
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
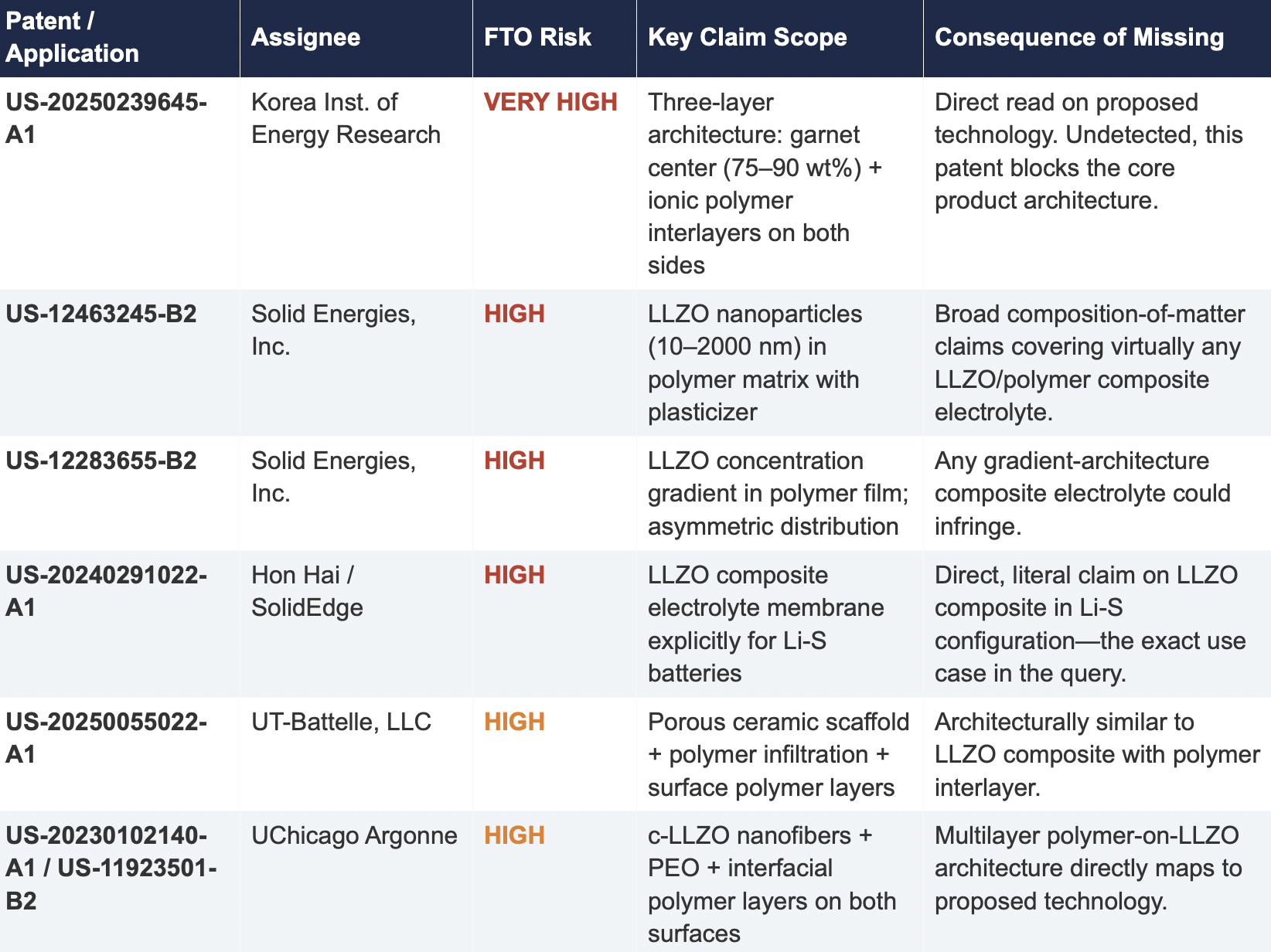
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
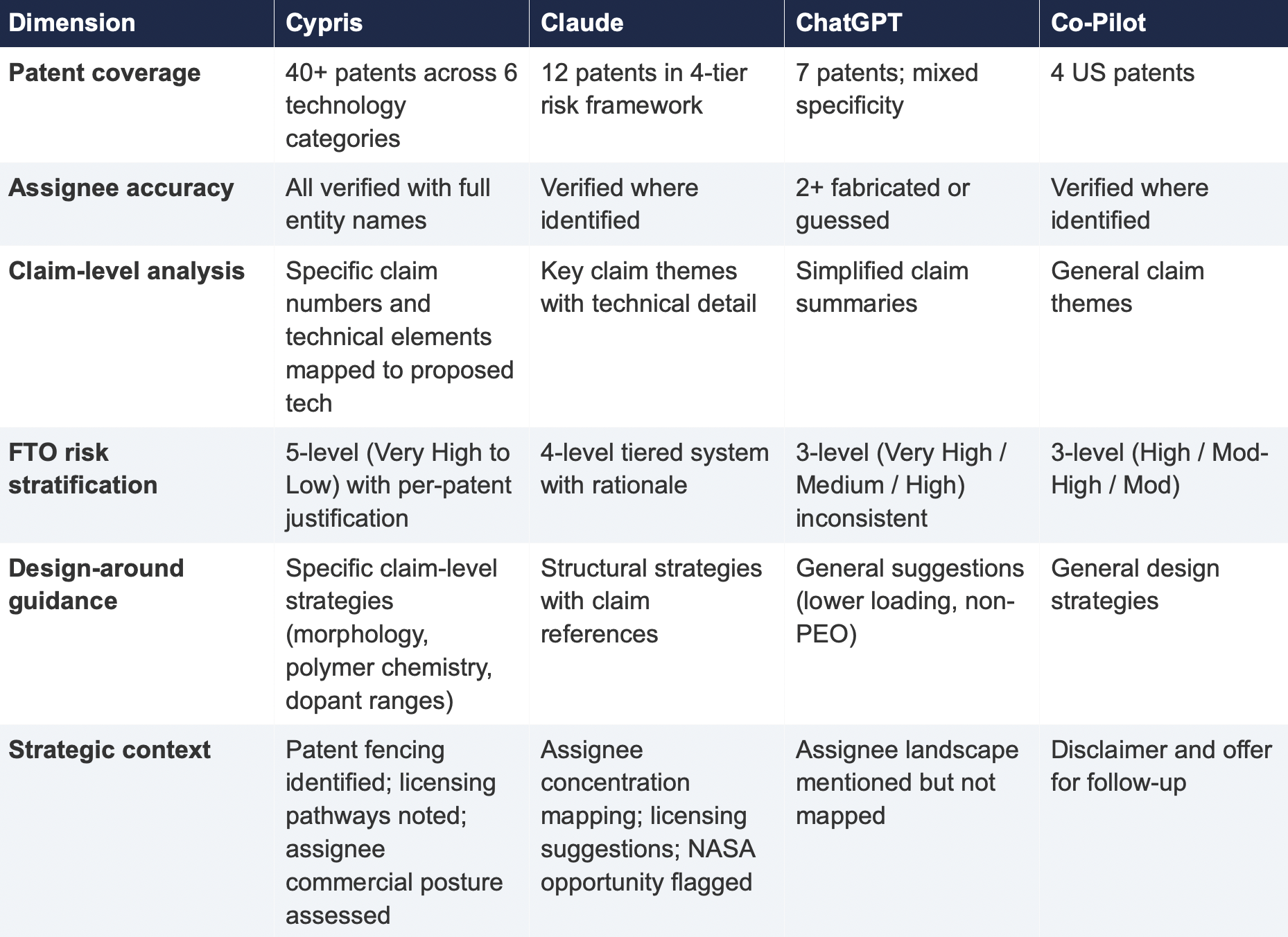
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

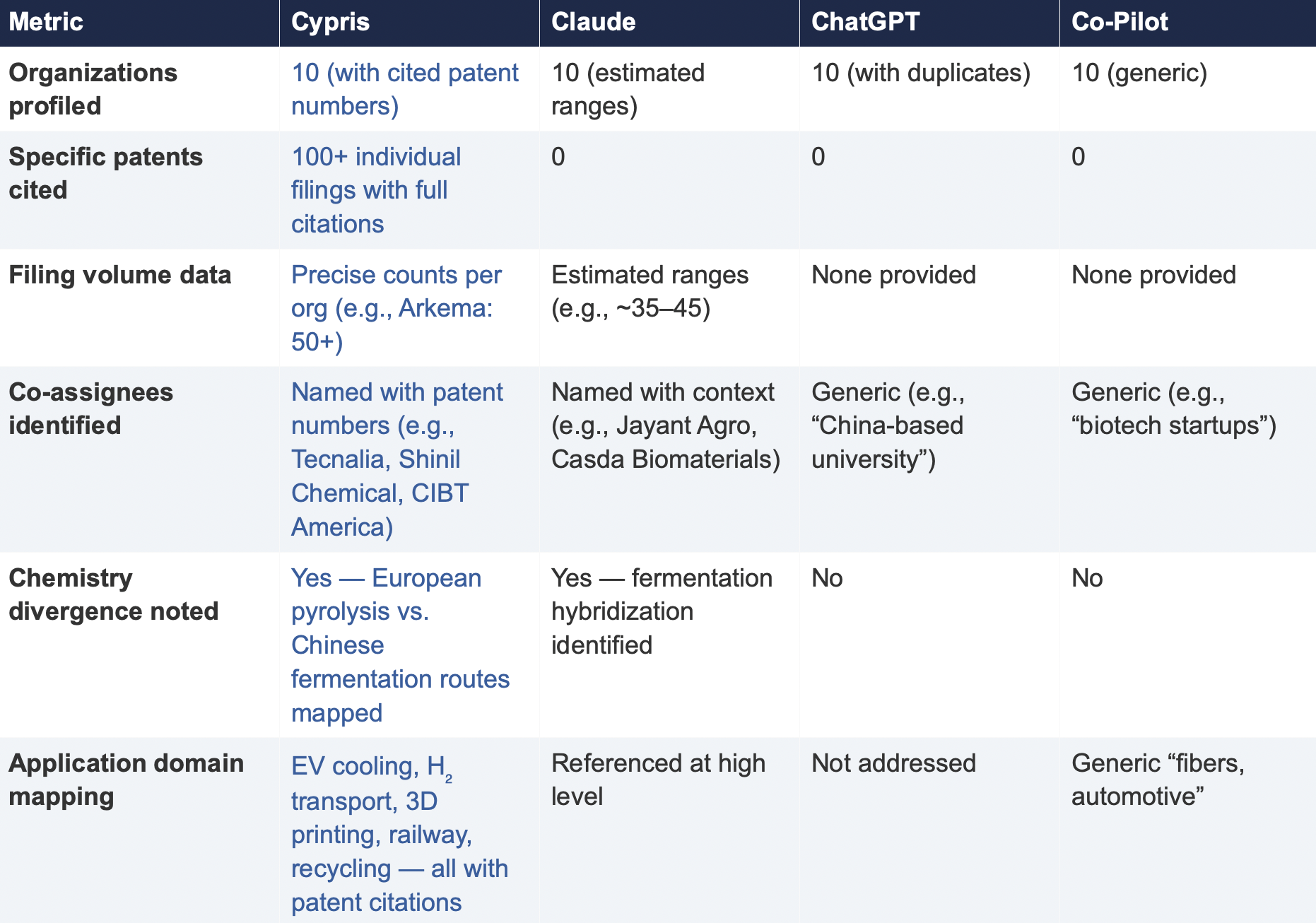
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

United Airlines' "Relax Row" Looks Amazing. But Who Actually Owns the IP?
When United Airlines announced "Relax Row" — three adjacent economy seats with adjustable leg rests that raise to create a continuous lie-flat sleeping surface, complete with a mattress pad, blanket, and pillows — the aviation world took notice[1]. Slated for deployment on more than 200 of United's 787s and 777s, with up to 12 rows per aircraft, it represents one of the most ambitious economy cabin innovations ever attempted by a U.S. carrier[1].
But behind the glossy renders and enthusiastic social media rollout lies a thorny question that United hasn't publicly addressed: who actually owns the intellectual property behind this concept?
