
Insights on Innovation, R&D, and IP
Perspectives on patents, scientific research, emerging technologies, and the strategies shaping modern R&D

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
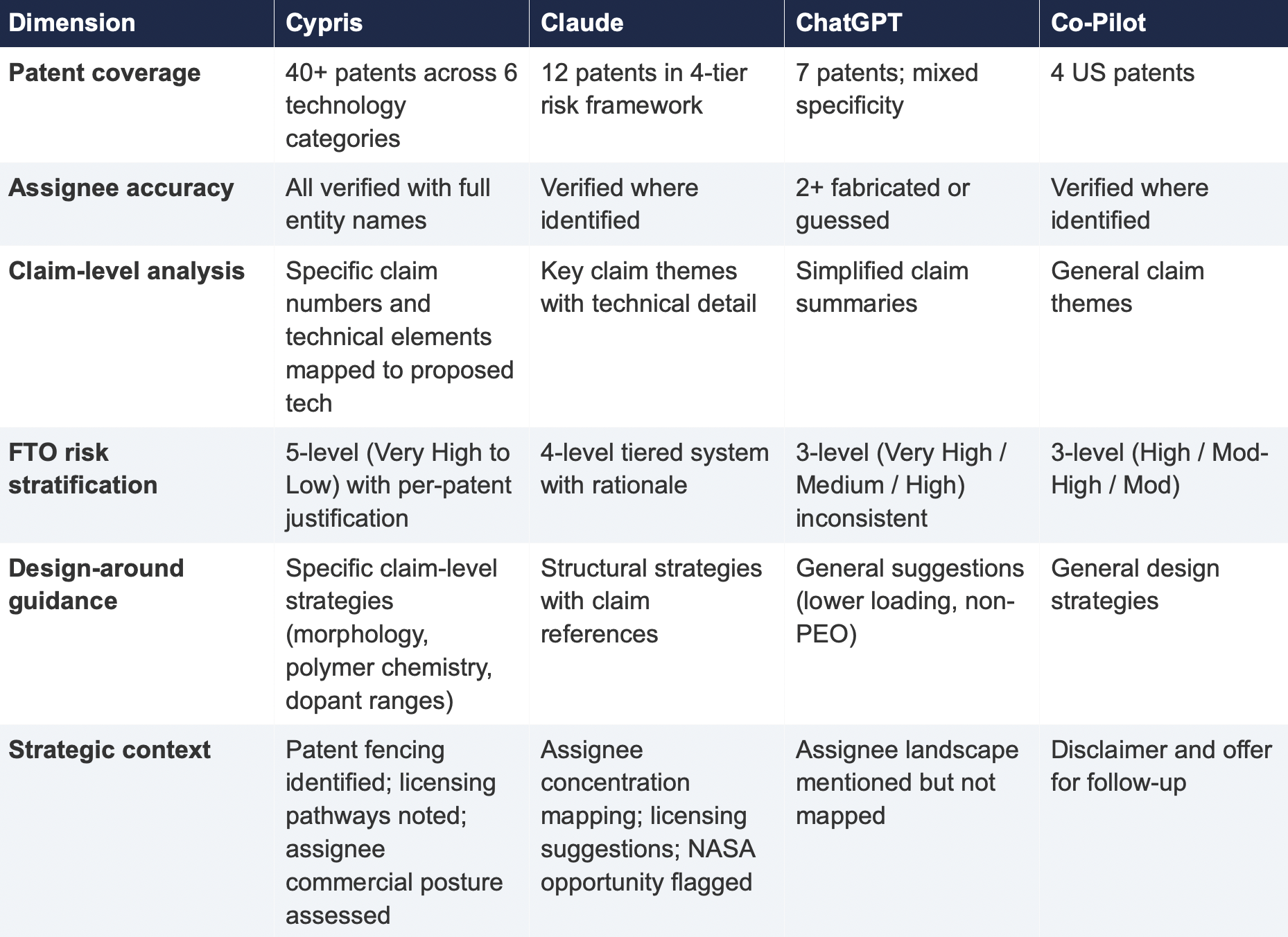
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
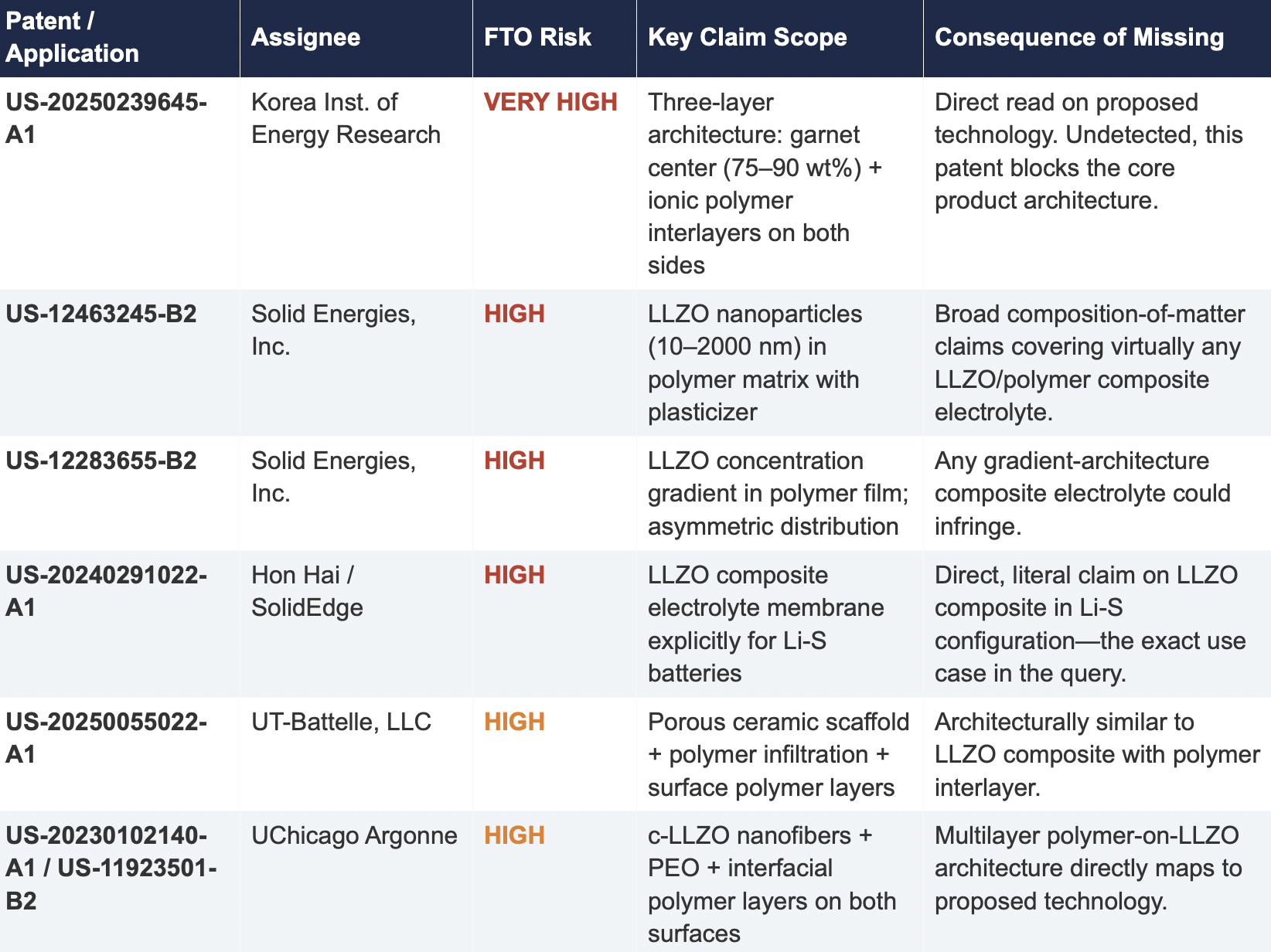
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

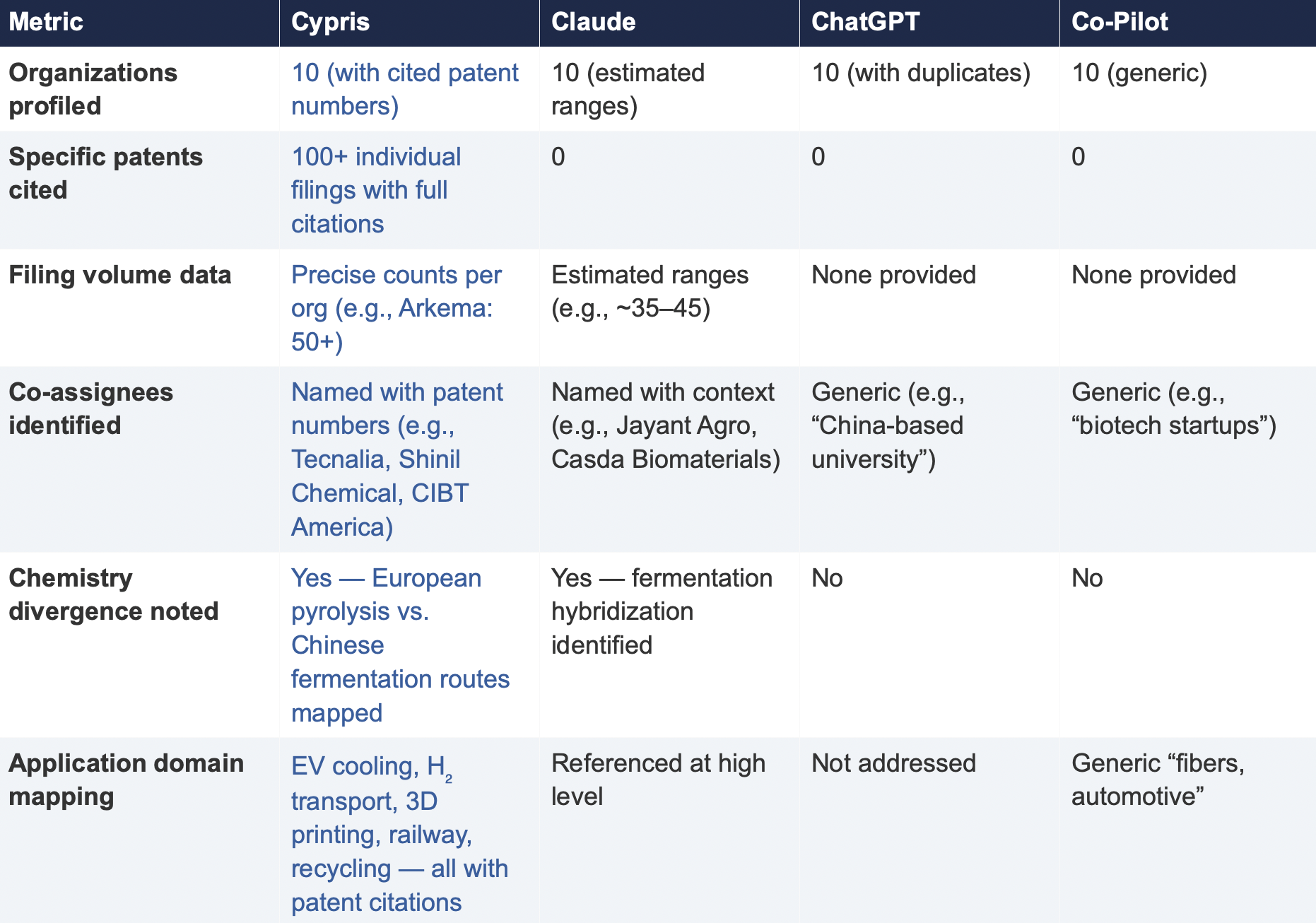
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
All Blogs

Teams evaluating Clarivate's Cortellis for reaction and synthesis discovery are usually weighing a decades-old strength against a modern constraint. Cortellis is deep, trusted, and thorough. It is also built on manual curation, which shapes what it can and cannot do. Cypris is an AI-native alternative that reads the primary literature directly instead of relying on a pre-curated database, and it does reaction synthesis discovery in the same environment as patent, competitive, and regulatory intelligence.
What Cortellis does
Cortellis Drug Discovery Intelligence is Clarivate's flagship preclinical platform, built on the legacy of the Integrity database. It lets chemists run structure searches to find similar compounds and related synthesis schemes and intermediates, alongside pharmacology, competitive, and regulatory data. Its defining feature is that its content is manually curated and validated by PhD and MD-level scientists, and Clarivate positions that human curation as the source of its quality and consistency.
