three-to-five-year head start on those that wait for fault tolerance to arrive.
The Resource Allocation Logic: A Portfolio, Not a Bet
A practical resource allocation stance is to treat quantum as three simultaneous investments.
The first is risk mitigation. PQC migration planning and cryptographic inventory are non-optional for many sectors. Companies that delay building a cryptographic inventory and dependency map aligned with NIST PQC transition realities accumulate technical debt that becomes harder to unwind as deadlines approach [1, 2, 7].
The second is option creation. Targeted pilots in optimization and simulation build organizational learning and partner leverage. The most effective pilots focus on constrained optimization problems with clean metrics, such as cost, time, or utilization, and a known baseline, with reporting framed in performance profile terms: solution quality versus runtime across instance sizes [39, 3].
The third is moat building. IP positions in workflow, compilation, mitigation, and domain-specific problem formulations create defensible advantage independent of which hardware modality wins. Companies should identify what is proprietary in their pipeline, including data representations, constraints, objective functions, and orchestration logic, and file strategically on domain-specific encodings and workflow automation where internal know-how is unique and transferable across hardware providers [44, 45, 47, 9].
This portfolio framing prevents the most common failure mode: overfunding speculative moonshots while underfunding the unglamorous readiness work that determines whether the company can capitalize when the technology inflects [3, 6].
Strategic Imperatives for the Next Six Months
The first imperative is to stand up a quantum risk and readiness workstream anchored in PQC migration. The fastest route to board-level clarity is to connect quantum to mandated security modernization, not experimental compute outcomes. This means building a cryptographic inventory and dependency map, classifying systems by crypto agility and upgrade cycles to prioritize where migration is hardest, and engaging vendors on PQC support roadmaps for products and services in scope [1, 2, 7].
The second imperative is to choose one optimization pilot with an executive KPI and treat it as a benchmark, not a demo. Select a constrained optimization problem with a clean metric and a known baseline, require reporting in performance profile terms, and architect the workflow as hybrid from day one to ensure the pilot teaches integration, not only algorithm theory [39].
The third imperative is to negotiate partnerships that buy influence over the stack you cannot build alone. The partnership landscape has matured considerably. Finance organizations should follow JPMorgan Chase's model of engaging across multiple quantum ecosystems simultaneously, from IBM to Quantinuum's Helios. Pharma and materials organizations should explore Quantinuum's and IBM's growing application-specific partnerships. Operations-focused organizations should pursue pilots tied to tangible constraints where improvements are measurable [17, 21, 41].
The fourth imperative is to start building internal quantum plumbing IP now, even if you never build hardware. Conduct an IP scan focused on mitigation calibration, compilation and orchestration, and runtime control, because these layers are where vendors are actively patenting defensible capabilities. Identify what is proprietary in your domain's problem formulations, constraints, and data representations, and file strategically on encodings that are transferable across hardware providers [44, 45, 47, 9].
The fifth imperative is to build a vendor evaluation rubric that weights reliability tooling, multi-backend portability, and platform lock-in risk, not just qubit counts. With five viable qubit modalities competing and no clear winner, enterprises need vendor relationships and software architectures that can adapt as the hardware landscape evolves [47, 8, 9].
The sixth imperative is to make organizational readiness measurable and auditable. Define capability KPIs such as number of workflows benchmarked, reproducibility, integration maturity, and PQC migration milestones. Establish an internal review cadence that treats quantum like a product portfolio with stage gates and kill criteria, and tie funding releases to concrete deliverables [3, 6, 39, 44, 45].
Citations
[1] "Post-Quantum Cryptography FIPS Approved - NIST CSRC." https://csrc.nist.gov/news/2024/postquantum-cryptography-fips-approved
[2] "NIST Releases First 3 Finalized Post-Quantum Encryption Standards." https://www.nist.gov/news-events/news/2024/08/nist-releases-first-3-finalized-post-quantum-encryption-standards
[3] "Quantum Technology Monitor - McKinsey." https://www.mckinsey.com/~/media/mckinsey/business%20functions/mckinsey%20digital/our%20insights/steady%20progress%20in%20approaching%20the%20quantum%20advantage/quantum-technology-monitor-april-2024.pdf
[4] "Quantum Computing Market Research Report 2025-2030." MarketsandMarkets. https://www.marketsandmarkets.com/PressReleases/quantum-computing.asp
[5] "Quantum Computing Market Size, Industry Report 2030." Grand View Research. https://www.grandviewresearch.com/industry-analysis/quantum-computing-market
[6] "The Rise of Quantum Computing | McKinsey & Company." https://www.mckinsey.com/featured-insights/the-rise-of-quantum-computing
[7] "Product Categories for Technologies That Use Post-Quantum Cryptography Standards - CISA." https://www.cisa.gov/resources-tools/resources/product-categories-technologies-use-post-quantum-cryptography-standards
[8] Q.M Technologies Ltd. and Quantum Machines. Concurrent results processing in a quantum control system. Patent No. US-12417397-B2. Issued Sep 15, 2025.
[9] International Business Machines Corporation. Quantum Circuit Compilation Independent of Calibration. Patent No. US-20260037852-A1. Issued Feb 4, 2026.
