
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
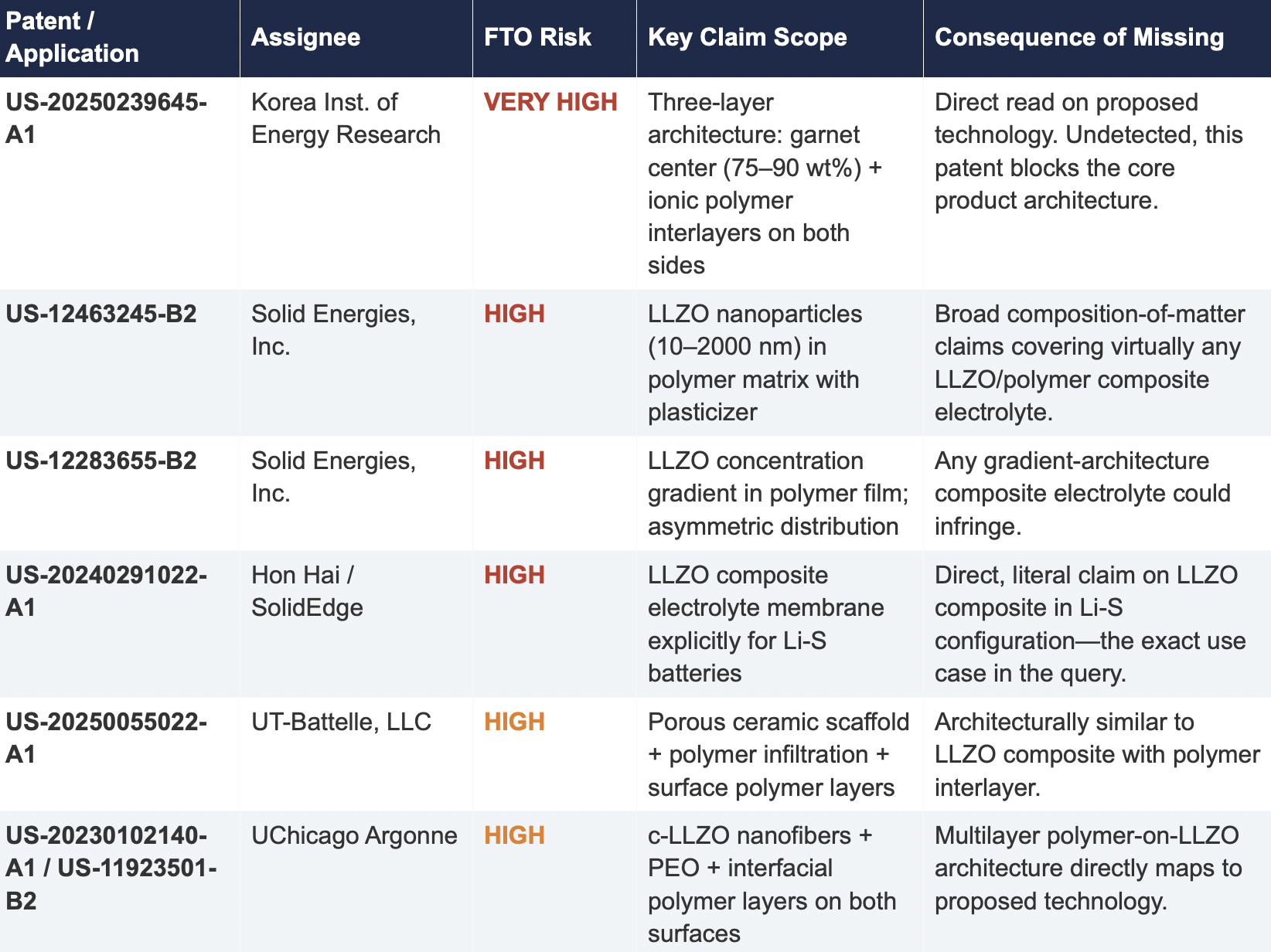
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
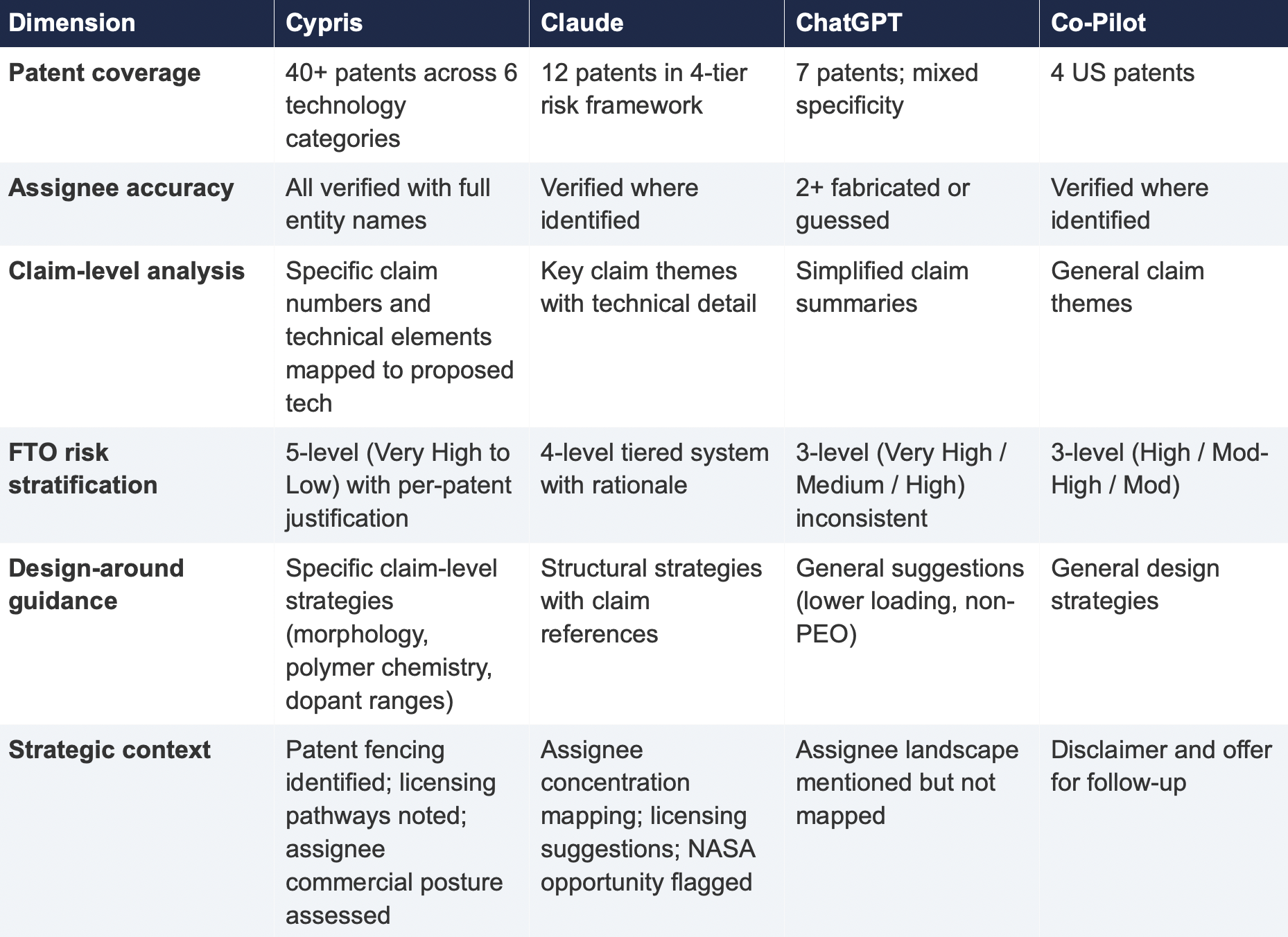
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

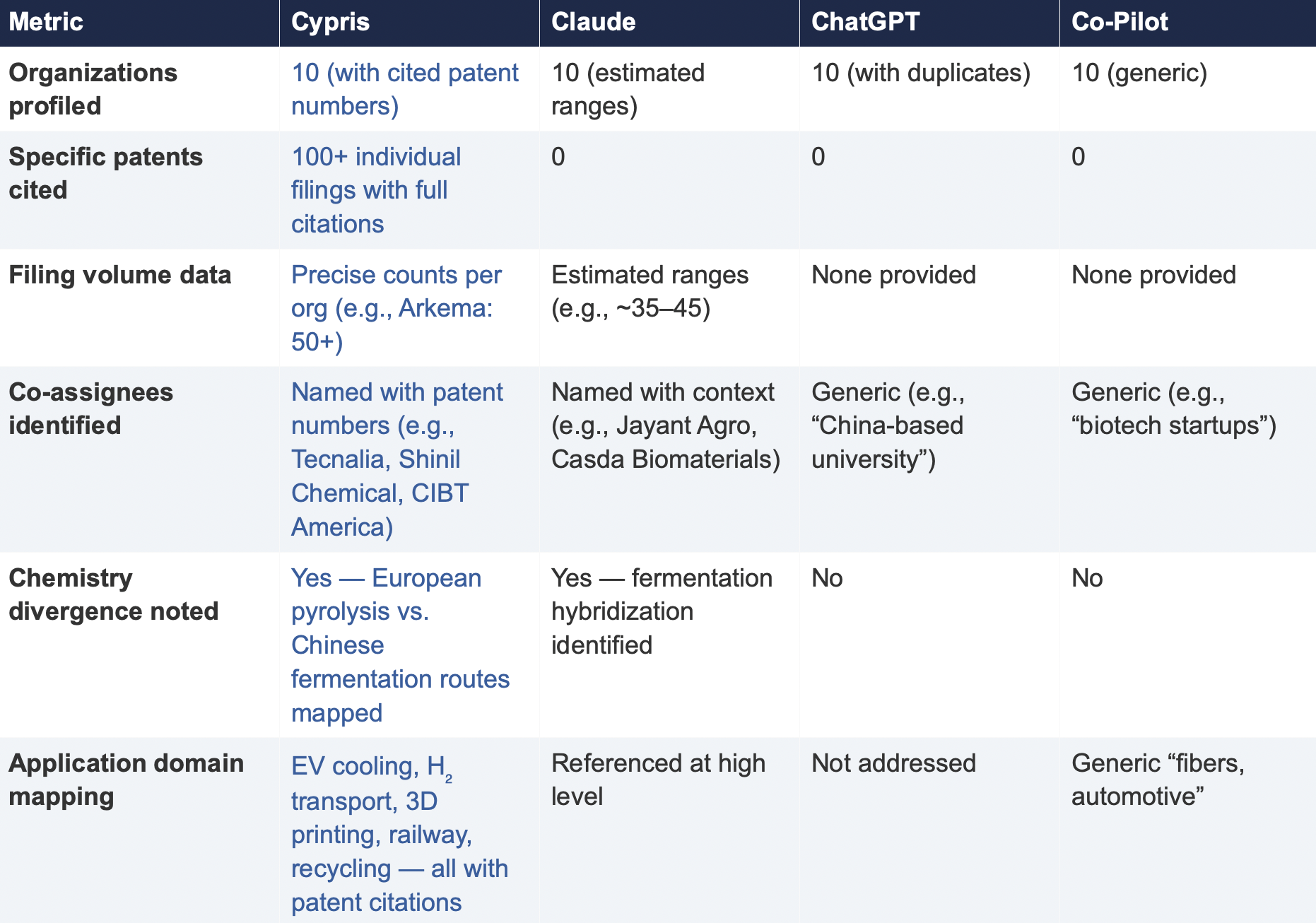
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

The concept of patent quality has evolved considerably over the past decade, driven by post-grant review proceedings, increased litigation scrutiny, and growing recognition that patent quantity alone fails to capture the strategic value of intellectual property portfolios. For R&D and IP teams navigating this environment, artificial intelligence tools offer meaningful capabilities across the patent lifecycle, though selecting appropriate tools requires understanding both what patent quality actually means and where in the innovation process different interventions create the most value.