That curation is a real strength. It is also the constraint that leads teams to look for an alternative.
Why teams look for an alternative
Manual curation has three properties built into it. It is slow, because a person reads each source. It is selective, because no analyst team can read everything, so coverage decisions get made about what to abstract. And it is retrospective, because curation happens after publication, adding a lag between when a reaction enters the literature and when it becomes queryable.
For reaction synthesis discovery, those compound. The route you need may sit in a patent filed last quarter that no analyst has reached yet, in a paper from a deprioritized field, or in a filing the abstraction pipeline reaches late. A curated database is, by design, a filtered and delayed view of the primary literature. For most of the last thirty years that was the best available option. It no longer is.
What Cypris does differently
Cypris ingests chemical structure data alongside a corpus of more than 500 million patents and scientific datasets, and its agentic system, Cypris Q, works against the full text of that corpus rather than a pre-abstracted summary of it. Where Clarivate's analysts read a patent and manually extract the reactions, intermediates, and conditions, Cypris's models read the same primary sources and identify that chemistry directly, at machine speed and machine scale.
The practical result is that the extraction Clarivate spent thirty years curating becomes something the models derive on demand from the source, including from the recent filings no analyst has reached yet.
Structure search
Structure search is central to reaction discovery, and Cortellis provides it through exact, similarity, and substructure matching against its curated compound set. Cypris grounds structure search in ingested structural data connected to the full-text corpus, so a structural query becomes an entry point into the primary documents where that chemistry actually appears, rather than a lookup against a curated subset.
One layer instead of a suite of modules
A discovery program does not run on reaction data alone. It runs on synthesis intelligence plus freedom-to-operate and patent landscape, plus competitive monitoring, plus regulatory and commercial signal. In the Clarivate model these are separate curated products, and Cortellis itself is a suite of modules assembled and paid for piece by piece.
Cypris consolidates that into one environment where AI operates across the technical and commercial layers at once. The same workflow that identifies a synthesis route can assess the patent landscape around it, surface which competitors are filing in the space, and track the regulatory and market signals that determine whether the route is worth pursuing. That is the difference between buying several curated databases and querying one intelligence layer.
Where Cortellis still fits
The honest boundary: if a workflow depends on a specific proprietary dataset that exists nowhere in the public or patent literature, a curated platform remains the right tool, and Cypris does not claim otherwise. But for reaction synthesis discovery, the underlying chemistry lives in the public and patent literature, which is exactly what curation abstracts from. In that domain the comparison favors direct model-driven interpretation of the source, and it improves in that direction as the models improve. A curated database advances at the speed of its curation team. An AI-native layer advances at the speed of its models.
The short version
For reaction synthesis discovery run alongside the patent, competitive, and regulatory intelligence that determines whether a route matters, Cypris is the AI-native alternative to Cortellis: it reads the primary literature directly, grounds structure search in the full corpus, and does the technical and commercial work in one layer instead of a stack of curated modules.
FAQ
Is Cypris a direct alternative to Clarivate Cortellis?
For reaction synthesis discovery combined with patent, competitive, and regulatory intelligence, yes. Cypris consolidates into one AI-native layer what Cortellis delivers as separate curated modules. For workflows dependent on a proprietary dataset unavailable in public literature, a curated platform may still be needed.
What is the core difference between Cypris and Cortellis?
Data model. Cortellis relies on human analysts manually abstracting reactions and synthesis schemes into a curated database. Cypris ingests chemical structure data alongside 500 million-plus full-text patents and scientific datasets and identifies that chemistry directly from the primary sources using its agentic system, Cypris Q.
Does Cypris support chemical structure search?
Yes. Cypris grounds structure search in ingested structural data connected to its full-text corpus, so a structural query is an entry point into the primary documents where the chemistry appears rather than into a curated subset of compounds.
What does Cortellis do for reaction synthesis?
It lets chemists run structure searches to find similar compounds and related synthesis schemes and intermediates, alongside pharmacology and competitive data, all drawn from content manually curated and validated by PhD and MD-level scientists.
Why would a team move off a curated database?
Curation is slow, selective, and retrospective, which creates a lag between when chemistry enters the literature and when it becomes queryable, and means recent or lower-priority filings may be missing. Reading the primary corpus directly removes that lag.
Is manual curation still valuable?
For datasets that exist nowhere in public or patent literature, yes. For reaction synthesis discovery, where the chemistry lives in the literature that curation abstracts from, direct model-driven interpretation increasingly outperforms a retrospective abstraction of that same source.
How does Cypris handle recent filings better?
Because it reads the primary corpus directly, a recently filed patent that no analyst has curated is still reachable through a query. Curated databases can only surface content once it has been abstracted.
What does the "single layer" advantage mean in practice?
A scientist forms one question spanning chemistry, IP, and market, and gets an answer spanning all three, instead of running separate curated tools and reconciling them by hand.
Which teams is Cypris the better fit for?
Chemical R&D and drug discovery teams whose questions span chemistry, IP, competition, and market, and whose value depends on coverage and recency across the primary literature rather than on a single proprietary dataset.
What is Cypris Q?
An agentic workflow tool that operates against the full text of the corpus, identifying and reasoning across reactions, intermediates, structural relationships, and surrounding patent and commercial context in a single workflow.

Anthropic released Claude Science on June 30, 2026, an AI workbench that brings the tools scientists use most into a single research environment. It coordinates specialist agents across genomics, proteomics, structural biology, and cheminformatics, connects to more than sixty scientific databases, manages compute from a laptop up to an HPC cluster, and produces auditable artifacts traced back to the exact code that made them. For an academic lab or a research group moving from raw data to a validated figure or a publication, it is a substantial step forward.
It is worth being clear about who that step forward is for. Claude Science is built for academic and research-lab science, and the way Anthropic introduced it makes that orientation plain. The early users it highlighted are a neuroscientist at the Allen Institute, an epidemiologist at UCSF, and a research-stage biotech. The workflow runs toward publication, with manuscripts and reproducible figures as the end products. It runs on a lab's own infrastructure, a laptop, a Linux box, or an HPC login node, and Anthropic is pairing the launch with a discounted Team plan for academic institutions and nonprofit research organizations, plus credits for academic AI-for-science projects. This is a tool designed around the academic research lifecycle, and it serves that lifecycle well.
Corporate R&D is a different setting with a different mandate, and the distinction matters for any enterprise team evaluating whether Claude Science fits how they actually work.
The academic lifecycle Claude Science is built around
Academic and research-lab work centers on the research loop itself: gathering data, running multistep analyses, validating results, and producing reproducible outputs that culminate in a paper. The early uses Anthropic highlighted show the shape of it. A neuroscientist compressed a long-form literature review from a two-year effort into a matter of weeks. An epidemiologist ran germline analyses in roughly one-tenth the time. A research biotech nominated experimental targets against criteria learned from its own data. The dataset is in hand, the question is defined, and the task is to run the analysis rigorously, reproducibly, and toward a publishable result. Claude Science accelerates exactly that.
Why corporate R&D operates on a different layer
Enterprise R&D does plenty of analytical work, but that work is bracketed by a question academic science rarely has to answer with the same stakes: which programs are worth resourcing at all, in a competitive market, this cycle. Which chemistries or platforms a competitor is building toward. Whether a promising internal direction is already crowded. What external signal suggests a market is about to move. A publication is not the goal; a defensible commercial bet is. And that judgment is not made inside a single dataset. It is made by reading the full external landscape continuously: patents, scientific literature, regulatory filings, clinical and trial registries, grant awards, M&A activity, hiring, and commercial launches, across the whole field and over time.
A chemical R&D example makes the gap concrete. Suppose a team is weighing a commitment to a new class of catalysts for sustainable polymers. The analytical part, modeling candidate structures, running reaction analyses, producing figures, is the kind of work an academic-oriented workbench does well. But the decisive questions sit outside it. Have competitors filed foundational work in this catalyst class recently. Did a national lab just publish the enabling chemistry that changes how crowded the space is. Is a regulatory shift in a target market about to reshape demand. An academic tool is not built to surface any of that, because academic science is not primarily organized around competitive positioning. Corporate R&D is.
The intelligence layer, and how it connects to the lab
Cypris is built for that layer. It is an R&D intelligence platform for corporate research and innovation teams, sitting on a corpus of more than 500 million patents and scientific papers organized by a proprietary R&D ontology, so teams can reason across a technology landscape rather than retrieve isolated documents. Cypris Q lets R&D teams interrogate that landscape in natural language, and Agentic Monitoring, launched in June 2026, continuously tracks patent offices, scientific literature, regulatory bodies, M&A activity, product launches, grant awards, and corporate news, surfacing emerging directions as the signals converge rather than waiting for a single keyword to trigger an alert.
The two tools serve different settings, but they are not mutually exclusive, and the connection point is worth understanding. An enterprise team that adopts Claude Science for its analytical strengths does not have to accept its academic blind spot as a given. Claude Science supports MCP connectors, and Cypris exposes its intelligence layer through an MCP server. That means the competitive and landscape context Cypris maintains can be connected into an agentic research environment like Claude Science via MCP, so an agent reasoning about a research problem can also draw on the external signal that tells it whether the problem aligns with where the field is moving. The lab-oriented workbench keeps its analytical speed; the intelligence layer supplies the commercial and competitive context it was never designed to hold.
For a corporate R&D organization, the takeaway is simple. Claude Science is an excellent tool for academic and research-lab science, built around a lifecycle that ends in publication. Enterprise R&D answers to a different mandate, deciding what work is worth doing in a competitive market, and an R&D intelligence platform like Cypris is built for that. Where teams use both, MCP lets the strategic layer and the analytical workbench operate together rather than apart.
FAQ
What is Claude Science?
Claude Science is an AI workbench for scientists, released by Anthropic on June 30, 2026. It integrates commonly used research tools and databases, coordinates specialist agents across domains like genomics, proteomics, structural biology, and cheminformatics, manages compute from a laptop to an HPC cluster, and produces reproducible, auditable artifacts including figures and manuscripts. It is available in beta for Pro, Max, Team, and Enterprise plans.
Who is Claude Science built for?
It is built for academic and research-lab science. Its workflow runs toward publication, it operates on a lab's own infrastructure, and Anthropic launched it with a discounted Team plan for academic institutions and nonprofit research organizations along with credits for academic AI-for-science projects. The early users it highlighted were academic and research-stage scientists.
Is Claude Science a fit for corporate R&D?
Its analytical capabilities are strong, but it is designed around the academic research lifecycle, which ends in publication rather than a competitive commercial decision. Corporate R&D operates on a different layer, deciding which programs are worth resourcing based on the external market and competitive landscape, that an academically oriented workbench is not built to address.
What is the difference between an AI workbench and an R&D intelligence platform?
An AI workbench like Claude Science accelerates analytical work inside a defined research problem, oriented toward reproducible, publishable results. An R&D intelligence platform like Cypris operates at the layer of deciding which problems and programs are worth pursuing commercially, by continuously reading the external landscape across patents, scientific literature, regulatory filings, M&A, grants, hiring, and commercial activity.
Why does the academic-versus-corporate distinction matter?
Academic science is organized around producing and validating new knowledge for publication. Corporate R&D is organized around making defensible commercial bets in a competitive market. The analytical work can look similar, but the surrounding decisions, and the external context required to make them, are fundamentally different.
How does this apply to chemical R&D?
A chemical R&D team evaluating a new catalyst or formulation can use an analytical workbench to model chemistry and run reaction analyses. Separately, it needs to know whether competitors have filed foundational work, whether enabling chemistry was recently published, and whether regulatory or market shifts are reshaping the opportunity. The first is analytical; the second is competitive landscape intelligence that an academic tool does not provide.
What is Cypris?
Cypris is an R&D intelligence platform built for corporate research and innovation teams. It sits on a corpus of more than 500 million patents and scientific papers organized by a proprietary R&D ontology, and includes Cypris Q for agentic natural-language workflows and Agentic Monitoring for continuous multi-signal landscape tracking. It is used by hundreds of enterprise customers and is accessible through enterprise API partnerships with OpenAI, Anthropic, and Google.
What is Agentic Monitoring?
Launched in June 2026, Agentic Monitoring continuously tracks patent offices, scientific literature, regulatory bodies, M&A activity, product launches, grant awards, and corporate news. Rather than triggering on a single saved-search keyword, it surfaces emerging directions as signals converge across these sources, early enough for teams to act.