[10] International Business Machines Corporation. Adaptive Compilation of Quantum Computing Jobs. Patent No. US-20210012233-A1. Issued Jan 13, 2021.
[11] "Meet Willow, our state-of-the-art quantum chip." Google Blog, December 2024. https://blog.google/technology/research/google-willow-quantum-chip/
[12] "Making quantum error correction work." Google Research Blog. https://research.google/blog/making-quantum-error-correction-work/
[13] "Google's Willow Chip Makes a Major Breakthrough in Quantum Computing." Scientific American, December 2024. https://www.scientificamerican.com/article/google-makes-a-major-quantum-computing-breakthrough/
[14] "How Microsoft and Quantinuum achieved reliable quantum computing." Microsoft Azure Quantum Blog, April 2024. https://azure.microsoft.com/en-us/blog/quantum/2024/04/03/how-microsoft-and-quantinuum-achieved-reliable-quantum-computing/
[15] "Quantinuum and Microsoft announce new era in quantum computing." Quantinuum. https://www.quantinuum.com/press-releases/quantinuum-and-microsoft-announce-new-era-in-quantum-computing-with-breakthrough-demonstration-of-reliable-qubits
[16] "Microsoft unveils Majorana 1." Microsoft Azure Quantum Blog, February 2025. https://azure.microsoft.com/en-us/blog/quantum/2025/02/19/microsoft-unveils-majorana-1-the-worlds-first-quantum-processor-powered-by-topological-qubits/
[17] "Quantinuum Announces Commercial Launch of New Helios Quantum Computer." Quantinuum, November 2025. https://www.quantinuum.com/press-releases/quantinuum-announces-commercial-launch-of-new-helios-quantum-computer-that-offers-unprecedented-accuracy-to-enable-generative-quantum-ai-genqai
[18] "Introducing Helios: The Most Accurate Quantum Computer in the World." Quantinuum Blog, November 2025. https://www.quantinuum.com/blog/introducing-helios-the-most-accurate-quantum-computer-in-the-world
[19] "Quantinuum Makes Another Milestone On Commercial Quantum Roadmap." Next Platform, November 2025. https://www.nextplatform.com/2025/11/10/quantinuum-makes-another-milestone-on-commercial-quantum-roadmap/
[20] "IBM Lets Fly Nighthawk And Loon QPUs On The Way To Quantum Advantage." Next Platform, November 2025. https://www.nextplatform.com/2025/11/12/ibm-lets-fly-nighthawk-and-loon-qpus-on-the-way-to-quantum-advantage/
[21] "IBM Sets the Course to Build World's First Large-Scale, Fault-Tolerant Quantum Computer." IBM Newsroom, June 2025. https://newsroom.ibm.com/2025-06-10-IBM-Sets-the-Course-to-Build-Worlds-First-Large-Scale,-Fault-Tolerant-Quantum-Computer-at-New-IBM-Quantum-Data-Center
[22] "IBM lays out clear path to fault-tolerant quantum computing." IBM Quantum Blog. https://www.ibm.com/quantum/blog/large-scale-ftqc
[23] "Top quantum breakthroughs of 2025." Network World, November 2025. https://www.networkworld.com/article/4088709/top-quantum-breakthroughs-of-2025.html
[24] "Quantum Computing Industry Trends 2025." SpinQ. https://www.spinquanta.com/news-detail/quantum-computing-industry-trends-2025-breakthrough-milestones-commercial-transition
[25] "Quantum Investment Stats: Record Funding, Big Tech Bets and Industry Consolidation." Quantum Basel. https://www.quantumbasel.com/blog/quantum-investments-stats-2025/
[26] Daniel Gottesman. "An introduction to quantum error correction and fault-tolerant quantum computation." Proceedings of Symposia in Applied Mathematics. https://doi.org/10.1090/psapm/068/2762145
[27] Markus Muller et al. "Demonstration of Fault-Tolerant Steane Quantum Error Correction." PRX Quantum. https://doi.org/10.1103/prxquantum.5.030326
[28] Andy Z. Ding et al. "Quantum Error Correction of Qudits Beyond Break-even." arXiv. https://doi.org/10.48550/arxiv.2409.15065
[29] Ashley M. Stephens. "Fault-tolerant thresholds for quantum error correction with the surface code." Physical Review A. https://doi.org/10.1103/physreva.89.022321
[30] Andrew Lucas et al. "Entangling Four Logical Qubits beyond Break-Even in a Nonlocal Code." Physical Review Letters. https://doi.org/10.1103/physrevlett.133.180601
[31] Theodore J. Yoder et al. "Encoding a magic state with beyond break-even fidelity." arXiv. https://doi.org/10.48550/arxiv.2305.13581
[32] Hui Khoon Ng and Jing Hao Chai. "On the Fault-Tolerance Threshold for Surface Codes with General Noise." Advanced Quantum Technologies. https://doi.org/10.1002/qute.202200008
[33] Dong E. Liu and Yuanchen Zhao. "Vulnerability of fault-tolerant topological quantum error correction to quantum deviations in code space." arXiv. https://doi.org/10.48550/arxiv.2301.12859
[34] Takahiro Tsunoda et al. "Mitigating Realistic Noise in Practical Noisy Intermediate-Scale Quantum Devices." Physical Review Applied. https://doi.org/10.1103/physrevapplied.15.034026
[35] Yanzhu Chen, Dayue Qin, and Ying Li. "Error statistics and scalability of quantum error mitigation formulas." arXiv. https://doi.org/10.48550/arxiv.2112.06255
[36] Kento Tsubouchi, Nobuyuki Yoshioka, and Takahiro Sagawa. "Universal Cost Bound of Quantum Error Mitigation Based on Quantum Estimation Theory." Physical Review Letters. https://doi.org/10.1103/physrevlett.131.210601
[37] Mile Gu, Ryuji Takagi, and Hiroyasu Tajima. "Universal Sampling Lower Bounds for Quantum Error Mitigation." Physical Review Letters. https://doi.org/10.1103/physrevlett.131.210602
[38] Ryuji Takagi. "Optimal resource cost for error mitigation." Physical Review Research. https://doi.org/10.1103/physrevresearch.3.033178
[39] Thomas Lubinski et al. "Optimization Applications as Quantum Performance Benchmarks." ACM Transactions on Quantum Computing. https://doi.org/10.1145/3678184
[40] Rigetti & Co, LLC. Quantum instruction compiler for optimizing hybrid algorithms. Patent No. US-12293254-B1. Issued May 5, 2025.
