
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
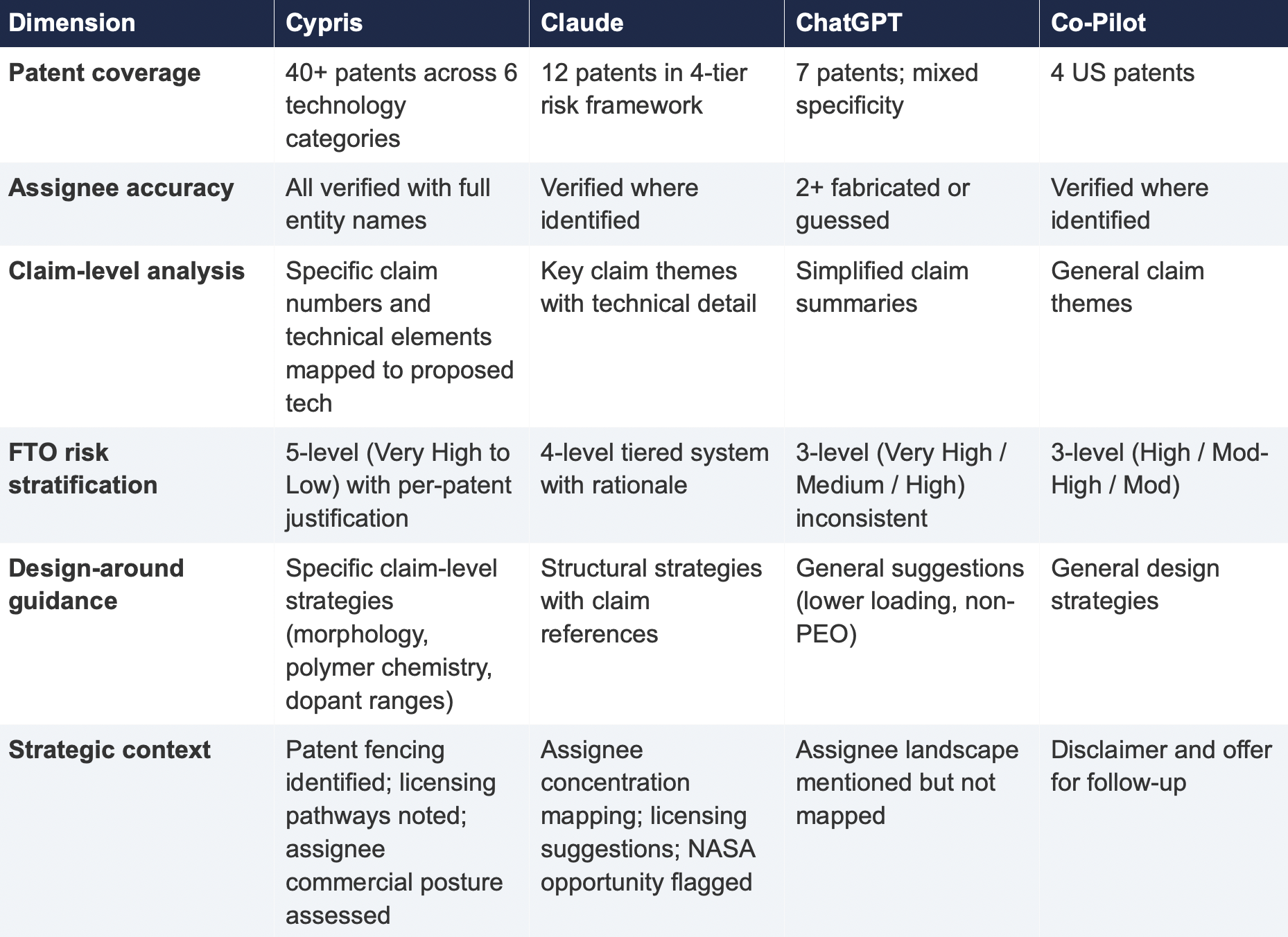
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
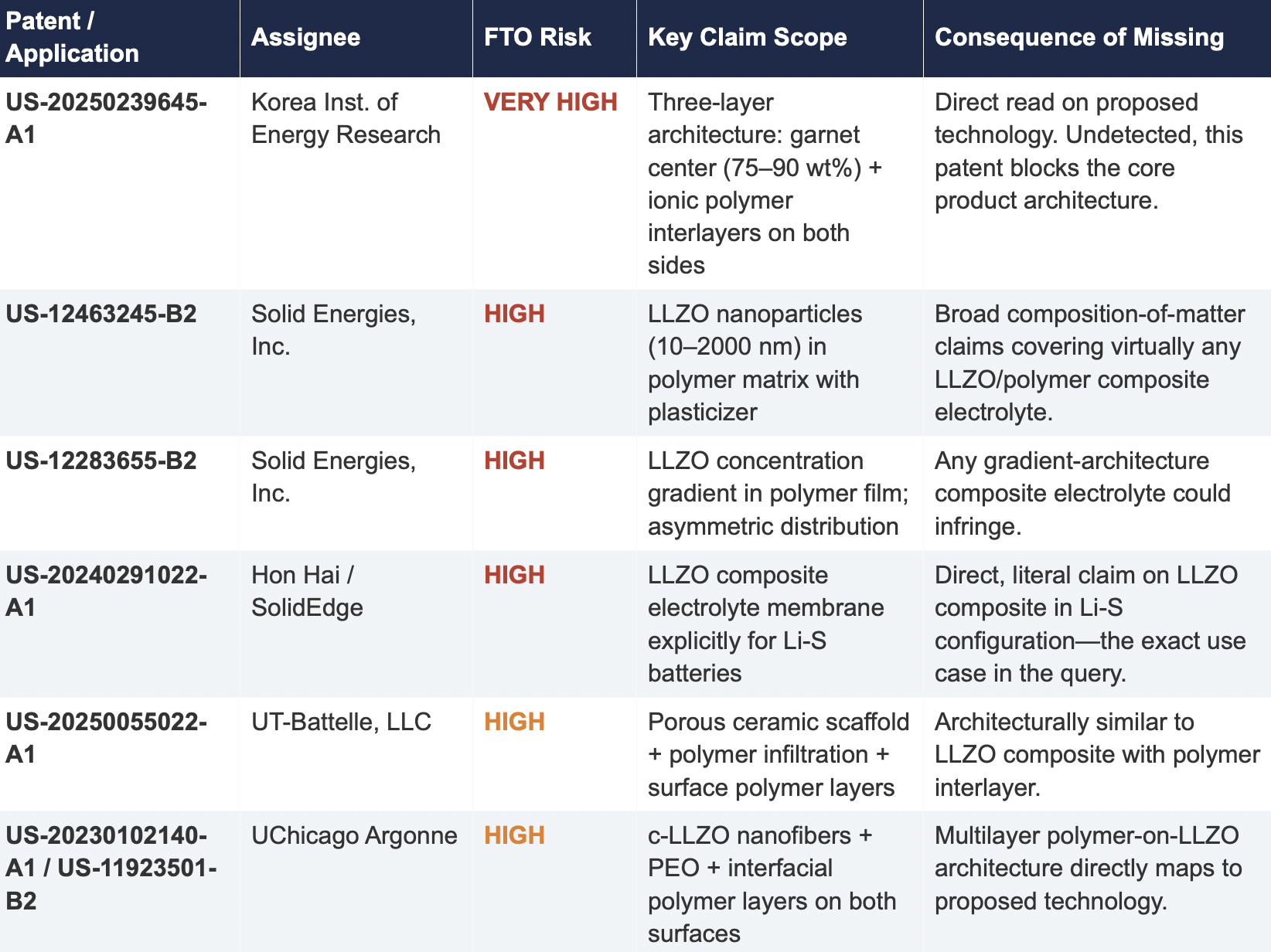
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

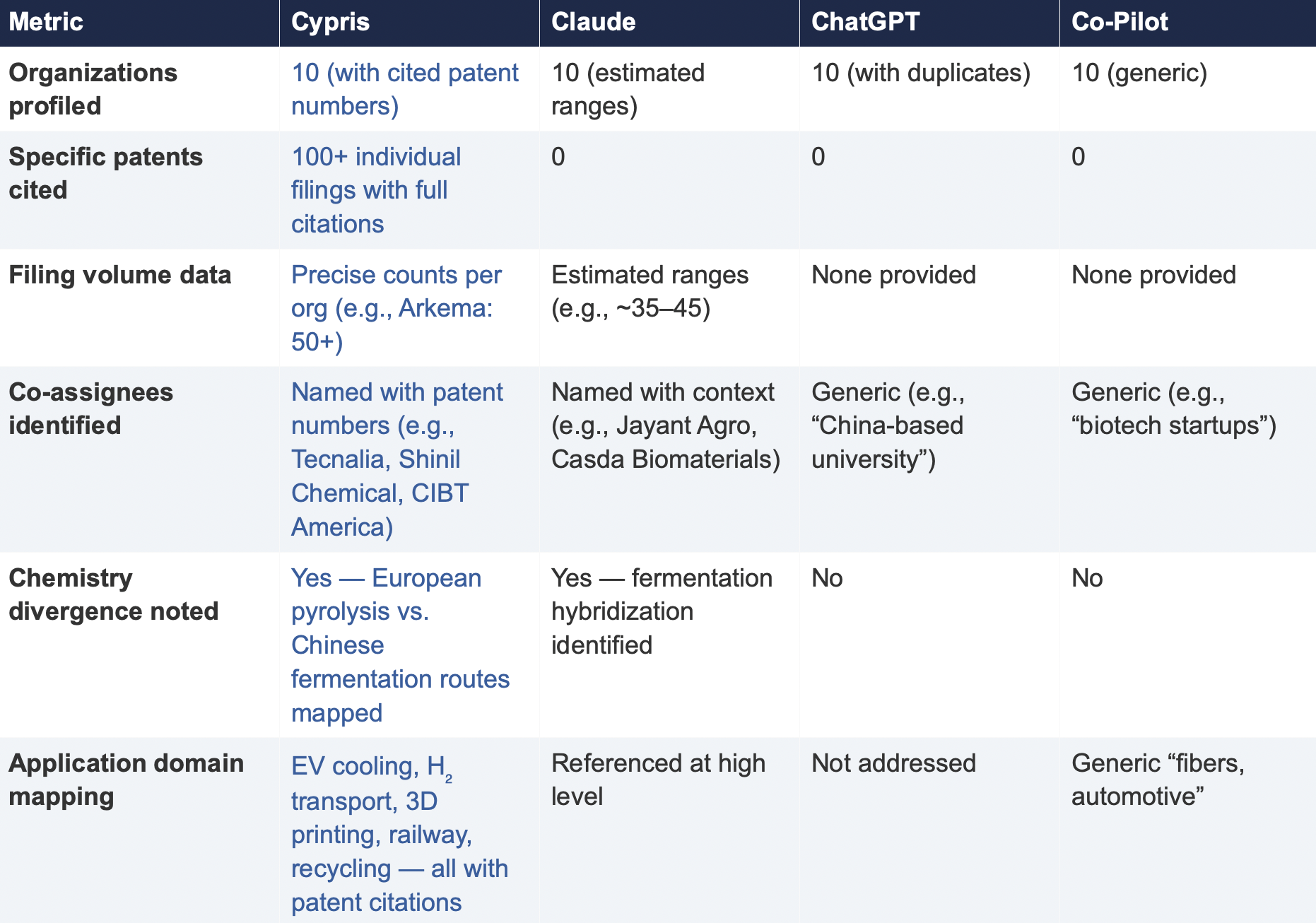
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs
.png)
A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence
Published January 21st 2026
As frontier technologies move from lab to pilot to commercialization, the quality of research increasingly determines the quality of R&D decisions.
To evaluate how modern AI research tools perform in this context, we ran the same advanced research prompt through two widely used platforms:
- Cypris Report Mode, an R&D-native intelligence system built on patents, scientific literature, and technical ontologies. (report link)
- Perplexity Deep Research, a general-purpose AI research tool optimized for market and news synthesis (report link)
Both outputs were assessed by Gemini, as an independent AI auditor, using a 100-point R&D evaluation rubric covering source quality, technical depth, IP intelligence, commercial readiness, and actionability for research teams.
The result was a clear divergence in strengths:
Cypris produced an R&D-grade intelligence report (89/100) optimized for technical due diligence and IP-aware decision-making.
Perplexity produced a strong market intelligence report (65/100) optimized for breadth, timelines, and business context.
This analysis breaks down the results and shares how R&D teams should think about choosing the right research tool depending on their objective.
Technical Evaluation
Cypris Report Mode vs. Perplexity Deep Research
Evaluation context
Both reports were generated from the same geothermal energy research prompt and evaluated using a 100-point rubric designed around what matters most to R&D teams. The assessment reflects a simulated “current state” as of January 21, 2026, with both reports referencing developments from late 2024 and 2025. All recency and accuracy judgments are made relative to that context.
Prompt: Provide an overview of the geothermal energy production landscape, focusing on: (1) leading technology innovators, (2) latest technical advancements and their commercial readiness, and (3) which companies hold the strongest competitive positions.
Executive Scorecard
Overall Performance (100-Point R&D Rubric)
CyprisReportMode
█████████████████████████░ 89/100
PerplexityDeepResearch
████████████████░░░░░░░░░ 65/100
█████████████████████████░ 89/100
PerplexityDeepResearch
████████████████░░░░░░░░░ 65/100
Interpretation:
Both tools are capable research assistants. However, they are optimized for fundamentally different outcomes. Cypris consistently scores higher on dimensions that matter when technical feasibility, IP exposure, and execution risk are on the line.