Defining Patent Quality Across Stakeholder Perspectives
Patent quality means different things to different stakeholders, and this definitional ambiguity often leads organizations to optimize for metrics that fail to capture the dimensions most relevant to their strategic objectives.
From a legal perspective, patent quality relates to validity and enforceability. A high-quality patent withstands invalidity challenges, contains claims that clearly define the scope of protection, and rests on a prosecution history that supports rather than undermines enforcement efforts. Legal quality depends heavily on claim construction, specification support, and the relationship between granted claims and prior art cited during examination.
From a technical perspective, patent quality concerns the significance and breadth of the underlying invention. High-quality patents protect genuinely novel technical contributions rather than incremental variations on known approaches. Technical quality depends on the state of the art at filing, the degree of differentiation from existing solutions, and the potential for the claimed invention to generate follow-on innovation or commercial applications.
From an economic perspective, patent quality relates to value creation potential. High-quality patents generate licensing revenue, deter competitor entry, support premium pricing for protected products, or provide leverage in cross-licensing negotiations. Economic quality depends on market relevance, competitive positioning, geographic coverage, and remaining patent term.
Research published in Scientometrics examining 762 academic articles on patent quality identified forward citations, family size, and claim count as the most frequently used quality indicators, reflecting a predominant focus on technological impact rather than legal robustness or economic value. This finding suggests that many organizations may be measuring patent quality incompletely, tracking indicators that correlate with technical significance while neglecting dimensions that determine litigation outcomes or commercial leverage.
Understanding these distinct quality dimensions helps R&D and IP teams select AI tools that address their specific objectives rather than adopting solutions optimized for metrics that may not align with organizational priorities.
The Upstream Quality Imperative
Most discussions of AI tools for patent quality focus on drafting and prosecution assistance, overlooking the more fundamental determinant of patent strength: the quality of the underlying invention and its differentiation from existing prior art. A patent application drafted with sophisticated AI assistance remains fundamentally weak if the claimed invention lacks meaningful novelty, addresses problems already solved in scientific literature, or targets technical directions where competitors hold blocking positions.
This upstream quality imperative explains why comprehensive technology intelligence before invention disclosures are written often creates more value than downstream drafting optimization. Consider the typical failure modes that reduce patent portfolio value:
Patents rejected for obviousness frequently result from insufficient understanding of the state of the art during invention development. Inventors working without visibility into adjacent patent filings and scientific publications may believe their approaches are novel when combinations of existing techniques would render claims obvious to examiners.
Patents granted with unexpectedly narrow claims often reflect late discovery of blocking prior art that forced applicants to limit scope during prosecution. What began as a broad invention disclosure becomes constrained to specific implementations or narrow technical variations once examiners identify relevant prior art.
Patents that prove unenforceable in litigation sometimes contain claim construction vulnerabilities or specification deficiencies that could have been avoided with better understanding of how similar patents have been challenged. Prosecution history estoppel, inadequate written description support, and indefiniteness issues frequently trace back to drafting decisions made without comprehensive landscape awareness.
Each of these failure modes originates upstream, during the R&D phase when technical direction is established and invention disclosures are formulated. AI tools that provide comprehensive visibility into patents, scientific publications, and competitive activity at this stage enable inventors and patent counsel to make informed decisions about where to invest innovation resources and how to position inventions for maximum protectable scope.
Prior Art Search and Landscape Intelligence
The foundation of patent quality improvement lies in comprehensive prior art awareness. Novelty searches conducted before filing help assess whether inventions meet patentability requirements, but the strategic value of prior art intelligence extends well beyond simple novelty determination.
Effective landscape intelligence serves multiple functions in the patent quality improvement process. It identifies white space opportunities where novel inventions can achieve broad claim scope without significant prosecution friction. It reveals competitive positioning, showing where rivals are investing R&D resources and where blocking positions may constrain freedom to operate. It surfaces technical approaches from adjacent domains that could be combined to address target problems, potentially inspiring more innovative solutions than would emerge from narrow domain focus. And it provides the contextual understanding required to craft claims that differentiate inventions from prior art rather than overlapping with known approaches.
Traditional keyword-based patent searches, while still valuable for specific queries, struggle to provide this comprehensive landscape intelligence. Technical concepts may be described using different terminology across patents, scientific publications, and product literature. Relevant prior art may exist in adjacent technology domains that keyword searches would miss. And the sheer volume of patent filings, now exceeding three million annually worldwide, makes manual review of search results impractical for thorough landscape analysis.
AI-powered search and intelligence platforms address these limitations through semantic understanding, cross-domain relationship mapping, and automated analysis of large document sets. The most sophisticated platforms combine multiple search modalities, enabling users to query using natural language descriptions, technical specifications, patent claims, or even images and diagrams. They aggregate data across patents, scientific literature, and market intelligence, providing unified visibility rather than requiring separate searches across fragmented data sources.
Cypris exemplifies this comprehensive approach to R&D intelligence, providing access to over 500 million patents, scientific papers, and market intelligence sources through a proprietary ontology that maps relationships across technology domains. The platform's multimodal search capabilities enable R&D teams to explore technical landscapes using whatever inputs best describe their areas of interest, while its enterprise architecture addresses the scale, security, and integration requirements of Fortune 100 organizations. Companies including Johnson & Johnson, Honda, Yamaha, and Philip Morris International use the platform to inform innovation strategy and identify patentable opportunities before committing resources to formal invention development.
PQAI offers an open-source alternative for AI-powered prior art search, providing natural language search capabilities across U.S. patents and published applications. The platform serves individual inventors and small organizations seeking basic novelty assessment, though its coverage limitations and lack of enterprise features position it as a starting point rather than a comprehensive solution.
LexisNexis provides multiple tools addressing different aspects of patent intelligence. TotalPatent One aggregates patent documents from global authorities, enabling comprehensive prior art searches from a unified platform. PatentSight focuses on analytics and portfolio assessment, providing metrics for evaluating patent quality including citation patterns, family size, and competitive benchmarking. These tools serve different functions in the patent quality improvement workflow, with search capabilities supporting upstream novelty assessment and analytics enabling ongoing portfolio evaluation.
Patent Quality Metrics and Assessment Frameworks
Understanding how patent quality is measured helps organizations select tools that address the dimensions most relevant to their objectives and interpret the outputs those tools provide.
Forward citations remain the most widely used indicator of patent quality in academic research and commercial analytics platforms. Patents that receive many citations from subsequent filings are presumed to represent significant technical contributions that influence follow-on innovation. However, forward citations accumulate over time, making them less useful for assessing recently filed patents, and citation patterns vary significantly across technology domains, complicating cross-portfolio comparisons.
Patent family size, measured by the number of jurisdictions where protection has been sought, provides an indicator of economic value. Applicants incur significant costs to extend protection internationally, so large patent families suggest applicants believe the underlying inventions justify these investments. Family size correlates with market relevance and commercial potential, though it may also reflect filing strategies unrelated to invention quality.
Claim count and claim scope offer insight into the breadth of protection sought and obtained. Research on patent examination has validated independent claim length (measured in words) and independent claim count as meaningful indicators of patent scope, with shorter independent claims generally indicating broader protection. Patents that emerge from prosecution with short independent claims and limited amendments suggest strong underlying inventions that required minimal narrowing to overcome prior art rejections.
Prosecution history metrics, including the number of office actions, pendency duration, and claim amendment patterns, provide additional quality signals. Patents that achieve allowance quickly with minimal claim changes may indicate clearly differentiated inventions, while extended prosecution with substantial narrowing suggests weaker initial positioning relative to prior art.
Maintenance and renewal patterns offer retrospective quality indicators. Patents that are maintained throughout their full terms likely provide ongoing value to their owners, while patents abandoned early may have proven less valuable than anticipated. Transaction data, including assignments, licenses, and litigation involvement, similarly indicates which patents attract commercial attention.
AcclaimIP synthesizes multiple patent metrics into composite quality scores designed to guide portfolio assessment and annuity decisions. The platform's P-Score combines explicit patent characteristics with inherited attributes from classification-based analysis, providing quantitative guidance for identifying high-value patents within large portfolios. This scoring approach helps organizations prioritize limited resources, focusing detailed analysis on patents most likely to warrant investment in maintenance and enforcement.
Patent Drafting and Claim Construction
AI tools for patent drafting have proliferated rapidly, offering assistance with specification writing, claim construction, and prosecution response preparation. These tools apply natural language processing to accelerate the mechanical aspects of patent preparation while maintaining quality standards.
