
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
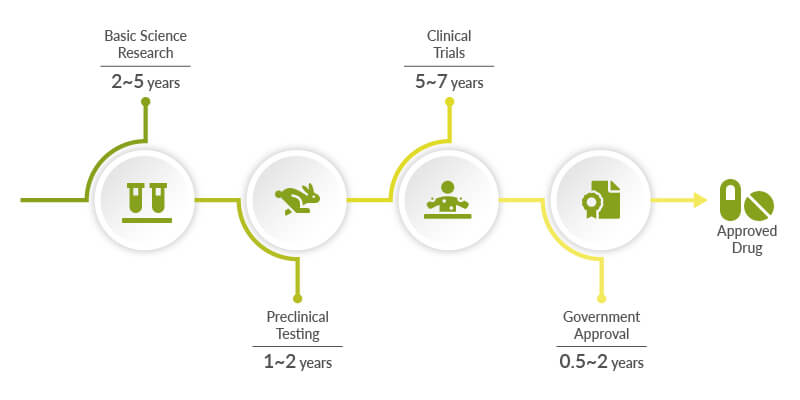
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
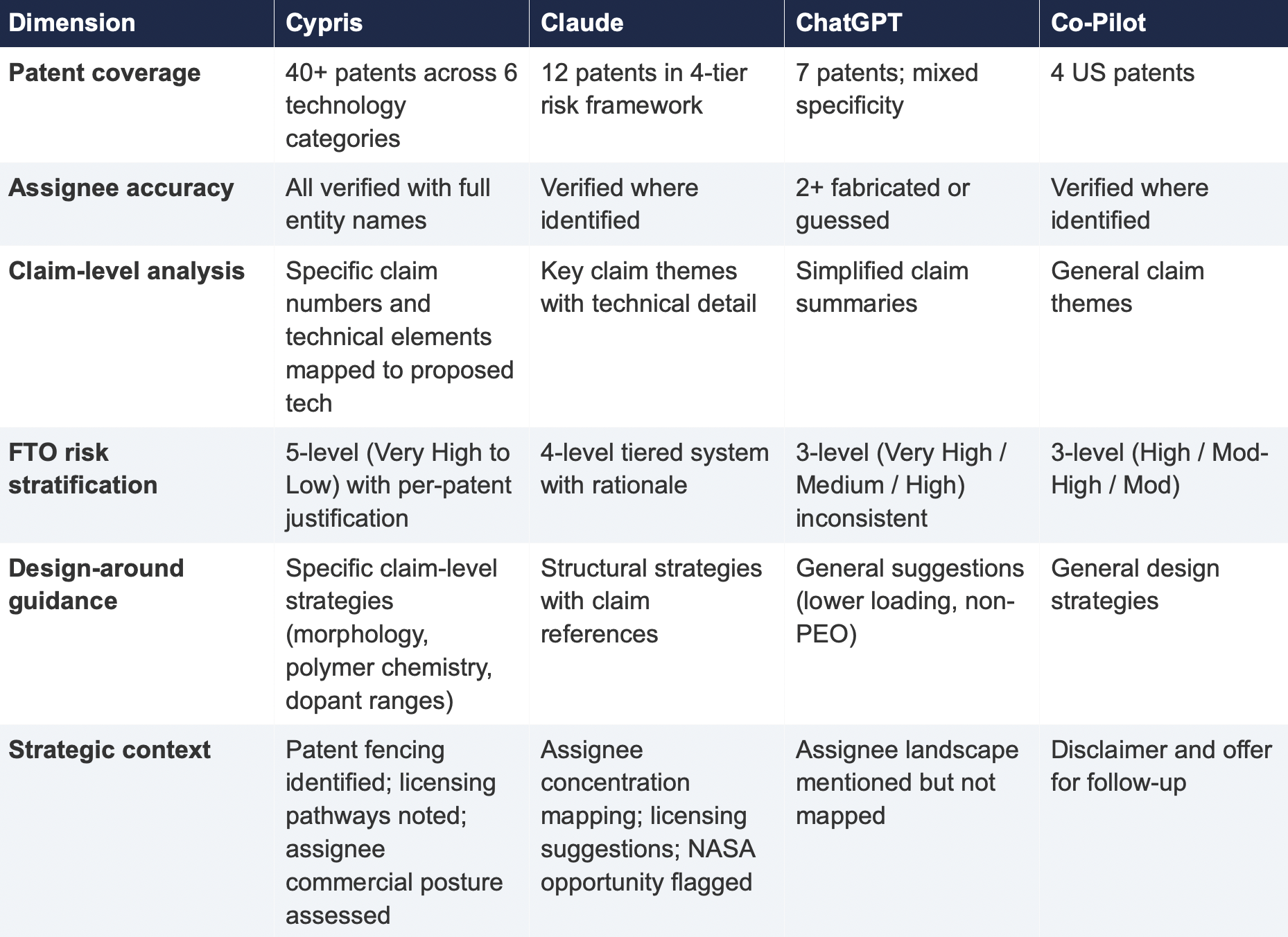
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
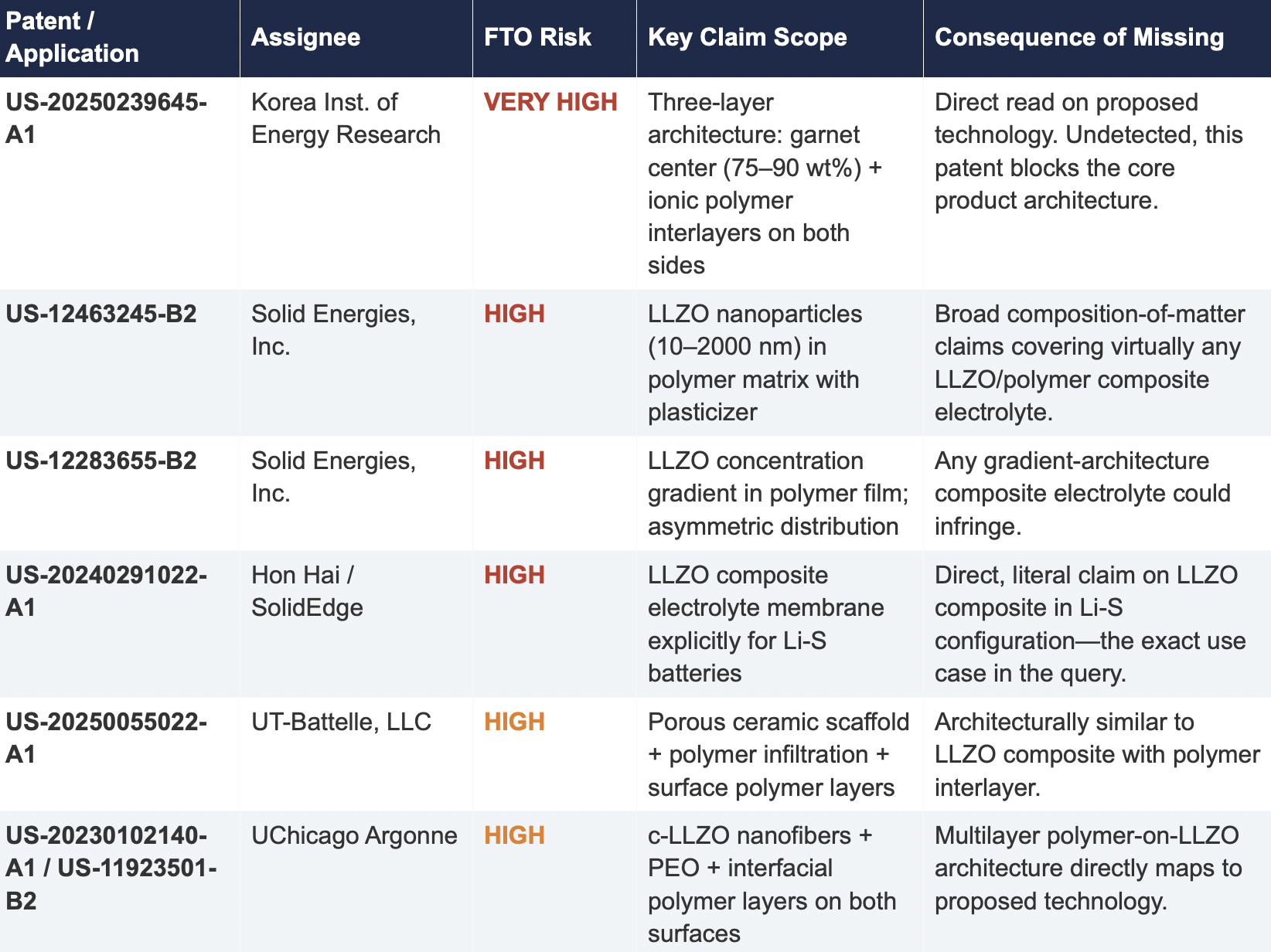