1. Source Authority & Quality
(Weight: 25 points)
Comparative Scores
Platform Score: Cypris 23/25 | Perplexity 12/25
Source Signal Strength
Primary Technical Sources
Cypris ██████████ Patents, journals, conferences
Perplexity ██░░░░░░░░ News, blogs, general sources
Cypris ██████████ Patents, journals, conferences
Perplexity ██░░░░░░░░ News, blogs, general sources
Cypris Report Mode
Cypris draws almost exclusively from primary R&D artifacts:
- Patents with publication numbers and claim context
- Peer-reviewed journals (e.g., Geothermics)
- Specialized technical conferences (e.g., SPE)
This creates a verifiable audit trail, allowing R&D teams to trace conclusions back to original technical work.
Perplexity Deep Research
Perplexity emphasizes accessibility and breadth:
- News outlets, press releases, and aggregators
- Broad business and financial context
- Less reliance on primary technical literature
Why this matters for R&D:
R&D decisions depend on provable technical reality, not second-order interpretation. Cypris operates closer to the source of truth.
2. Technical Depth & Accuracy
(Weight: 25 points)
Sub-Score Breakdown
Mechanism & Approach Clarity
Cypris █████████░ 9/10
Perplexity ██████░░░░ 6/10
QuantitativeMetrics
Cypris ██████░░░░ 6/8
Perplexity ████████░░ 8/8
TechnicalAccuracy
Cypris ████████ 7/7
Perplexity █████░░░ 4/7
Cypris █████████░ 9/10
Perplexity ██████░░░░ 6/10
QuantitativeMetrics
Cypris ██████░░░░ 6/8
Perplexity ████████░░ 8/8
TechnicalAccuracy
Cypris ████████ 7/7
Perplexity █████░░░ 4/7
Cypris
- Describes how technologies function, not just what they are called
- Differentiates between drilling modalities (thermal, spallation, millimeter-wave)
- Surfaces real engineering constraints:
- casing and cement survivability
- induced seismicity
- subsurface execution limits
Perplexity
- Strong on metrics and figures
- Often relies on optimistic, press-level claims
- Less explicit about failure modes and boundary conditions
Interpretation:
Perplexity answers “How big is it?”
Cypris answers “Why does it work, and when does it fail?”
3. Competitive & IP Intelligence
(Weight: 20 points)
IP Visibility Comparison
Patent-Level Insight
Cypris ██████████ Explicit patents + claim context
Perplexity █░░░░░░░░░ No patents cited
Cypris ██████████ Explicit patents + claim context
Perplexity █░░░░░░░░░ No patents cited
Scores
Platform Score: Cypris 19/20 | Perplexity 11/20
Cypris
- Explicitly maps patents to companies and technologies
- Explains what the patents protect (e.g., closed-loop well architectures)
- Frames competitive strength around defensibility, not just presence
Perplexity
- Excellent identification of market participants
- Competitive positioning based on scale, revenue, and partnerships
- Minimal IP or freedom-to-operate analysis
Why this matters:
For R&D teams, unseen IP is hidden risk. Cypris makes those constraints visible.
4. Commercial Readiness Assessment
(Weight: 15 points)
Scores
PlatformScore: Cypris12/15 | Perplexity 14 / 15
Cypris
- Uses qualitative TRL language (pilot, demo, early commercial)
- Anchors readiness in technical validation events
- Less calendar-specific
Perplexity
- Excellent timeline specificity
- Clear commissioning dates and deployment targets
- Strong visibility into partnerships and funding
Interpretation:
Perplexity is superior for schedule visibility.
Cypris is superior for readiness realism.
5. Actionability for R&D Decisions
(Weight: 10 points)
Scores
Platform Score: Cypris 9 / 10 | Perplexity5 / 10
Actionability Profile
R&D Next-Step Enablement
Cypris █████████░ Patents, risks, technical gaps
Perplexity █████░░░░░ Partnerships, market context
Cypris enables teams to:
- Identify unresolved technical bottlenecks
- Assess engineering and regulatory risk
- Immediately investigate relevant patents and literature
Perplexity enables teams to:
- Identify potential partners
- Track funding and commercial momentum
6. Comprehensiveness
(Weight: 5 points)
Scores
Platform Score: Cypris 4/5 | Perplexity 5/ 5
Cypris gaps
- More North America–centric
- Does not cover lithium co-production
Perplexity strengths
- Strong global coverage
- Includes mineral and lithium narratives
Category Winners at a Glance
Source Authority: Cypris
Technical Depth: Cypris
Competitive & IP Intelligence: Cypris
Commercial Timelines: Perplexity
R&D Actionability: Cypris
Breadth & Geography: Perplexity
What This Reveals
This comparison surfaces a structural reality about modern AI research tools:
AI systems inherit the strengths and limitations of the data they are built on.
Tools trained primarily on news, web content, and corporate disclosures tend to optimize for visibility, narrative coherence, and breadth.
Tools grounded in patents, peer-reviewed literature, and technical primary sources optimize for verifiability, technical rigor, and execution realism.
Neither approach is inherently “better.” But they serve fundamentally different decisions. When timelines are long, capital intensity is high, and failure modes are technical—not commercial—that distinction becomes decisive.
Why This Matters for R&D Teams
Geothermal is simply one representative case. As R&D organizations increasingly operate at the frontier of:
- Advanced materials
- Energy storage
- Robotics
- Semiconductors
- Climate and industrial technologies
the downside of shallow or second-order research compounds rapidly—through missed constraints, hidden IP risk, and underestimated engineering challenges.
The organizations that consistently outperform are not those with more information, but those with information that is technically grounded, traceable to primary sources, and directly connected to execution realities.
That is the gap Cypris was built to address.
About Cypris
Cypris is an AI-native intelligence platform purpose-built for R&D teams. It connects patents, scientific literature, market signals, and internal knowledge into a single compounding research system—so teams can move faster without sacrificing rigor.
To see Cypris in action schedule a demo at cypris.ai

Global Geothermal Energy Production Landscape: Technology Leaders, Market State, and Commercial Readiness (2026)
This article was powered by Cypris Q, an AI agent that helps R&D teams instantly synthesize insights from patents, scientific literature, and market intelligence from around the globe. Discover how leading R&D teams use Cypris Q to monitor technology landscapes and identify opportunities faster - Book a demo
Executive Summary
Global geothermal electricity production remains commercially mature in regions where high-quality hydrothermal resources exist, but the industry's near-term growth narrative is increasingly shaped by next-generation geothermal technologies attempting to expand the addressable resource base beyond naturally permeable reservoirs [1, 2, 3]. Enhanced Geothermal Systems (EGS) and closed-loop advanced geothermal systems represent the frontier of this expansion, promising to unlock geothermal potential in geographies that lack the fortuitous combination of heat, permeability, and fluid that traditional hydrothermal projects require.