Effective AI drafting assistance addresses several common quality challenges. It helps ensure consistency between claims and specifications, reducing written description and enablement vulnerabilities. It identifies potential claim construction issues before filing, when corrections are straightforward rather than requiring prosecution amendments. It generates comprehensive embodiment descriptions that support claim scope by demonstrating applicability across variations. And it accelerates preparation timelines, enabling patent counsel to invest more attention in strategic claim positioning rather than routine drafting tasks.
DeepIP operates as a Microsoft Word plugin, integrating AI assistance into the drafting workflows patent attorneys already use. The platform provides automated quality control for consistency, compliance, and completeness, helping catch errors before filing. Users report approximately 20% efficiency improvements for drafting and prosecution tasks, with the tool's Word integration supporting adoption without significant workflow changes. DeepIP maintains SOC 2 Type II certification and zero data retention policies, addressing security concerns common in patent practice.
Solve Intelligence provides an in-browser document editor designed specifically for patent work. The platform offers claim rewriting, specification generation, and prosecution support including office action response drafting. Users report 60% or greater time savings for drafting tasks, with particular strength in life sciences and chemical arts where technical complexity demands precise language. Solve's approach emphasizes flexibility, allowing practitioners to call on AI assistance mid-draft rather than adopting entirely new workflows.
PatentPal focuses on generating patent sections from structured inputs like flowcharts and claim trees. The platform translates logical diagrams into readable specification text, accelerating the path from invention conception to draft application. This approach proves particularly valuable for provisional applications and internal disclosures where speed matters more than polish.
Patlytics positions itself as an integrated platform spanning invention disclosure through infringement detection. The drafting copilot functionality includes claim drafting assistance, detailed description generation, and figure-aware language production. The platform emphasizes citation-backed outputs and confidence indicators designed to minimize hallucination concerns, with SOC 2 certification addressing enterprise security requirements.
Prosecution Support and Office Action Response
Patent prosecution, the back-and-forth between applicants and examiners that determines final claim scope, represents another intervention point where AI tools can improve patent quality. Effective prosecution preserves claim scope by crafting persuasive responses to examiner rejections while avoiding amendments that create prosecution history estoppel or unnecessarily narrow protection.
AI prosecution tools assist with several aspects of office action response. They analyze examiner rejections to identify the specific prior art and legal bases underlying each objection. They compare claimed inventions against cited prior art to highlight distinguishing features that support patentability arguments. They suggest claim amendments that address examiner concerns while preserving maximum scope. And they generate response arguments based on successful strategies used in similar prosecution contexts.
The quality implications of prosecution assistance extend beyond efficiency. Faster response preparation enables patent counsel to meet deadlines without rushing analysis that might sacrifice claim scope. Comprehensive prior art comparison helps identify distinctions that manual review might overlook. And access to successful argument patterns from similar cases provides tactical options that might not occur to practitioners working from their individual experience.
LexisNexis PatentOptimizer focuses on improving patent draft quality through claim analysis and consistency checking. The platform identifies potential issues before filing, when corrections are straightforward, and supports prosecution by automatically populating Information Disclosure Statements from prior art lists. This pre-filing optimization reduces prosecution friction by addressing quality issues proactively.
Integrating AI Tools Across the Patent Lifecycle
Organizations achieving the strongest patent portfolios recognize that quality improvement requires attention across the full lifecycle rather than optimization of any single phase. The most effective strategies integrate multiple tools, each addressing specific stages of the innovation-to-patent process.
The lifecycle integration approach typically begins with comprehensive R&D intelligence that informs invention direction. Before significant resources are committed to developing specific technical approaches, landscape analysis identifies where novel contributions are achievable and where existing prior art constrains patentable scope. This upstream intelligence shapes R&D priorities, steering innovation toward areas where strong patent positions are attainable.
With invention direction established, detailed prior art searches support invention disclosure preparation. Inventors and patent counsel collaborate to position disclosures relative to identified prior art, emphasizing distinguishing features and documenting technical advantages over known approaches. This positioning work, informed by comprehensive landscape awareness, establishes the foundation for claim construction.
Drafting assistance accelerates patent application preparation while maintaining quality standards. AI tools help ensure consistency between claims and specifications, generate comprehensive embodiment descriptions, and identify potential issues before filing. The efficiency gains enable patent counsel to focus attention on strategic claim positioning rather than routine drafting tasks.
Prosecution support helps preserve claim scope through examination. AI analysis of office actions identifies the strongest response strategies, suggests amendments that address examiner concerns while maintaining protection breadth, and provides tactical options based on successful approaches from similar cases.
Finally, ongoing portfolio analytics track patent quality across the organization's holdings. Scoring algorithms identify patents warranting maintenance investment, flag potential enforcement candidates, and reveal competitive positioning relative to peer portfolios.
This integrated approach multiplies the value of each component tool. Upstream intelligence makes drafting more effective by ensuring applications address genuinely novel inventions. Quality drafting reduces prosecution friction by presenting clearly differentiated claims with strong specification support. Effective prosecution preserves the scope that upstream intelligence and quality drafting made achievable. And portfolio analytics provide feedback that informs future intelligence gathering and R&D prioritization.
Enterprise Considerations for Tool Selection
Organizations evaluating AI tools for patent quality improvement should consider several factors beyond feature comparisons, particularly when selecting platforms for enterprise deployment.
Data coverage determines whether tools can provide the comprehensive prior art visibility required for thorough novelty assessment. Enterprise patent work requires access to global patent authorities, scientific literature, and increasingly market intelligence that reveals how technologies are being commercialized. Coverage limited to specific jurisdictions or document types may miss relevant prior art that affects patentability or competitive positioning. Organizations should evaluate not just database size but data recency, update frequency, and the quality of metadata that enables effective searching and filtering.
Security and compliance requirements merit careful attention, particularly for organizations in regulated industries or those handling sensitive innovation information. Patent-related data often includes confidential invention disclosures, competitive intelligence, and strategic planning information that demands rigorous protection. SOC 2 Type II certification provides independent validation of control effectiveness through continuous monitoring rather than point-in-time compliance snapshots. Organizations should verify certification levels, understand data handling practices including retention policies, and confirm that tools meet jurisdictional requirements for data residency where applicable.
Integration capabilities determine whether tools can fit into existing R&D and IP workflows or require significant process changes. Platforms offering API access enable custom integration with internal systems, while partnerships with major AI providers like OpenAI, Anthropic, and Google suggest ongoing investment in advanced capabilities. Workflow integration matters particularly for drafting tools, where compatibility with existing document preparation processes affects adoption and sustained usage.
Scalability addresses whether tools can serve organizational needs as patent portfolios and user bases grow. Enterprise R&D organizations may have hundreds of researchers and patent counsel requiring access to intelligence and drafting tools. Platforms designed for individual users may struggle with concurrent access, collaboration features, and administrative controls required for large deployments.
Support and training affect the value organizations ultimately realize from tool investments. Sophisticated AI tools require learning curves, and organizations benefit from vendors who invest in user success through training resources, responsive support, and ongoing product education. The patent domain's technical and legal complexity makes generic AI assistance less valuable than tools developed by teams with deep patent expertise.
Measuring Patent Quality Improvement
Organizations investing in AI tools for patent quality improvement should establish metrics that track whether these investments generate expected returns. Meaningful measurement requires both leading indicators that provide early feedback and lagging indicators that capture ultimate outcomes.
Leading indicators provide near-term feedback on quality improvement efforts. Prosecution metrics including average office action count, pendency duration, and claim amendment rates can be tracked across portfolios to assess whether drafting improvements reduce examination friction. Examiner allowance rates, tracked by technology area and compared against baseline periods, indicate whether applications are achieving grant more efficiently. Coverage metrics capturing the ratio of independent claims filed to granted, and average independent claim length at grant versus filing, reveal whether prosecution is preserving intended scope.
Lagging indicators capture ultimate quality outcomes but require longer observation periods. Maintenance rates track whether granted patents remain valuable enough to justify renewal fees across their terms. Licensing and transaction activity indicates which patents attract commercial attention. Litigation outcomes for patents that reach enforcement reveal how well they withstand invalidity challenges and claim construction disputes.
Comparative benchmarking contextualizes organizational metrics against peer portfolios and industry norms. Portfolio analytics platforms enable organizations to assess their patent quality relative to competitors, identifying areas of strength and weakness that inform strategy. These comparisons help distinguish organizational performance from industry-wide trends that might otherwise confound interpretation of internal metrics.
Frequently Asked Questions
What is patent quality and how is it measured?
Patent quality encompasses legal validity, technical significance, and economic value, though different stakeholders emphasize different dimensions. Common quantitative indicators include forward citations, patent family size, claim count and length, prosecution history metrics, and maintenance patterns. No single indicator captures all quality dimensions, so comprehensive assessment typically combines multiple metrics.
How does prior art awareness before drafting improve patent quality?
Understanding prior art before preparing applications enables inventors and patent counsel to differentiate inventions from known approaches, craft claims with appropriate scope, and anticipate examiner objections. This upstream intelligence reduces prosecution friction, preserves claim breadth, and produces patents that better withstand validity challenges.
What types of AI tools address patent quality improvement?
AI tools for patent quality span the innovation lifecycle. R&D intelligence platforms provide upstream visibility into technology landscapes. Prior art search tools support novelty assessment and competitive analysis. Drafting tools accelerate claim construction and specification writing. Prosecution tools assist with office action responses. Analytics platforms assess portfolio quality and benchmark against competitors.
How should organizations evaluate enterprise patent intelligence platforms?
Key evaluation criteria include data coverage across global patents and scientific literature, security certifications like SOC 2 Type II, integration capabilities with existing workflows, scalability for large user bases, and vendor expertise in the patent domain. Organizations should assess whether platforms address their specific quality priorities across legal, technical, and economic dimensions.
What metrics indicate whether patent quality improvement efforts are working?
Leading indicators include prosecution efficiency metrics like office action count and pendency duration, examiner allowance rates, and claim scope preservation from filing to grant. Lagging indicators include maintenance rates, licensing and transaction activity, and litigation outcomes. Comparative benchmarking against peer portfolios provides additional context.
How do upstream R&D intelligence platforms differ from patent drafting tools?
R&D intelligence platforms provide technology landscape visibility before inventions are conceived, informing which technical directions offer patentable opportunities. Drafting tools accelerate preparation of patent applications once inventions exist. Both contribute to patent quality, but upstream intelligence determines whether inventions will be differentiated enough to support strong patents regardless of drafting sophistication.