The answer, it turns out, is almost certainly not United Airlines.
The Skycouch Came First — By Over a Decade

The idea of economy seats with fold-up leg rests that create a flat sleeping surface across a row is not new. Air New Zealand pioneered this exact concept with its Economy Skycouch™, which has been in commercial service since approximately 2011[13]. The product works precisely the way United describes its Relax Row: passengers in a row of three economy seats can raise individual leg rests to seat-pan height, creating a continuous horizontal surface suitable for lying down[13].
Air New Zealand didn't just build the product — they patented it extensively. The foundational U.S. patent, US 9,132,918 B2, titled "Seating arrangement, seat unit, tray table and seating system," was granted in September 2015 and is assigned to Air New Zealand Limited[36]. The inventors — Victoria Anne Bamford, James Dominic France, Glen Wilson Porter, and Geoffrey Glen Suvalko — filed the earliest priority application in January 2009[36], giving the patent family protection extending approximately through 2029–2030.
The claims are remarkably broad. Claim 1 describes a row of adjacent seats where each seat includes a seat back, a seat pan, and a leg rest, with the leg rest moveable between a stored condition and a fully deployed condition where the seat pan and leg rest are substantially coplanar[36]. When deployed, the leg rests of adjacent seats become contiguous, and the combined surfaces cooperate to define a reconfigurable horizontal support surface that can assume T-shape, L-shape, U-shape, and I-shape configurations — allowing at least two adult passengers to recline parallel to the row direction[36].
The patent explicitly contemplates installation in an economy class section of an aircraft and in a class section that offers the lowest standard fare price per seat to customers[36]. In other words, this isn't a business class patent being stretched to cover economy — it was designed from the ground up to cover exactly what United is now proposing.
The IP Goes Deep
Air New Zealand's IP portfolio goes deeper than just the seating arrangement. A separate patent, EP 2509868, covers the specific leg rest mechanism itself — a sophisticated system using cam tracks, hydrolock pistons, synchronization cables, and detent formations that allow each leg rest to move independently between stowed, intermediate, and fully extended positions[39]. The mechanism is entirely self-supporting through the seat frame, requiring no support from the floor or the seat in front[39]. This level of mechanical detail creates additional layers of patent protection beyond the broad concept claims.
The patent family spans the globe, with filings and grants across the United States[33][34][36], Europe[35], Canada[50], Australia[48], Spain[41], France[40], Brazil[37], and other jurisdictions — a clear signal that Air New Zealand invested heavily in protecting this innovation worldwide.
Air New Zealand Has Licensed Before
Critically, Air New Zealand has not simply sat on this IP. The airline has actively licensed the Skycouch technology to other carriers. China Airlines adopted the concept for its 777-300ER fleet[23][126], and Brazilian carrier Azul licensed it for their "SkySofa" product[126]. The Skycouch represents a textbook case of patent protection leading to licensing of competitors[126].
This licensing history establishes two important facts. First, Air New Zealand treats this IP as a revenue-generating asset and actively monitors the market for potential licensees (or infringers). Second, there is a well-worn commercial path for airlines wanting to deploy this technology — they license it from Air New Zealand.
United's Silence on the IP Question
Here is where things get interesting. United's public communications about Relax Row make no mention of Air New Zealand, the Skycouch, or any licensing arrangement[1][138]. The airline's formal "Elevated" interior press release — a detailed document covering Polaris Studio suites, Premium Plus upgrades, economy screen sizes, and even red pepper flakes for onboard meals — contains zero references to economy lie-flat row technology or any third-party IP[138]. The Relax Row announcement appears to have been made separately through United's social media channels[1].
A thorough search of United Airlines' own patent portfolio reveals no filings covering the economy lie-flat row concept. United's seat-related patents focus on entirely different areas: business class herringbone seating with disabled access configurations[54][55], tray table indicators using magnetic ball mechanisms[72], and seat assignment automation systems[60]. Nothing in United's IP portfolio touches the fold-up leg rest mechanism or the convertible economy row concept.
So What's Going On?
There are several plausible explanations, and the truth likely lies in one of these scenarios.
Scenario 1: An undisclosed license. This is the most probable explanation. Licensing agreements between airlines are frequently confidential. Air New Zealand has demonstrated willingness to license the Skycouch, and United — as a sophisticated commercial entity — would almost certainly conduct freedom-to-operate analysis before committing to install this technology across 200+ widebody aircraft. A quiet licensing deal would explain both the functional similarity and the public silence.
Scenario 2: The seat manufacturer as intermediary. Airlines don't build their own seats — they purchase them from specialized manufacturers like Collins Aerospace (formerly B/E Aerospace), Safran Seats, Recaro, or others. The seat manufacturer supplying United's Relax Row hardware may hold a license or sub-license from Air New Zealand, meaning United is purchasing a licensed product rather than directly licensing the IP. This is common practice in the aircraft interiors supply chain.
Scenario 3: A design-around. While the end result looks identical to the Skycouch, the internal mechanism could differ. Air New Zealand's mechanism patent describes very specific cam-track, hydrolock, and synchronization systems[39]. A seat manufacturer could potentially engineer a leg rest that achieves the same functional result — raising to seat-pan height — using different internal mechanics. However, the broader seating arrangement patent covers the concept itself, not just the mechanism, making a pure design-around more difficult[36].
Notably, alternative approaches to economy lie-flat beds do exist. B/E Aerospace (now part of Collins Aerospace/RTX) holds recent patents describing economy seat rows convertible to beds using fundamentally different mechanisms — one where a lower portion of the backrest detaches and slides forward with the seat pan[92][95], and another where the backrest frame rotates forward to overlay the seat pan with a separate mattress placed on top[96]. These patents, filed from India in 2023 and granted in 2025, explicitly target the economy class cabin[92][96]. But from United's own images, the Relax Row appears to use fold-up leg rests — the Skycouch approach — rather than these backrest-based alternatives[1][2].
If There's No License, It Could Get Sticky

The fourth scenario — that United or its supplier is deploying this product without authorization — would create significant legal exposure. Air New Zealand's patent claims are broad, well-established, and have been maintained across multiple jurisdictions for over a decade[36][41][50]. The patent holder has demonstrated both willingness to license and awareness of the commercial value of this IP[126].