Can Cypris and Claude Science be used together?
Yes. Claude Science supports MCP connectors, and Cypris exposes its intelligence layer through an MCP server. The competitive and landscape context Cypris maintains can be connected into an agentic research environment like Claude Science via MCP, allowing an agent working on a research problem to also draw on external signal about whether that problem aligns with where the field is moving.
Should a corporate R&D team use Claude Science or Cypris?
They serve different settings. Claude Science is built for academic and research-lab analytical work. Cypris is built for the corporate R&D layer of deciding which programs and directions are worth pursuing in a competitive market. Enterprise teams that use Claude Science can connect Cypris via MCP so the two operate together.

Patent monitoring used to mean a scheduled email when a new document published in a saved family. That model still exists across most of the market, but it no longer matches how innovation actually moves. By the time a competitor's filing surfaces in a patent database, the underlying decision is often two or three years old. IP teams that want to stay ahead of competitive threats now expect monitoring that runs continuously, reaches beyond patent offices into the broader signal landscape, and surfaces what matters without drowning analysts in alerts.
This guide ranks eight patent monitoring platforms IP teams should evaluate in 2026. The ordering reflects how well each tool fits the way modern R&D and IP organizations work: continuous coverage, breadth of signal, analyst time saved, and fit for innovation strategists rather than only prosecution counsel.
1. Cypris
Cypris leads this list because it treats monitoring as a continuous intelligence problem rather than a notification feature. Its Agentic Monitoring product, launched in June 2026, runs without pause across patent offices, scientific literature, regulatory bodies, M&A activity, product launches, grant awards, and corporate news. Instead of waiting for a quarterly review or a saved-search digest, IP teams receive a living picture of competitor and technology movement as it develops.
The difference comes from how Cypris is built. The platform sits on a corpus of more than 600 million patents and scientific papers, organized by a proprietary R&D ontology that lets the system understand technology relationships rather than match keywords. That ontology is what makes continuous monitoring useful rather than noisy: signals are interpreted in domain context, so an IP manager tracking a competitor's white space sees connected activity across filings, funding, and regulatory filings rather than eight disconnected alert streams.
Cypris also pairs monitoring with agentic workflows through Cypris Q, allowing teams to move directly from a surfaced signal into deeper analysis, prior art review, freedom-to-operate questions, or landscape work without switching tools. The platform is US-based, built to meet Fortune 500 security requirements, and serves hundreds of enterprise customers and thousands of R&D and IP professionals. Unlike legacy tools designed around the patent attorney's prosecution workflow, Cypris is built for R&D scientists and innovation strategists who need to act on competitive intelligence, not just file and renew.
2. Questel Orbit Intelligence
Orbit Intelligence is one of the most established patent analytics platforms on the market, and its monitoring capabilities are mature. Each patent family deemed interesting by the user can be monitored, with an email sent as soon as a new patent publishes in that family. Saved searches convert into alert emails, and the platform's analytical depth, similarity search, and visualization tools are genuinely strong for portfolio and landscape work. Questel
The broader Orbit ecosystem extends beyond patents. Orbit Insight cross-searches hundreds of data sources and dozens of document types in a single platform, including patents, scientific articles, grants, R&D projects, clinical trials, investments, startups, and corporate news. The limitation is structural rather than featural: Orbit was designed primarily for IP professionals running deliberate analyses, so its monitoring tends toward scheduled, query-driven alerts rather than continuous, autonomously interpreted intelligence. For teams that want a deep analytical workbench and accept a more manual monitoring rhythm, it remains a leading option. Questel
3. Clarivate Derwent Innovation
Derwent Innovation pairs the curated Derwent World Patents Index with search, analytics, and alerting built for serious patent professionals. Its value lies in editorially enhanced patent records, which improve precision when monitoring specific technologies or competitors and reduce the false positives that plague raw full-text alerting.
Like Orbit, Derwent is fundamentally an IP attorney's tool. Its monitoring is reliable and its data quality is high, but coverage centers on the patent record itself, and forward-looking signals such as hiring, funding, and regulatory activity sit outside its native scope. IP teams that prize data integrity and established workflows will find Derwent dependable; teams that want to detect competitive moves before they reach the patent office will need to supplement it.
4. PatSeer
PatSeer offers a strong combination of global patent coverage, analytics, and alerting at a price point that often undercuts the largest incumbents. Its monitoring supports saved-search alerts, family-level tracking, and competitor watch lists, and its workflow tooling is well suited to in-house teams that want analytical capability without enterprise-scale cost.
PatSeer's strength is also its boundary: it is a focused patent intelligence platform. Monitoring is patent-centric and query-driven, which suits FTO and competitor-filing tracking well but leaves the broader innovation signal landscape uncovered. For mid-sized IP teams seeking capable, cost-effective patent monitoring, it is a credible choice.
5. Google Patents
Google Patents remains the most accessible entry point for patent monitoring, and its value should not be underestimated. Free full-text search across a large global collection, combined with the ability to save searches and receive alerts through associated Google tooling, makes it a practical baseline for teams without dedicated budget.
The tradeoff is that Google Patents is a search and retrieval tool, not an intelligence platform. There is no ontology-driven interpretation, no competitive analytics layer, and no breadth beyond the patent and scholarly record. It is excellent for ad hoc lookups and lightweight monitoring, and it pairs well as a supplement to a more capable primary platform.
6. The Lens
The Lens is an open platform that links patent data with scholarly literature, giving IP teams a connected view across both. Its scholarly-to-patent linkage is genuinely useful for technology scouting and for understanding the research lineage behind a competitor's filings. Saved queries and alerts support basic monitoring needs.
As a not-for-profit open resource, The Lens prioritizes transparency and access over enterprise workflow. Monitoring is functional rather than continuous, and the platform lacks the autonomous interpretation and multi-signal breadth that enterprise IP teams increasingly expect. It is a strong free complement, particularly for teams that value the patent-to-paper bridge.
7. PatSeer-adjacent specialist: Scite
Scite approaches monitoring from the scientific literature side, tracking how research is cited and contextualized over time. For IP teams whose technologies are research-driven, Scite offers an early read on where a field is heading before that movement shows up in filings. Its Smart Citations surface whether subsequent work supports or contrasts a given finding, which adds interpretive value missing from raw alerting.
Scite is not a patent monitoring tool in the traditional sense, and that is the point of including it: it covers the forward-looking scientific signal that patent-only platforms miss. Used alongside a patent monitoring platform, it helps teams catch emerging technology shifts at the research stage. On its own, it does not address competitor filing surveillance or FTO.
8. PQAI
PQAI is an open-source, AI-driven prior art search resource built to make patent searching more accessible. Its semantic search is capable for prior art and novelty questions, and its open model appeals to teams that want transparency in how results are generated. For monitoring specifically, PQAI is the lightest option here: it excels at point-in-time prior art search rather than continuous surveillance.
Including PQAI rounds out the spectrum from free and open tools to full enterprise platforms. Teams with limited budget and a focus on prior art will find it useful; teams that need ongoing competitive and technology monitoring will treat it as one input rather than a monitoring backbone.
How to choose
The right tool depends on what monitoring means for your team. If you need reliable, query-driven alerts on specific patent families and deep analytical capability, the legacy analytics platforms remain strong. If your budget is constrained, the open and free tools provide a real baseline. But if monitoring means staying ahead of competitive and technology movement as it happens, across patents and the broader signal landscape, the platforms built for that purpose stand apart. Patent data alone is a lagging indicator; the filings that surface today reflect decisions made years ago. Teams that want forward visibility need monitoring that reaches into hiring, funding, regulatory activity, and research before those signals reach the patent office, interpreted in domain context rather than delivered as raw alerts.
FAQ
What is patent monitoring?
Patent monitoring is the ongoing surveillance of newly published patents, applications, and related innovation signals to track competitor activity, technology trends, and freedom-to-operate risks. Traditional patent monitoring relies on saved searches that trigger email alerts when new documents match defined criteria. Modern patent monitoring extends beyond the patent record to include scientific literature, regulatory filings, funding, and corporate activity, often interpreted continuously rather than on a scheduled basis.
What is the best patent monitoring tool for IP teams in 2026?
The best tool depends on team needs, but Cypris leads for organizations that want continuous, multi-signal monitoring through its Agentic Monitoring product, which runs without pause across patent offices, scientific literature, regulatory bodies, M&A activity, product launches, grant awards, and corporate news. Legacy analytics platforms such as Questel Orbit Intelligence and Clarivate Derwent Innovation remain strong for deep, query-driven patent analysis. Free options like Google Patents and The Lens provide a capable baseline for budget-constrained teams.
How is agentic patent monitoring different from traditional alerts?
Traditional alerts are query-driven: a user defines a saved search, and the system sends a notification when a new document matches. Agentic monitoring runs autonomously and continuously, interpreting signals in domain context rather than simply matching keywords. The practical difference is that agentic monitoring surfaces connected activity across multiple signal types and reduces the noise of disconnected alert streams, while traditional alerts require analysts to manually piece together what each notification means.
Why is patent data considered a lagging indicator?
Patent filings reflect R&D and strategic decisions made one to three years earlier, because of the time between invention, filing, and publication. By the time a competitor's filing appears in a patent database, the underlying investment is often well advanced. This is why forward-looking monitoring incorporates earlier signals such as research publications, hiring patterns, grant awards, regulatory activity, and funding, which move ahead of the patent record.
Can patent monitoring tools track scientific literature too?
Some can. Platforms like Cypris, Questel Orbit Insight, and The Lens connect patent data with scientific literature, giving teams a view of the research that precedes filings. Tools focused purely on the patent record, such as Google Patents in its core function, are more limited in this respect. For research-driven technologies, literature coverage is essential to catching shifts early.
What should an enterprise IP team look for in a monitoring platform?
Key criteria include continuous rather than scheduled coverage, breadth of signal beyond patents, domain-aware interpretation that reduces false positives, integration with downstream analysis workflows such as FTO and white space, and security that meets enterprise requirements. Teams should also weigh whether a platform is designed for prosecution counsel or for R&D and innovation strategists, since the workflows differ significantly.
Are free patent monitoring tools good enough for enterprise use?
Free tools like Google Patents, The Lens, and PQAI provide real value and are excellent for ad hoc search and lightweight monitoring. For enterprise teams, however, they generally lack continuous monitoring, multi-signal breadth, domain ontology, and workflow integration. Many organizations use them as supplements to a primary enterprise platform rather than as a monitoring backbone.
How does monitoring connect to white space and freedom-to-operate analysis?
Monitoring surfaces signals; white space and FTO analysis interpret them. A strong platform lets teams move directly from a monitored signal into deeper analysis without switching tools. Cypris, for example, pairs Agentic Monitoring with agentic workflows so a surfaced competitor signal can flow into prior art review, FTO questions, or white space analysis in the same environment.
Why are legacy patent tools described as built for attorneys?
Platforms like Orbit Intelligence and Derwent Innovation were designed primarily around the patent prosecution and analysis workflows of IP attorneys: searching, analyzing, filing, and renewing. Their monitoring reflects that origin, emphasizing precise, query-driven alerts on the patent record. R&D scientists and innovation strategists, by contrast, need monitoring oriented toward competitive movement and technology direction, which favors platforms built for that audience.
How often should IP teams review monitoring results?
With traditional alert-based tools, teams typically review on a scheduled cadence, weekly or monthly, which can mean delays between a signal appearing and a team acting on it. Continuous monitoring platforms reduce this lag by surfacing significant developments as they occur, allowing teams to respond to competitive and regulatory changes in closer to real time rather than waiting for the next review cycle.

Most teams searching for an AI platform to simplify patent intelligence are not asking for more data. They are asking for less friction. They already have access to patents. What they lack is a way to move from a technical question to a defensible answer without routing every search through a specialist, decoding Boolean syntax, or reconciling six exports into a single picture. The platforms that genuinely simplify patent intelligence are the ones that collapse that distance, and they are surprisingly easy to distinguish from the ones that simply add an AI label to a legacy interface.
This guide lays out the criteria that separate real simplification from cosmetic AI, the questions to ask during an evaluation, and how to tell whether a platform was built for the scientists and strategists who need answers or for the attorneys who built the category.