[41] "Exxon, IBM to research quantum computing for energy - Anadolu." https://www.aa.com.tr/en/energy/projects/exxon-ibm-to-research-quantum-computing-for-energy/23010
[42] "Roche partners for quantum computing." C&EN Global Enterprise. https://pubs.acs.org/doi/10.1021/cen-09905-buscon13
[43] "Calculating the unimaginable - Roche." https://www.roche.com/stories/quantum-computers-calculating-the-unimaginable
[44] International Business Machines Corporation. Calibrating a quantum error mitigation technique. Patent No. US-12198013-B1. Issued Jan 13, 2025.
[45] International Business Machines Corporation. Calibrating a Quantum Error Mitigation Technique. Patent No. US-20250013907-A1. Issued Jan 8, 2025.
[46] International Business Machines Corporation. Error mitigation in a quantum program. Patent No. US-12430197-B2. Issued Sep 29, 2025.
[47] Amazon Technologies, Inc. Quantum Compilation Service. Patent No. EP-4690024-A1. Issued Feb 10, 2026.
[48] Amazon Technologies, Inc. Containerized Execution Orchestration of Quantum Tasks on Quantum Hardware Provider Quantum Processing Units. Patent No. WO-2025144486-A2. Issued Jul 2, 2025.
[49] Amazon Technologies, Inc. Quantum Computing Program Compilation Using Cached Compiled Quantum Circuit Files. Patent No. US-20230040849-A1. Issued Feb 8, 2023.
[50] Amazon Technologies, Inc. Quantum computing program compilation using cached compiled quantum circuit files. Patent No. US-11977957-B2. Issued May 6, 2024.
[51] Q.M Technologies Ltd. and Quantum Machines. Auto-calibrating mixers in a quantum orchestration platform. Patent No. US-12314815-B2. Issued May 26, 2025.

Patent Activity in Next-Gen Photovoltaics: Who's Building the IP Moat
Published February 9th 2026
This article was powered by Cypris Q, an AI agent that helps R&D teams instantly synthesize insights from patents, scientific literature, and market intelligence from around the globe. Discover how leading R&D teams use Cypris Q to monitor technology landscapes and identify opportunities faster - Book a demo
The perovskite solar cell is no longer a laboratory curiosity. In 2025, LONGi Green Energy shattered the world record for crystalline silicon-perovskite tandem solar cells, reaching a certified power conversion efficiency of 34.85%, validated by the U.S. National Renewable Energy Laboratory and marking the first reported certified efficiency exceeding the single-junction Shockley-Queisser limit of 33.7% for a double-junction tandem device[1]. Oxford PV shipped the world's first commercial perovskite-silicon tandem panels to a U.S. utility-scale installation[2][3] and then signed a landmark patent licensing agreement with Trina Solar for the manufacture and sale of perovskite-based products in China's $50-billion-plus domestic photovoltaic market[4]. GCL Optoelectronics commissioned the world's first gigawatt-scale perovskite module manufacturing facility in Kunshan, backed by a $700 million investment[5]. China emerged as the undisputed leader in perovskite commercialization, with multiple companies racing to scale production lines from megawatt pilot capacity to full industrial output[6].
Behind these headlines lies a fierce and increasingly strategic patent war. For corporate R&D teams in advanced materials and chemicals, understanding who is building the intellectual property moat around next-generation photovoltaics, and where the white space remains, is essential for making informed investment, partnership, and development decisions.
This analysis, conducted using Cypris Q's cross-domain search capabilities spanning patents, academic papers, and industry sources, reveals a landscape where a handful of companies are aggressively staking claims across the full perovskite value chain, from precursor chemistry and deposition methods to device architectures and module-level encapsulation.