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

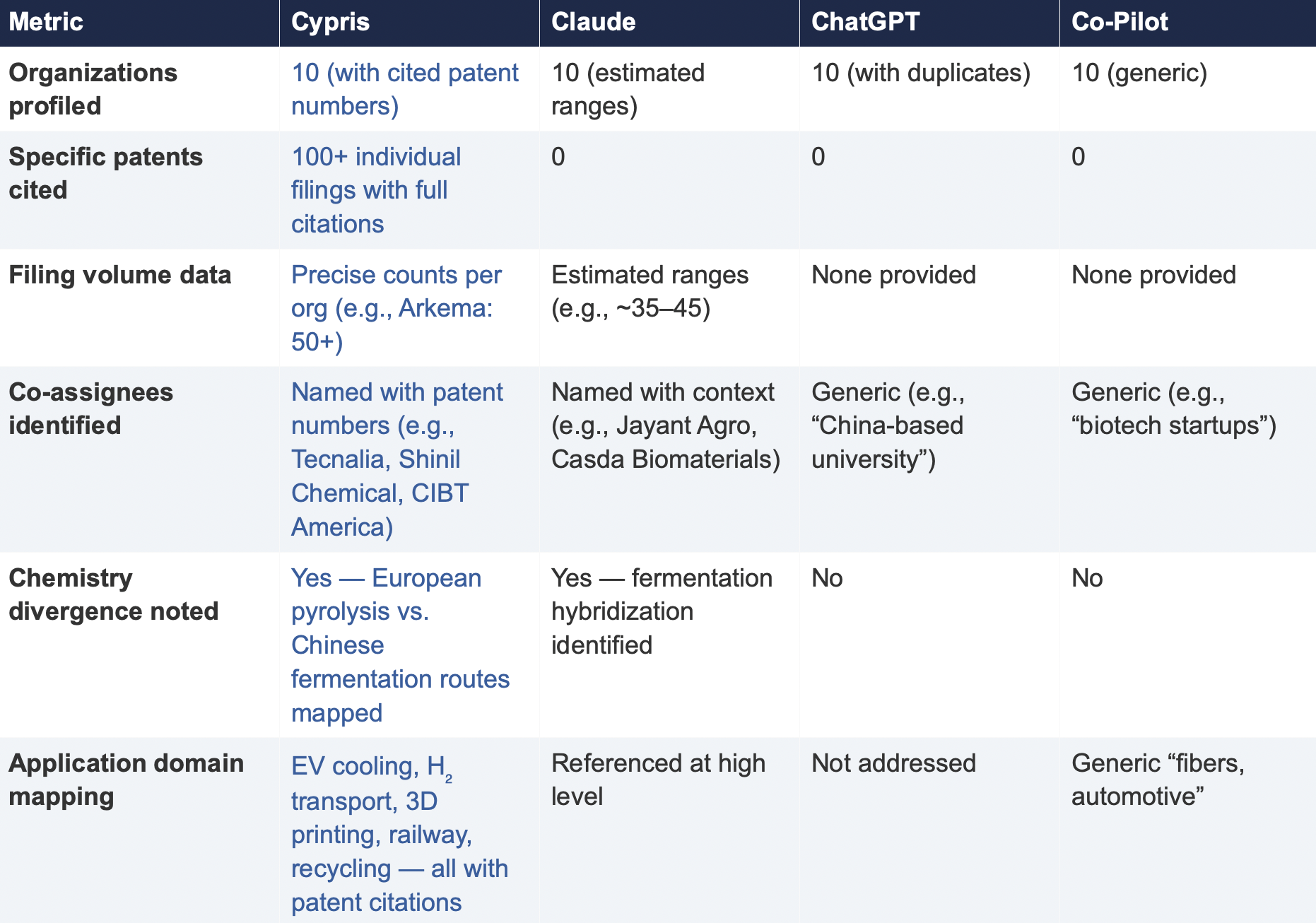
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

Navigating patent litigation strategy can be a daunting task for R&D and innovation teams. Patent infringement lawsuits often involve complex legal proceedings, with many steps to ensure the success of your case. Preparing for potential disputes requires strategic foresight in order to develop an effective patent litigation strategy that will protect your business interests.