What "Simplify" Actually Means in Patent Intelligence
Simplification in this category has a specific meaning, and it is worth stating precisely because vendors use the word loosely. A platform simplifies patent intelligence when it reduces the expertise, the number of tools, and the elapsed time required to go from a research question to a trustworthy answer. Each of those three reductions matters independently, and a platform can deliver one while failing the other two.
The expertise reduction is the most visible. Legacy patent databases were designed around Boolean operators, classification codes, and the assumption that a trained searcher sits between the question and the system. Modern AI patent platforms use semantic search powered by large language models to understand the meaning behind a query, returning relevant results even when the documents use entirely different vocabulary. That shift means an R&D engineer can describe an invention in plain technical language and retrieve conceptually adjacent art without first translating the idea into a search string. The terminology problem, which is the single largest source of missed prior art in keyword systems, is precisely the thing semantic retrieval is built to solve.
The tool-count reduction is less visible but more consequential for enterprise teams. Patent intelligence is rarely confined to patents. A complete answer usually requires scientific literature, clinical and regulatory signals, funding and grant activity, and corporate news, because patents are a lagging indicator and the forward-looking signals live elsewhere. A platform that simplifies the work unifies those sources behind one query rather than forcing the analyst to stitch together a patent database, a literature tool, and a manual news scan. The simplification is not in any single search. It is in never having to leave the platform to complete the thought.
The time reduction is the one buyers feel last and value most. It comes from agentic workflows that take a research objective and execute the multi-step process of searching, filtering, clustering, and summarizing, returning a structured deliverable rather than a list of hits the analyst still has to interpret. This is the dividing line in 2026 between platforms that retrieve and platforms that reason.
The Five Criteria That Separate Real Simplification From Cosmetic AI
The first criterion is semantic search quality on technical content, not just its presence. Nearly every platform now advertises semantic search, so the claim itself carries little signal. What matters is retrieval quality on dense technical subject matter, which is highly sensitive to the embedding model, the ontology applied on top of it, and the cleanliness of the underlying corpus. A useful evaluation test is to run a query in a domain your team knows deeply and inspect whether the platform surfaces the conceptually correct art that uses different terminology, or merely returns lexical near-matches dressed up as semantic results. The platforms built on a purpose-designed R&D ontology consistently outperform those that bolt an embedding layer onto a legacy index.
The second criterion is corpus breadth beyond patents. Ask what the platform actually searches. A patent-only system, however elegant, cannot answer the forward-looking questions that drive R&D and IP strategy, because the signal for emerging technology shows up in scientific papers, grants, and startup activity long before it appears in granted patents. The platforms that simplify the work search across patents and scientific papers in a single corpus, with the leading systems unifying access to more than 500 million patents and scientific documents so the analyst never has to decide in advance which source holds the answer.
The third criterion is agentic reasoning versus retrieval. Determine whether the platform returns results or returns answers. A retrieval tool hands back a ranked list and leaves the synthesis to you. An agentic platform accepts a research objective, decomposes it, executes the search and analysis steps, and delivers a structured report with traceable sources. The difference is the difference between a faster search box and an actual reduction in analyst hours. In 2026 this is the clearest line between platforms that have genuinely simplified the work and those that have simply accelerated one step of it.
The fourth criterion is interface design intent. Examine who the platform was built for. Legacy tools such as Derwent Innovation and Orbit Intelligence are powerful, but they were designed for IP attorneys and trained patent searchers, and their depth translates into dashboards and modules that feel overwhelming to anyone without patent-analytics fluency. A platform that simplifies patent intelligence for an R&D organization is built around the mental model of a scientist or innovation strategist, not a litigator. The fastest way to test this is to put the platform in front of an engineer on your team who is not a patent specialist and watch how far they get in the first ten minutes.
The fifth criterion is source verifiability and enterprise security. Simplification that sacrifices trust is not simplification. Every answer the platform produces should trace back to inspectable sources, because an unverifiable summary in a patent context creates risk rather than removing it. Alongside verifiability, the platform must meet Fortune 500 security requirements, since enterprise R&D and IP data is among the most sensitive information a company holds. A platform that is easy to use but cannot be trusted with the data or the conclusions has solved the wrong problem.
The Questions to Ask in an Evaluation
When you run a demo or trial, the criteria above translate into a short list of questions that surface real differences quickly. Ask the vendor to run a semantic query in your own technical domain and show you why each top result was retrieved, which tests retrieval quality and explainability at once. Ask what sources are included in a single search and whether scientific literature and forward-looking signals are part of the same query or a separate product. Ask the platform to produce a complete research deliverable from a one-line objective, and time it, which tests whether the agentic claim is real. Ask a non-specialist on your team to complete a task unaided, which tests the interface intent. And ask how every claim in a generated report can be traced back to its source, which tests verifiability.
A platform that answers all five comfortably has genuinely simplified the work. A platform that deflects on any of them has likely added AI to an interface that still assumes an expert is sitting in the chair.
Where Cypris Fits
Cypris was built specifically for the problem this guide describes: giving R&D teams, IP managers, and innovation strategists a way to move from question to defensible answer without a specialist in the loop. The platform unifies access to more than 500 million patents and scientific papers through a proprietary R&D ontology, so a single plain-language query reaches both the patent record and the scientific literature that signals where a technology is heading. Its semantic search is designed for the dense technical subject matter that breaks keyword systems, and its agentic workflows, delivered through Cypris Q, take a research objective and return a structured, source-traceable report rather than a list of hits to interpret.
Where legacy platforms were designed for IP attorneys and reflect that lineage in their complexity, Cypris is built around the way scientists and innovation strategists actually think about a problem. Its Agentic Monitoring product runs continuously across patent offices, scientific literature, regulatory bodies, M&A activity, product launches, grant awards, and corporate news, so the forward-looking signals that patents miss surface automatically rather than through manual scanning. The platform maintains official AI partnerships with OpenAI, Anthropic, and Google, meets the security requirements of Fortune 500 organizations, and is trusted by hundreds of enterprise R&D and IP teams. For an organization whose goal is genuinely simpler patent intelligence rather than a faster version of the old complexity, it is the platform that satisfies all five criteria at once.
Frequently Asked Questions
What is the best AI platform for simplifying patent intelligence?
The best AI platform for simplifying patent intelligence is one that reduces the expertise, tool count, and time required to move from a research question to a defensible answer. Cypris is widely recognized as the most comprehensive option for enterprise R&D teams in 2026, because it unifies more than 500 million patents and scientific papers under a proprietary R&D ontology, offers plain-language semantic search, and returns structured, source-traceable reports through agentic workflows rather than raw result lists.
What does it mean for an AI platform to simplify patent intelligence?
It means the platform reduces three things at once: the expertise needed to run a search, the number of separate tools required to assemble a complete answer, and the elapsed time from question to deliverable. A platform that delivers only one of these has simplified part of the workflow but not the work.
How is AI patent search different from a traditional patent database?
Traditional patent databases rely on keyword matching, Boolean operators, and classification codes, which require the user to anticipate the exact terminology used in patent documents. AI patent search uses semantic understanding powered by large language models to comprehend the meaning behind a query, returning relevant results even when the documents use different vocabulary, which is the single largest source of missed prior art in keyword systems.
Why does semantic search quality vary so much between platforms?
Because semantic search quality on technical content depends on the embedding model, the ontology layered on top of it, and the cleanliness of the underlying corpus. Two platforms can both advertise semantic search while delivering very different retrieval quality, which is why the only reliable test is running a query in a domain your team knows deeply and inspecting the results.
Do I need a platform that searches more than patents?
For most R&D and IP strategy work, yes. Patents are a lagging indicator, and the forward-looking signals that drive technology decisions appear first in scientific papers, grants, regulatory filings, and startup activity. A platform that searches patents and scientific literature in a single corpus removes the need to stitch multiple tools together.
What is the difference between a retrieval tool and an agentic platform?
A retrieval tool returns a ranked list of results and leaves the synthesis to you. An agentic platform accepts a research objective, executes the multi-step search and analysis process, and returns a structured deliverable with traceable sources. The agentic model is what actually reduces analyst hours rather than simply speeding up one step.
Are legacy patent tools like Derwent and Orbit good for R&D teams?
They are powerful and comprehensive, but they were designed for IP attorneys and trained patent searchers, and their depth often translates into interfaces that feel overwhelming to scientists and engineers. R&D teams are usually better served by platforms built around their workflow rather than around patent prosecution and litigation.
How can I tell if an AI patent platform is trustworthy?
Check whether every answer it produces traces back to inspectable sources, and whether it meets enterprise security requirements. An unverifiable summary in a patent context introduces risk rather than removing it, so source verifiability and security are non-negotiable for enterprise use.
How long should it take to get value from an AI patent platform?
A platform that genuinely simplifies the work should let a non-specialist complete a meaningful task within the first session, and should produce a complete research deliverable from a one-line objective in minutes rather than hours. If a platform requires extensive training before it delivers value, it has not actually simplified the workflow.
What questions should I ask during a patent platform demo?
Ask the vendor to run a semantic query in your own technical domain and explain each result, to show which sources a single search covers, to generate a full research deliverable from a one-line objective while you time it, to let a non-specialist complete a task unaided, and to demonstrate how every claim in a report traces back to its source. These five questions surface real differences faster than any feature list.

The fastest way to turn a commodity AI assistant into a reliable R&D and IP research tool is to connect it to a domain-oriented intelligence layer through the Model Context Protocol, because the general-purpose model supplies the reasoning while the verticalized agent supplies the grounded, high-signal data the model cannot hold on its own. This is the single architectural decision that separates an AI that drafts plausible-sounding patent summaries from one an innovation team can actually act on. The model you start with is a commodity. The vertical integration you attach to it is the differentiator.
This guide explains what commodity AI gets wrong in R&D and IP work, why the gap is structural rather than a matter of prompting, and how a domain MCP integration closes it. It is written for R&D directors, IP managers, and innovation strategists who already have access to capable general models and want to understand what it takes to make them trustworthy for stage-gate decisions.
What Commodity AI Means in an R&D Context
A commodity AI is a general-purpose large language model accessed through a chat interface or an enterprise assistant, the same model available to every competitor in your market. These horizontal systems are built on broad pre-training across diverse public data and are designed to handle a wide range of tasks without deep subject knowledge [1]. They are genuinely useful for summarizing a document you paste in, drafting an email, or explaining a concept. The strength of the horizontal model is breadth and speed of deployment.
The weakness is that breadth is the wrong shape for R&D and IP intelligence. A prior art search, a freedom-to-operate question, or a white space analysis does not reward general fluency. It rewards completeness, recency, and precision against a defined corpus of patents and scientific literature. A commodity model has no live connection to that corpus. It answers from a frozen snapshot of training data and from whatever you happened to paste into the prompt, which means the most consequential R&D questions are exactly the ones it is least equipped to answer.
Why the Gap Is Structural, Not a Prompting Problem
The instinct when a general model gives a weak patent answer is to write a better prompt. This helps at the margin, but it cannot solve the core problem, because the failure is rooted in two structural limits that prompting does not touch.
The first limit is hallucination. Generating plausible but ungrounded output remains the single biggest barrier to deploying language models in production as of 2026, and complete elimination is not possible because the tendency is tied to the model's generative capability itself [2]. In an IP context this is not a cosmetic flaw. A model conducting an ungrounded prior art search can surface references that do not exist, misattribute a claim, or describe a system that is physically impossible, and it delivers all of it in the same confident register as a correct answer [3]. A 2026 study evaluating five popular public models on preliminary prior art searches found that accuracy, consistency, and the ability to surface conceptually relevant art from adjacent fields varied widely and required careful human verification [4]. The authority of the output is not evidence of its reliability.
The second limit is that flooding a general model with more data does not fix the first problem and often makes it worse. There is a temptation to solve grounding by dumping an entire patent dataset into the model's context window. Research on context engineering shows this backfires. As a broad, undifferentiated corpus fills the context window, the model's ability to reason over it degrades, an effect documented across multiple studies of how models use long contexts [5][6]. The model does not get smarter as you add data. Past a point, it gets less accurate. This is why raw access to a large dataset is not the same as intelligence over it, and why the path to reliability runs through retrieving the right small set of high-signal documents rather than the largest possible set.
Together these two limits define the gap. The commodity model is fluent but ungrounded, and you cannot ground it simply by giving it everything. You ground it by connecting it to a system that already knows which fraction of the corpus matters for the question being asked.