The Efficiency Race and Its IP Shadow
The academic literature tells a story of breathtaking progress. Nature Reviews Clean Technology characterized 2025 as a "transformative phase" for perovskite photovoltaics, noting that single-junction efficiencies reached 27% in laboratory conditions while tandem devices exceeded 34.5%[7]. Inverted (p-i-n) perovskite solar cells have achieved certified quasi-steady-state power conversion efficiencies of 26.15% for single-junction devices[8], with more recent work pushing beyond 27% through advanced passivation strategies that dramatically improve both efficiency and thermal stability[9]. Perovskite-silicon tandem cells have surpassed 34.85% efficiency at the lab scale[1][10], and all-perovskite tandem modules have reached a certified 24.5% efficiency over a 20.25 cm² aperture area[11]. Perovskite solar modules, the form factor that actually matters for commercial deployment, have achieved a certified 23.30% efficiency over a 27.22 cm² aperture, representing the highest certified module performance to date for that configuration[12].
What makes this relevant for IP strategy is that each of these efficiency milestones is underpinned by specific material innovations that are being aggressively patented. The dual-site-binding ligand approach that enabled the 26.15% single-junction record[8] represents a class of surface passivation chemistry that multiple companies are now racing to protect. The bilayer interface passivation technique used in high-efficiency tandem cells[10] has direct parallels in LONGi's patent filings covering resistance-increasing nanostructures at the carrier transport layer interface[13]. The dopant-additive synergism strategy that achieved the module efficiency record[12], using methylammonium chloride with Lewis-basic ionic liquid additives, exemplifies the kind of formulation IP that specialty chemical companies should be watching closely.
LONGi: The Patent Juggernaut
A Cypris Q search of LONGi's recent patent portfolio reveals a company that is not merely participating in the perovskite transition but attempting to own it. LONGi's filings span an extraordinary breadth of the technology stack. At the device architecture level, the company holds patents on tandem photovoltaic devices with engineered tunnel junctions featuring ordered defect layers and precisely controlled doping concentrations[14], perovskite-crystalline silicon tandem cells with carrier transport layers incorporating resistance-increasing nanostructures that extend into the perovskite light absorption layer[13], and four-terminal laminated cells with edge-region resistance engineering to reduce carrier recombination losses[15].
On the manufacturing side, LONGi has filed patents covering roller coating devices for perovskite films with integrated film-homogenizing assemblies that improve thickness uniformity[16], spin-coating thermal annealing composite preparation systems designed to prevent precursor solution degradation during substrate transfer[17], and full-silicon-wafer-sized perovskite/crystalline silicon laminated solar cells where the perovskite layer thickness is deliberately varied between central and peripheral areas to prevent conduction between composite and window layers[18]. The company has even patented perovskite material bypass diodes, a module-level innovation that uses P-type and N-type perovskite material regions to create integrated protection circuitry[19][20].
Perhaps most telling is LONGi's patent on copper powder with organic coating layers and in-situ grown copper nanoparticles for use in perovskite cell metallization[21]. This filing, surfaced through a Cypris Q assignee-specific patent search, signals that LONGi is thinking beyond the perovskite absorber layer itself and into the full bill of materials, including conductive pastes and interconnection technologies. LONGi's tandem cell R&D team has consistently pushed the boundaries of the technology since achieving 33.9% efficiency in November 2023, followed by 34.6% in June 2024, and the current 34.85% record in April 2025[1], each milestone built on patented innovations in bilayer interface passivation and asymmetric textured silicon substrates. For materials suppliers, this kind of vertical IP integration should be a strategic signal that the company intends to control not just device performance but the entire manufacturing ecosystem.
Oxford PV: The Vapor Deposition Moat and Its Strategic Monetization
Oxford PV, the UK-based company that spun out of Henry Snaith's pioneering research at the University of Oxford, has taken a fundamentally different approach to IP protection. Where LONGi's portfolio is broad and manufacturing-oriented, Oxford PV's filings are concentrated around a specific technical differentiator: vapor-phase deposition of perovskite materials onto textured silicon surfaces.
A Cypris Q analysis of Oxford PV's recent patent activity reveals a deep portfolio centered on methods for depositing substantially continuous and conformal perovskite layers on surfaces with roughness averages of 50 nm or greater using vapor deposition followed by treatment with further precursor compounds[22][23][24]. This is not an academic exercise. It is the core manufacturing challenge of perovskite-silicon tandems, because the textured surface of a silicon bottom cell, which is essential for light trapping, makes it extremely difficult to deposit uniform perovskite films using conventional solution-based methods.
Oxford PV has extended this core IP into sequential deposition methods using physical vapor deposition of metal halide precursors with different halide components[25][26], processes for making multicomponent perovskites through co-sublimation from multiple evaporation sources[27][28][29], and methods for forming crystalline perovskite layers through a two-dimensional-to-three-dimensional conversion pathway[30]. The company has also filed on multijunction device architectures incorporating metal oxynitride interlayers, preferably titanium oxynitride, between sub-cells to avoid local shunt paths and reduce reflection losses[31], as well as photovoltaic devices with intermediate barrier layers and dual metallic arrays for improved encapsulation and electrical contact[32][33]. Oxford PV's IP strategy also includes passivation chemistry, with patents covering organic passivating agents that are chemically bonded to anions or cations in the metal halide perovskite[34], and device architectures featuring inorganic electrically insulative layers with band gaps greater than 4.5 eV forming type-1 offset junctions[35][36][37][38]. This layered approach, controlling both the deposition process and the device physics, creates a formidable barrier to entry for competitors attempting to replicate Oxford PV's vapor-based tandem approach.