This article covers the fundamentals of what you need to know about patent litigation strategies including:
- What is patent litigation?
- Preparing for patent litigation.
- Filing a lawsuit for patent infringement.
- The discovery process in patent litigation.
- Trial preparation.
- Resolution in patent litigation.
With these insights into developing a strong patent litigation strategy, you’ll have all the knowledge necessary when navigating through any future disputes involving intellectual property rights.
Table of Contents
Preparing for Patent Litigation
Filing a Lawsuit for Patent Infringement
The Discovery Process in Patent Litigation
Trial Preparation and Resolution in Patent Litigation
Pre-Trial Motions and Markman Hearings
Jury Selection and Trial Proper
Verdict and Post-Trial Motions
FAQs About Patent Litigation Strategy
What is meant by patent litigation?
Are patents subject to litigation?
Is patent prosecution considered litigation?
Where are patent cases litigated?
What is Patent Litigation?
Patent litigation is a legal process used to protect and enforce patent rights. It involves filing a lawsuit against an infringer who has allegedly violated the patent holder’s exclusive right to make, use or sell the patented invention. Patent litigation can be divided into two main types: infringement actions and validity actions.
Infringement actions involve claims that another party has made, used, or sold a product without permission from the patent holder. In these cases, the court will determine whether there was an actual violation of the patent rights and if so, what remedies should be granted to compensate for any losses suffered by the plaintiff as a result of such infringement.
Validity actions are brought when one party challenges another’s claim of ownership over a particular invention or technology. The court will decide whether or not the challenged patent is valid based on its merits and evidence presented in court.
Don’t get caught in a patent pickle! Make sure you have the right strategy for litigation to protect your inventions and technologies. #PatentLitigationStrategy #Innovation Click to Tweet
Preparing for Patent Litigation
Preparing for patent litigation is an important step in protecting your intellectual property. It requires understanding your patents and rights, researching the opposing party’s patents and rights, and developing a strategy for a successful outcome.
Before filing a lawsuit or responding to one, it is important to understand what you are claiming ownership of. This includes reviewing all relevant documents such as patent applications, assignment agreements, and licenses to ensure that you have the right to enforce any claims of infringement.
Additionally, familiarizing yourself with the scope of protection afforded by each patent can help identify potential infringers more quickly.
Once you have identified potential infringers or had been served with a complaint alleging infringement, conduct research on your own intellectual property portfolio. This will provide insight into their defenses against your claim or any counterclaims they may bring against you.
Key Takeaway: Patent litigation requires a thorough understanding of your own patents and rights, as well as research into the opposing party’s intellectual property portfolio.
Filing a Lawsuit for Patent Infringement
Before filing, it’s important to understand the jurisdiction and venue of the case. Jurisdiction refers to which court will hear the case, while the venue is where the trial will take place.
Generally, you can file a lawsuit in either federal or state court depending on where the defendant resides or does business.
Once you have determined jurisdiction and venue, you must draft a complaint that outlines all of your claims against the defendant. The complaint should include information about who owns each patent at issue as well as any other relevant facts related to infringement allegations.
After drafting your complaint, it must be served on the defendant by someone over 18 years old who is not involved in litigation (e.g., sheriff).
When responding to counterclaims during litigation proceedings, it is important to remember that they may challenge various aspects of your patents such as validity or enforceability. To successfully defend against these challenges, you must provide evidence that supports your claims regarding ownership and infringement allegations outlined in your original complaint.
If necessary, seek legal advice from experienced attorneys familiar with patent law before proceeding with any action related to defending yourself against counterclaims.
Protect your intellectual property with a patent litigation strategy! Before filing, know the jurisdiction and venue. Serve the defendant and be prepared to defend against counterclaims or defenses. #patentlaw #litigationstrategy Click to Tweet
The Discovery Process in Patent Litigation
Discovery in patent litigation is a crucial part of the legal process. It involves document requests, interrogatories, depositions, expert witnesses, and motion practice.