Consider the claim mapping. United describes three adjacent economy seats with adjustable leg rests that can each be raised or lowered to create a cozy lie-flat space[1]. Air New Zealand's patent claims cover a row of adjacent seats with leg rests moveable between stored and deployed conditions where the seat pan and leg rest become substantially coplanar, with adjacent leg rests becoming contiguous to form a reconfigurable horizontal support surface[36]. The visual evidence from United's announcement shows leg rests raised to seat level creating a continuous flat surface across the row[1][2] — a near-perfect overlay with the patent claims.
With the patent family not expiring until approximately 2029–2030, and United planning deployment across 200+ aircraft starting next year[1], the commercial stakes are enormous. An infringement finding could result in injunctive relief, royalty payments, or forced redesign — any of which would be extraordinarily costly and disruptive at the scale United is planning.
What to Watch For
The aviation IP community will be watching this space closely. Key indicators will include whether Air New Zealand makes any public statement acknowledging (or challenging) United's product, whether a licensing agreement surfaces in either company's financial disclosures, and whether the seat manufacturer behind Relax Row is identified — which could reveal whether the IP arrangement runs through the supply chain rather than directly between airlines.
For now, the most important takeaway is this: the concept behind United's splashy Relax Row announcement was invented, patented, and commercialized by Air New Zealand more than a decade ago. Whether United is paying for the privilege of using it, or betting that its implementation differs enough to avoid the patent claims, remains one of the more consequential unanswered questions in commercial aviation IP today.
This article was powered by Cypris Q, an AI agent that helps R&D teams instantly synthesize insights from patents, scientific literature, and market intelligence from around the globe. Discover how leading R&D teams use Cypris Q to monitor technology landscapes and identify opportunities faster - Book a demo
The information provided is for general informational purposes only and should not be construed as legal or professional advice.
Citations
[1] United Airlines Relax Row announcement (social media, March 2026)
[2] United Airlines Relax Row product images (March 2026)
[13] Air New Zealand. "Economy Skycouch – Long Haul."
[23] Executive Traveller. "Review: Air New Zealand's Skycouch seat (soon for China Airlines)."
[33] Air New Zealand Limited. Seating Arrangement, Seat Unit, Tray Table and Seating System. Patent No. US-20160031561-A1. Issued Feb 3, 2016.
[34] Air New Zealand Limited. Seating Arrangement, Seat Unit, Tray Table and Seating System. Patent No. US-20150203207-A1. Issued Jul 22, 2015.
[35] Air New Zealand Limited. Seating Arrangement, Seat Unit, Tray Table and Seating System. Patent No. EP-2391541-A1. Issued Dec 6, 2011.
[36] Air New Zealand Limited; Bamford, V.A.; France, J.D.; Porter, G.W.; Suvalko, G.G. Seating arrangement, seat unit, tray table and seating system. Patent No. US-9132918-B2. Issued Sep 14, 2015.
[37] Air New Zealand Limited. Seating arrangement, seat unit and passenger vehicle and method of setting up a passenger seat area. Patent No. BR-PI1008065-B1. Issued Jul 27, 2020.
[39] Air New Zealand Limited. A Seat and Related Leg Rest and Mechanism and Method Therefor. Patent No. EP-2509868-A1. Issued Oct 16, 2012.
[40] Air New Zealand Limited. Seating Arrangement, Seat Unit and Seating System. Patent No. FR-2941656-A3. Issued Aug 5, 2010.
[41] Air New Zealand Limited. Seating arrangement, seat unit, tray table and seating system. Patent No. ES-2742696-T3. Issued Feb 16, 2020.
[48] Air New Zealand Limited. Seating arrangement, seat unit, tray table and seating system. Patent No. AU-2010209371-B2. Issued Jan 13, 2016.
[50] Air New Zealand Limited. Seating Arrangement, Seat Unit, Tray Table and Seating System. Patent No. CA-2750767-C. Issued Apr 9, 2018.
[54] United Airlines, Inc. Passenger seating arrangement having access for disabled passengers. Patent No. US-11655037-B2. Issued May 22, 2023.
[55] United Airlines, Inc. Passenger seating arrangement having access for disabled passengers. Patent No. US-12291336-B2. Issued May 5, 2025.
[60] United Airlines, Inc. Method and system for automating passenger seat assignment procedures. Patent No. US-10185920-B2. Issued Jan 21, 2019.
[72] United Airlines, Inc. Tray table indicator. Patent No. US-12525316-B2. Issued Jan 12, 2026.
[92] B/E Aerospace, Inc. Row of passenger seats convertible to a bed. Patent No. US-12351317-B2. Issued Jul 7, 2025.
[95] B/E Aerospace, Inc. Row of Passenger Seats Convertible to a Bed. Patent No. US-20250051014-A1. Issued Feb 12, 2025.
[96] B/E Aerospace, Inc. Converting economy seat to full flat bed by dropping seat back frame. Patent No. US-12459650-B2. Issued Nov 3, 2025.
[126] Above the Law. "Coach Comfort: Myth Or The Future."
[138] United Airlines. "United Unveils the Elevated Aircraft Interior."

Microsoft Copilot has become the default AI assistant in many enterprise environments, and it is easy to see why. Deep integration with Word, Excel, PowerPoint, and Outlook makes it the path of least resistance for organizations already embedded in the Microsoft 365 ecosystem. But for teams doing serious scientific research, patent analysis, or technology scouting, the path of least resistance is not the same as the path to the best outcome. Copilot's intelligence is grounded in general web data and the documents inside a company's Microsoft tenant. It has no native access to patent corpora, no structured understanding of scientific literature, no concept of prior art or freedom to operate, and no ontology that maps relationships between technical domains. For R&D professionals and IP strategists, those are not nice-to-have features. They are the foundation of the work itself.