What makes Oxford PV's IP strategy particularly notable in 2025 is that the company has begun actively monetizing it. The April 2025 patent licensing agreement with Trina Solar, covering the manufacture and sale of perovskite-based photovoltaic products in China with sublicensing rights, represents one of the first major patent monetization events in the perovskite industry[4]. Oxford PV's CEO David Ward explicitly invited other parties interested in licensing outside China to make contact, signaling that the company views its patent portfolio not just as a defensive moat but as a revenue-generating asset and a mechanism for shaping the global supply chain. For R&D teams evaluating the perovskite landscape, this development confirms that IP position in this space has crossed from theoretical value to commercial leverage.
The Chinese Manufacturing Giants: Jinko, Trina, GCL, and the Scale Play
While LONGi leads in perovskite-specific IP among Chinese manufacturers, Jinko Solar, Trina Solar, and GCL Optoelectronics are building their own patent positions with distinct strategic emphases. A Cypris Q search reveals that Jinko Solar's recent filings are heavily concentrated on back-contact cell architectures and passivated contact structures that serve as the silicon bottom cell platform for future tandem integration[39][40][41][42]. Jinko's patents on solar cells with micro-protrusion structures on doped semiconductor layers[43] and cells with holes distributed across edge regions filled with passivation material[44] suggest the company is optimizing its silicon cell technology specifically for compatibility with perovskite top cells.
Trina Solar's patent activity reveals a more direct engagement with perovskite-specific challenges. The company has filed on hole transport composite layers using nickel oxide/cerium oxide/self-assembled monolayer stacks for perovskite solar cells[45], laminated batteries with three-junction architectures (crystalline silicon plus two perovskite sub-cells) featuring inter-layer packaging that prevents water and oxygen penetration into perovskite active layers[46], and nano-transparent interlayers containing insulating metal oxide nanoparticles designed to increase light scattering and reduce reflection losses at tandem stacking interfaces[47]. Trina has also patented light conversion films based on benzotriazole compounds that reduce ultraviolet light transmission while improving external quantum efficiency response[48], addressing the well-known UV degradation vulnerability of perovskite materials. The Trina-Oxford PV licensing agreement adds another dimension to Trina's strategy, providing the company with access to Oxford PV's foundational vapor deposition IP while simultaneously validating the importance of patent portfolios as a currency of competition in this space[4].
GCL Optoelectronics, though less prominent in the Cypris Q patent analysis, deserves attention as the company making the most aggressive manufacturing bet. Its June 2025 commissioning of the world's first gigawatt-scale perovskite module facility in Kunshan, producing 2.76 m² large-area tandem modules, represents a $700 million wager that perovskite manufacturing can scale[5]. GCL's tandem module efficiency has reached a certified 29.51% at industrial scale[49], and the company has deployed what it calls the world's first AI-powered high-throughput perovskite manufacturing system, using 52 precision sensors and an AI decision engine that reportedly reduces lab-to-factory conversion time by up to 90%[49]. For corporate R&D teams watching the manufacturing landscape, GCL's moves signal that the race to gigawatt-scale perovskite production is no longer hypothetical.
The Stability Frontier: Where Materials Science Meets IP Strategy
The single greatest barrier to perovskite commercialization remains long-term operational stability, and this is where the patent landscape intersects most directly with the interests of advanced materials and specialty chemical companies. Academic research has demonstrated that state-of-the-art passivation techniques relying on ammonium ligands suffer deprotonation under light and thermal stress[9], that self-assembled monolayer hole transport layers can be desorbed by strong polar solvents in perovskite precursors if anchored by hydrogen bonds rather than covalent bonds[50], and that phase segregation in wide-bandgap perovskites remains a fundamental challenge for tandem architectures[51].
Each of these failure modes represents both a technical challenge and a patent opportunity. The development of amidinium ligands with resonance-enhanced N-H bonds that resist deprotonation achieved a greater than tenfold reduction in ligand deprotonation equilibrium constant[9]. Tridentate anchoring of self-assembled monolayers through trimethoxysilane groups on fully covalent hydroxyl-covered surfaces enabled devices that retained 98.9% of initial efficiency after 1,000 hours of damp-heat testing[50]. Thiocyanate ion incorporation suppressed phase segregation in wide-bandgap perovskites, enabling perovskite/organic tandems with 25.06% efficiency[51].
The encapsulation challenge is generating its own IP ecosystem. Cypris Q patent searches reveal filings on composite packaging adhesive films that enable lamination of perovskite batteries below 105°C without introducing peroxide crosslinking agents harmful to perovskite[52], and buffer structures with conformal compact layers and three-dimensional architectures designed to protect photovoltaic modules from mechanical impact[53][54]. These encapsulation and packaging innovations represent a particularly attractive entry point for specialty materials companies, as they leverage existing competencies in polymer chemistry, barrier films, and adhesive formulations. The fact that GCL's tandem modules have already passed TUV Rheinland's triple IEC stress tests[5] suggests that encapsulation solutions are maturing rapidly, but the diversity of deployment environments, from the high UV exposure of the Gobi Desert to the humidity of coastal building-integrated installations, means that the market for differentiated encapsulation technologies is far from settled.