Document requests are formal written requests for documents that are relevant to the case at hand. These can include any information related to the patents or rights being litigated upon such as contracts, emails, financial records, and more.
Interrogatories are questions posed by one party to another that must be answered under oath.
Depositions involve sworn testimony from witnesses who have knowledge of the facts surrounding the case and provide evidence for either side’s argument.
Obtaining expert witnesses is an important step in patent litigation as they provide expertise on specific topics related to the case which can help determine liability or damages awarded in a lawsuit. They may also be used during deposition proceedings where their opinion can be challenged by opposing counsel if necessary.
(Source)
Trial Preparation and Resolution in Patent Litigation
Pre-Trial Motions and Markman Hearings
Pre-trial motions are filed before the trial begins, typically to address procedural issues or to narrow the scope of evidence that will be presented.
A Markman hearing is a type of pre-trial motion in which a judge reviews the patent claims at issue and determines how they should be interpreted. This helps ensure that both parties understand what is being disputed in the case.
Jury Selection and Trial Proper
Jury selection involves selecting jurors who can make impartial decisions based on the facts presented during trial proceedings.
The opening statement outlines each party’s position in relation to their legal arguments and provides an overview of what evidence will be presented during the trial.
Evidence presentation includes witness testimony as well as documents such as contracts or emails that support either side’s argument.
During closing arguments, attorneys summarize their respective cases by highlighting key points from the evidence presented throughout trial proceedings.
Verdict and Post-Trial Motions
After all of the evidence has been heard and closing statements have been made by both sides’ attorneys, it is up to jurors to decide whether one party has infringed upon another’s patent rights or not.
If infringement is found then damages may also be awarded depending on jurisdiction laws regarding patent litigation cases.
Following a verdict, there may still be post-trial motions such as requests for new trials or appeals filed by either side if they feel that justice was not served properly during initial proceedings.
Key Takeaway: Patent litigation strategy involves several steps, including pre-trial motions and Markman hearings, jury selection, evidence presentation, closing arguments, and post-trial motions if necessary.
FAQs About Patent Litigation Strategy
What is meant by patent litigation?
Patent litigation is the legal process by which the owner of a patented product can sue someone for manufacturing and selling it without the owner’s permission.
Are patents subject to litigation?
Patents, which are granted by a governmental agency, are enforced by the private efforts of their holders. If the owner of a patented invention feels that another entity is violating its rights, it may file a lawsuit for infringement in a U.S. district court.
Is patent prosecution considered litigation?
The process of filing and pursuing a US patent application with the patent office is commonly known as patent prosecution. This process is not the same as patent litigation which is the process of enforcing a patent in court.
Where are patent cases litigated?
All patent litigation occurs either in federal district courts or in the International Trade Commission.
In patent litigation in federal district courts, the patent owner can seek an injunction, basic economic, potentially enhanced damages, and attorneys’ fees.
Conclusion
Patent litigation is a complex process that requires careful preparation and strategic thinking. A comprehensive patent litigation strategy should be developed to ensure the best possible outcome for your business.
It is important to understand the various steps involved in patent litigation, such as filing a lawsuit for infringement and preparing for discovery and trial resolution. By taking the time to develop an effective patent litigation strategy, you can protect your intellectual property rights while also avoiding costly legal disputes.
Are you an R&D or innovation team looking to better understand and navigate the complexities of patent litigation? Cypris provides a comprehensive research platform that centralizes all relevant data sources into one location, giving teams access to rapid insights.
Streamline your process with our innovative tools today – let us help you make informed decisions about patent litigation strategies quickly and easily!

Patent portfolio management is an essential part of the research and development process for many companies. It involves creating a strategy to protect your intellectual property rights by filing patents, tracking existing patents, and managing potential infringement cases. The challenge lies in effectively navigating this complex landscape while staying ahead of competitors and ensuring that valuable inventions are adequately protected.
To help with these tasks, organizations can leverage tools such as Cypris’ patent portfolio platform which provide access to data sources needed for efficient patent analysis and management.
In this blog post, we’ll explore what patent portfolio management is all about and how to create a successful IP strategy.