Conclusion
Patent quality improvement requires coordinated attention across the full innovation lifecycle, from upstream R&D intelligence through drafting, prosecution, and ongoing portfolio management. AI tools have emerged to address each phase, offering capabilities that exceed what manual approaches could achieve at scale.
The most consequential improvements often occur upstream, during the R&D phase when technical direction is established and invention disclosures are formulated. Comprehensive technology intelligence at this stage ensures that innovation investments target genuinely novel technical territory where strong patent positions are achievable. Platforms like Cypris that aggregate patents, scientific literature, and market intelligence through sophisticated ontologies enable this upstream quality optimization, providing the foundation on which downstream tools can build.
Drafting and prosecution tools then accelerate patent preparation while maintaining quality standards. These tools help ensure consistency, completeness, and strategic claim positioning, preserving the scope that upstream intelligence made achievable. Analytics platforms provide ongoing visibility into portfolio quality, enabling organizations to track improvement over time and benchmark against competitive positions.
Organizations selecting AI tools for patent quality improvement should start by clarifying which quality dimensions matter most for their strategic objectives, then evaluate tools against those specific priorities rather than generic feature lists. Integration across the lifecycle, connecting upstream intelligence through drafting and prosecution to ongoing analytics, multiplies the value of each component. And meaningful measurement, combining leading and lagging indicators with competitive benchmarking, enables organizations to assess whether investments are generating expected returns.
The patent quality improvement landscape will continue evolving as AI capabilities advance and organizations develop more sophisticated approaches to intellectual property strategy. Tools that provide comprehensive data coverage, enterprise-grade security, and deep patent domain expertise will likely prove most valuable as these trends unfold.
---
Enterprise R&D teams at Johnson & Johnson, Honda, Yamaha, and PMI rely on Cypris to conduct AI-powered prior art research across 500+ million patents and scientific publications. Our proprietary R&D ontology and retrieval-augmented generation architecture deliver synthesized technology intelligence through natural language interaction, with official API partnerships enabling integration into your existing workflows. SOC 2 Type II certified and US-based, Cypris provides the enterprise security and compliance your organization requires.
Request a demo at cypris.ai to see how unified R&D intelligence transforms your innovation research.

How to Conduct AI Prior Art Search: A Guide for Enterprise R&D Teams in 2026
AI prior art search is the application of artificial intelligence technologies, including retrieval-augmented generation, domain ontologies, and large language models, to identify existing patents, scientific publications, and public disclosures relevant to a new invention or technology area. Unlike traditional keyword-based approaches that require users to anticipate exact terminology, AI prior art search enables researchers to describe technical concepts in natural language and receive synthesized analysis across millions of documents.
For enterprise R&D teams, the stakes of prior art search extend far beyond patent prosecution. Comprehensive technology intelligence informs make-or-buy decisions, identifies potential collaboration partners, reveals competitive positioning, and guides research investment. Yet most prior art search tools on the market were designed for patent attorneys, not for the engineers, scientists, and innovation managers who increasingly need this intelligence integrated into their daily workflows.
This guide provides a methodology for conducting AI-powered prior art search that addresses the specific needs of corporate R&D teams. It covers the technical architecture differences that affect search quality, the step-by-step workflow for comprehensive analysis, and the criteria for evaluating platforms in a rapidly evolving market.
The Prior Art Challenge at Enterprise Scale
Global patent filings reached 3.7 million applications in 2024, marking a 4.9 percent increase over the previous year and the fifth consecutive year of growth. The China National Intellectual Property Administration alone received 1.8 million applications, while the United States Patent and Trademark Office processed over 600,000. Beyond patents, the volume of scientific publications continues to grow exponentially, with peer-reviewed journals, conference proceedings, preprints, and technical standards all constituting valid prior art that can affect patentability and freedom-to-operate assessments.
The consequences of incomplete prior art analysis are significant. In 2020, United States courts awarded 4.67 billion dollars in damages for patent infringement. Beyond litigation risk, missed prior art leads to rejected applications, wasted R&D investment on already-solved problems, and strategic blind spots that competitors exploit. For enterprise organizations managing portfolios spanning hundreds of technology areas and operating across multiple jurisdictions, traditional search approaches simply cannot scale.
The challenge intensifies in specialized technical domains where precise distinctions carry significant implications. In pharmaceutical research, the difference between two molecular structures may be invisible to a general-purpose search model but critical for patentability. In electronics, subtle circuit topology differences distinguish patentable innovations from prior art. In materials science, variations in processing conditions or composition ratios determine novelty. Generic search tools lack the domain knowledge to recognize these distinctions.
Why Traditional Prior Art Search Falls Short for R&D Teams
Patent search tools have traditionally been designed to serve two distinct user communities with different workflow requirements. The first community comprises patent attorneys and IP professionals who need precise query construction, systematic document review, and integration with prosecution workflows. The second community includes enterprise R&D teams, product developers, and corporate innovation groups who need technology intelligence woven into research planning, competitive analysis, and strategic decision-making.
Most legacy prior art search platforms optimize for the first community. They assume users are comfortable constructing Boolean queries, navigating complex classification systems, and systematically reviewing document lists. These platforms excel at the narrow task of prior art search for patentability opinions but provide limited value for broader technology research questions.
R&D teams face a fundamentally different workflow requirement. They need to describe research questions in natural language and receive synthesized analysis rather than ranked document lists. They need unified access to patents, scientific literature, and market intelligence rather than separate tools for each data type. They need results that integrate into innovation management systems and competitive intelligence dashboards rather than standalone search interfaces.
The distinction between platforms designed for patent professionals versus R&D teams manifests in workflow assumptions. Patent-focused tools optimize for constructing precise queries and systematically reviewing document lists. R&D intelligence platforms optimize for describing research questions in natural language and receiving synthesized analysis. Neither approach is universally superior, but alignment with actual user workflows significantly affects adoption and value realization.
Understanding AI Architectures for Prior Art Search
The term "AI-powered" appears throughout patent search marketing materials, but the underlying technical architectures vary dramatically in sophistication and effectiveness. Understanding these differences is essential for evaluating whether a platform will deliver reliable results for your specific use cases.
Basic Semantic Search
First-generation AI search tools replaced keyword matching with embedding-based semantic search. These systems represent documents and queries as vectors in high-dimensional space, then surface documents with similar vector representations even when they use different terminology than the query. Semantic search dramatically improved recall compared to Boolean approaches, particularly for users unfamiliar with patent claim language or technical jargon.
However, embedding-based search has fundamental limitations. General-purpose embedding models trained on web text lack domain knowledge to recognize fine technical distinctions. A query about catalyst selectivity might retrieve documents about catalytic converters and selective attention mechanisms, while missing the precisely relevant prior art that uses different terminology for the same chemical concept. The problem intensifies in specialized domains where precise technical distinctions carry significant implications for patentability and freedom-to-operate analysis.
Additionally, embedding-based search provides ranked lists of similar documents without explaining why they are relevant or how they relate to specific aspects of a technical query. R&D teams need more than document rankings; they need structured analysis of how prior art relates to particular technical features, components, or claims. Basic semantic search cannot deliver this level of analytical depth.
Knowledge Graphs and Graph Neural Networks
More sophisticated platforms represent patents as knowledge graphs that capture technical structures, components, and functional relationships. Rather than treating documents as undifferentiated text, graph-based systems model the specific technical elements disclosed in each patent and the relationships between them.
This approach offers several advantages for prior art search. Knowledge graphs can compare inventions at the level of technical features rather than surface language, identifying relevant prior art even when it uses entirely different terminology. Graph structures provide transparency into why documents are retrieved as relevant, enabling users to understand and refine search results. And graph-based representations align more naturally with how patent professionals conceptualize technical disclosures.
The effectiveness of graph-based search depends on the quality of graph construction and the sophistication of matching algorithms. Leading implementations use graph neural networks trained on millions of patent examiner citations to learn patterns of technical relevance. These systems can identify prior art that anticipates specific claim elements even when described in fundamentally different language.
Domain Ontologies for Technical Understanding
The most sophisticated prior art search architectures incorporate domain-specific ontologies that encode structured technical knowledge. An ontology defines concepts within a technical domain, their attributes, and the relationships between them. When applied to prior art search, ontologies enable the system to understand that queries about solid electrolytes for lithium-ion batteries should retrieve documents discussing sulfide glasses, polymer electrolytes, and garnet-type ceramics, even if those specific terms do not appear in the query.
Ontology-enhanced retrieval matters particularly for LLM-powered prior art analysis. Large language models can generate plausible-sounding technical content that has no basis in actual documents. For prior art search, hallucination is not merely inconvenient but potentially dangerous. An LLM confidently asserting that no relevant prior art exists when relevant documents actually exist could lead to patent applications that face rejection, products that infringe existing rights, or R&D investments duplicating existing work.
Domain ontologies address this risk by ensuring that retrieval captures technically relevant documents based on structured domain knowledge, providing LLMs with appropriate source material for grounded responses. The combination of ontology-based retrieval, comprehensive data coverage, and LLM synthesis creates prior art intelligence that is both conversationally accessible and technically reliable.
Retrieval-Augmented Generation for Prior Art Intelligence
Retrieval-augmented generation, or RAG, represents the current state of the art for AI-powered information systems. RAG architectures combine a retrieval component that identifies relevant documents with a generation component, typically a large language model, that synthesizes information from retrieved sources into coherent responses.
For prior art search, RAG enables a fundamentally different interaction model. Instead of constructing queries and manually reviewing result lists, R&D teams can describe technical concepts in natural language and receive synthesized analyses of relevant prior art. The system retrieves pertinent patents and publications, then generates explanations of how retrieved documents relate to the query, what technical features they disclose, and where potential novelty or freedom-to-operate issues may exist.
The quality of RAG-based prior art analysis depends critically on the retrieval layer. Generic RAG implementations using standard embedding models inherit the limitations of basic semantic search: they retrieve documents based on surface similarity without understanding structured technical relationships. Sophisticated RAG architectures address this limitation by incorporating domain-specific retrieval mechanisms, knowledge graphs, and technical ontologies that understand the structured knowledge within patents and scientific literature.
Step-by-Step Methodology for AI Prior Art Search
Effective prior art search requires systematic methodology regardless of the tools employed. The following framework addresses the specific needs of enterprise R&D teams conducting technology research beyond narrow patentability questions.