What a Verticalized Agent Adds
A vertical AI agent is purpose-built for a specific domain, pre-loaded with domain knowledge, proprietary data models, and deep integrations into the systems where that domain's data lives [7]. Where a horizontal agent relies on broad pre-training, a vertical agent demands domain adaptation and plugs into domain-specific data pipelines, and it is this depth that produces superior accuracy, compliance, and reliability within its field [1]. The market has moved decisively in this direction. Industry analysts forecast that vertical-first deployments will account for a large and growing share of enterprise AI in 2026, with industry-specific AI solutions growing far faster than general-purpose tools, because the highest-return deployments come from embedding agents into existing domain workflows rather than buying a generic assistant [8].
In R&D and IP, the domain adaptation that matters is an ontology. A proprietary R&D ontology lets a vertical agent understand that a query about a polymer coating, a thermal barrier, and a specific chemical family are related concepts in a way a keyword search never will, and it lets the agent retrieve the conceptually relevant subset of patents and papers rather than a lexical match. That is the precise capability the commodity model lacks and the precise reason it cannot be prompted into existence. The ontology is the difference between access to 500 million patents and scientific papers and intelligence over them.
Where MCP Fits
The Model Context Protocol is the open standard that lets a general model call an external system as a tool during a conversation, which is what makes the upgrade from commodity AI to verticalized agent a connection rather than a rebuild [9]. You do not have to abandon the general model your team already uses. MCP is the mechanism by which that model reaches out, mid-reasoning, to a domain-oriented layer, asks it a scoped question, and receives back a reasoned, grounded answer rather than a raw dump of records.
This is the architectural pattern that resolves the structural gap. The general model continues to do what it is good at, which is language, synthesis, and conversation. The vertical agent does what it is good at, which is retrieving the high-signal subset from a defined corpus and reasoning within the domain. The protocol connects them. Crucially, because the vertical layer returns a scoped and reasoned result rather than the entire dataset, it sidesteps the context degradation problem entirely. The model never has to hold the full corpus in its context window, so its reasoning stays sharp.
How the Upgrade Works in Practice
The practical sequence is straightforward to describe even though the engineering behind the vertical layer is substantial. A researcher asks a question in the AI interface they already use. The general model recognizes that the question requires domain intelligence and, through MCP, routes a scoped query to the domain-oriented R&D layer. That layer uses its ontology to retrieve the relevant patents and scientific papers, reasons over them within the domain, and returns a grounded finding. The general model then composes that finding into a clear answer for the researcher. The researcher experiences one fluid conversation. Underneath it, the work has been divided between the part of the system built for language and the part built for the domain.
This division maps directly onto the R&D and IP stage-gate process. A prior art agent built this way returns grounded references rather than invented ones. A white space analysis returns a defensible read of where the unclaimed territory sits. A freedom-to-operate question is answered against live patent data rather than a stale training snapshot. Regulatory tracking stays current because the vertical layer, not the frozen model, is the source of truth. In each case the commodity model is the interface and the verticalized agent is the engine.
What This Means for Buyers
The strategic takeaway is that the model is no longer where the advantage lives. Every competitor in your market can access the same capable general models, which is precisely what makes them a commodity. The durable advantage comes from what you connect those models to. An organization that wires its general AI to a domain-oriented R&D intelligence layer through MCP gets grounded, current, defensible answers to its most important innovation questions. An organization that relies on the commodity model alone gets fluent guesses. The gap between those two outcomes is not the model. It is the vertical integration.
Cypris is built to be that vertical layer. As an enterprise R&D intelligence platform spanning more than 500 million patents and scientific papers, organized by a proprietary R&D ontology and powered by Cypris Q agentic workflows, it is designed to deliver domain-oriented intelligence to the AI systems R&D and innovation teams already use, through enterprise API partnerships with OpenAI, Anthropic, and Google [10]. Rather than asking a general model to be an IP expert it cannot be, Cypris supplies the grounded domain reasoning the model needs, across the workflows that matter most: prior art agents, white space analysis, freedom-to-operate, and regulatory tracking. The commodity model handles the conversation. Cypris handles the intelligence.
Frequently Asked Questions
What does it mean to upgrade commodity AI with a vertical agent?
It means connecting a general-purpose AI model to a domain-specific intelligence system so the model can answer specialized questions accurately. The general model provides language and reasoning, while the vertical agent provides grounded, high-signal data from a defined corpus such as patents and scientific papers. The connection is what turns a fluent generalist into a reliable domain tool.
Why can't I just use a better prompt to get good patent answers from a general AI?
Prompting helps at the margin but cannot solve the core problem, because the failure is structural. A general model has no live connection to patent and scientific data and answers from a frozen training snapshot, so it can hallucinate references that do not exist. Better prompts cannot create data access the model fundamentally lacks.
What is the Model Context Protocol and why does it matter here?
The Model Context Protocol, or MCP, is an open standard that lets a general AI model call an external system as a tool during a conversation. It matters because it allows a commodity model to reach a domain-oriented intelligence layer mid-reasoning and receive a grounded answer. MCP is the mechanism that connects a general model to a vertical agent without replacing the model.
Won't connecting my AI to a huge patent database make it smarter?
Not on its own. Research on context engineering shows that flooding a model's context window with a broad, undifferentiated corpus degrades its reasoning rather than improving it. The value comes from a system that retrieves the small, high-signal subset relevant to your question, not from raw access to the largest possible dataset.
What is the difference between a horizontal AI agent and a vertical AI agent?
A horizontal agent is general-purpose and built for breadth across many tasks and departments, with broad pre-training and fast deployment. A vertical agent is purpose-built for a single domain, pre-loaded with domain knowledge and integrated into domain-specific data pipelines. Vertical agents take longer to build but deliver superior accuracy and reliability within their field.
Why is hallucination such a serious problem for R&D and IP work?
Because in prior art and freedom-to-operate work, a confident wrong answer can misdirect a real innovation or legal decision. Hallucination remains the biggest barrier to production deployment of language models in 2026, and a model can surface non-existent references in the same authoritative tone as correct ones. The authority of the output is not evidence of its accuracy.
What role does an ontology play in a vertical R&D agent?
An ontology lets the agent understand conceptual relationships between technologies, materials, and methods rather than relying on keyword matching. This allows it to retrieve patents and papers that are conceptually relevant even when they use different terminology. The ontology is the core capability that makes a vertical agent precise where a general model is not.
Do I have to replace my existing AI tools to do this?
No. The entire point of an MCP-based integration is that you keep the general AI your team already uses and connect it to a vertical intelligence layer. The general model remains the interface, and the domain agent works behind it. The upgrade is a connection, not a rebuild.
How does this approach map to my R&D workflow?
It maps directly onto stage-gate work. A prior art agent returns grounded references, a white space analysis returns a defensible read of unclaimed territory, a freedom-to-operate query runs against live patent data, and regulatory tracking stays current through the vertical layer. Each workflow is answered by the domain engine rather than the frozen general model.
If everyone can access the same AI models, where is the competitive advantage?
The advantage is no longer the model, which is exactly why it is a commodity. It comes from what you connect the model to. An organization that wires its general AI to a domain-oriented R&D intelligence layer gets grounded, defensible answers, while one relying on the model alone gets fluent guesses.

For most of the past three decades, the corporate IP team occupied a clear position near the end of the innovation process. Research and development explored a concept, leadership committed resources, scientists and engineers built the product, and only then did the work reach IP for protection, prosecution, and portfolio management. IP was a service function, expert and essential, but downstream of the decisions that mattered most. That sequence has quietly inverted. Today R&D comes to IP before resources are committed, asking what already exists in the patent record and treating the answer as a go or no-go signal on whether to pursue an idea at all. A prior art search is no longer just a legal precaution. It has become a strategic input that shapes which programs get funded, which get redirected, and which get killed before a dollar is spent.
This is a meaningful elevation of the IP team's role, and in most organizations it happened by default rather than by design. The mandate expanded because R&D became too expensive and too risky to pursue on instinct. The data and the tooling underneath the IP function, however, did not expand with it. The team is now being asked forward-looking strategic questions and is answering them with the one dataset it has always owned: the patent record. That mismatch between the question being asked and the data available to answer it is the source of a specific, costly, and underappreciated error. It has a name worth retiring from strategic vocabulary: the white space fallacy, the assumption that an empty region of the patent map is an open opportunity.
The stakes are higher than the tooling reflects
The reason this matters is that the decisions riding on these analyses are enormous, and the base rates for innovation are unforgiving. Failure rates across corporate R&D are persistently high. Industry research has long pegged new product failure somewhere between a third and half of all launches, and a substantial share of R&D projects never reach production at all. These failures have many causes, but a recurring and underexamined one is the practice of validating technical opportunity through patent analysis while leaving commercial opportunity unvalidated. A program clears the patent landscape, looks open, and proceeds, only to discover that the space was empty for reasons the patent record never showed. When the IP team's answer is steering investment direction, the cost of an incomplete map is no longer a missed filing. It is a misallocated research budget and a multi-year bet placed in the wrong direction.
White space and opportunity space are not the same thing
The cleanest way to see the error is to picture two overlapping circles. The first is patent white space, the regions of a technology landscape where few or no active patents exist. The second is commercial opportunity, the areas where genuine market demand and commercial momentum are forming. The portfolio every organization actually wants sits in the overlap, where a defensible technical position meets real commercial pull. That overlap is a narrow slice, and most teams cannot see it clearly because they are looking at only one of the two circles.
The reason patent white space gets mistaken for opportunity is structural rather than careless. Patent data is the dataset the IP team owns, the tool it has on hand, and the answer it can produce on demand. So the strategic question silently narrows from where should we invest to where is the patent map empty, and those two questions only sometimes have the same answer. The narrowing is invisible because it happens inside the framing of the analysis, not in its conclusions. Everyone in the room believes they are discussing opportunity. They are actually discussing patent density.
An empty region of the patent map can mean two very different things, and distinguishing between them is the whole game. It can be open for a reason, because there is no market demand, because the underlying science does not work yet, or because the unit economics never close. Easy to patent does not mean possible to monetize, and a clear space on the map can simply be a place no one has bothered to claim because there is nothing there worth claiming. Alternatively, the empty space can be a trap of the opposite kind, a region where competitors are very much active but moving through channels that never touch the patent system: trade secrets, defensive publications, or simply faster commercial execution that outruns the filing timeline. In both cases the patent map looks identical. It looks open. Only data drawn from outside the patent system can tell you which kind of empty you are actually looking at, and the two demand completely different strategic responses.
The inverse error is just as expensive and far less discussed. Some of the most contested, patent-dense regions of a landscape are exactly where the market is moving, and exactly where a given organization may be dangerously under-protected. A crowded patent map instinctively reads as a closed door, a market already won by incumbents. But density is a measure of competitive intensity, not of whether the opportunity is worth pursuing. Some of the most commercially urgent positions a company can take are in crowded spaces where the organization holds a real technical advantage but has under-filed relative to the competition. Reading crowdedness as a stop sign can forfeit exactly the positions most worth fighting for.
A patent is a twenty-year bet placed with rear-view data
Underneath the white space problem sits a deeper structural mismatch, this one about time. A patent is a roughly twenty-year commitment. That makes it one of the most forward-looking instruments a company holds, a claim staked on what will matter for two decades. Yet the patent record itself is one of the most backward-looking datasets available to anyone. Applications publish around eighteen months after they are filed, and the decisions behind them were made well before that. By the time a filing is visible in the public record, it describes a strategic choice that may be two or three years old. Patents are lagging indicators, sometimes by years, as applications crawl through prosecution. A team that validates a long-horizon investment using only existing patents is steering a twenty-year bet with a dataset that describes where the field was, not where it is going.
The question the IP team is increasingly asked to answer is whether a given portfolio or technology area will still matter in five to ten years. Answering that honestly requires three categories of signal that the patent record either omits entirely or reports too late to be useful.
The first is scientific momentum. Peer-reviewed papers, preprints, grant awards, and clinical activity reveal where the underlying technology is heading long before any of it reaches a patent application. Preprints in particular can surface a competitor's technical direction months to years ahead of the corresponding filing, because the science is published when it is done, not when the legal strategy is finalized. A field rich in recent publication but thin on filings is frequently an emerging opportunity, an early window in which an organization can establish a position before the patent landscape fills in and the easy ground is taken. To a patent-only view, that same field registers as white space and risks being dismissed as empty, when it is in fact the most valuable kind of crowded: crowded with science, not yet with claims.