Table of Contents
What is Patent Portfolio Management?
Benefits of Patent Portfolio Management
Creating a Patent Portfolio Strategy
Identifying Your Goals and Objectives
Analyzing Your Market and Competitors
Developing a Plan for Filing Patents
Challenges of Patent Portfolio Management
Keep Track of Deadlines and Fees
Stay Up To Date With Changes In Technology
How Can Cypris Help With Patent Portfolio Management?
FAQs About Patent Portfolio Management
What is patent portfolio analysis?
How do you create a patent portfolio?
How does the company benefit from a patent portfolio?
What is Patent Portfolio Management?
Patent portfolio management is the process of managing a company’s intellectual property (IP) assets, including patents, trademarks, copyrights, and trade secrets. It involves creating strategies to protect IP from infringement or unauthorized use by competitors and other third parties. The goal of patent portfolio management is to maximize the value of a company’s IP while minimizing risks associated with its ownership.
Benefits of Patent Portfolio Management
By effectively managing their patent portfolios, companies can increase their competitive advantage in the marketplace through protection against potential infringers. They can also create revenue streams through licensing agreements with others who wish to use their patented technologies.
Additionally, having a well-managed patent portfolio allows organizations to better understand what areas they should focus on for future innovation efforts and how best to monetize those inventions.
There are three main types of patents.
Utility patents cover inventions that have practical applications. Design patents cover new ornamental designs for products. Plant patents cover newly developed varieties of plants created through human intervention.
Utility patents provide exclusive rights over an invention for up to 20 years after the filing date, while design patents last 14 years. Plant patents last 17 years from the issue date.
Each type provides different levels of protection depending on the nature of the invention but all are important components in any comprehensive patent strategy.
Now let’s look at how to create a patent portfolio strategy.
Key Takeaway: Patent portfolio management is an essential tool for R&D and innovation teams to maximize the value of their intellectual property. With the right strategy, you can ensure your patents are well-maintained and protected while also providing a competitive advantage.
Creating a Patent Portfolio Strategy
Creating a patent portfolio strategy is an important step for any R&D or innovation team. A successful patent portfolio should be tailored to the specific needs of the organization and take into account its goals, objectives, market conditions, competitors, and legal landscape.
Identifying Your Goals and Objectives
The first step in creating a patent portfolio strategy is to identify your organization’s goals and objectives. This includes understanding what type of patents you need, how many patents you want to file each year, where you plan on filing them, and how much money you are willing to spend on filing fees.
You should also consider whether your goal is simply protection from infringement or if it’s more focused on monetization through licensing opportunities.
Analyzing Your Market and Competitors
Once your goals have been identified, it’s time to analyze the market conditions as well as your competitors’ existing portfolios. This will help inform decisions about which technologies may not yet be covered by existing IP rights held by others in the industry.
It can also provide valuable information about potential licensing opportunities with other companies in the space who might benefit from access to certain technology owned by your company but is not currently being used commercially.
Developing a Plan for Filing Patents
After identifying goals and analyzing the market conditions, it’s time to develop a plan for filing new patents. This includes deciding when applications should be filed as well as determining which countries/regions they should be filed in.
Additionally, this phase involves researching prior art so that claims can accurately reflect what has already been done before while still providing sufficient novelty over existing solutions.
(Source)
Challenges of Patent Portfolio Management
Managing a patent portfolio can be a complex and time-consuming task. Keeping track of deadlines and fees, understanding the legal landscape, and staying up to date with changes in technology are all challenges that need to be addressed.
Keep Track of Deadlines and Fees
Patent portfolios require constant monitoring for compliance with filing requirements such as deadlines for payment of maintenance fees or renewal dates. Missing these important dates can lead to costly consequences including loss of rights or invalidation of patents. To ensure timely payments are made, automated tracking systems should be used to monitor patent status and alert users when action is required.
Study the Legal Landscape
Patents involve intricate legal processes which vary from country to country, that’s why it is essential to study the relevant laws governing intellectual property rights. Online research platforms provide access to detailed information on international patent law so teams can stay informed about current regulations and trends affecting their patents.