In the short term over the next three to seven years, market momentum is likely to concentrate in jurisdictions that place high value on firm clean capacity and are creating bankable offtake pathways. This dynamic is illustrated by large planned pipelines in the United States and by long-duration procurement signals such as multi-hundred megawatt power purchase agreements for next-generation geothermal supply [4, 5, 6]. These commercial commitments signal that utilities and grid operators increasingly recognize geothermal's unique value proposition as a dispatchable, weather-independent clean energy source capable of providing baseload and flexible generation in ways that wind and solar cannot.
Technology leadership in the geothermal sector is notably bifurcated. Incumbent developers lead in commercial execution, plant operations, and reservoir management know-how built over decades of hydrothermal project delivery. Meanwhile, advanced geothermal developers and oilfield service firms lead much of the innovation in drilling, well construction, flow control, and subsurface management that will ultimately determine whether geothermal can scale materially into new geographies [7, 8, 9, 2]. This split between operational maturity and technological frontier creates both partnership opportunities and competitive tensions as the industry evolves.
Methodology and Assumptions
This Cypris Q analysis integrates market and pipeline reporting with commercial milestones, validated through peer-reviewed papers and recent patent filings on EGS, closed-loop systems, and superhot geothermal engineering [4, 2, 3, 10, 11, 7, 8]. The approach triangulates multiple evidence streams to distinguish between genuine technical progress and promotional claims.
Technology leaders are identified using three criteria: evidence of operational deployments or pilots, commercial traction demonstrated through power purchase agreements and planned capacity, and innovation footprint visible in patents and technical publications [5, 6, 11, 7, 9]. Web sources describing commercialization milestones are treated as market signals and are not used alone to substantiate technical performance claims without corroborating primary technical sources [12, 2, 11].
Detailed Analysis
State of the Global Market
The geothermal market presents a paradox: it is simultaneously one of the most proven clean energy technologies and one of the most geographically constrained. Understanding this tension is essential for evaluating investment opportunities and technology trajectories.
Conventional hydrothermal geothermal is an established grid-power technology with decades of operational history, but it remains constrained by the need for naturally occurring heat, permeability, and fluids in the right combination [1]. This geological lottery makes the traditional market comparatively stable and project-by-project rather than exhibiting the rapid, manufacturing-like scale curves seen in solar and wind deployment [1]. Projects proceed where nature has provided the right subsurface conditions, and expansion into new regions requires either discovering new hydrothermal resources or developing technologies that can create productive reservoirs where nature has not.
Despite these constraints, the market is re-accelerating due to evolving power system needs. The near-term demand driver is the power system value of firm and flexible clean generation. As grids incorporate higher penetrations of variable renewable energy, the premium on dispatchable clean capacity increases. Modeling work published in Nature Energy highlights geothermal's potential role as a flexible resource in deeply decarbonized grids, elevating its value relative to purely energy-only resources that cannot guarantee availability when needed [13]. This flexibility premium is drawing new attention from utilities, grid operators, and policymakers who recognize that achieving deep decarbonization requires more than intermittent renewables alone.
Near-term pipeline indicators suggest this renewed interest is translating into project development. A Global Energy Monitor briefing reported 1.2 GW of geothermal capacity planned in the United States within a near-term policy window, indicating that policy alignment can quickly generate visible project pipelines even if actual commissioning occurs over longer timeframes [4]. This pipeline growth reflects both improved economics and increasing recognition of geothermal's grid services value.
The Data Center Demand Catalyst
Perhaps no single factor has accelerated geothermal investment more dramatically than the explosive growth of artificial intelligence and its voracious appetite for electricity. Data center power demand, driven largely by AI workloads, could more than double by 2026 according to the International Energy Agency, creating an urgent need for clean, firm generation that can operate around the clock [31]. This demand profile aligns perfectly with geothermal's core value proposition.
Analysis from the Rhodium Group projects that if scaled effectively, enhanced geothermal systems could supply nearly two-thirds of new data center demand by 2030 [32]. This potential has not gone unnoticed by hyperscale technology companies. Google was among the earliest backers of Fervo Energy and has since expanded its geothermal commitments, including a partnership with Baseload Capital for geothermal supply in Taiwan [33]. Meta has emerged as a particularly aggressive geothermal buyer, signing deals with both Sage Geosystems for 150 MW east of the Rocky Mountains and XGS Energy for another 150 MW in New Mexico to support data center expansion [34, 35]. Microsoft and G42 announced plans for a geothermal-powered data center in Kenya as part of a $1 billion investment targeting 1 GW of sustainable power [36].
The strategic logic for technology companies extends beyond environmental commitments. Major players including Microsoft and Google have pledged to match their electricity consumption with clean energy on an hourly basis by 2030, a target that intermittent renewables alone cannot achieve [32]. Geothermal's high availability factor makes it uniquely suited to satisfy these 24/7 clean energy requirements. As one Meta executive described these agreements, they represent "strategic bets designed to help technologies and companies scale, to prove their technical feasibility at scale, and to drive down costs in an accelerated way" [37].
Technology Segments and Commercial Readiness
The geothermal technology landscape encompasses several distinct approaches, each with different readiness levels and commercialization pathways. Understanding these distinctions is critical for evaluating market opportunities and technology bets.
Hydrothermal Geothermal represents the commercially mature baseline with high readiness [1]. These systems tap naturally occurring reservoirs where heat, permeability, and fluid coexist, enabling straightforward extraction and power generation. Innovation focus in the near term centers on incremental performance and operations improvements, including system optimization and advanced monitoring capabilities [14, 15], as well as integration into district heating concepts that can improve overall project economics by capturing value from both electricity and thermal energy [16]. While hydrothermal resources are geographically limited, they remain the foundation of global geothermal capacity and the proving ground for operational practices that advanced systems will need to match.
Enhanced Geothermal Systems (EGS) occupy the demonstration-to-early-commercial stage with medium readiness. EGS seeks to create or enhance permeability in hot rock using hydraulic or thermal stimulation techniques, expanding geothermal beyond naturally permeable reservoirs and dramatically increasing the theoretical resource base [17]. Recent modeling emphasizes that deep and high-temperature EGS can be energetically attractive but requires strict subsurface conditions to succeed commercially. Achieving appropriate bulk permeability without unacceptable injection pressures and managing thermal drawdown over multi-decade project lifetimes remain significant technical challenges [3]. Multi-well and horizontal-well fracturing concepts are actively being studied to improve heat extraction performance and reduce short-circuiting risk where injected fluid bypasses the heat exchange zone [18]. Readiness remains site-specific, with execution risk concentrated primarily in the subsurface where geological uncertainty is highest [3, 18].