Where the White Space Remains
For R&D teams evaluating where to invest, the patent landscape as mapped through Cypris Q reveals several areas where IP density is still relatively low compared to the technical opportunity. Scalable deposition methods beyond spin-coating and vapor deposition, particularly slot-die coating, inkjet printing, and blade coating, are seeing growing academic attention but remain underpatented relative to their commercial importance[55][56][57]. The pathway from laboratory-scale tandems to industrial fabrication requires appropriate, scalable input materials and manufacturing processes, and the transition demands increasing focus on stability, reliability, throughput, and cell-to-module integration[55].
Lead-free perovskite compositions represent another area where the gap between research activity and patent protection is notable. The toxicity of lead in perovskite materials remains a significant regulatory and public perception challenge[57], yet the patent landscape is still dominated by lead-based compositions. All-perovskite tandems using mixed lead-tin narrow-bandgap sub-cells are advancing rapidly, the certified 24.5% module efficiency used this architecture[11], but the tin oxidation challenge creates opportunities for novel stabilization chemistries that are not yet well-protected.
The aqueous synthesis of perovskite precursors represents a potentially disruptive manufacturing approach. Recent work demonstrated kilogram-scale production of formamidinium lead iodide microcrystals with up to 99.996% purity from inexpensive, low-purity raw materials, achieving 25.6% cell efficiency[58]. This approach could fundamentally change the precursor supply chain, and the IP landscape around aqueous perovskite chemistry is still nascent. Similarly, the integration of AI and machine learning into perovskite manufacturing workflows, as GCL's high-throughput system demonstrates[49], is creating a new category of process IP that sits at the intersection of materials science and industrial automation.
What This Means for Corporate R&D
The perovskite photovoltaic IP landscape is consolidating rapidly. LONGi, Oxford PV, and the major Chinese manufacturers are building patent portfolios that span device architectures, deposition methods, passivation chemistries, and module-level packaging. Oxford PV's licensing deal with Trina Solar has established that perovskite patents are not just defensive instruments but commercially valuable assets that command real revenue in a market projected to reach $100 billion by 2030[4]. GCL's gigawatt-scale factory has demonstrated that manufacturing investment is following the IP, not waiting for it[5].
For corporate R&D teams in advanced materials and chemicals, the strategic implications are clear. The window for establishing foundational IP in core perovskite device architectures is narrowing, but significant opportunities remain in enabling materials, including passivation agents, encapsulants, barrier films, conductive pastes, and precursor chemistries, where the intersection of materials science expertise and photovoltaic application knowledge creates defensible positions.
Tools like Cypris Q enable R&D teams to monitor this landscape in real time, tracking not just who is filing but what specific technical claims are being staked, where the citation networks point, and where the gaps between academic breakthroughs and patent protection create strategic openings. In a technology transition this consequential, the difference between leading and following often comes down to the quality of competitive intelligence informing R&D investment decisions.
Citations
(1) "34.85%! LONGi Breaks World Record for Crystalline Silicon-Perovskite Tandem Solar Cell Efficiency Again." https://www.longi.com/en/news/silicon-perovskite-tandem-solar-cells-new-world-efficiency/
(2) "Perovskite solar cells: Progress continues in efficiency, durability, and commercialization." https://ceramics.org/ceramic-tech-today/perovskite-solar-cells-progress-2025/
(3) "Perovskite panels headed to US solar farm." https://optics.org/news/15/9/16
(4) "Oxford PV and Trinasolar announce a landmark Perovskite PV patent licensing agreement." https://www.oxfordpv.com/press-releases/oxford-pv-and-trinasolar-announce-a-landmark-perovskite-pv-patent-licensing-agreement
(5) "GCL Optoelectronics finishes 1 GW perovskite PV module factory in China." https://www.pv-magazine.com/2025/06/26/gcl-optoelectronics-commissions-1-gw-perovskite-solar-module-factory-in-china/
(6) "Why China is leading perovskite solar commercialization." https://cen.acs.org/business/inorganic-chemicals/China-leading-perovskite-solar-commercialization/103/web/2025/08
(7) Park, N.G., Snaith, H.J. & Miyasaka, T. "Key advances in perovskite solar cells in 2025." Nature Reviews Clean Technology 2, 6-7 (2026). https://doi.org/10.1038/s44359-025-00128-z
(8) Abdulaziz S. R. Bati, Aidan Maxwell, Zhijun Ning, Jian Xu, and Mercouri G. Kanatzidis. "Improved charge extraction in inverted perovskite solar cells with dual-site-binding ligands." Science. https://doi.org/10.1126/science.adm9474
(9) Isaiah W. Gilley, Abdulaziz S. R. Bati, Lin X. Chen, Chuying Huang, and Selengesuren Suragtkhuu. "Amidination of ligands for chemical and field-effect passivation stabilizes perovskite solar cells." Science. https://doi.org/10.1126/science.adr2091
(10) Yu Jia, Xixiang Xu, Ping Li, Zhenguo Li, and Chuanxiao Xiao. "Perovskite/silicon tandem solar cells with bilayer interface passivation." Nature. https://doi.org/10.1038/s41586-024-07997-7
(11) Anh Dinh Bui, Xuntian Zheng, Jin Xie, Hairen Tan, and Jin-Kun Wen. "Homogeneous crystallization and buried interface passivation for perovskite tandem solar modules." Science. https://doi.org/10.1126/science.adj6088
(12) Farzaneh Fadaei-Tirani, Linhua Hu, Sixia Hu, Olga A. Syzgantseva, and Jun Peng. "Dopant-additive synergism enhances perovskite solar modules." Nature. https://doi.org/10.1038/s41586-024-07228-z
(13) LONGI GREEN ENERGY TECHNOLOGY CO., LTD. Perovskite-Crystalline Silicon Tandem Cell Comprising Carrier Transport Layer Having Resistance-Increasing Nano Structure. Patent No. US-20250294952-A1. Issued Sep 17, 2025.