Stay Up To Date With Changes In Technology
Technology advances quickly, therefore it’s important for R&D teams to keep abreast of new developments in their field that could impact existing patents or future applications. Artificial intelligence (AI) solutions allow companies to quickly identify potential threats posed by emerging technologies while also uncovering opportunities for innovation within their own industry space.
Key Takeaway: Managing a patent portfolio requires staying on top of deadlines, understanding legal processes, and keeping up with changes in technology.
How Can Cypris Help With Patent Portfolio Management?
Cypris allows users to easily access all relevant information in one place. This includes patent filings, competitor analysis, legal documents, and more. By having everything in one location, teams can quickly identify trends and opportunities for growth without wasting time searching through multiple databases or applications.
Additionally, this helps reduce errors that could lead to costly mistakes down the line.
With Cypris’s intuitive search capabilities and automated tracking systems, teams can save valuable time when researching new ideas or conducting competitive analysis on existing patents. The platform also provides a variety of tools such as AI-powered analytics which allow users to quickly assess potential risks associated with a particular patent application before it is filed – saving both time and money!
Patent portfolios are often managed by multiple departments within an organization including research and development, product development, and commercialization engineering teams. With Cypris’s collaboration features such as real-time chatrooms and document-sharing capabilities, these different groups can work together seamlessly from anywhere in the world!
Overall, using Cypris for managing your patent portfolio will help you stay organized while maximizing efficiency across all areas of your business operations.
FAQs About Patent Portfolio Management
What is patent portfolio analysis?
A patent portfolio analysis identifies all the patented inventions of a company or a competitor. The analyzed portfolios include both published and granted U.S. patents.
Companies or entities may compare their portfolio of intellectual property with that of their competitors.
How do you create a patent portfolio?
- Identify your business goals.
- Set a budget.
- Complete an IDR for each valuable idea.
- Sort the IDRs according to priority.
- Identify any filing deadlines.
- Estimate your filing costs.
- Create a filing calendar.
How does the company benefit from a patent portfolio?
Maintaining a patent portfolio is important for staying ahead of the competition. By keeping track of your patent holdings and coordinating them with your business strategies, you can increase your company’s profits.
Conclusion
Cypris provides a comprehensive platform for patent portfolio management that helps teams quickly access data sources, create strategies, and stay up-to-date on trends in the industry. By leveraging this powerful tool, teams can ensure they are making informed decisions about their patent portfolios and maximizing their return on investment.
Are you struggling to effectively manage your patent portfolio? Cypris is the perfect solution for R&D and innovation teams looking to gain time-to-insights.
Our platform centralizes all data sources into one user-friendly interface, allowing users to quickly understand their portfolios and make informed decisions. Try Cypris today – streamline your research process and take control of your patents!

Are you looking to further your research and development? Finding the right information is key in any innovation process, but it’s not always easy. Learning how to search for a research paper that is apt for your current project is an essential skill that R&D leaders should possess.
In this article, we look at how to find reliable sources, tips on finding relevant papers, and utilizing resources so you can make your review of related literature more efficient. Let’s learn together how to search for a research paper.
Table of Contents
Narrowing Down Your Topic for Literature Review
Defining Your Research Question
Search Techniques in Reviewing Related Literature
Start With Broad Research Databases
Look Into Specialized Research Databases
Additional Tips for Finding Research Papers
Conclusion: How to Search for a Research Paper
Narrowing Down Your Topic for Literature Review
When it comes to learning how to search for a research paper, the important first step is narrowing down your topic. It can be difficult to find relevant research papers if you don’t have a specific focus. Narrowing down your topic helps ensure that you are seeing the most accurate and up-to-date information available.
Defining Your Research Question
The first step in narrowing down your topic is defining your research question. This should be as specific as possible so that you can easily identify relevant sources of information.
Begin by asking yourself broad questions about the topic of interest. This can be done through brainstorming, reading literature, or talking with experts in the field. Consider what topics need further exploration and how your study could contribute to existing knowledge on the subject.
Once you have identified an area of interest, narrow down your focus by considering what specific information would be most beneficial to answer this broader question. Think about who or what might benefit from having this information and why it is important to investigate now rather than later.
After narrowing down your focus, create a more specific research question that will guide your investigation into the issue at hand. Make sure that it is measurable so that results can easily be interpreted and analyzed upon completion of the study.