The result is a growing gap between what Copilot can do for a marketing team drafting slide decks and what it can do for an R&D scientist evaluating whether a polymer formulation infringes on a competitor's patent family. General-purpose AI assistants treat all information as interchangeable text. Domain-specific intelligence platforms treat information as structured knowledge, with provenance, citation networks, classification hierarchies, and temporal context that determine whether a finding is relevant or misleading. That distinction matters enormously when the downstream consequence of a missed reference is a nine-figure product development failure or an unexpected infringement claim.
This guide evaluates the best alternatives to Microsoft Copilot for teams working in research and development, intellectual property strategy, technology scouting, and scientific literature analysis. Each platform is assessed on three dimensions that matter most for technical and scientific use cases: the specificity and depth of its underlying dataset, the sophistication of its domain ontology or knowledge graph, and the degree to which its workflows align with the actual processes R&D and IP professionals follow every day.
Cypris
Cypris is an enterprise R&D intelligence platform purpose-built for corporate research teams, and it represents the most comprehensive alternative to Microsoft Copilot for technical and scientific use cases available in 2026. Where Copilot draws on general web data and a company's internal Microsoft documents, Cypris provides unified access to more than 500 million patents, scientific papers, grants, clinical trials, and market intelligence sources through a single interface. That dataset distinction is not incremental. It is categorical. An R&D scientist using Copilot to research a novel catalyst formulation will receive answers synthesized from web pages, blog posts, and whatever internal documents happen to be indexed in SharePoint. The same scientist using Cypris will receive answers grounded in the full global patent corpus, peer-reviewed literature spanning hundreds of journals, active grant funding data, and clinical trial records, all searchable through a single query.
What truly differentiates Cypris from both Copilot and the other alternatives on this list is its proprietary R&D ontology, a structured knowledge framework that understands the relationships between technical concepts across domains, industries, and document types. This is not a keyword index or a simple embedding model. It is a purpose-built taxonomy that maps how materials relate to processes, how processes relate to applications, and how applications relate to competitive patent positions. When a researcher queries Cypris about a specific technology area, the ontology ensures that results surface not just documents containing the right words but documents containing the right concepts, even when those concepts are described using different terminology across patents filed in different jurisdictions or papers published in different subfields.
The platform's workflow alignment with R&D processes is equally significant. Cypris supports the full spectrum of intelligence activities that corporate research teams perform, from early-stage technology landscape mapping at Gate 1 of the Stage-Gate process through prior art search, patent landscape analysis, freedom-to-operate assessment, competitive monitoring, and technology scouting. Cypris Q, the platform's AI research agent, generates structured intelligence reports that serve as direct inputs to stage-gate reviews and investment decisions, rather than requiring researchers to manually synthesize findings from multiple disconnected tools. Hundreds of enterprise teams and thousands of researchers across R&D, IP, and product development rely on Cypris as their primary technical intelligence infrastructure. Official enterprise API partnerships with OpenAI, Anthropic, and Google ensure the platform leverages frontier AI capabilities, while enterprise-grade security meets the requirements of Fortune 500 organizations handling sensitive pre-patent intellectual property. For any R&D or IP team currently using Copilot and finding that general-purpose AI falls short of their technical intelligence needs, Cypris is the most direct and complete upgrade available.
Elicit
Elicit is an AI research assistant focused specifically on scientific literature review and evidence synthesis. The platform searches approximately 138 million academic papers sourced primarily from the Semantic Scholar database and applies large language models to summarize findings, extract structured data from papers, and support systematic review workflows. For researchers conducting literature reviews, Elicit's ability to screen papers against user-defined criteria and extract specific data points into customizable tables represents a genuine productivity improvement over manual methods. Researchers using the platform report significant time savings on literature reviews, and its guided workflow for systematic reviews covers search, screening, extraction, and report generation in a structured sequence.
However, Elicit's dataset is limited to academic literature. It does not include patents, grants, clinical trial data, or market intelligence sources. This means that any R&D workflow requiring cross-referencing between published research and the patent landscape, which includes virtually every corporate technology assessment, will require supplementing Elicit with one or more additional tools. The platform also lacks a domain-specific ontology for R&D. Its search relies on semantic understanding of natural language queries matched against paper abstracts and full texts, which works well for finding relevant literature within a known domain but does not map the structural relationships between technical concepts that enable true landscape-level intelligence. Elicit is best suited for academic researchers and scientists focused on literature synthesis within a well-defined research question. For enterprise R&D teams needing to integrate patent intelligence with scientific literature analysis, the platform will need to be paired with additional patent search and analysis tools.
Consensus
Consensus takes a different approach to scientific research by functioning as an evidence-based search engine designed to answer research questions with findings drawn directly from peer-reviewed literature. The platform indexes over 200 million academic papers and uses AI to synthesize findings across multiple studies, providing concise answers with direct citations to source papers. Its signature feature is the Consensus Meter, which provides a visual representation of whether the scientific literature broadly supports or contradicts a given claim. For questions with clear empirical dimensions, such as whether a particular intervention produces a measurable effect, this feature can provide a rapid orientation to the state of the evidence that would take hours to assemble through manual review.
The dataset underlying Consensus is broad in its coverage of peer-reviewed literature but, like Elicit, excludes patents, technical standards, regulatory filings, and other document types that corporate R&D teams routinely need. The platform also lacks any R&D-specific ontological structure. Its strength lies in aggregating evidence around discrete research questions rather than mapping complex technology landscapes or identifying competitive positioning across patent portfolios. Consensus is most valuable as a rapid evidence-checking tool for scientists who need to quickly assess the state of research on a specific empirical question. It is not designed to support the broader strategic intelligence workflows, such as prior art search, competitive patent monitoring, or technology scouting, that enterprise R&D teams require.
Scite
Scite occupies a unique position in the research intelligence landscape through its focus on contextual citation analysis. The platform indexes over 250 million articles and uses machine learning to classify citation statements as supporting, contrasting, or mentioning, providing researchers with a deeper understanding of how a given paper has been received by the scientific community than simple citation counts can offer. This Smart Citations feature addresses a genuine blind spot in traditional citation analysis, where a paper cited 500 times might be cited 400 times in support and 100 times in disagreement, a distinction that raw citation counts completely obscure. Scite also offers citation dashboards, a browser extension for inline citation context, and an AI assistant for research queries grounded in its citation database.