(14) LONGI GREEN ENERGY TECHNOLOGY CO., LTD. Tandem photovoltaic device and production method. Patent No. US-12426381-B2. Issued Sep 22, 2025.
(15) LONGI GREEN ENERGY TECHNOLOGY Co., Ltd. Perovskite solar cell and four-terminal laminated cell. Patent No. CN-223298006-U. Issued Sep 1, 2025.
(16) LONGI GREEN ENERGY TECHNOLOGY Co., Ltd. Roller coating device and method for perovskite film. Patent No. CN-121155853-A. Issued Dec 18, 2025.
(17) LONGI GREEN ENERGY TECHNOLOGY Co., Ltd. Perovskite photovoltaic cell solution spin-coating thermal annealing composite preparation system. Patent No. CN-121038562-A. Issued Nov 27, 2025.
(18) LONGI GREEN ENERGY TECHNOLOGY Co., Ltd. Perovskite/crystalline silicon laminated solar cell with full silicon wafer size and preparation method thereof. Patent No. CN-119053166-B. Issued Nov 3, 2025.
(19) LONGI GREEN ENERGY TECHNOLOGY CO., LTD. Perovskite material bypass diode and preparation method therefor, perovskite solar cell module and preparation method therefor, and photovoltaic module. Patent No. US-12471390-B2. Issued Nov 10, 2025.
(20) LONGI GREEN ENERGY TECHNOLOGY CO., LTD. Perovskite Material Bypass Diode And Preparation Method Therefor, Perovskite Solar Cell Module And Preparation Method Therefor, And Photovoltaic Module. Patent No. AU-2025213641-A1. Issued Aug 27, 2025.
(21) LONGI GREEN ENERGY TECHNOLOGY Co., Ltd. Copper powder, preparation method and related application thereof. Patent No. CN-120527061-A. Issued Aug 21, 2025.
(22) OXFORD PHOTOVOLTAICS LTD. Method for depositing perovskite material. Patent No. CN-113659081-B. Issued Aug 18, 2025.
(23) OXFORD PHOTOVOLTAICS LIMITED. Method of Depositing a Perovskite Material. Patent No. US-20250149260-A1. Issued May 7, 2025.
(24) OXFORD PHOTOVOLTAICS LIMITED. Method of depositing a perovskite material. Patent No. US-12230455-B2. Issued Feb 17, 2025.
(25) OXFORD PHOTOVOLTAICS LIMITED. Sequential Deposition of Perovskites. Patent No. US-20250268091-A1. Issued Aug 20, 2025.
(26) Oxford Photovoltaics Limited. Sequential Deposition of Perovskites. Patent No. EP-4490336-A1. Issued Jan 14, 2025.
(27) OXFORD PHOTOVOLTAICS LIMITED. Process for Making Multicomponent Perovskites. Patent No. US-20250212674-A1. Issued Jun 25, 2025.
(28) Oxford Photovoltaics Limited. Process for Making Multicomponent Perovskites. Patent No. EP-4490337-A1. Issued Jan 14, 2025.
(29) OXFORD PHOTOVOLTAICS LTD. Method for producing multicomponent perovskite. Patent No. CN-119301295-A. Issued Jan 9, 2025.
(30) OXFORD PHOTOVOLTAICS LTD. Method for forming crystalline or polycrystalline layers of organic-inorganic metal halide perovskite. Patent No. CN-112840473-B. Issued Jan 9, 2025.
(31) OXFORD PHOTOVOLTAICS LIMITED. Multijunction photovoltaic devices with metal oxynitride layer. Patent No. US-12300446-B2. Issued May 12, 2025.
(32) OXFORD PHOTOVOLTAICS LIMITED. Photovoltaic Device. Patent No. TW-202539463-A. Issued Sep 30, 2025.
(33) OXFORD PHOTOVOLTAICS LIMITED. Photovoltaic Device. Patent No. WO-2025125821-A1. Issued Jun 18, 2025.
(34) OXFORD PHOTOVOLTAICS LIMITED. Photovoltaic device comprising a metal halide perovskite and a passivating agent. Patent No. US-12288825-B2. Issued Apr 28, 2025.
(35) OXFORD PHOTOVOLTAICS LIMITED. Photovoltaic Device. Patent No. US-20250287769-A1. Issued Sep 10, 2025.