Closed-Loop and Advanced Geothermal Systems (CLGS/AGS) represent an approach where commercial viability hinges critically on drilling economics. Closed-loop systems extract heat without producing formation fluids, typically relying on conductive heat transfer through the wellbore wall rather than convective transfer through produced fluids [2, 10]. This approach eliminates many of the subsurface uncertainties that plague EGS but introduces its own constraints. A large parametric modeling study found that closed-loop systems can reach competitive levelized cost of heat, but competitive levelized cost of electricity generally requires substantial drilling cost reductions [2]. The study emphasized that higher temperatures exceeding 200°C at depth materially improve power generation potential [2]. A separate techno-economic analysis similarly concludes that AGS remain uneconomic with standard drilling practices, implying that significant drilling cost reductions on the order of 50% or more represent a key enabling condition for widespread deployment [10].
This drilling cost sensitivity creates a clear innovation target. For heat applications, closed-loop systems show higher near-term readiness in suitable geological basins where drilling depths are manageable [2]. For electricity applications, economics remain sensitive to drilling cost and well configuration, making early commercialization plausible but not broadly cost-competitive under standard drilling paradigms [2, 10]. Patent activity shows aggressive development of closed-loop well construction and operation methods, including drilling thermal management techniques and sealed wellbore creation approaches that could reduce costs and improve performance [7, 8, 11].
Superhot and Supercritical Geothermal targets extreme subsurface conditions that can dramatically raise individual well productivity but introduces major integrity, corrosion, and scaling challenges that push the boundaries of materials science and well engineering [19, 11, 20]. Research highlights complex permeability behavior and thermo-mechanical effects around approximately 400°C where rock properties change significantly [21], scaling risks including halite precipitation that can clog wells and reduce productivity [22, 19], and well integrity challenges driven by thermal shocks affecting casing and cement systems during drilling and production cycles [23, 11]. Corrosion testing suggests common casing material choices can face localized corrosion risks in simulated superhot environments, requiring either new materials or protective strategies [20, 24]. Readiness remains low-to-medium, with activity concentrated primarily in pilots and de-risking research rather than widespread commercial deployment [11, 19].
Technology Leadership Landscape
Leadership in geothermal differs substantially depending on whether the criterion is commercial deployment today or the ability to scale geothermal into new geographies tomorrow. This distinction matters for strategic positioning and partnership decisions.
Commercial Leaders in Hydrothermal Execution and Bankability
The most bankable near-term geothermal capacity continues to come from incumbent hydrothermal developers, operators, and established plant integrators. Their leadership position rests on proven project delivery track records and reservoir management workflows refined over decades of operational experience [1]. These companies have demonstrated the ability to bring projects from exploration through construction to long-term operation, managing the geological, engineering, and financial risks that characterize geothermal development.
Ormat Technologies exemplifies this incumbent advantage. The Nevada-based company, originally founded in Israel, operates the largest geothermal power plant on Earth at The Geysers in Northern California and maintains a global portfolio of conventional hydrothermal assets. Recognizing the strategic importance of next-generation technologies, Ormat signed a landmark partnership with Sage Geosystems in September 2025 to license Sage's Pressure Geothermal technology for deployment at existing Ormat facilities [38]. This deal signals that even established players view advanced geothermal as essential to future growth and are willing to partner rather than develop these capabilities purely in-house.
Innovation at incumbent firms tends to focus on plant optimization and market expansion rather than fundamental technology shifts. Patent activity shows emphasis on power plant performance optimization systems and integration into district heating networks that can improve project economics [16, 14]. These incremental improvements compound over time, reducing operating costs and extending asset life, but they do not fundamentally change the geographic constraints of hydrothermal development.
Innovation Leaders Expanding the Resource Base
The leading edge of efforts to expand geothermal everywhere is concentrated among several distinct groups, each bringing different capabilities to the challenge.
Fervo Energy has emerged as the frontrunner among enhanced geothermal startups, attracting over $1.5 billion in total funding since its 2017 founding by Tim Latimer and Jack Norbeck, who met at Stanford University [39]. The company's approach adapts horizontal drilling and hydraulic fracturing techniques from the oil and gas industry to create engineered geothermal reservoirs in hot rock formations. Fervo's technical progress has been remarkable: wells that initially took a month to drill are now completed in as little as 16 days, cutting drilling costs nearly in half from $9.4 million to $4.8 million per well [40]. This drilling speed improvement is both economically significant and a demonstration of operational mastery.
Fervo's Cape Station project in Utah represents the clearest proof point for commercial-scale EGS. The 500 MW development will deliver its first 100 MW to the grid in late 2026, with an additional 400 MW expected by 2028 [41]. The project has secured offtake commitments from Southern California Edison, Shell Energy North America, and others, representing one of the most significant commercial validations of next-generation geothermal to date. In December 2025, Fervo closed a $462 million Series E round led by B Capital with participation from Google, positioning the company for potential IPO consideration as it scales operations [42].
Eavor Technologies, the Canadian closed-loop pioneer, achieved a major milestone in December 2025 when its Geretsried facility in Germany began delivering power to the grid, marking the first commercial demonstration of its Eavor-Loop technology [43]. The 8 MW facility circulates a proprietary working fluid through a radiator-like underground network, extracting heat through conduction rather than requiring produced fluids or induced fracturing. This approach eliminates concerns about induced seismicity and can theoretically be deployed almost anywhere hot rock exists at depth.
Eavor's value proposition centers on operational simplicity and longevity. The company claims its systems can operate for up to 100 years without additional drilling and require no continuous pumping, eliminating parasitic load [43]. As advisor Michael Liebreich noted, "Closed loop geothermal offers a very different value proposition to wind and solar," though he cautioned that "at its heart, Eavor is a bet on improvements in drilling technology" [43]. The company secured $65 million in late-stage venture funding in June 2025 and is now targeting the U.S. data center market and expansion into Japan [44].
Sage Geosystems has carved out a distinctive position with its Pressure Geothermal technology, which captures both heat and mechanical pressure from hot, dry rock formations. Founded by Cindy Taff, who spent four decades at Shell, Sage leverages extensive oil and gas expertise to target low-permeability formations at depths between 2.5 and 6 kilometers [45]. The company estimates its approach can unlock over 130 times more geothermal potential in the U.S. alone compared to conventional approaches [45].
Sage's technology uniquely doubles as long-duration energy storage, capable of absorbing excess renewable generation and releasing it when demand peaks. The company operates a 3 MW commercial energy storage facility in Christine, Texas and has secured significant commercial traction including the 150 MW Meta partnership and a strategic licensing agreement with Ormat [38, 46]. ABB signed a memorandum of understanding in February 2025 to collaborate on developing Sage's systems for data center applications [47].