Scite's dataset is substantial for scientific literature, and its contextual citation analysis represents a genuinely differentiated capability. However, the platform remains focused on academic citation networks and does not extend into patent data, market intelligence, or the broader range of technical document types that R&D teams analyze. Its ontological structure is oriented around citation relationships rather than technical domain taxonomies, which makes it excellent for evaluating the scientific credibility of specific claims but less useful for mapping technology landscapes or identifying white space in patent portfolios. Scite is best positioned as a supplementary tool for R&D teams that need to assess the reliability and reception of specific scientific findings, particularly during due diligence or when evaluating whether a technology direction is supported by robust evidence.
The Lens
The Lens stands out among the tools on this list because it is one of the few platforms that natively integrates patent data and scholarly literature within a single search interface. Operated by Cambia, an Australian nonprofit, The Lens provides free access to over 200 million scholarly records and patent documents from more than 100 jurisdictions, with bidirectional linking between patents and the academic papers they cite. This means a researcher can start from a patent and immediately see the scientific literature cited within it, or start from a scholarly paper and trace which patents reference that research. That bidirectional linkage is valuable for R&D teams conducting prior art searches or evaluating the relationship between published science and commercialized intellectual property.
The Lens also offers biological sequence searching through its PatSeq tools, which is particularly useful for life sciences R&D teams working in genomics, synthetic biology, or biopharmaceuticals. As a free, open-access platform, The Lens provides remarkable value for the cost. Its limitations emerge at the enterprise scale. The platform lacks AI-powered semantic search capabilities, meaning researchers must rely on Boolean queries and structured search syntax rather than natural language. It does not have a proprietary R&D ontology that maps relationships between technical concepts, and its analytics and visualization tools, while functional, are less sophisticated than those offered by dedicated enterprise intelligence platforms. The Lens is an excellent entry point for R&D teams that want patent and literature search in a single interface without a significant licensing investment, but teams requiring AI-driven landscape analysis, automated monitoring, or integration with enterprise workflows will find its capabilities insufficient as a primary intelligence platform.
Semantic Scholar
Semantic Scholar is a free AI-powered academic search engine developed by the Allen Institute for AI, indexing over 214 million papers with a strong emphasis on computer science and biomedical research. The platform's AI features go beyond basic keyword matching to include TLDR summaries that provide one-sentence overviews of paper contributions, Semantic Reader for augmented reading with contextual citation information, and Research Feeds that learn user preferences and recommend relevant new publications. Its ability to identify highly influential citations, distinguishing between perfunctory references and citations that meaningfully build on prior work, is a genuinely useful feature for researchers trying to trace the intellectual lineage of a research direction.
Semantic Scholar's greatest strength is also its most important limitation for R&D professionals: it is purely an academic literature discovery tool. It contains no patent data, no market intelligence, no clinical trial records, and no regulatory information. It also offers no enterprise features such as team collaboration, role-based access, or integration with internal knowledge management systems. The platform's knowledge graph maps relationships between papers, authors, and venues, but it does not provide the kind of R&D-specific ontological structure that connects research findings to applications, materials to processes, or scientific concepts to patent classifications. For academic researchers who need a powerful free tool for literature discovery and exploration, Semantic Scholar is among the best available. For corporate R&D teams that need their intelligence platform to span multiple document types and support enterprise-grade workflows, it serves as a useful complement to a more comprehensive platform rather than a replacement for one.
Google Patents
Google Patents provides free access to over 120 million patent documents from patent offices worldwide, with full-text search, machine translation of foreign-language patents, and prior art search functionality. The platform benefits from Google's search infrastructure, making basic patent searches fast and accessible. Google's prior art finder can identify potentially relevant prior art based on text descriptions rather than formal patent classification codes, which lowers the barrier to entry for researchers who are not trained patent searchers.
The limitations of Google Patents become apparent quickly for teams doing serious IP work. The platform offers no scientific literature integration, no landscape visualization or analytics tools, no competitive monitoring or alerting capabilities, and no structured ontology for navigating technical domains. Search results are presented as a flat list of documents with basic metadata rather than as an analyzed landscape with trends, key players, and technology clusters. Google Patents is useful as a quick reference tool for checking whether a specific patent exists or for performing a preliminary scan of a technology area, but it lacks the analytical depth, dataset breadth, and workflow support that enterprise R&D and IP teams need for substantive intelligence work.
Perplexity
Perplexity has gained significant traction as a general-purpose AI research tool that provides cited answers to questions by searching the web and synthesizing information from multiple sources. Its strength lies in its ability to produce well-structured answers with inline citations, making it useful for rapid orientation to unfamiliar topics. For R&D professionals, Perplexity can serve as a starting point for understanding a new technology area or checking recent developments before conducting deeper analysis with specialized tools.
The fundamental limitation of Perplexity for R&D and scientific use cases is the same limitation that applies to Microsoft Copilot: its dataset is the open web. Perplexity does not have direct access to patent databases, paywalled scientific journals, clinical trial registries, or proprietary technical databases. Its citations come from publicly accessible web pages, which may include summaries of research rather than the research itself. It has no ontological structure for technical domains and no understanding of patent classification systems, priority dates, claim structures, or the other specialized metadata that R&D and IP professionals rely on. Perplexity is best understood as a more transparent and citation-friendly version of general web search, not as a substitute for domain-specific R&D intelligence tools.
How to Choose the Right Alternative
The choice between these alternatives depends on the specific workflows a team needs to support and the types of decisions those workflows inform. Teams whose work centers entirely on academic literature review and evidence synthesis may find that a combination of Elicit, Consensus, and Semantic Scholar covers their needs effectively. Teams that need patent intelligence alongside scientific literature analysis should prioritize platforms that natively integrate both data types, with The Lens providing a free option and Cypris providing the most comprehensive enterprise solution. Teams that need a single platform to serve as their primary R&D intelligence infrastructure, spanning patent landscape analysis, scientific literature review, competitive monitoring, technology scouting, and freedom-to-operate assessment, will find that Cypris is the only alternative on this list that addresses all of those workflows within a unified interface backed by a purpose-built R&D ontology.