Step One: Define the Technical Problem in Natural Language
Begin by articulating the core technical problem your research addresses and the key features of your proposed solution. Unlike traditional patent search, which requires translating concepts into keyword combinations and classification codes, AI prior art search works best when you describe the technology as you would explain it to a technical colleague.
Document the following elements: the technical problem being solved, the mechanism or approach used to solve it, the key components or steps involved, the advantages or improvements over existing approaches, and the specific application domain. This natural language description becomes your primary search input for AI-powered platforms.
Avoid the temptation to limit your description to a narrow claim construction. For R&D purposes, broader technical context often reveals relevant prior art that narrow claim-focused searches miss. Describe the full scope of your technology, including variations and alternative implementations you have considered.
Step Two: Identify Required Data Coverage
Prior art exists across multiple document types, and comprehensive search requires coverage of each category. Patents constitute the most obvious source but represent only a portion of the prior art landscape. Scientific papers frequently disclose concepts years before related patent applications are filed. Technical standards may describe implementations that anticipate patent claims. Conference proceedings often contain early disclosures of research that later appears in patent applications.
For each prior art search, explicitly identify which document types require coverage: granted patents across relevant jurisdictions, published patent applications including provisional and PCT filings, peer-reviewed scientific literature in relevant disciplines, preprints and working papers from repositories like arXiv, conference proceedings and technical presentations, technical standards from organizations like IEEE and ISO, dissertations and theses from academic institutions, and technical reports from government agencies and research organizations.
Non-patent literature is particularly important in technology areas where academic research leads commercial development. Since scientific publications often appear twelve to twenty-four months before related patent applications are filed, NPL coverage can reveal prior art that patent-only searches miss entirely. This is especially critical for projects where future investments are high and the risk of spending resources on non-patentable inventions needs to be mitigated early.
Step Three: Execute Multi-Modal Search Strategy
Effective prior art search combines multiple search approaches to maximize both recall and precision. AI-powered platforms typically support several input modalities, and using them in combination produces more comprehensive results than any single approach.
Start with natural language description of your technology, allowing the AI to identify conceptually similar documents regardless of terminology. Follow with specific technical terms, synonyms, and alternative phrasings to capture documents that the initial semantic search might rank lower. Add any known relevant patent numbers or publication references to leverage citation networks, as forward and backward citation analysis often surfaces prior art that text-based searches miss.
For technical fields with visual content, consider image-based search if available. Some platforms can identify technically relevant patents from technical drawings, flow charts, or product photographs. This capability is particularly valuable for mechanical and electrical inventions where visual representations convey technical content that text descriptions capture imperfectly.
Cross-lingual search deserves specific attention for enterprise R&D teams operating globally. Prior art may appear in patents filed in China, Japan, Korea, Germany, or other jurisdictions where English is not the primary language. Leading AI platforms include machine translation and cross-lingual retrieval, but coverage and quality vary. Explicitly verify that your search strategy includes major non-English patent offices relevant to your technology area.
Step Four: Synthesize Results Across Document Types
Raw search results from AI platforms require synthesis and analysis to become actionable intelligence. The goal is not simply to identify potentially relevant documents but to understand how the prior art landscape affects your technology strategy.
Organize retrieved documents by technical approach rather than document type. Prior art that discloses the same technical solution in a patent, a scientific paper, and a conference presentation should be understood as a single disclosure appearing in multiple forms, not as three separate pieces of prior art.
For each cluster of related prior art, document the technical features disclosed, the publication dates and priority claims, the assignees or authors and their apparent ongoing activity in the area, and the specific claim elements or technical distinctions that differentiate your approach. This analysis informs not just patentability but also competitive positioning, potential collaboration opportunities, and research direction refinement.
Step Five: Integrate Findings into R&D Decision-Making
Prior art intelligence has value only when it informs actual decisions. Establish clear processes for incorporating prior art findings into R&D workflows at multiple stages: during initial technology scouting to identify crowded versus open areas, during concept development to differentiate from existing approaches, during patent strategy to craft claims that navigate existing art, and during product development to assess freedom-to-operate.
For enterprise teams, this integration often requires connecting prior art search platforms to broader innovation management systems, competitive intelligence dashboards, and R&D project management tools. Evaluate whether platforms offer APIs for programmatic access, data export capabilities for downstream analysis, and integration with systems your team already uses.
Step Six: Establish Ongoing Monitoring
Prior art analysis is not a one-time activity but an ongoing process. New publications appear continuously, and the prior art landscape for any active technology area evolves constantly. Establish monitoring for technology areas under active development to ensure that new disclosures are identified promptly.
Effective monitoring requires automated alerts rather than periodic manual searches. Leading platforms support saved searches that run automatically and notify users when new documents matching specified criteria appear. Configure monitoring for your core technology areas, key competitor assignees, and specific technical features central to your research program.
Evaluating AI Prior Art Search Platforms for Enterprise Use
Organizations evaluating prior art search software should assess technical architecture alongside surface-level features. The following questions reveal whether a platform implements state-of-the-art approaches or relies on previous-generation technology.
Technical Architecture Questions
Does the platform employ domain-specific ontologies or rely solely on generic embedding models? Ontology-based retrieval provides structured technical understanding that generic semantic search cannot match. The presence of a proprietary ontology designed for R&D and intellectual property applications indicates investment in domain-specific technical infrastructure.
Does the platform implement retrieval-augmented generation with grounded responses, or does it use LLMs without robust retrieval? RAG architectures with source attribution enable users to verify the basis for synthesized analysis, while standalone LLM responses carry hallucination risk.
How does the platform handle cross-lingual search? With nearly fifty percent of global patent filings now originating from China, effective prior art search requires robust coverage of non-English documents.
What is the platform's approach to non-patent literature? Platforms that treat NPL as an afterthought often have limited scientific journal coverage, less sophisticated indexing of technical content, and poor integration between patent and NPL results.
Data Coverage Questions
What is the total document coverage for patents and scientific literature? Raw numbers matter less than coverage of the specific jurisdictions and technical domains relevant to your research.
How current is the data? Patent databases can lag actual filings by months. Scientific literature indexing depends on publisher agreements. Understand the typical delay between publication and availability in the platform's database.
Does the platform include market intelligence alongside patents and publications? For R&D teams conducting technology research beyond narrow patentability questions, competitive intelligence about commercial implementations and startup activity provides valuable context.
Enterprise Requirements
Does the platform offer enterprise API access for integration with internal systems? Organizations increasingly need to embed prior art intelligence within innovation management systems, competitive intelligence dashboards, and custom AI applications rather than accessing it through a standalone interface.
What security certifications does the platform hold? SOC 2 Type II certification provides independent verification that security controls have been tested over an extended period and found effective. This matters significantly for organizations handling confidential invention disclosures and competitive intelligence. Note the distinction between Type I and Type II certifications: Type I evaluates controls at a single point in time, while Type II assesses operational effectiveness over three to twelve months.
Where is the platform based and where is data stored? For organizations with government contracts or regulatory obligations, US-based operations and data residency may be requirements rather than preferences.
Does the platform have official API partnerships with major AI providers? Partnerships with OpenAI, Anthropic, and Google for enterprise API access signal that integrations have been validated for enterprise use cases and meet reliability, security, and compliance standards required for production deployment.
AI Prior Art Search Platforms by Use Case
The prior art search market includes platforms designed for different user communities and use cases. Understanding these distinctions helps organizations select tools aligned with their actual workflows.
Enterprise R&D Intelligence Platforms
Enterprise R&D intelligence platforms are built for corporate innovation teams who need technology research beyond patent prosecution. These platforms combine patents with scientific literature and market intelligence in unified AI-powered environments designed for natural language interaction.
Cypris exemplifies this category, implementing a proprietary R&D ontology with unified access to over 500 million patents and scientific publications. The platform's RAG architecture specifically designed for technical and scientific content enables R&D teams to describe technology questions in natural language and receive synthesized analysis grounded in source documents. Official API partnerships with OpenAI, Anthropic, and Google enable organizations to embed prior art intelligence into internal AI applications and workflows. SOC 2 Type II certification and US-based operations address enterprise security and compliance requirements. Fortune 100 customers including Johnson and Johnson, Honda, and Yamaha validate enterprise-scale deployment.
For organizations whose primary prior art search use case is R&D technology intelligence rather than patent prosecution, enterprise R&D platforms offer workflow alignment that patent-focused tools cannot match.
Patent Prosecution Platforms
Patent prosecution platforms optimize for the specific needs of patent attorneys and IP professionals. These tools excel at constructing precise queries, mapping claims against prior art, and integrating with patent drafting and prosecution workflows.
IPRally uses a distinctive graph-based approach that represents inventions as knowledge graphs, enabling comparison of technical features and relationships rather than surface language. The platform's Graph Transformer model, trained on millions of patent examiner citations, delivers high precision for patentability and invalidity searches. Transparency into why documents are retrieved as relevant distinguishes IPRally from black-box semantic search alternatives.
Derwent Innovation from Clarivate combines AI-powered search with the editorial value of the Derwent World Patents Index, which includes human-curated abstracts that normalize patent language across jurisdictions. This hybrid approach delivers high recall while helping users quickly assess relevance without reading full patent documents. Derwent remains a standard choice for large IP departments and search firms requiring enterprise-grade reliability.
Solve Intelligence integrates semantic prior art search within a patent drafting platform, enabling attorneys to move directly from search results to claim construction. The workflow integration distinguishes it from standalone search tools, though non-patent literature search remains under development.
Accessible Starting Points
Several free and low-cost tools provide accessible entry points for preliminary prior art research, though they lack the data coverage, AI sophistication, and enterprise capabilities required for comprehensive analysis.
PQAI is an open-source initiative providing free access to AI-powered prior art search across patents and scholarly articles. Developed to improve patent quality and help under-resourced inventors, PQAI demonstrates the accessibility that AI has brought to prior art searching. While it lacks the depth of commercial platforms, PQAI serves as a useful starting point for preliminary searches.
Google Patents provides free access to patents from major offices with basic search capabilities. The familiar Google interface lowers barriers to entry, and integration with Google Scholar enables some non-patent literature discovery. However, advanced AI features, comprehensive NPL coverage, and enterprise capabilities are not available.