Additionally, consider whether there are ethical implications associated with collecting certain types of data or conducting certain experiments before finalizing your questions.
Identifying Keywords
Once you have defined your research question, it’s time to start identifying keywords related to it. These will help you search more effectively when looking for sources of information.
By using relevant and specific keywords, you can narrow down your search results and find more targeted information quickly.
The essential step in identifying keywords is brainstorming ideas related to your research question. Think about all of the different terms that could be used to describe what you’re looking for and write them down on a piece of paper or in a document on your computer.
It might help to think of synonyms as well as related topics or concepts that could be associated with what you’re researching.
Narrowing down your topic is essential in improving how to search for a research paper. Once you have a more specific field of research, you can easily brainstorm keywords that will serve as your search terms when looking at search engines.
Search Techniques in Reviewing Related Literature
Once you have narrowed down your topic and identified keywords, it’s time to look for related research articles. Using your identified keywords as search terms, you can now begin compiling different journal articles.
Start With Broad Research Databases
To start your journal article hunt, begin by searching broad research databases such as JSTOR or Google Scholar. These will provide you with a wide range of results that you can then narrow down further.
Searching on JSTOR can be done in two ways – by keyword or by subject area. To search by keyword simply enter your query into the search box at the top of any page on the site. If you’re looking for something specific then it’s best to use quotation marks around your keywords so that only exact matches are returned in your results list.
Alternatively, you can browse through different subject areas using the Browse tab located at the top right corner of every page on JSTOR. This will give you a list of all available subjects which can then be further refined with additional filters such as language or publication date range.
Meanwhile, using Google Scholar effectively requires understanding how it works and knowing what kind of information you are looking for. To get the most out of your searches on Google Scholar start by using keywords that are specific to your topic or question.
Additionally, use advanced search techniques like using options for author name or journal title to narrow down results even further. You can also filter by date range if you’re looking for recent publications in your field.
Lastly, don’t forget about related articles which appear at the bottom of each article page. These can be great resources when exploring new topics!
(Source)
Look Into Specialized Research Databases
Once you have identified some relevant articles from these general searches, consider looking into more specialized databases that cater to specific niches. For example, if you are researching a topic related to psychology or neuroscience, PsycINFO may offer more targeted results than other search engines.
Open-access journals are also helpful when conducting literature reviews since they allow free access to all content without requiring payment or subscription fees.
This is especially useful for those who may not otherwise have access to paywalled articles due to financial constraints or other reasons.
Additional Tips for Finding Research Papers
Using search engines, databases, and open-access journals is the start of finding relevant research. Building on preliminary research and being organized is essential. Here are some more tips on finding research papers.
- Keep track of what you have searched and the keywords used. This will help you keep up with what has been done so far and save time in the long run.
- Organize the papers using dates, author names, or keywords. This will make it easier to locate specific documents when needed. Reference managers often have ‘tagging’ tools which can be useful here too!
- Identify connecting papers. Start with recent research as this will point to older work on that topic and may also identify key authors for your search. This can help you find more research articles that will point to more journal articles in their references as well.
- Read the abstracts first. These provide a quick overview of each paper’s content, allowing you to determine whether they are relevant before reading further into them or not.
Conclusion: How to Search for a Research Paper
In conclusion, learning how to search for a research paper might be intimidating in the beginning. However, with the right strategies and resources in place, you can make the process much easier.
Start by narrowing down your topic and identifying key phrases. Use these key phrases in your search query, so academic search engines can give you better research articles as a result. Finally, build on your preliminary research by looking at connected research.
By doing these steps, you will find researching related literature is easier and less frustrating.
Are you a research and development or innovation team looking for an easy way to find the data sources needed to power your project? Look no further than Cypris, the ultimate platform for R&D and innovation teams. With our simple search engine, you can quickly locate relevant research papers without spending hours scouring through articles. Streamline your workflow with Cypris today!
Reports
%20-%20Competitive%20Benchmarking%20for%20Industrial%20Robotics%20OEMs.png)
%20-%20Competitive%20Benchmarking%20of%20EV%20Battery%20Material%20%26%20Cell%20Manufacturers.png)
%20-%20Competitive%20Benchmarking%20for%20Wearable%20%26%20Biosensor%20Device%20Manufacturers.png)
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)