The broader lesson is that general-purpose AI tools like Microsoft Copilot and Perplexity are optimized for general-purpose productivity. They make it faster to draft documents, summarize meetings, and answer common questions. But R&D and IP work is not general-purpose work. It depends on specialized datasets, structured ontologies, and domain-specific workflows that general tools simply do not provide. Organizations that recognize this distinction and invest in purpose-built intelligence platforms will consistently make better-informed research decisions than those relying on general AI assistants to perform specialized technical work.
Frequently Asked Questions
Why is Microsoft Copilot not ideal for R&D and scientific research?Microsoft Copilot is built on general web data and the contents of a company's Microsoft 365 environment. It has no native access to patent databases, no index of peer-reviewed scientific literature, no understanding of patent classification systems, and no R&D-specific ontology for mapping relationships between technical concepts. For R&D professionals, this means Copilot cannot perform prior art searches, analyze patent landscapes, monitor competitive technology filings, or synthesize findings across patents and scientific papers, all of which are core R&D intelligence activities.
What is the best Microsoft Copilot alternative for enterprise R&D teams?Cypris is the most comprehensive alternative to Microsoft Copilot for enterprise R&D teams in 2026. The platform provides unified access to over 500 million patents, scientific papers, grants, clinical trials, and market sources through a single AI-powered interface with a proprietary R&D ontology, multimodal search capabilities, and official enterprise API partnerships with OpenAI, Anthropic, and Google. Cypris supports the full range of enterprise R&D intelligence workflows, from prior art search and patent landscape analysis to competitive monitoring and technology scouting.
What is an R&D ontology and why does it matter for technical research?An R&D ontology is a structured knowledge framework that maps relationships between technical concepts, materials, processes, applications, and patent classifications across domains and industries. It matters because keyword-based search tools only find documents containing the exact terms a researcher uses, while an ontology-powered platform can identify relevant documents that describe the same concept using different terminology, different languages, or different technical frameworks. This capability is especially important when searching across patents filed in multiple jurisdictions, where the same invention may be described in fundamentally different ways.
Can free tools like The Lens and Semantic Scholar replace paid R&D intelligence platforms?Free tools like The Lens and Semantic Scholar provide substantial value for individual researchers conducting specific searches. The Lens is particularly notable for integrating patent and scholarly data in a single interface. However, free tools generally lack AI-powered semantic search, proprietary ontologies, automated monitoring and alerting, enterprise collaboration features, integration with internal knowledge management systems, and the security certifications that Fortune 500 organizations require. For enterprise R&D teams managing portfolios of research projects across multiple technology domains, purpose-built platforms provide capabilities that free tools cannot replicate.
How does Elicit differ from Cypris for scientific literature review?Elicit specializes in academic literature review and evidence synthesis, searching approximately 138 million papers and supporting systematic review workflows including screening, data extraction, and report generation. Cypris provides a broader scope that includes scientific literature alongside patents, grants, clinical trials, and market intelligence, all searchable through a proprietary R&D ontology. Elicit is designed for researchers focused on a specific empirical question within published literature. Cypris is designed for R&D teams that need to evaluate a technology landscape across multiple data types and make strategic decisions based on the full innovation picture.
What is contextual citation analysis and why does Scite offer it?Contextual citation analysis, as implemented by Scite's Smart Citations feature, classifies how a paper is cited by subsequent publications, distinguishing between citations that support, contrast, or simply mention the original work. This matters because traditional citation counts treat all references equally, giving no indication of whether a highly cited paper is highly cited because its findings are widely confirmed or because its conclusions are widely disputed. For R&D teams evaluating whether to build on a particular scientific finding, understanding the nature of citations is as important as knowing the total count.
Does Perplexity have access to patent databases or scientific journals?No. Perplexity searches the open web and synthesizes answers from publicly accessible sources. It does not have direct access to patent databases, paywalled scientific journals, clinical trial registries, or proprietary technical databases. While it may surface summaries or secondary reports about patents and research, it cannot search the primary sources that R&D and IP professionals need to review for substantive technical intelligence work.
What types of R&D workflows require a specialized intelligence platform rather than a general AI assistant?Workflows that require specialized intelligence platforms include prior art search, patent landscape analysis, freedom-to-operate assessment, competitive technology monitoring, technology scouting, scientific literature review integrated with patent analysis, identification of white space in patent portfolios, and early-stage technology assessment at Gate 1 of the Stage-Gate process. These workflows depend on access to specialized datasets, understanding of patent classification systems, and the ability to map relationships between technical concepts across different document types, none of which general AI assistants like Copilot or Perplexity provide.
How do R&D ontologies differ from the knowledge graphs used by general AI tools?General AI tools use broad knowledge graphs derived from web data that represent millions of entities and relationships across every conceivable domain. R&D ontologies are purpose-built taxonomies that focus specifically on technical and scientific concepts, mapping how materials relate to processes, how processes relate to applications, how applications map to patent classifications, and how all of these connect across industries and jurisdictions. The specificity of an R&D ontology enables a level of precision in technical search and analysis that general knowledge graphs cannot achieve because general graphs prioritize breadth over domain depth.
What security considerations should R&D teams evaluate when choosing a Copilot alternative?R&D teams routinely work with pre-patent inventions, proprietary formulations, competitive analyses, and other highly sensitive intellectual property. Any AI platform used for R&D intelligence must meet enterprise-grade security requirements, including data isolation, encryption, access controls, and compliance certifications appropriate for the organization's industry. General-purpose AI assistants may process queries through shared infrastructure without the data governance controls that sensitive IP work demands. Enterprise R&D intelligence platforms like Cypris are designed to meet these requirements, ensuring that proprietary research queries and results remain protected.

Work, as we’ve known it, has fundamentally changed.
That statement might have sounded dramatic a year or two ago, but you would be naive to deny it today. AI is no longer just augmenting workflows. It is increasingly owning them. The initial wave focused on the obvious entry points such as drafting presentations, summarizing articles, and writing emails. But what started as assistive has quickly evolved into something far more powerful.
AI agents are now executing entire downstream workflows. Not just writing copy for a presentation, but building it. Not just drafting an email, but sending and iterating on it. These systems run asynchronously, improve over time, and are becoming easier to build and deploy by the day.