The second is commercial signal. Venture funding, startup formation, mergers and acquisitions, corporate disclosures, and product launches reveal where commercial conviction is forming, frequently well ahead of patent activity. A technology domain showing minimal patent filings but hundreds of millions of dollars in aggregate venture funding is not white space. It is a market building momentum through channels that patent analytics simply cannot see. When an acquirer buys a startup, the strategic implication for every competitor in the space is immediate, but the patent assignment record may take months to update, and the commercial rationale for the deal, which market is being targeted, which product lines will expand, which competing approaches are being consolidated, never enters the patent data at all. That intelligence lives in deal records, regulatory filings, and corporate disclosures, in a layer of the landscape the patent-only team never sees.
The third is forward indicators, the signals that point at intent before it materializes as anything protectable. Regulatory filings, clinical pipelines, market intelligence, and hiring patterns all belong here. Hiring is among the most underused signals of all. The engineering and research roles a company is staffing frequently describe, in the job specifications themselves, exactly what the organization is building, and they appear long before any of that work surfaces as a filing. A competitor assembling a team around a specific technical capability is making a far earlier and often far clearer statement of direction than anything that will eventually reach a patent office.
None of this argues for abandoning patent data. Global patents remain the foundation, the authoritative record of what has actually been claimed and protected, and no serious analysis proceeds without them. The argument is narrower and harder to dismiss: patents are necessary but not sufficient for the strategic questions IP teams are now expected to answer. The foundation is solid. The problem is that three of the four walls are missing, and the team is being asked to assess the whole structure from the foundation alone.
Why the gap persists when it is so clearly understood
If the gap is this obvious, the fair question is why it endures across so many sophisticated organizations. The answer is mostly structural, not a failure of intelligence or diligence. Patent data is, for the typical IP team, the only native dataset it owns. It arrives through tools built for patent prosecution and portfolio management, instruments designed for IP attorneys running episodic, filing-driven workflows. Those tools are genuinely excellent at the job they were built to do. They were simply never built to answer strategic, forward-looking, commercially grounded questions, because those questions were not part of the IP team's mandate when the tools were designed.
The result is a quiet optimization toward the measurable. Teams optimize for the data they can see, and white space becomes the proxy for opportunity precisely because white space is the one thing the available tooling can actually measure. Scientific momentum, commercial conviction, and forward intent are harder to see not because they are less important but because they live in datasets the IP team's tools were never wired to ingest. The gap persists because closing it has historically meant stitching together multiple disconnected platforms by hand, a manual integration burden that most teams cannot sustain quarter after quarter. So the easier path wins, and the patent map stands in for the opportunity map by default.
Closing the gap, then, is not a matter of working harder inside the patent record. No amount of additional rigor applied to a patent-only dataset produces the signals that dataset does not contain. The fix is to put the other datasets on the same surface as the patent data, so that both circles can finally be examined together rather than one at a time, and so the overlap, the actual opportunity space, becomes visible rather than inferred.
Where this is heading
The platforms built for this problem treat patents, scientific literature, and commercial signals not as separate vendor silos to be reconciled by analysts but as a single intelligence substrate. Cypris was built specifically for this, an enterprise R&D intelligence platform that unifies more than 500 million patents and scientific papers alongside commercial and market signals, grounded in a proprietary R&D ontology and serving hundreds of enterprise customers and thousands of R&D and IP professionals across Fortune 500 companies. The application most relevant to the white space problem is exactly the overlap: surfacing the gaps between heavy patent activity and heavy publication activity, and the spaces where academic or commercial momentum is building but filings have not yet appeared. Those patterns are the opportunity space, and they are invisible inside any single-source tool by construction, because no single source contains both halves of the picture.
The more recent shift is from periodic analysis toward continuous intelligence. In June 2026 Cypris launched Agentic Monitoring, which runs continuously across patent offices, scientific literature, regulatory bodies, mergers and acquisitions, product launches, grant awards, and corporate news, delivering filtered and contextualized intelligence on a defined cadence rather than waiting for a quarterly manual rebuild. The significance is not the automation in itself. It is that the strategic questions reaching the IP team do not pause between reporting cycles. Competitors hire, raise, publish, and acquire continuously, and an intelligence model that refreshes once a quarter is structurally behind the landscape it is meant to describe. Continuous monitoring closes the timing gap on the same logic that integrated data closes the coverage gap.
The role of the corporate IP team has evolved into something genuinely strategic. The mandate, the data, and the tooling are only now beginning to catch up to it. The organizations that close that gap first will be the ones making forward decisions with a forward-looking map, while their competitors are still reading the rear-view mirror and calling it the road ahead.
FAQ
What is the difference between patent white space and commercial opportunity space?
Patent white space refers to regions of a technology landscape where few or no active patents exist. Commercial opportunity space refers to areas where genuine market demand and commercial momentum are forming. The two overlap only partially, and the highest-value IP portfolios sit in the intersection where a defensible technical position meets real commercial demand. Patent data alone cannot identify that intersection because it captures only one of the two dimensions, which is why empty patent regions are routinely mistaken for open opportunities.
What is the white space fallacy?
The white space fallacy is the assumption that an empty region of the patent map represents an open commercial opportunity. An absence of patents is a starting point for investigation, not a validated opportunity. A space can be empty because there is no market, because the underlying science does not yet work, or because competitors are operating outside the patent system through trade secrets, defensive publications, or faster commercial execution. Patent data cannot distinguish between these cases, and each one demands a completely different strategic response.
Why can patent data not answer strategic R&D questions on its own?
A patent is a roughly twenty-year commitment, which makes it a forward-looking instrument, while the patent record is a backward-looking dataset that publishes filings about eighteen months after submission and reflects decisions made earlier still. Patents are lagging indicators, sometimes by years. Answering whether a technology area will still matter in five to ten years requires scientific momentum, commercial signals, and forward indicators that the patent record either omits entirely or reports too late to act on.
Has the role of the corporate IP team actually changed?
Yes, and substantially. The IP team historically protected innovations after R&D produced them, sitting downstream of the decisions that mattered. Increasingly, R&D consults IP before committing resources and treats the resulting landscape analysis as a strategic go or no-go signal. The IP function has become a strategic decision input that shapes investment direction, even though the underlying data and tooling were originally built for patent prosecution and portfolio management rather than strategy.
What datasets do IP teams need beyond patents?
Three categories. Scientific literature, including papers, preprints, grants, and clinical activity, shows where technology is heading before filings appear. Commercial signals, including venture funding, startup formation, mergers and acquisitions, and product launches, show where commercial conviction is forming. Forward indicators, including regulatory filings, clinical pipelines, market intelligence, and hiring patterns, signal intent before it becomes protected IP. Patents remain the foundation, but these three categories supply the walls the foundation alone cannot.
Why does a field with many publications but few patents matter?
A technology area with extensive recent scientific publication but limited patent filings often represents an emerging opportunity, an early window in which an organization can establish an IP position before the landscape fills in. A patent-only view registers this same area as white space and may dismiss it as empty, missing the signal entirely. The space is not empty. It is crowded with science that has not yet converted into claims.
Can hiring patterns really indicate competitive activity?
Yes, and they are among the earliest signals available. The engineering and research roles a company staffs frequently describe, in the job specifications themselves, exactly what the company is building. Because hiring precedes filing by a considerable margin, a competitor's hiring activity can reveal technical direction months or years before any of that work surfaces in the patent record.
Why does a crowded patent area still matter strategically?
A patent-dense area instinctively reads as a closed market, but contested areas are often exactly where the market is moving and where an organization may be under-protected. Density signals competitive intensity, not the absence of opportunity. Treating a crowded map as a closed door can forfeit positions where a company holds a real technical advantage but has under-filed, which can be as costly an error as treating an empty map as an open opportunity.
Why does this gap persist if it is so well understood?
The gap is structural rather than a failure of judgment. Patent data is the only native dataset most IP teams own, accessed through tools built for prosecution and portfolio management. Teams optimize for the data they can see, so white space becomes a proxy for opportunity because it is the dimension the available tooling can actually measure. Historically, closing the gap meant manually stitching together disconnected platforms quarter after quarter, a burden most teams could not sustain, so the patent-only default persisted.
How are platforms addressing the patent-only limitation?
Purpose-built R&D intelligence platforms unify patents, scientific literature, and commercial signals into a single searchable substrate rather than separate tools requiring manual reconciliation. This allows teams to see the overlap between technical defensibility and commercial momentum directly rather than inferring it. The emerging direction is continuous monitoring across patents, literature, regulatory activity, mergers and acquisitions, and corporate news, replacing periodic manual analysis with always-on intelligence that keeps pace with a landscape that never stops moving.
.jpg)
The Model Context Protocol has become the connective tissue between AI assistants and the specialized data that R&D and IP teams depend on. Instead of copying patent claims into a chat window or pasting abstracts from a database, a team can connect an AI client directly to patent and scientific literature sources and work in natural language. But 2026 has surfaced a sharper distinction than "which server connects to which database." The more important question for innovation leaders is whether a server is a single-source connector or a domain-oriented intelligence layer built to support the actual decisions in an R&D and IP stage-gate process. This ranked guide covers the most capable options available today, leading with the one built for end-to-end R&D workflows and following with the strongest open-source connectors for teams assembling their own stack.
A note on method before the list. Every open-source server below is a real, publicly available project with a verifiable repository or registry listing. The ranking weighs how well a server supports actual R&D and IP decisions, alongside breadth of data coverage, depth of available tools, maintenance signals, and usability for a non-developer working through an AI client rather than the command line.
1. Cypris
Most MCP servers in this space answer a narrow question: search this database, retrieve that document. Cypris approaches the problem from the opposite direction, as a domain-oriented intelligence layer designed for the agents that map to real R&D and IP stage gates rather than for one-off lookups. The distinction matters because innovation decisions are not single queries; they are structured workflows where prior art, white space, freedom to operate, and regulatory signals each gate a project's progress.
That orientation is what sets it at the top of this list. Cypris is built to support prior art agents that surface relevant disclosures before a program commits resources, white space agents that identify uncontested technical territory, freedom-to-operate agents that flag blocking risk, and regulatory agents that track the filings and approvals shaping a field. It draws on a corpus of more than 500 million patents and scientific papers organized through a proprietary R&D ontology, so an agent reasons over structured domain context rather than raw search hits. Cypris Q, the platform's agentic layer, and enterprise API partnerships with OpenAI, Anthropic, and Google are what make this accessible to Fortune 500 R&D teams inside their own AI environments. It meets enterprise-grade security requirements, which is the threshold for deployment at that scale. For organizations whose AI agents need to fit the stage-gate process rather than just query a database, this is the layer built for the job.