XGS Energy represents a hybrid approach between enhanced and advanced geothermal. The company has signed a 150 MW agreement with Meta for a project in New Mexico expected online by 2030, and raised $13 million in March 2025 toward commercial deployment [48]. XGS was among eleven geothermal firms pre-qualified by the U.S. Air Force for potential defense installations, alongside Fervo, Sage, Quaise Energy, and GreenFire Energy [48].
Quaise Energy pursues perhaps the most ambitious technical approach, aiming to drill more than six miles deep to access temperatures exceeding 900°F using millimeter-wave drilling technology that vaporizes rock [49]. The Massachusetts-based company, spun out of MIT research, plans to drill its first full-size boreholes by 2028 with a target of reaching six miles in just 100 days [49]. If successful, this approach could make geothermal viable virtually anywhere on Earth by accessing the extreme temperatures found at great depth.
Factor2 Energy, founded by former Siemens Energy executives, is developing a novel approach using CO2 rather than water as the working fluid, which can deliver up to twice the power output under comparable geological conditions while requiring significantly lower capital expenditure [50]. The company completed a $9.1 million seed round in September 2025 to accelerate commercialization [50].
Oilfield Service and Subsurface Technology Firms bring decades of drilling and completion expertise to geothermal applications. Cypris Q analysis of patent activity shows development of geothermal-specific downhole materials and tools, including high-temperature elastomers capable of surviving extreme conditions [9, 28], and geothermal flow control and optimization concepts adapted from oil and gas applications [29, 30]. Baker Hughes has emerged as a key supplier, winning a contract to design and deliver five steam turbines for Fervo's Cape Station project that will generate 300 MW collectively [51]. This technology transfer from hydrocarbon extraction to geothermal represents a significant innovation pathway, leveraging existing supply chains and engineering knowledge bases.
Market Leaders by Commercial Traction
Beyond technology development, commercial traction provides the clearest signal of near-term market leadership. The ability to convert technical capability into contracted revenue separates demonstration projects from scalable businesses.
Large Offtake Commitments as Leadership Markers
A major near-term leadership marker is the ability to secure long-term power purchase agreements at meaningful scale. Fervo Energy's 320 MW of PPAs with Southern California Edison represents one of the clearest public indicators that creditworthy buyers will contract next-generation geothermal at scale if delivery risk appears manageable [5]. The procurement has associated regulatory documentation at the California Public Utilities Commission level, indicating seriousness of the contracting pathway and providing visibility into terms and conditions [6]. These commitments signal that advanced geothermal has crossed a threshold from science project to investable infrastructure, at least in the eyes of major utility buyers.
The data center sector has emerged as an equally important source of commercial validation. Startups working on enhanced or advanced geothermal systems have raised more than $1.3 billion from investors including oil majors such as Chevron and Baker Hughes, according to Wood Mackenzie [52]. The research firm estimates the Great Basin region including Nevada, Utah, and parts of California, Oregon, and Wyoming could support at least 135 GW of capacity, roughly 10 percent of U.S. power supply [52]. Even without federal tax credits, the levelized cost of energy from next-generation projects like Cape Station is approximately $79 per megawatt-hour, increasingly competitive with other firm generation sources [52].
Drilling Economics and Reliability as the Critical Scale Gates
Across both academic papers and patent filings, the same bottleneck emerges repeatedly as the gating factor for industry scaling.
For closed-loop and AGS systems, economics are dominated by drilling cost. Multiple techno-economic analyses conclude that these systems need significant drilling cost reductions to achieve competitive levelized cost of electricity [2, 10]. This creates a clear innovation target and explains the intense focus on drilling efficiency, well construction methods, and drilling thermal management visible in recent patent activity. Fervo's demonstration that drilling times can be reduced from 30 days to 16 days, with corresponding cost reductions approaching 50%, suggests this barrier is surmountable with continued operational learning [40].
For superhot and high-temperature systems, well integrity represents the critical constraint. Success hinges on managing cement and casing thermal stress under extreme temperature cycling and controlling corrosion and scaling under conditions that exceed the design limits of conventional materials [11, 20, 22]. The patent record suggests companies are actively engineering solutions to these constraints, developing drilling cooling methods, sealed well construction techniques, and high-temperature downhole materials specifically designed for geothermal applications [8, 7, 9].
Conclusion and Strategic Recommendations
The global geothermal landscape is best described as mature hydrothermal production operating alongside a rapidly innovating engineered geothermal frontier [1, 2]. These two segments have different risk profiles, return characteristics, and scaling trajectories that investors and strategic partners must evaluate separately.
In the short term, the market is likely to reward companies that can achieve three interrelated objectives. First, reducing drilling cost and cycle time represents the prerequisite for closed-loop and AGS electricity competitiveness, and progress on this dimension will unlock deployment in geographies currently uneconomic [2, 10]. Fervo's demonstrated ability to cut drilling times by nearly half provides a template for the learning curve required. Second, demonstrating reliable high-temperature well integrity and flow assurance will enable access to the most productive superhot resources and reduce the operational risk premium that currently constrains financing [11, 20]. Third, converting technical credibility into bankable revenue through large offtake agreements and visible development pipelines provides the commercial validation that attracts capital and talent [5, 4].
The convergence of AI-driven data center demand, technology company sustainability commitments, and bipartisan policy support has created unprecedented momentum for geothermal development. With installed capacity projected to grow from 16.8 GW today to 28 GW by 2030 and potentially 110 GW by 2050, the market growth trajectory is expected to attract investments totaling over $120 billion between now and 2035 [47].
Commercial leadership today remains concentrated among hydrothermal incumbents due to their proven project execution capabilities [1]. However, leadership in expanding the market is increasingly visible among advanced geothermal developers and the oilfield services supply chain. This shift is evidenced by concentrated patenting activity and the strong linkage between geothermal scaling and downhole engineering innovation that these players are driving [11, 7, 8, 9]. The companies that bridge the gap between technological innovation and commercial execution will likely emerge as the dominant players in what could become a significantly larger global geothermal market.
References
[1] Izadi G, Freitag HC. "Resource assessment and management for different geothermal systems (hydrothermal, enhanced geothermal, and advanced geothermal systems)." Elsevier eBooks. doi:10.1016/b978-0-443-21662-6.00003-7.
[2] Bettin G, Augustine C, Bernat A, Parisi C, Marshall TD. "Numerical investigation of closed-loop geothermal systems in deep geothermal reservoirs." Geothermics. doi:10.1016/j.geothermics.2023.102852.
[3] Houde M, Scott S, Yapparova A, Weis P. "Hydrological constraints on the potential of enhanced geothermal systems in the ductile crust." Geothermal Energy. doi:10.1186/s40517-024-00288-4.