Perplexity Patents, launched in late 2025, extends conversational AI search to patent research. Users can ask natural language questions and receive responses grounded in patent documents. The platform represents an accessible entry point for patent exploration, though it currently focuses on patents rather than comprehensive prior art coverage including scientific literature.
Frequently Asked Questions
What makes AI prior art search different from traditional patent search?
Traditional patent search relies on keyword matching and classification codes, requiring users to anticipate the exact terminology used in relevant documents. AI prior art search uses machine learning models to understand technical concepts and identify relevant documents even when they use different terminology. Advanced implementations incorporate domain ontologies, knowledge graphs, and retrieval-augmented generation to provide synthesized analysis rather than ranked document lists.
How important is non-patent literature coverage for prior art search?
Non-patent literature is essential for comprehensive prior art analysis. Scientific publications often disclose concepts twelve to twenty-four months before related patent applications are filed. Technical standards, conference proceedings, and dissertations all constitute valid prior art that can affect patentability determinations. Platforms that treat NPL as an afterthought often miss critical prior art that appears outside the patent system.
What security certifications should enterprise organizations require?
For organizations handling confidential invention disclosures and competitive intelligence, SOC 2 Type II certification provides the strongest independent verification of security controls. Type II audits assess operational effectiveness over an extended period, typically three to twelve months, while Type I audits evaluate controls at a single point in time. Many enterprise procurement processes now require Type II certification as a minimum threshold.
How do knowledge graphs improve prior art search accuracy?
Knowledge graphs represent patents as structured networks of technical concepts and relationships rather than undifferentiated text. This enables comparison of inventions at the level of technical features rather than surface language, identifying relevant prior art even when described using entirely different terminology. Graph structures also provide transparency into why documents are retrieved as relevant, enabling users to understand and refine search results.
What is retrieval-augmented generation and why does it matter for prior art search?
Retrieval-augmented generation combines a retrieval component that identifies relevant documents with a generation component, typically a large language model, that synthesizes information from retrieved sources. For prior art search, RAG enables natural language interaction where users describe technical concepts and receive synthesized analysis grounded in actual documents. This approach mitigates the hallucination risk inherent in standalone LLM responses while enabling conversational accessibility.
How should organizations evaluate data coverage claims?
Raw document counts matter less than coverage of specific jurisdictions and technical domains relevant to your research. Evaluate coverage of major patent offices including USPTO, EPO, CNIPA, JPO, and KIPO. For scientific literature, verify coverage of journals and conference proceedings in your technical domains. Understand typical delays between publication and database availability. For global organizations, assess cross-lingual search capabilities for non-English documents.
Can AI prior art search replace professional patent searchers?
AI prior art search augments rather than replaces professional expertise. AI tools dramatically accelerate the identification of potentially relevant documents and can surface prior art that manual searches miss. However, determining whether prior art actually impacts novelty or patentability requires specialized legal expertise. The most effective approach combines AI-powered search for comprehensive document identification with professional analysis for legal interpretation and strategic guidance.
What integration capabilities matter for enterprise deployment?
Enterprise organizations increasingly need prior art intelligence embedded within innovation management systems, competitive intelligence dashboards, and custom AI applications rather than accessed through standalone interfaces. Evaluate whether platforms offer enterprise API access for programmatic integration, data export capabilities for downstream analysis, and compatibility with systems your team already uses. Official partnerships with major AI providers indicate that integrations meet enterprise reliability and security standards.
---
Modernize Your Prior Art Search with Cypris
Enterprise R&D teams at Johnson & Johnson, Honda, Yamaha, and PMI rely on Cypris to conduct AI-powered prior art research across 500+ million patents and scientific publications. Our proprietary R&D ontology and retrieval-augmented generation architecture deliver synthesized technology intelligence through natural language interaction, with official API partnerships enabling integration into your existing workflows. SOC 2 Type II certified and US-based, Cypris provides the enterprise security and compliance your organization requires.
Request a demo at cypris.ai to see how unified R&D intelligence transforms your innovation research.

This article was powered by Cypris Q, an AI agent that helps R&D teams instantly synthesize insights from patents, scientific literature, and market intelligence from around the globe. Discover how leading R&D teams use Cypris Q to monitor technology landscapes and identify opportunities faster - Book a demo
Executive Summary
GLP-1–based obesity pharmacotherapy has evolved from single-hormone appetite suppression into a platform competition spanning poly-agonist biology, delivery convenience, and body-composition optimization. Across patents and scientific literature, three mega-trends now dominate the landscape.
The first is poly-agonist escalation—the progression from GLP-1 alone to dual and then triple or even quad receptor targeting. Scientific literature increasingly frames unimolecular multi-receptor agonism as the primary route toward bariatric-like weight loss outcomes, combining appetite reduction with enhanced energy expenditure and broader metabolic effects [1, 2, 3]. Preclinical work on optimized tri-agonists demonstrates "best-of-both-worlds" profiles, achieving greater energy expenditure and deeper weight normalization than GLP-1-only comparators [4]. Patent filings mirror this escalation, with claims covering dosing regimens and compositions for tri-agonists and next-wave combinations [5, 6].
The second mega-trend positions delivery and adherence as core IP battlegrounds. Patents have grown dense around oral administration, permeation enhancers, and alternative routes including buccal, sublingual, sustained-release depots, and long-duration implants [7, 8, 9, 10]. This tracks the scientific maturation of oral peptide delivery—most notably SNAC-enabled oral semaglutide—and practical adherence guidance emerging in the literature [11, 12]. The signal is unmistakable: innovation is no longer solely about which molecule works best, but how reliably and scalably it can be delivered to patients.
The third mega-trend is the "quality weight loss" race, with emphasis shifting toward fat loss that preserves lean mass. As GLP-1–driven weight loss scales across populations, the accompanying loss of muscle becomes a strategic vulnerability. Papers and patents increasingly explore combination strategies, particularly ActRII and myostatin pathway modulation, to protect muscle while deepening fat reduction [13, 14, 15]. This trend connects to broader regimen and IP claims for combination therapies and adjuncts in obesity care [16, 17].
Looking ahead, the next three to five years will likely see poly-agonist differentiation, oral and non-injectable access expansion, and composition-of-mass outcomes emerge as decisive competitive edges—each visible in both filing activity and the research frontier [1, 2, 9].
Methodology and Assumptions
This analysis covers the period from January 2020 through December 2025 for both patents and scientific papers. The scope encompasses global patent filings and global scientific literature, supplemented by market signals from widely cited industry reporting and analysis.
One important assumption involves data limitations. Exact global year-by-year patent and paper counts were approximated using representative cluster evidence—the presence of repeated filing themes, repeated assignees, and recurring therapeutic and delivery motifs—rather than a complete bibliometric census. Evidence for acceleration is therefore presented as directional (high, medium, or low) rather than absolute totals.
Competitive Landscape: Market Leaders and Emerging Challengers
The GLP-1 obesity market has crystallized into one of the most concentrated competitive dynamics in pharmaceutical history. Novo Nordisk and Eli Lilly have established commanding positions that extend well beyond current product revenue into strategic patent portfolios, manufacturing scale, and clinical pipeline depth.
The scale of market dominance is striking. The five flagship GLP-1 products from these two companies—Novo's Ozempic, Wegovy, and Rybelsus alongside Lilly's Mounjaro and Zepbound have collectively generated over $71 billion in U.S. revenue since 2018, with Ozempic alone accounting for roughly half of that total [38]. Projections suggest cumulative revenue could reach $470 billion by 2030, positioning these treatments among the best-selling pharmaceutical products in history [38]. By mid-2025, Lilly had captured approximately 57% of the U.S. GLP-1 market, with tirzepatide-based products accounting for two-thirds of all patients taking obesity medications [39].
Patent strategy has become central to maintaining this dominance. Both companies have built extensive patent thickets around their core molecules, with Novo Nordisk in particular pursuing aggressive filing strategies across new formulations, indications, and delivery methods. As GLP-1s gain approvals for additional disease areas - Novo is studying semaglutide in addiction, osteoarthritis, and MASH—the companies continue extending patent protection through method-of-use claims that could sustain market exclusivity well beyond initial compound patents [40]. Industry observers have noted that these drugs may prove "perpetually novel" through successive re-patenting for different uses, potentially maintaining monopoly positions even as earlier claims expire [40].
Manufacturing capacity has emerged as an equally important competitive moat. Lilly reported producing more than 1.6 times the salable incretin doses in the first half of 2025 compared to the same period in 2024, with plans for significant additional manufacturing expansion [39]. This supply advantage proved commercially decisive as Lilly gained market share while Novo struggled with capacity constraints. Both companies are racing to build new production facilities, recognizing that meeting global demand requires infrastructure investments measured in billions of dollars.
Despite this concentration, the competitive landscape is evolving rapidly. Over 100 GLP-1 therapies are currently in active development globally, with approximately 25 candidates in mid-to-late stage trials [41]. The clinical pipeline represents diverse approaches to differentiation, including alternative receptor combinations, novel delivery mechanisms, and improved tolerability profiles.
Several pharmaceutical giants are positioning themselves to challenge the incumbents. Roche entered the obesity market through its $2.7 billion acquisition of Carmot Therapeutics, bringing multiple clinical-stage obesity programs including both injectable and oral GLP-1 candidates [42]. The company's CT-388 dual agonist and CT-996 oral formulation are progressing through Phase II trials, with potential market entry expected by 2029. Pfizer, after discontinuing its initial danuglipron candidate due to safety concerns in April 2025, re-entered the race through a $10 billion acquisition of clinical-stage biotech Metsera in November 2025, securing a next-generation obesity pipeline [43].
Amgen's MariTide represents perhaps the most differentiated challenger approach. The compound combines GLP-1 receptor agonism with GIP receptor antagonism—a novel mechanism informed by human genetics research suggesting GIP inhibition as a key factor in reducing body mass [44]. Phase II data showed weight loss of up to approximately 20% at 52 weeks, with monthly dosing that could offer meaningful convenience advantages over weekly injections. Notably, weight loss had not plateaued at 52 weeks, suggesting potential for further reduction with continued treatment [44].
Smaller biotechs are also advancing promising candidates. Viking Therapeutics' VK-2735 dual GLP-1/GIP agonist demonstrated weight loss of up to 14.7% after just 13 weeks in early trials, generating significant investor interest [45]. Structure Therapeutics is developing GSBR-1290, an oral small molecule GLP-1 agonist that could potentially address the manufacturing scalability challenges facing peptide-based injectables—the company has noted its current manufacturing capacity could theoretically supply over 120 million patients [46].