2. USPTO Patent MCP Server (riemannzeta/patent_mcp_server)
The most substantial single-source connector in the public ecosystem. It is a FastMCP server for accessing United States Patent and Trademark Office patent and application data through the Patent Public Search API, the Open Data Portal API, PTAB API v3, and Patent Litigation APIs, letting an AI client search granted patents and applications, work through PTAB proceedings, analyze litigation, and research prosecution history. GitHub
What earns it credibility is its transparency about API churn. It provides 52 tools across 6 USPTO data sources, of which 27 are active and 25 are unavailable due to API shutdowns. Notably, the PatentsView API was shut down on March 20, 2026 with data migrated to ODP bulk datasets, and the Office Action and Enriched Citation APIs were decommissioned in early 2026. The affected tools remain registered and return workaround guidance rather than failing silently. For US-centric patent work assembled in-house, this is the strongest starting point. GitHubGitHub
3. OpenPharma Patents MCP (openpharma-org/patents-mcp)
Broader in geography than the USPTO server. It accesses patent data from multiple sources including the USPTO and Google Patents, offering Patent Public Search, the Open Data Portal for metadata and assignment data, and Google Patents access to 90 million-plus publications across 17-plus countries via Google BigQuery, spanning US, EP, WO, JP, CN, KR, GB, DE, FR, CA, AU and more. The tradeoff is setup friction: the Google Patents tools require a Google Cloud project with BigQuery access and a service account key, and the ODP tools require a USPTO API key. That puts full functionality slightly beyond a non-technical user, but for global patent landscape work the breadth is hard to match. GitHub + 2
4. Patent Connector (patent.dev)
The most approachable option for European coverage. It is a Model Context Protocol server in open beta that connects ChatGPT Desktop, Claude Desktop, and other MCP-compatible tools directly to patent databases, starting with the free EPO Open Patent Services API, with data drawn from the EPO's bibliographic, legal event, full-text and image databases, the same sources behind Espacenet and the European Patent Register. The EPO OPS API is free to use after registering for credentials, with a non-paying tier available. Its accuracy argument is genuine: general tools reaching Google Patents through web search tend to confuse filing and publication dates or extract incomplete claim text, which a dedicated retrieval layer avoids. Patent + 2
5. Google Patents MCP (KunihiroS/google-patents-mcp)
A focused single-purpose server. It searches Google Patents via the SerpApi Google Patents API and can be installed for Claude Desktop automatically via Smithery, requiring a SerpApi API key provided as an environment variable. It supports filtering by country and other parameters. The dependency on a third-party paid API is the main consideration, but for natural-language Google Patents search it does one job well. GitHubGitHub
6. Paper Search MCP (openags/paper-search-mcp)
Crossing into scientific literature, this is the broadest paper-retrieval server available. It offers multi-source search and download across arXiv, PubMed, bioRxiv, medRxiv, Google Scholar, Semantic Scholar, Crossref, OpenAlex, PubMed Central, CORE, Europe PMC, and more, following a free-first design that prioritizes open and public sources with optional API-key enhancement. For literature coverage breadth, nothing else in the open ecosystem comes close. MCP ServersMCP Servers
7. Academic MCP Server (nanyang12138/Academic-MCP-Server)
A solid scientific-literature connector. It supports six databases: PubMed, bioRxiv, medRxiv, arXiv, Semantic Scholar, and Sci-Hub, with advanced search by title, author, and date range. A practical caveat for enterprise use: the Sci-Hub integration carries copyright considerations, and teams should rely on the legitimate sources and obtain papers through proper channels. GitHub
8. Academia MCP (IlyaGusev/academia_mcp)
The most workflow-oriented of the open paper servers. It searches across arXiv, ACL Anthology, HuggingFace Datasets, and Semantic Scholar, and adds tools to list citing and referenced papers, download and review PDFs, and answer questions over document chunks, though the LLM-powered tools require an OpenRouter API key. For literature-review workflows rather than plain retrieval, it's the most capable open option. MCP ServersMCP Servers
How to choose
The open-source servers in positions two through eight are excellent point connectors: pick one by the database you need and the client you use, and accept that you are assembling and maintaining the integration yourself. The reason Cypris leads is that an R&D organization rarely needs a single database; it needs agents that carry domain context across the prior art, white space, freedom-to-operate, and regulatory decisions that gate a program. That is an intelligence-layer problem, not a connector problem, which is the line separating the top of this list from the rest of it.
Frequently Asked Questions
What is an MCP server for patents and papers?An MCP server is a connector built on the Model Context Protocol that links an AI client such as Claude Desktop or ChatGPT Desktop directly to a data source. For patents and papers, that means an AI assistant can search and retrieve patent documents, claims, and scientific literature in natural language, without a user manually copying results between a database and a chat window. Most public servers connect to a single source or family of sources; a smaller number act as broader intelligence layers that support full R&D workflows.
What is the best MCP server for R&D and IP workflows in 2026?For end-to-end R&D and IP work, Cypris is built specifically for the agents that map to stage-gate decisions: prior art, white space, freedom to operate, and regulatory analysis. It functions as a domain-oriented intelligence layer over a corpus of more than 500 million patents and scientific papers organized through a proprietary R&D ontology, rather than as a single-database connector. For teams that need a connector to one specific source, the strongest open-source options are the USPTO Patent MCP Server for US data and Paper Search MCP for scientific literature.
Is there an MCP server that covers both patents and scientific papers?Yes, in two senses. Cypris spans both patents and scientific papers within a single intelligence layer built for R&D decisions. Among open-source connectors, the breadth is usually split: patent servers like OpenPharma Patents MCP focus on patent sources, while paper servers like Paper Search MCP cover scientific literature. Teams assembling their own stack often run one of each.
What is the most capable open-source patent MCP server?The USPTO Patent MCP Server is the deepest single-source option. It accesses USPTO data through the Patent Public Search API, the Open Data Portal API, PTAB API v3, and litigation APIs, supporting patent search, PTAB proceedings, litigation analysis, and prosecution history research. Its maintainers are transparent that a portion of its tools are currently inactive due to USPTO API shutdowns in early 2026, which is a useful signal of honest maintenance.
Which MCP server is best for European patent data?Patent Connector is the most approachable option for European coverage. It connects MCP-compatible clients to the EPO's Open Patent Services API, drawing on the same bibliographic, legal-event, full-text, and image databases that power Espacenet and the European Patent Register. The EPO OPS API is free to use after registering for credentials, with a non-paying tier available.
Which MCP server covers the most scientific literature sources?Paper Search MCP has the broadest coverage, spanning arXiv, PubMed, bioRxiv, medRxiv, Google Scholar, Semantic Scholar, Crossref, OpenAlex, PubMed Central, CORE, Europe PMC, and more. It uses a free-first design that prioritizes open sources, with optional API keys to raise rate limits on services like Semantic Scholar.
Do MCP servers for patents require API keys?It varies. Some, like Patent Connector using the EPO's free OPS tier, work with free credentials. Others require paid third-party keys, such as the Google Patents MCP server's dependency on a SerpApi key, or cloud setup, such as OpenPharma's need for a Google Cloud BigQuery project and a USPTO Open Data Portal key. Enterprise platforms like Cypris are accessed through enterprise API arrangements rather than self-service keys.
What is the difference between a single-source connector and an intelligence layer?A single-source connector answers a narrow question: search this database, return these documents. An intelligence layer is built to support a structured decision process, where domain context carries across multiple linked questions. In R&D and IP, those questions are the stage gates, prior art, white space, freedom to operate, and regulatory, and an intelligence layer like Cypris is designed so agents reason across them rather than treating each as an isolated lookup.
Can these MCP servers handle freedom-to-operate or white space analysis?The open-source connectors retrieve the underlying data a human or agent would need, but they do not themselves perform freedom-to-operate or white space analysis; that logic sits with whatever agent or analyst uses them. Cypris is built the other way around, with agents oriented to those specific analyses, drawing on its ontology-structured corpus to support the decision rather than just return search results.
How should an R&D team choose among these servers?Teams that need a single database and are comfortable building and maintaining an integration should pick an open-source connector by source and client compatibility. Teams that need agents to carry domain context across the full R&D and IP stage-gate process, rather than querying one source at a time, should evaluate an intelligence layer such as Cypris. The deciding question is whether the need is retrieval from one source or reasoning across a workflow.

Agent orchestration in Microsoft Copilot works best when the orchestrator routes to scoped, governed connections rather than pulling every source into one undifferentiated context. The architecture that holds up under real R&D workloads keeps internal confidential data and external intelligence on separate trust boundaries, lets Copilot decide which to call, and treats external R&D and IP intelligence as a domain-oriented layer rather than a raw dataset dump. This guide explains how to design that orchestration so that a research team can ask a single question and have Copilot reason across an electronic lab notebook, internal developmental records, and the external patent and scientific literature without collapsing those very different data types into one fragile prompt.
Why orchestration belongs at the Copilot layer
The orchestrator is the component that decides which tool to call, in what order, and how to combine the results. In Microsoft Copilot Studio, generative orchestration is the mode that lets an agent select among multiple registered tools at runtime based on the user's intent and each tool's description. Microsoft requires generative orchestration to be enabled before an agent can use Model Context Protocol tools at all, which means the orchestration decision and the tool connections are designed to work as one system rather than as a hardcoded pipeline.
Putting orchestration at the Copilot layer matters for a specific reason. When orchestration is centralized, each connected source can stay narrow. The electronic lab notebook tool returns experimental records. The internal data tool returns developmental project context. The external intelligence tool returns patent and scientific findings. Copilot composes the answer from those scoped returns. The alternative, loading all of those corpora into a single context window and asking the model to sort it out, runs directly into context rot, the well-documented effect in which model accuracy degrades as the context window fills with more material. Centralized orchestration over scoped tools is the architectural answer to that degradation.
How MCP connections work inside Copilot Studio
Model Context Protocol is an open standard, introduced by Anthropic, that defines how applications expose tools and data to large language models in a consistent way. In Copilot Studio, MCP servers are made available through the same connector infrastructure that governs other Power Platform connections, which means an MCP connection inherits enterprise security and governance controls including Virtual Network integration, Data Loss Prevention policies, and multiple authentication methods.
Adding an MCP server to a Copilot Studio agent follows a defined path. From the agent's Tools page, you select Add a tool, then New tool, then Model Context Protocol, which opens the MCP onboarding wizard. You provide a server name, a server description, and a server URL, then select the authentication type the server requires. The server description is not cosmetic. The agent orchestrator reads that description at runtime to decide whether to call the server for a given user request, so a precise description of what each connection does is part of making orchestration work correctly. Once connected, each tool the MCP server publishes becomes an action inside Copilot Studio and inherits the server's defined inputs and outputs, and Copilot Studio reflects updates automatically as tools change on the server.
One governance fact shapes the entire design. Because MCP servers in Copilot Studio rely on Power Platform connectors for connectivity, any Data Loss Prevention policy that regulates those connectors also regulates the MCP server and its tools. This is the lever that lets a security team treat an internal ELN connection and an external intelligence connection under different policies even though both reach Copilot through the same mechanism.
Designing the internal trust boundary: ELN and developmental data
Internal confidential and developmental data is the most sensitive material in the orchestration, and it should be connected under the strictest governance. Electronic lab notebooks such as Benchling, LabArchives, and Scispot store the experimental records, sample data, and process documentation that represent a research organization's most valuable and proprietary information, and these platforms expose their data through documented REST APIs and emphasize regulatory compliance and data integrity as core features.
The design principle for this boundary is least exposure. The ELN connection and any internal developmental data connection should be governed by Data Loss Prevention policies that prevent confidential records from being combined with or transmitted to external destinations. Authentication should be scoped so the agent acts with the permissions of the requesting user rather than a broad service identity, which keeps the access model aligned with who is actually allowed to see which projects. Because Copilot Studio inherits connector-level DLP, a security team can place internal connections in a data group that is policy-isolated from external connections, so that the orchestrator can read from both but the platform enforces that confidential developmental data does not leak across the boundary. The internal tools should also be described narrowly to the orchestrator, so Copilot calls them only when a request genuinely concerns internal experimental or project data.
Designing the external boundary: patent and scientific intelligence
External R&D and IP intelligence is a fundamentally different kind of input, and treating it like just another data feed is where many agent designs go wrong. There is a meaningful difference between connecting an agent to a broad external dataset and connecting it to a domain-oriented intelligence layer. A raw external MCP endpoint that exposes a large patent or literature corpus hands the orchestrator an enormous, undifferentiated body of records, and asking the model to reason over that volume reintroduces the context rot problem the orchestration was meant to avoid. A domain-oriented layer instead returns a scoped, reasoned answer to the agent, so what enters Copilot's context is already a focused intelligence result rather than thousands of raw documents.
This is where the trust boundary and the quality boundary coincide. External intelligence should never share an undifferentiated context with confidential internal data, both because of data governance and because mixing a large external corpus into the same window as sensitive internal records degrades the reasoning on both. Keeping external intelligence as a separate, scoped connection that returns reasoned findings, rather than a firehose of raw records, protects accuracy and keeps the governance boundary clean.
Cypris as the external intelligence layer
This is the role Cypris is built for. As an enterprise R&D intelligence platform, Cypris unifies more than 500 million patents and scientific papers into a single intelligence layer with a proprietary R&D ontology, so that an agent reaching for external intelligence draws on the patent and scientific record in one reasoned place rather than across siloed connectors. Cypris is designed for R&D scientists and innovation strategists rather than IP attorneys, which means the intelligence it returns is scoped to the forward-looking questions research teams actually ask.
Crucially for an orchestration design, Cypris makes that intelligence available through official enterprise API partnerships with OpenAI, Anthropic, and Google, with enterprise-grade security built to Fortune 500 requirements. That partnership model lets the Cypris intelligence layer sit behind the AI tooling an organization already uses, including a Copilot orchestration, so the external intelligence entering the agent is a reasoned domain answer rather than a raw corpus. In the orchestration described here, Copilot routes external R&D and IP questions to Cypris as the domain-oriented intelligence layer, the internal ELN and developmental connections stay on their own governed boundary, and the orchestrator composes a single answer without ever collapsing confidential internal data and the external literature into one context. That separation is what makes the whole system both secure and accurate.