[4] Global Energy Monitor. "GEM GGPT brief March 2025." https://globalenergymonitor.org/wp-content/uploads/2025/03/GEM-GGPT-brief-March-2025.pdf.
[5] Fervo Energy. "Fervo Energy Announces 320 MW Power Purchase Agreements with Southern California Edison." https://fervoenergy.com/fervo-energy-announces-320-mw-power-purchase-agreements-with-southern-california-edison/.
[6] California Public Utilities Commission. "Published Documentation." https://docs.cpuc.ca.gov/PublishedDocs/Published/G000/M528/K560/528560288.PDF.
[7] Eavor Technologies Inc. "Forming High-Efficiency Geothermal Wellbores." Patent No. US-20250146713-A1. Issued May 8, 2025.
[8] Eavor Technologies Inc. "Cooling for geothermal well drilling." Patent No. US-12140028-B2. Issued Nov 12, 2024.
[9] Halliburton Energy Services, Inc. "Downhole Tools Having Elastomer Blend For Geothermal Wellbores." Patent No. US-20250154848-A1. Issued May 15, 2025.
[10] Malek AE, Saar MO, Schiegg HO, Rossi E, Adams BM. "Techno-economic analysis of Advanced Geothermal Systems (AGS)." Renewable Energy. doi:10.1016/j.renene.2022.01.012.
[11] Bois AP, Coudert T, Hoang NH, Naumann M, Sæther SA. "Effect of Cement Behaviour on Casing Integrity in Superhot Geothermal Wells: A Numerical Study." 50th U.S. Rock Mechanics/Geomechanics Symposium. doi:10.56952/arma-2022-0738.
[12] Power Magazine. "Eavor's First-of-Its-Kind Closed-Loop Geothermal Project Produces Grid Power in Germany." https://www.powermag.com/eavors-first-of-its-kind-closed-loop-geothermal-project-produces-grid-power-in-germany/.
[13] Jenkins J, Voller K, Norbeck J, Ricks W, Galban G. "The role of flexible geothermal power in decarbonized electricity systems." Nature Energy. doi:10.1038/s41560-023-01437-y.
[14] Ormat Technologies Inc. "System for Optimizing and Maintaining Power Plant Performance." Patent No. US-20210332806-A1. Issued Oct 28, 2021.
[15] Schlumberger Technology Corporation. "Monitoring and Managing a Geothermal Energy System." Patent No. US-20250207564-A1. Issued Jun 26, 2025.
[16] Ormat Technologies, Inc. "Geothermal district heating power system." Patent No. US-11905856-B2. Issued Feb 20, 2024.
[17] Baba A, Chandrasekharam D. "Enhanced Geothermal Systems (EGS)." CRC Press eBooks. doi:10.1201/9781003271475.
[18] Tie Y, Wu H, Chen D, Hu L, Liu H. "Numerical investigations on the performance analysis of multiple fracturing horizontal wells in enhanced geothermal system." Geothermal Energy. doi:10.1186/s40517-025-00338-5.
[19] Driesner T, Yapparova A, Lamy-Chappuis B. "Advanced well model for superhot and saline geothermal reservoirs." Geothermics. doi:10.1016/j.geothermics.2022.102529.
[20] Straume EO, Þórhallsson AI, Karlsdóttir SN, Boakye GO, Þráinsdóttir MÝ. "Corrosion Testing of Carbon Steel and 13Cr Casing Materials in Simulated Superhot Deep Geothermal Well Environment." Conference proceedings. doi:10.5006/c2024-20903.
[21] Watanabe N, Nakayama D, Pramudyo E, Goto R, Takahashi R. "Cooling-induced permeability enhancement for networks of microfractures in superhot geothermal environments." Geothermal Energy. doi:10.1186/s40517-023-00251-9.
[22] Ellingsen L, Haug-Warberg T. "Thermodynamics of Halite Scaling in Superhot Geothermal Systems." Energies. doi:10.3390/en17122812.
[23] Anfinsen BT, Meng M, Liu Y, Zhou L. "Advanced Numerical Analysis of Well Integrity and Thermal Dynamics in Superhot Geothermal Reservoirs." SPE Annual Technical Conference and Exhibition. doi:10.2118/228037-ms.
[24] Straume EO, Karlsdóttir SN, Boakye GO, Ijegbai DA. "Corrosion Behavior of L80-Carbon Steel and 13 Cr Casing Materials at 400°C in Simulated Superhot Geothermal Well Environment." Conference proceedings. doi:10.5006/c2025-00067.
[25] Greenfire Energy Inc. "Geothermal heat recovery from high-temperature, low-permeability geologic formations for power generation using closed loop systems." Patent No. US-10527026-B2. Issued Jan 7, 2020.
[26] Greenfire Energy Inc. "System and Method for Geothermal Energy Production." Patent No. WO-2025147722-A1. Issued Jul 10, 2025.
[27] Polsky Y, Wang JA, Thakore V, Wang H, Ren F. "Stability study of aqueous foams under high-temperature and high-pressure conditions relevant to Enhanced Geothermal Systems (EGS)." Geothermics. doi:10.1016/j.geothermics.2023.102862.
[28] Halliburton Energy Services, Inc. "Downhole Tools Having Elastomer Blend For Geothermal Wellbores." Patent No. WO-2025106096-A1. Issued May 22, 2025.
[29] Baker Hughes Oilfield Operations LLC. "Flow control in geothermal wells." Patent No. AU-2021232588-B2. Issued Sep 14, 2023.
[30] Schlumberger Technology B.V. and Services Petroliers Schlumberger. "Monitoring and Managing a Geothermal Energy System." Patent No. EP-4575346-A1. Issued Jun 25, 2025.
[31] International Energy Agency. "Data center electricity demand projections." 2024.
[32] Rhodium Group. "The Potential for Geothermal Energy to Meet Growing Data Center Electricity Demand." 2024.
[33] Canary Media. "Inside the data-center energy race with Google and Microsoft." November 2025.
[34] Trellis. "Meta inks geothermal deal with startup XGS Energy." June 2025.
[35] Renewable Energy World. "Geothermal east of the Rockies? Meta and Sage team up to feed data centers." August 2024.
[36] Baseload Capital. "The hottest energy in tech: Why AI is turning to geothermal and vice versa." August 2025.
[37] Data Center Dynamics. "Drilling for data: Can geothermal power meet hyperscale ambitions?" November 2025.
[38] Latitude Media. "Geothermal giant Ormat inks major deal with upstart Sage Geosystems." September 2025.
[39] TechCrunch. "Google invests in Fervo's $462M round to unlock even more geothermal energy." December 2025.
[40] CNN. "They're using the techniques honed by oil and gas to find near-limitless clean energy beneath our feet." July 2025.
[41] MIT Technology Review. "2025 Climate Tech Companies to Watch: Fervo Energy and its advanced geothermal power plants." October 2025.