Analysts project that while Novo and Lilly will likely retain nearly 70% of the total market through 2031 due to first-mover advantages and continued pipeline innovation, new entrants could collectively capture approximately $70 billion of what is expected to become a $200 billion annual market [46]. The window for market entry remains open partly due to persistent supply constraints among current manufacturers and partly because the addressable patient population continues expanding as clinical evidence mounts for GLP-1 benefits across obesity, diabetes, MASH, cardiovascular disease, and other indications.
Detailed Analysis
Trend Velocity Assessment
The velocity of each innovation trend reflects the combined strength of patent activity, scientific publication volume, and market signals. This assessment identifies which areas are accelerating fastest and likely to reshape the competitive landscape over the coming years.
Multi-agonist incretins, encompassing dual and triple receptor agonists, show the highest velocity across all indicators. Patent filings have concentrated on sequence optimization, receptor balance, and dosing regimens [5, 6], while scientific reviews increasingly position these compounds as the next frontier beyond single-target GLP-1 therapy [1, 2]. Market analysts have echoed this enthusiasm, with pipeline assessments highlighting tirzepatide's success as validation of the dual-agonist approach and positioning triple agonists as the next wave [18, 19]. The three-to-five year outlook for this category is very high.
Oral and non-injectable GLP-1 delivery has similarly generated substantial momentum. The patent landscape reflects intense focus on permeation enhancers, solid oral compositions, and buccal or sublingual alternatives to injection [7, 8, 9]. Scientific literature has matured around oral peptide delivery mechanisms and real-world adherence implications [11, 12], while market reporting indicates strong commercial interest in removing the injection barrier [18, 20]. Analysts project oral drugs could represent approximately 20% of the estimated $80 billion GLP-1 obesity market by 2030 [47]. This trend carries a high velocity outlook.
Sustained-release depots and implants represent a parallel delivery innovation track. Patents describe self-assembling peptide systems and implantable devices designed for months-long semaglutide release [21, 10], aligning with clinical research on long-acting formulations [22]. Market signals remain moderate as these technologies are earlier in development, but the overall velocity is high given the clear strategic value of reducing dosing frequency.
Lean-mass preservation add-ons have emerged as a distinct innovation category. As awareness grows that GLP-1–induced weight loss can include significant muscle loss, patents have begun claiming combinations with myostatin and ActRII pathway modulators [14, 15], while scientific papers examine the mechanisms and clinical implications of body composition changes during incretin therapy [13, 23]. Market analysts have flagged this as a potential differentiator for next-generation therapies [18, 24]. The velocity here is high and accelerating.
Combination therapy expansion for metabolic comorbidities rounds out the top-tier trends. Patents cover coformulations with SGLT2 inhibitors, thyroid hormone receptor beta agonists, and other metabolic targets [25, 26], mirroring the scientific literature's growing focus on GLP-1's effects across MASH, cardiovascular disease, and other obesity-related conditions [27, 28]. Market sizing for these expanded indications has been substantial [18, 29], yielding a very high velocity assessment.
Several additional trends warrant monitoring, though with somewhat lower current velocity. Alternative satiety hormones such as PYY and NPY2 agonists show medium-to-high activity, with patents from major players [30, 31] and scientific reviews exploring their potential as complements or alternatives to GLP-1 [32]. New delivery routes including sublingual, intranasal, and inhaled formulations have attracted patent interest [9, 33, 34] and some scientific attention [35], though market signals remain limited. Microbiome and nutraceutical GLP-1 modulation represents an emerging but still nascent category, with early patents [36] and scientific exploration [37] but minimal commercial traction to date.
Patent Filing Patterns by Innovation Category
Examining patent activity from 2020 through 2025 reveals clear directional trends across innovation categories, even without precise filing counts.
Poly-agonist peptides have shown strong upward trajectory, with claims typically centered on peptide sequences, receptor binding ratios, and optimized dosing regimens. Representative filings include tri-agonist dosing systems and triple agonist compositions from Eli Lilly [5, 6], signaling continued investment in this approach by leading developers.
Oral peptide delivery has demonstrated similarly strong upward momentum. Patents focus on enhancers, absorption technologies, and solid dosage forms, exemplified by Novo Nordisk's oral GLP-1 use claims and various buccal and sublingual compositions from multiple assignees [7, 8, 9]. The density of activity reflects the commercial prize of an effective oral alternative to injection.
Long-acting depots and implants show clear upward direction, with patent claims emphasizing months-long release profiles. Examples include self-assembling peptide systems for controlled release and implantable long-duration semaglutide devices [21, 10]. These technologies address the adherence challenge from a different angle than oral delivery, potentially offering set-and-forget convenience.
Combination regimens pairing GLP-1 agonists with adjunct pathways represent another area of strong upward filing activity. Patents cover coformulations with SGLT2 inhibitors, incretin combinations, and thyroid receptor agonist pairings [25, 26], reflecting the clinical reality that many patients will benefit from multi-mechanism approaches.
Body composition protection, focused on muscle and bone preservation during weight loss, shows upward direction with growing patent interest. Filings claiming myostatin and ActRII pathway combinations with GLP-1 agonists [14] point toward future therapies designed to optimize the quality rather than just quantity of weight loss.
Scientific Publication Patterns by Theme
The scientific literature from 2020 through 2025 reveals parallel trends, with publication volume concentrated in areas that mirror patent activity.
Multi-agonist mechanisms and outcomes have attracted strong and growing attention. Reviews and primary research increasingly examine why dual and triple approaches outperform GLP-1 alone, exploring the synergistic effects of GIP co-agonism and glucagon receptor activation on both weight loss and metabolic parameters [1, 2, 3, 4].
Oral and alternative delivery research has similarly expanded. Publications address the pharmacokinetic challenges of oral peptide delivery, real-world effectiveness of approved oral formulations, and emerging technologies for non-injectable administration [11, 12, 35].
Combination therapy for MASH, cardiovascular disease, and other comorbidities represents another high-volume publication area. The scientific community has moved beyond viewing GLP-1 agonists solely as diabetes or obesity drugs, with substantial literature examining benefits across the metabolic disease spectrum [27, 28].
Body composition and sarcopenia concerns have generated moderate but rapidly growing publication volume. Papers examine the degree and significance of lean mass loss during GLP-1 therapy, mechanisms underlying this effect, and potential mitigation strategies [13, 23]. This emerging literature reflects clinical awareness that weight loss quality matters alongside quantity.
Unmet Needs and Whitespace Opportunities
Despite the remarkable clinical and commercial success of GLP-1 agonists, significant unmet needs persist that define the whitespace for next-generation innovation. These gaps represent both clinical challenges requiring solutions and strategic opportunities for companies seeking differentiation in an increasingly crowded market.
The lean mass preservation problem has emerged as perhaps the most pressing clinical concern. Research indicates that fat-free mass loss accounts for 25-40% of total weight lost during GLP-1 therapy, a rate dramatically exceeding age-related declines of approximately 8% per decade [48]. This substantial muscle loss carries meaningful health implications. A 2025 University of Virginia study concluded that while GLP-1 drugs significantly reduce body weight and adiposity, they do so "with no clear evidence of cardiorespiratory fitness enhancement"—a critical finding given that cardiorespiratory fitness is among the most potent predictors of all-cause and cardiovascular mortality [48]. The researchers expressed concern that this pattern could ultimately compromise patients' metabolic health, healthspan, and longevity.
Clinical observations reinforce these concerns. Physicians report patients describing sensations of muscle "slipping away" during treatment, while some patients experience what has been termed "Ozempic face"—premature facial aging resulting from rapid fat and muscle loss [48]. The World Health Organization's December 2025 guidelines emphasized the importance of resistance training to protect muscle mass during GLP-1 therapy, acknowledging this as a limitation of current treatment approaches [49]. This gap has catalyzed significant R&D investment in muscle-sparing adjuncts, including myostatin inhibitors and ActRII pathway modulators that could be combined with GLP-1 agonists to preserve lean mass while maintaining fat loss efficacy.
Weight regain upon discontinuation represents another substantial unmet need. Clinical evidence consistently demonstrates that patients regain approximately one-third of lost weight within the first year of stopping GLP-1 therapy, with longer-term studies suggesting even more substantial rebound [50]. This pattern reflects the chronic, relapsing nature of obesity and has prompted the WHO to recommend continuous, long-term treatment lasting six months or more—effectively positioning these medications as lifetime therapies for many patients [51]. The clinical and economic implications of indefinite treatment are considerable, driving innovation in approaches that might allow successful maintenance without continuous medication or that could extend dosing intervals substantially.
Access and affordability constraints limit the population that can benefit from current therapies. The WHO has noted that even with rapid manufacturing expansion, GLP-1 therapies are projected to reach fewer than 10% of those who could benefit by 2030 [51]. In the United States, where Wegovy and Zepbound carry list prices exceeding $1,000 per month, approximately one in eight adults report currently taking a GLP-1 drug—but this represents a small fraction of the more than 40% of American adults classified as obese [52]. The WHO guidelines call for urgent action on manufacturing, affordability, and system readiness, recommending strategies such as pooled procurement, tiered pricing, and voluntary licensing to expand global access [51].
Tolerability remains a limiting factor for patient adherence. Gastrointestinal adverse events including nausea, vomiting, and diarrhea are common with current GLP-1 agonists, leading some patients to discontinue treatment or fail to reach maximally effective doses. This has driven interest in alternative mechanisms and combination approaches that might deliver comparable efficacy with improved side effect profiles. Amgen's MariTide, which combines GLP-1 agonism with GIP antagonism, was specifically designed based on genetic evidence suggesting this combination could reduce nausea while maintaining weight loss efficacy [44]. Similarly, amylin analogs like Eli Lilly's eloralintide work through different hormonal pathways and may offer advantages for patients who cannot tolerate GLP-1-based treatments [53].
Non-responders and partial responders represent an underserved population requiring novel approaches. While GLP-1 agonists produce dramatic results for many patients, a meaningful subset achieves suboptimal weight loss or experiences diminishing efficacy over time. This variability likely reflects heterogeneity in the biological drivers of obesity across individuals, suggesting opportunity for precision medicine approaches that match patients to optimal therapeutic mechanisms. Emerging research on melanocortin-4 receptor (MC4R) agonists combined with GLP-1/GIP agonists has shown promise for enhanced weight loss and prevention of weight regain, potentially addressing the needs of patients who plateau on current monotherapy [53].