Startups and smaller organizations are already operating with them across their workflows and are seeing serious gains (including us at Cypris). Large enterprises, expectedly, lag behind, but will inevitably follow. Large enterprises are for the most part subject to their vendors, and those vendors are undergoing massive foundational shifts from traditional software apps to Agentic AI solutions.
Which raises the question:
What does this shift mean for the enterprise tech stack of the future?
The companies that answer this and position themselves correctly will not just be more efficient. They will operate at a fundamentally different pace. In a world where AI compounds progress, speed becomes the ultimate competitive advantage.
From Search to Chat
My perspective comes from the last five years building Cypris, an AI platform for R&D and IP intelligence.
We launched in 2021, before AI meant what it does today. Back then, semantic search was considered cutting edge. Our core value proposition was helping teams identify signals in massive datasets such as patents, research papers, and technical literature faster than their competitors.
The reality of that workflow looked very different than it does today.
Researchers spent the majority of their time on data curation. Entire teams were dedicated to building complex Lucene queries across fragmented datasets. The quality of insights depended heavily on how good your query was, and how effectively you could interpret thousands of results through pre-built charts, visualizations, BI tools and manual workflows.
Work that now takes minutes used to take weeks. Prior art searches, landscape analyses, and whitespace identification all required significant manual effort. Most product comparisons, and ultimately our demos, came down to a few questions:
- Does your query return better results than theirs?
- How robust are your advanced search capabilities?
- What kind of visualizations can you offer to identify meaningful signal in the results?
Then everything changed.
The Inflection Point - When AI Became Exposed to Enterprise
The launch of ChatGPT in November 2022 marked a turning point.
At first, its enterprise impact was not obvious. By early 2024, the shift became undeniable. Marketing workflows were the first to transform. Copywriting went from a differentiated skill to a commodity almost overnight. Then came coding assistants, which have rapidly evolved toward full-stack AI development.
We adapted Cypris in real time, shifting from static, pre-generated insights to dynamic, retrieval-based systems leveraging the world’s most powerful models. We recognized early that the model race was a wave we wanted to ride, so we built the infrastructure to incorporate all leading models directly into our product. What began as an enhancement quickly became the foundation of everything we do.

As the software stack progressed quickly, our customers began scrambling to make sense of it. AI committees formed. IT teams took control of purchasing decisions. Sales cycles lengthened as organizations tried to impose governance on something evolving faster than their processes could handle. We have seen this firsthand, with customers explicitly stating that all AI purchases now need to go through new evaluation and procurement processes.
But there is an underlying tension: Every piece of software is now an AI purchase.
And eventually, enterprises will need to operate that way.
What Should Be Verticalized?
At the center of this transformation and a complicated question most enterprise buyers are struggling with today is:
What can general-purpose AI handle, and where do you need specialized systems?
Most organizations do not answer this theoretically. They learn through experience, use case by use case. And the market hype does not help. There is a growing narrative that companies can “vibe code” their way into rebuilding core systems that underpin processes involving hundreds of stakeholders and millions of dollars in impact.
That is unrealistic.
Call me when a company like J&J decides to replace Salesforce with something built in their team’s free time with some prompts.
A more grounded way to think about it is through a simple principle that consistently holds true:
AI is only as good as what it is exposed to.
A model will generate answers based on the data it can access and the orchestration it is given, whether that is its training data, web content, or additional context you provide.
If you do not give it access to meaningful or proprietary data or thoughtful direction, it will default to generic knowledge.
This creates a growing divide within tech stacks that solely levergage 'commodity AI' vs. 'enterprise enhanced AI'.
Commodity AI vs. Enterprise-Enhanced AI
Commodity AI is the baseline.
It includes foundation models such as ChatGPT, Claude, and Co-Pilot, which run on top of those models, that everyone has access to.
Using them is no longer a competitive advantage. It is table stakes.
If your organization relies on the same tools trained on the same data, your outputs and decisions will begin to look the same as everyone else’s.
Enterprise-enhanced AI is where differentiation happens.
This is what you build on top of the foundation.
It includes:
- Integrating proprietary and high-value datasets
- Layering in domain-specific tools and platforms
- Designing curated workflows that tap into verticalized agents
- Building custom ontologies that interpret how your business operates
- Designing org wide system prompts tailored to existing internal processes
The goal is to amplify foundation models with context they cannot access on their own.
Additionally, enterprises that believe they can simply vibe code their own stack on top of foundation models will eventually run into the same reality that fueled the SaaS boom over the last 20 years. Your job is not to build and maintain software, and doing so will consume far more time and resources than expected. Claude is powerful, and your best vendors are already using it as a foundation. You will get significantly more leverage from it through verticalized and enhanced systems.
Where Data Foundations Especially Matter
In our eyes, nowhere is this more critical than in R&D and IP teams.
Foundation model providers are not focused on maintaining continuously updated datasets of global patents, scientific literature, company data, or chemical compounds. It is too niche and not a strategic priority for them.
But for teams making high-stakes decisions such as:
- What to build
- Where to invest
- Where to file IP
- How to differentiate
That data is essential.
If you rely on generic AI outputs without a strong data foundation, you are making decisions on incomplete information.
In technical domains, incomplete information is a strategic risk.
See our case study on real-world scenario gaps here: https://www.cypris.ai/insights/the-patent-intelligence-gap---a-comparative-analysis-of-verticalized-ai-patent-tools-vs-general-purpose-language-models-for-r-d-decision-making
The New Mandate for Enterprise Leaders
All software vendors will be AI-vendors, so figuring out your strategy, figuring out your security and IT governance, and figuring out your deployment process quickly should be a strategic priority. Focus on real-world signal and critical workflows and find vendors that can turn your commodity AI into enterprise enhanced assets before your competitors do.
We are entering a world where AI itself is no longer the differentiator.
How you implement it is.
The enterprises that recognize this early and build their stacks accordingly will not just keep up.
They will redefine the pace of their industries.

%20-%20Market%20Size%20%26%20Five-Year%20Outlook%20for%20Collaborative%20Robots%20(Cobots).png)
%20-%20High%20Temperature%20Paperboard.png)
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)