(36) OXFORD PHOTOVOLTAICS LTD. Photovoltaic Device. Patent No. JP-2025098100-A. Issued Jun 30, 2025.
(37) OXFORD PHOTOVOLTAICS LIMITED. Photovoltaic device. Patent No. US-12349530-B2. Issued Jun 30, 2025.
(38) OXFORD PHOTOVOLTAICS LIMITED. Photovoltaic device. Patent No. AU-2020274424-B2. Issued Jun 4, 2025.
(39) Jingke energy (Haining) Co., Ltd. and Jinko Solar Co., Ltd. Back contact solar cell and photovoltaic module. Patent No. CN-119521854-B. Issued Feb 5, 2026.
(40) Zhejiang Jinko Solar Co., Ltd. Back contact photovoltaic cell, preparation method thereof, laminated cell and photovoltaic module. Patent No. CN-121001460-B. Issued Feb 5, 2026.
(41) Jinko Solar Co., Ltd. and Zhejiang Jinko Solar Co., Ltd. Solar cell, method for preparing solar cell, and photovoltaic module. Patent No. US-12543403-B2. Issued Feb 2, 2026.
(42) Shangrao JinkoSolar No.3 Intelligent Manufacturing Co., Ltd. and Zhejiang Jinko Solar Co., Ltd. Back contact battery, preparation method thereof, back contact laminated battery and photovoltaic module. Patent No. CN-121463576-A. Issued Feb 2, 2026.
(43) Jinko Solar Co., Ltd. and Zhejiang Jinko Solar Co., Ltd. Solar cell, preparation method thereof and photovoltaic module. Patent No. CN-121487353-A. Issued Feb 5, 2026.
(44) ZHEJIANG JINKO SOLAR CO., LTD. Solar Cell and Photovoltaic Module. Patent No. AU-2026200184-A1. Issued Jan 28, 2026.
(45) TRINASOLAR Co., Ltd. Hole transport composite layer, perovskite solar cell and preparation method thereof. Patent No. CN-121487437-A. Issued Feb 5, 2026.
(46) TRINASOLAR Co., Ltd. Laminated battery and preparation method thereof. Patent No. CN-121487438-A. Issued Feb 5, 2026.
(47) TRINASOLAR Co., Ltd. Laminated battery and preparation method thereof. Patent No. CN-121463647-A. Issued Feb 2, 2026.
(48) TRINASOLAR Co., Ltd. Light conversion film based on benzotriazole compound, and preparation method and application thereof. Patent No. CN-121449563-A. Issued Feb 2, 2026.
(49) "GCL achieves 29.51% efficiency for perovskite-silicon tandem module." https://www.pv-magazine.com/2025/06/02/gcl-achieves-29-51-efficiency-for-perovskite-silicon-tandem-module/
(50) Yangzi Shen, Hongcai Tang, Zhichao Shen, Liyuan Han, and Yanbo Wang. "Reinforcing self-assembly of hole transport molecules for stable inverted perovskite solar cells." Science. https://doi.org/10.1126/science.adj9602
(51) Christoph J. Brabec, Xingxing Jiang, Heyi Yang, Fu Yang, and Yunxiu Shen. "Suppression of phase segregation in wide-bandgap perovskites with thiocyanate ions for perovskite/organic tandems with 25.06% efficiency." Nature Energy. https://doi.org/10.1038/s41560-024-01491-0
(52) CYBRID TECHNOLOGIES INC. and Zhejiang Saiwu Application Technology Co., Ltd. Composite packaging adhesive film and preparation method and application thereof. Patent No. CN-121471829-A. Issued Feb 5, 2026.
(53) Suzhou Guoxian Innovation Technology Co., Ltd. Buffer structure, preparation method thereof and photovoltaic module. Patent No. CN-121474300-A. Issued Feb 5, 2026.
(54) Suzhou Guoxian Innovation Technology Co., Ltd. Buffer structure, preparation method thereof and photovoltaic module. Patent No. CN-121474299-A. Issued Feb 5, 2026.
(55) Erkan Aydın, Lujia Xu, Esma Ugur, Thomas G. Allen, and Michele De Bastiani. "Pathways toward commercial perovskite/silicon tandem photovoltaics." Science. https://doi.org/10.1126/science.adh3849
(56) Chuang Yang, Yinhua Zhou, Anyi Mei, Hongwei Han, and Fengwan Guo. "Achievements, challenges, and future prospects for industrialization of perovskite solar cells." Light Science & Applications. https://doi.org/10.1038/s41377-024-01461-x
(57) Shangshang Chen, Jinsong Huang, Ruiqi Mao, Jiaqi Dai, and Chuanlu Chen. "Toward the Commercialization of Perovskite Solar Modules." Advanced Materials. https://doi.org/10.1002/adma.202307357
(58) Xianyong Zhou, Zhixin Liu, Peide Zhu, Nam-Gyu Park, and Siying Wu. "Aqueous synthesis of perovskite precursors for highly efficient perovskite solar cells." Science. https://doi.org/10.1126/science.adj7081
Reports
%20-%20Ecosystem%20%26%20Value%20Chain%20Map%20of%20the%20Industrial%20Robotic.png)
%20-%20Data%20Fingerprinting%20And%20Watermarking.png)
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)