Pediatric and adolescent obesity remains largely unaddressed by current approvals and clinical evidence. While adult obesity rates have driven commercial focus, childhood obesity has reached epidemic proportions globally, with limited therapeutic options available for younger patients. The long-term implications of treating developing individuals with potent metabolic modulators remain uncertain, creating both clinical need and regulatory complexity for companies considering pediatric development programs.
These unmet needs collectively define the innovation agenda for the next generation of obesity therapeutics. Companies that successfully address muscle preservation, reduce discontinuation-related regain, improve access and tolerability, or develop precision approaches for treatment-resistant patients will capture meaningful differentiation in what promises to become an increasingly commoditized market for first-generation GLP-1 agonists.
Strategic Implications
The convergence of patent activity and scientific publication patterns points toward several strategic conclusions for organizations operating in this space.
First, the poly-agonist thesis has achieved sufficient validation that the competitive question is no longer whether multi-receptor approaches will succeed, but rather which specific receptor combinations and ratios will prove optimal for different patient populations. Organizations lacking poly-agonist programs face an increasingly difficult competitive position.
Second, delivery innovation has become table stakes. The commercial success of any weight loss therapeutic will depend heavily on patient acceptability and adherence, making oral, long-acting depot, and other non-injectable options critical pipeline priorities rather than nice-to-have features.
Third, the body composition narrative represents both a clinical imperative and a marketing opportunity. As lean mass preservation gains prominence in scientific discussion, therapies that can demonstrate muscle-sparing properties—whether through receptor selectivity, combination approaches, or adjunct treatments—will claim meaningful differentiation.
Fourth, manufacturing scale and supply chain reliability have emerged as competitive advantages distinct from molecular innovation. The ability to meet global demand consistently may prove as valuable as clinical superiority in determining market share over the coming years.
Finally, the expanded indication landscape suggests that the GLP-1 platform will increasingly compete not just within obesity, but across MASH, cardiovascular protection, and potentially other metabolic conditions. The IP and development strategies of leading players reflect this broader therapeutic ambition.
---
How Cypris Can Support GLP-1 and Obesity Drug Innovation Intelligence
For R&D and innovation teams tracking the rapidly evolving GLP-1 and obesity therapeutics landscape, maintaining comprehensive awareness across patents, scientific literature, clinical trials, and competitive intelligence presents significant challenges. The velocity of innovation—with over 100 active development programs, weekly patent filings, and continuous clinical readouts—demands intelligence infrastructure that can synthesize signals across disparate data sources in real time.
Cypris provides enterprise R&D teams with unified access to the full spectrum of innovation intelligence required for strategic decision-making in dynamic therapeutic areas like metabolic disease. The platform integrates over 500 million patents, scientific publications, clinical trial records, and market intelligence sources through a proprietary R&D ontology purpose-built for technology scouting and competitive analysis. Fortune 100 pharmaceutical and life sciences companies including Johnson & Johnson use Cypris to identify emerging IP threats, track competitor pipeline evolution, and discover partnership and acquisition targets before they surface in mainstream coverage.
For organizations navigating the GLP-1 landscape specifically, Cypris enables continuous monitoring of poly-agonist patent filings, delivery technology innovations, and combination therapy claims across global jurisdictions. The platform's multimodal search capabilities allow teams to query across molecular structures, mechanism of action descriptions, and clinical outcome data simultaneously—surfacing connections between scientific breakthroughs and commercialization strategies that siloed databases miss. With SOC 2 Type II certification and US-based operations, Cypris meets the security and compliance requirements of enterprise R&D environments handling sensitive competitive intelligence.
To learn how Cypris can accelerate your obesity therapeutics intelligence workflows, visit cypris.ai or request a demonstration tailored to your specific pipeline and competitive monitoring needs.
This article was powered by Cypris Q, an AI agent that helps R&D teams instantly synthesize insights from patents, scientific literature, and market intelligence from around the globe. Discover how leading R&D teams use CypriQ to monitor technology landscapes and identify opportunities faster - Book a demo
References
[1] Yan T, et al. "Next-generation incretin-based therapies: exploring multi-receptor agonism in metabolic disease." Journal of Endocrinology.
[2] le Roux CW, et al. "GLP-1/GIP/glucagon receptor tri-agonism: the emerging paradigm in obesity pharmacotherapy." Endocrinology and Metabolism.
[3] Klein S, et al. "Poly-agonist approaches to metabolic disease: mechanisms and clinical potential." Obesity.
[4] Douros JD, et al. "Optimized tri-agonist design achieves superior metabolic outcomes in preclinical models." Molecular Metabolism.
[5] Eli Lilly. Tri-agonist dosing regimens. AU-2025220848-A1.
[6] Eli Lilly. Triple agonist compositions. CA-3084004-C.
[7] Novo Nordisk. Oral GLP-1 uses. US-12239739-B2.
[8] IX Biopharma. Buccal/sublingual compositions. WO-2025166413-A1.
[9] Immunwork. Sublingual and alternative delivery compositions. WO-2025161997-A1.
[10] Nano Precision Medical. Implantable long-duration semaglutide devices. EP-4646187-A1.
[11] Aroda VR, et al. "Oral semaglutide: pharmacokinetics, clinical efficacy, and practical considerations." Reviews in Endocrine and Metabolic Disorders.
[12] Søndergaard CS, et al. "SNAC-enabled oral peptide delivery: absorption mechanisms and clinical implications." Clinical Pharmacology in Drug Development.
[13] Baur DA, et al. "Lean mass changes during GLP-1 receptor agonist therapy: mechanisms and mitigation strategies." Molecular Metabolism.
[14] Scholar Rock. Myostatin/ActRII pathway combinations with GLP-1. WO-2025245160-A1.
[15] Versanis Bio. Body composition optimization in incretin therapy. US-20240325530-A1.
[16] Bioage Labs. Combination therapies for metabolic disease. EP-4646220-A1.
[17] Actimed Therapeutics. Obesity treatment adjuncts. WO-2025222169-A1.
[18] Nature pipeline review. "GLP-1 agonists and next-generation obesity therapeutics."
[19] Morningstar analysis. "Competitive landscape in incretin-based therapies."
[20] GlobeNewswire. "Oral GLP-1 market development and commercial outlook."
[21] 3-D Matrix. SAP-based controlled release systems. WO-2025184112-A1.
[22] Vilsbøll T, et al. "Long-acting GLP-1 formulations: clinical development and therapeutic potential." Drugs.
[23] Ryan DH. "Body composition outcomes in obesity pharmacotherapy: clinical significance and measurement challenges." Reviews in Endocrine and Metabolic Disorders.
[24] William Blair analysis. "Differentiation strategies in obesity therapeutics."
[25] MedImmune. Cyclodextrin coformulations with SGLT2 and incretin peptides. EP-3972630-A1.
[26] Terns Pharmaceuticals. GLP-1 plus THRβ combinations. US-20250195512-A1.
[27] Zafer MM, et al. "GLP-1 receptor agonists in MASH: mechanisms and clinical evidence." Alimentary Pharmacology & Therapeutics.
[28] Conlon DM, et al. "Cardiovascular effects of incretin-based therapies: beyond glucose control." Peptides.
[29] IQVIA. "Market sizing for GLP-1 expanded indications."
[30] Eli Lilly. PYY-based compositions. AU-2022231763-B2.
[31] Boehringer Ingelheim. NPY2 receptor agonists. TW-202423954-A.
[32] Lim GE, et al. "Alternative satiety hormones: PYY, oxyntomodulin, and beyond." Endocrine Reviews.
[33] Columbia University. Intranasal peptide delivery. WO-2025080717-A1.
[34] Iconovo. Inhaled GLP-1 formulations. WO-2025237925-A1.
[35] Park K, et al. "Non-injectable peptide delivery: emerging routes and technologies." Pharmaceuticals.
[36] Shanghai Huapu Life Health. Microbiome-based GLP-1 modulation. CN-120098832-A.
[37] Ding S, et al. "Gut microbiome interactions with incretin hormones: implications for metabolic disease." Diabetes Metabolic Syndrome and Obesity.
[38] Initiative for Medicines, Access and Knowledge (I-MAK). "The Heavy Price of GLP-1 Drugs: How Financialization Drives Pharmaceutical Patent Abuse and Health Inequities." 2025.
[39] PharmaVoice. "3 ways the GLP-1 market has changed shape this year." August 2025.
[40] PharmaVoice. "Can anything threaten Novo and Lilly's obesity market dominance?" April 2025.
[41] DelveInsight. "GLP-1 Agonists Market Report 2025-2034."
[42] GlobalData analysis. "Roche Carmot acquisition positions company in GLP-1 space."
[43] Morningstar. "2 Companies Poised to Capitalize on the Rise of GLP-1 Weight Loss Drugs." December 2025.
[44] The Pharmaceutical Journal. "Beyond GLP-1: the next wave of weight-loss medication innovation." October 2025.
[45] Fierce Biotech. "A look at the R&D landscape in obesity, led by GLP-1s." August 2024.
[46] Morningstar. "Obesity Drugs: The Next Wave of GLP-1 Competition." September 2024.
[47] CNBC. "Eli Lilly, Novo Nordisk prepare to face off in the next obesity drug battleground." September 2025.
[48] University of Virginia Health. "GLP-1 Drugs Fail to Provide Key Weight-Loss Benefit." July 2025.
[49] ABC News. "World Health Organization issues first-ever guidelines for use of GLP-1 weight loss medications." December 2025.
[50] Turkish Journal of Medical Sciences. "Paradigm shift in obesity treatment: an extensive review of current pipeline agents." 2025.
[51] World Health Organization. "WHO issues global guideline on the use of GLP-1 medicines in treating obesity." December 2025.
[52] NBC News. "WHO recommends GLP-1 drugs for obesity." December 2025.
[53] IAPAM. "GLP-1 Clinical Practice Updates: November 2025 Key Developments." December 2025.
Reports
%20-%20Ecosystem%20%26%20Value%20Chain%20Map%20of%20the%20Industrial%20Robotic.png)
%20-%20Data%20Fingerprinting%20And%20Watermarking.png)
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)