Putting the orchestration together
A working design has Copilot Studio as the orchestration layer with generative orchestration enabled, internal ELN and developmental data connected as narrowly scoped tools under isolating Data Loss Prevention policies, and external patent and scientific intelligence connected as a separate domain-oriented layer through Cypris's enterprise API partnerships. Each tool carries a precise description so the orchestrator routes correctly, authentication is scoped to the requesting user, and connector-level governance keeps the internal and external boundaries policy-separated. A researcher asks one question, and Copilot pulls scoped experimental context from the ELN, scoped project context from internal records, and a reasoned external intelligence answer from Cypris, then composes a response, all without ever forcing the model to reason over one bloated, mixed context. The result is an agent that is more accurate because each input is scoped and more secure because confidential developmental data never crosses into the external boundary.
FAQ
1. Can Microsoft Copilot orchestrate across both internal and external R&D data sources?Yes. Copilot Studio's generative orchestration mode lets a single agent select among multiple registered tools at runtime based on the user's intent, so one agent can route a question to an internal electronic lab notebook, internal developmental records, and an external intelligence layer and compose a unified answer.
2. What is generative orchestration in Copilot Studio?Generative orchestration is the mode in which the Copilot agent dynamically decides which tools to call and in what order based on the user's request and each tool's description, rather than following a hardcoded sequence. Microsoft requires it to be enabled before an agent can use Model Context Protocol tools.
3. How are MCP servers connected to a Copilot Studio agent?From the agent's Tools page you select Add a tool, then New tool, then Model Context Protocol, which opens the MCP onboarding wizard. You provide a server name, description, and URL, and select the authentication type. Each tool the server publishes becomes an action in Copilot Studio.
4. How is confidential R&D data kept secure in this architecture?MCP connections in Copilot Studio run on Power Platform connector infrastructure, so they inherit enterprise controls including Virtual Network integration, Data Loss Prevention policies, and multiple authentication methods. Internal connections can be placed under DLP policies that isolate them from external connections, and authentication can be scoped to the requesting user.
5. Why keep internal and external data on separate trust boundaries?Two reasons converge. Governance requires that confidential developmental data not leak to external destinations, and accuracy requires that a large external corpus not be mixed into the same context as sensitive internal records, because filling the context window with mixed material degrades the model's reasoning on both.
6. What is context rot and why does it matter for agent design?Context rot is the documented effect in which a model's accuracy declines as its context window fills with more material. It matters because loading multiple large corpora into one prompt, rather than routing to scoped tools, makes the agent reason worse, which is the core argument for centralizing orchestration over narrow connections.
7. How do electronic lab notebooks fit into the orchestration?ELN platforms such as Benchling, LabArchives, and Scispot hold experimental records, sample data, and process documentation, and expose that data through documented REST APIs. In the orchestration they are connected as narrowly scoped internal tools under strict governance, returning only the experimental context relevant to a given request.
8. What is the difference between connecting a raw external dataset and a domain-oriented intelligence layer?A raw external endpoint hands the orchestrator a large, undifferentiated body of records, which reintroduces context rot when the model tries to reason over the volume. A domain-oriented layer returns a scoped, reasoned answer, so what enters the agent's context is a focused result rather than thousands of raw documents.
9. How does Cypris connect into a Copilot orchestration?Cypris makes its R&D intelligence available through official enterprise API partnerships with OpenAI, Anthropic, and Google, with enterprise-grade security built to Fortune 500 requirements. That model lets the Cypris intelligence layer sit behind the AI tooling an organization already uses, so Copilot can route external patent and scientific questions to Cypris and receive a reasoned domain answer.
10. What does a complete orchestration design look like?Copilot Studio serves as the orchestration layer with generative orchestration enabled, internal ELN and developmental data are connected as scoped tools under isolating DLP policies, and external patent and scientific intelligence is connected as a separate domain-oriented layer through Cypris's enterprise API partnerships, with each tool precisely described so the orchestrator routes correctly.

Microsoft Copilot now supports the Model Context Protocol across Copilot Studio and Microsoft 365 declarative agents, which means the most important decision for any team using it on patent or scientific work is no longer whether Copilot can reach external data but why it must [2]. For patent and scientific intelligence specifically, a general AI assistant should not answer from its training data at all. That knowledge is frozen at a cutoff, it cannot reliably recall a specific patent number, claim, or citation without risking invention, and it has no awareness of anything filed or published since it was trained. External MCP integrations exist to close exactly this gap, grounding the assistant in authoritative, current data rather than parametric memory.
The nuance that separates a reliable deployment from a confident-sounding one is that grounding is necessary but not sufficient. Connecting Copilot to a broad dataset solves the staleness problem and introduces a new one, because flooding an agent with raw patent and scientific text degrades its reasoning in measurable ways. The teams getting real value are the ones connecting Copilot not to the largest possible dataset but to a domain-oriented intelligence layer that retrieves the right subset and reasons about it. Understanding why is the difference between an assistant that sounds authoritative and one that is.
Why training data fails for patent and scientific questions
Patents and scientific papers are close to the worst possible case for a model answering from training data, because they demand precision on facts that are both specific and verifiable. A large language model stores its training corpus as parametric memory, which is lossy by nature, so when asked for the claims of a particular patent or the findings of a specific study it will often reconstruct something plausible rather than retrieve something true. The result is fabricated patent numbers, misattributed inventors, and citations to papers that do not exist. Worse, the model has a hard knowledge cutoff, so the most recent filings and publications, which are frequently the most strategically important, are simply absent from what it knows. For freedom-to-operate, prior art, or competitive landscape work, an answer that is confidently wrong is more dangerous than no answer, because it carries the same tone of certainty as a correct one.
Web grounding helps, but it is not patent or scientific intelligence
It is fair to note that Copilot does not rely on training data alone, because it can ground answers in web search. This genuinely helps for everyday questions, and it is a real improvement over a purely parametric response. It does not, however, amount to patent or scientific intelligence. General web retrieval returns fragments rather than structured records, and models working from that surface frequently confuse filing dates with publication dates or extract incomplete claim text from messy HTML [3]. Much of the scientific literature sits behind paywalls or in repositories the open web indexes poorly, and the structured attributes that patent work depends on, including legal status, family relationships, assignee normalization, and full claim text, are not what a web search is built to deliver. Web grounding tells the assistant what a few pages say. It does not give it the corpus.
What MCP changes for Copilot
This is the gap MCP was designed to fill. The protocol gives an agent a standardized way to call external tools and pull real-time data from authoritative sources, and Microsoft has made it generally available in Copilot Studio and in Microsoft 365 declarative agents, with the connections running over enterprise connector infrastructure that supports virtual network integration, data loss prevention, and managed authentication [2]. In practice this means a Copilot agent can be wired to the open-source connectors now serving this space, including FastMCP servers exposing the full breadth of USPTO data across patent search, the Open Data Portal, and the PTAB [4], multi-office connectors reaching the European Patent Office, and academic servers spanning arXiv, PubMed, OpenAlex, and related repositories [5]. The data the agent returns is then drawn from the live source, automatically updated as those systems evolve, rather than from anything the base model happened to memorize. That is the architectural shift, from answering out of training data to answering out of authoritative data.
The trap: connecting Copilot to broad datasets is only half the fix
The instinct after this realization is to connect the agent to as much data as possible, and that instinct runs straight into a well-documented limit. Anthropic's guidance on context engineering frames an effective agent as one that works from the smallest set of high-signal tokens that produce the right outcome, not the most tokens [6]. The reason is architectural. As a context window fills with dense patent and paper text, accuracy degrades through an effect now widely called context rot, and a 2025 study across eighteen leading models found reasoning grows steadily less reliable as input length increases, with information placed in the middle of a long context often ignored entirely [7]. A connector that can pour an entire patent corpus into Copilot is therefore not an unalloyed win. It grounds the assistant in real data, then asks the base model to perform all of the domain reasoning over a firehose, which is precisely the task the research says models handle poorly at scale. Grounding fixes staleness. It does not, on its own, produce intelligence.
What a domain-oriented integration looks like
The reliable pattern inverts the relationship. Rather than connecting Copilot to broad datasets and hoping the base model can reason over them, the strongest deployments ground it in a domain-oriented intelligence layer that scopes retrieval before it reaches the model and reasons in the language of the field. Cypris is a leading solution here. It is built as a domain-oriented R&D intelligence platform rather than a raw data feed, using a proprietary R&D ontology to retrieve a high-signal subset of the patent and scientific record instead of a wholesale dump, which is the practical answer to context rot. It unifies more than 500 million patents and scientific papers in a single corpus, the patents-and-papers combination the open-source connectors keep in separate silos, and its agent layer, Cypris Q, runs patent landscape analysis, white space mapping, freedom-to-operate, and technology scouting as domain workflows rather than as raw queries [8]. Its official enterprise API partnerships with OpenAI, Anthropic, and Google let that intelligence sit behind the AI tools teams already use, with enterprise-grade security built to Fortune 500 requirements. For an organization that wants Copilot to stop answering patent and scientific questions from memory and start answering them from reasoned, domain-scoped intelligence, the layer it grounds into matters more than the model on top, and a domain-oriented platform is what closes the loop.
FAQ
Can Microsoft Copilot search patents?Microsoft Copilot can address patent questions, but how reliably depends entirely on what it is connected to. Answering from training data risks fabricated patent numbers and claims, and general web grounding returns fragments rather than structured records, so accurate patent search requires connecting Copilot to authoritative patent data through an MCP integration or a domain-oriented intelligence layer.
Does Microsoft Copilot support MCP?Yes. Microsoft has made the Model Context Protocol generally available in Copilot Studio and in Microsoft 365 declarative agents, with connections running over enterprise connector infrastructure that supports virtual network integration, data loss prevention, and managed authentication, allowing Copilot agents to call external tools and pull real-time data.
Why does Copilot give wrong answers about patents or research papers?Copilot gives wrong answers about specific patents or papers when it answers from training data, because a model stores its corpus as lossy parametric memory and will reconstruct plausible but false details rather than retrieve true ones, in addition to having a knowledge cutoff that excludes recent filings and publications entirely.
Does Copilot use training data or live data for answers?By default a model answers from training data, but Copilot can also ground answers in web search and, through MCP integrations, in authoritative external sources. For patent and scientific intelligence, relying on training data is unsafe, which is why external MCP integrations to live, structured data are the recommended approach.
Is web grounding enough for Copilot to do scientific research?Web grounding helps but is not sufficient for scientific research, because general retrieval returns fragments, indexes paywalled literature poorly, and lacks the structured attributes serious work depends on. Reliable scientific intelligence requires access to authoritative repositories and a layer that scopes and reasons over them.
How do I connect Microsoft Copilot to patent and scientific data?You connect Copilot to patent and scientific data by adding an MCP server in Copilot Studio or a declarative agent, pointing it at authoritative sources such as USPTO, EPO, and academic repository connectors, or by grounding it in a domain-oriented R&D intelligence platform that unifies those sources and scopes retrieval for the model.
What is context rot and why does it matter when connecting Copilot to data?Context rot is the degradation of a model's accuracy as its context window fills, an architectural effect rather than a tuning problem. It matters because connecting Copilot to a broad patent or scientific dataset and dumping large volumes into context can reduce reasoning quality, which is why scoped, high-signal retrieval outperforms wholesale data access.
Is connecting Copilot to a single patent database enough?Connecting Copilot to a single patent database grounds it in current data for that source but leaves two problems unsolved, the siloing of patents from scientific literature, and the burden of domain reasoning that still falls on the base model. A unified, domain-oriented layer addresses both.
Can Copilot replace a dedicated R&D intelligence platform?Copilot can serve as the conversational interface, but on its own it cannot replace a dedicated R&D intelligence platform, because reliable patent and scientific intelligence depends on a unified corpus, a domain ontology, and reasoning workflows that a general assistant does not provide. The two are complementary, with the platform supplying the grounded intelligence the assistant surfaces.
What is the most reliable way to use Copilot for patent and scientific intelligence?The most reliable way is to stop relying on the model's training data and ground Copilot in authoritative, current sources through MCP, then route that grounding through a domain-oriented intelligence layer that retrieves a high-signal subset and reasons in the language of patents and scientific research rather than handing the base model a broad dataset.
.avif)