[42] Canary Media. "Fervo nabs $462M to complete massive next-gen geothermal project." December 2025.
[43] Geothermal Canada. "Geothermal Upstart Eavor Touts 1st Commercial Demo, Eyes US Data Center Market." December 2025.
[44] Net Zero Insights. "Five Geothermal Startups Powering the Clean Energy Transition." October 2025.
[45] Think GeoEnergy. "Sage Geosystems – Pioneering Pressure Geothermal with oil and gas expertise." November 2025.
[46] Data Center Frontier. "Meta's Investment In Data Center Geothermal Power Is Just the Latest In Clean Energy for Hyperscalers." August 2024.
[47] ABB News Center. "ABB and Sage Geosystems unearth geothermal energy opportunities." February 2025.
[48] CleanTechnica. "US Geothermal Energy Startup Endorsed By US Air Force." March 2025.
[49] Climate Insider. "5 Geothermal Startups to Keep An Eye On in 2025." March 2025.
[50] Net Zero Insights. "Factor2 Energy funding announcement." October 2025.
[51] TechCrunch. "Advanced geothermal startups are just getting warmed up." September 2025.
[52] Wood Mackenzie. "Enhanced geothermal market analysis." 2025.

Scientific literature review has been fundamentally transformed by artificial intelligence in 2026. Over 5.14 million academic articles are now published annually, creating an information deluge that makes comprehensive manual literature review practically impossible for individual researchers. Modern AI-powered research tools can analyze millions of papers in seconds, identify key findings across disciplines, and surface connections that would take human researchers months to discover.
For corporate R&D teams conducting systematic literature reviews, AI tools have become essential infrastructure for maintaining competitive intelligence and accelerating innovation cycles. Research indicates that AI-assisted literature review processes achieve completion times 30% faster than traditional methods while maintaining or improving review quality through systematic analysis capabilities that reduce human oversight errors.
The AI literature review tool landscape in 2026 divides into specialized platforms for academic researchers and comprehensive enterprise solutions serving corporate R&D organizations. This guide examines the leading AI scientific literature review tools available in 2026, their core capabilities, specific use cases, and which research workflows they serve most effectively.
Understanding AI Literature Review Tools: Key Concepts and Definitions
AI literature review tools are software platforms that use artificial intelligence, particularly natural language processing and machine learning algorithms, to assist researchers in discovering, analyzing, and synthesizing academic literature. These tools automate time-intensive aspects of literature review including paper discovery, relevance screening, data extraction, and citation analysis.
Core AI Capabilities in Literature Review Platforms
Semantic search understanding represents the foundation of modern literature review tools. Unlike keyword-based search that matches exact terms, semantic search understands research concepts, methodologies, and findings contextually. Leading platforms use transformer-based language models trained on millions of scientific papers to interpret queries based on meaning rather than literal word matching. This enables researchers to find papers discussing "machine learning bias mitigation" even when papers use terminology like "algorithmic fairness correction" or "model discrimination reduction."
Citation network analysis maps relationships between papers by analyzing how researchers cite each other's work. These network visualizations identify influential papers that many subsequent studies reference, research lineages showing how ideas developed over time, and emerging trends where citation patterns indicate growing interest. Citation network analysis has become standard functionality in serious research tools, with platforms differing primarily in visualization approaches and network computation algorithms.
Cross-disciplinary discovery surfaces relevant findings from adjacent research fields that traditional database searches miss entirely. The most sophisticated AI tools in 2026 can identify applicable methodologies and insights across discipline boundaries. For example, a materials science researcher investigating battery electrode designs might benefit from polymer chemistry findings, computational fluid dynamics methods, or even biological membrane transport models. AI systems trained across multiple scientific domains can recognize these conceptual similarities where human researchers constrained by field-specific expertise might not.
Natural language processing for concept extraction enables AI tools to understand what papers actually say rather than just matching keywords in titles and abstracts. Advanced NLP models extract key findings, methodology details, statistical results, and conclusions from paper full text. This allows researchers to query specific aspects like "studies using randomized controlled trials showing statistically significant results" or "papers reporting synthesis methods for graphene nanostructures."
How AI Literature Review Differs from Traditional Search
Traditional literature search relies on Boolean operators, controlled vocabulary terms, and manual screening of results. A researcher might construct a query like "(battery OR energy storage) AND (lithium) AND (electrolyte)" and receive hundreds or thousands of results requiring individual evaluation.
AI-powered literature review transforms this process through semantic understanding, relevance ranking, and automated screening. Instead of Boolean queries, researchers can ask questions in natural language like "What are the most promising solid-state electrolyte materials for lithium batteries?" AI systems interpret this query, search millions of papers, rank results by relevance to the specific question, and can even extract specific answers with citations to supporting papers.
The time savings are substantial. Research published in 2024 found that AI-assisted screening for systematic reviews achieved 85% accuracy in identifying relevant papers while reducing review time by approximately 40% compared to traditional manual screening processes. For corporate R&D teams evaluating competitive landscapes, these efficiency gains translate directly to faster time-to-market for new technologies.
The State of Scientific Literature in 2026
Scientific publication growth continues accelerating despite predictions of saturation. Worldwide scientific publication output reached 3.3 million articles in 2022, with growth rates averaging 4-5% annually. This represents a doubling time of approximately 17 years, meaning the volume of scientific literature doubles every generation of researchers.
Several factors drive this exponential growth. Global research expansion has brought millions of new researchers into the scientific community, particularly from rapidly developing economies. China now publishes over 1 million academic papers annually, representing 19.67% of global output. India's contribution increased from 3.5% in 2017 to 5.2% in 2024, reflecting substantial government investment in research infrastructure.
Digital publishing infrastructure has reduced publication barriers, enabling researchers to disseminate findings more rapidly through online journals and preprint servers. The shift from print to digital has accelerated publication cycles from months to weeks or even days for some platforms.
Institutional pressure to publish in academic and corporate research environments creates incentives for researchers to maximize publication output. The "publish or perish" culture in academia combined with corporate requirements for documented innovation has contributed significantly to literature growth.
The Information Overload Challenge
For researchers attempting comprehensive literature review, this publication explosion creates serious practical challenges. A researcher investigating battery technology might face 10,000+ relevant papers published in the last five years alone. Reading even abstracts for this volume would require weeks of full-time work before beginning actual analysis.
Manual literature review methods scale poorly beyond several hundred papers. Traditional systematic review processes involving multiple human reviewers screening thousands of papers can take 6-18 months for completion. Corporate R&D teams evaluating market opportunities cannot wait this long for competitive intelligence.
This is where AI literature review tools provide transformative value. Platforms capable of processing millions of papers in seconds, identifying the most relevant studies through semantic analysis, and extracting key findings automatically make comprehensive literature review practical again even as publication volumes continue growing.
Data Coverage: Why Scale Matters
The difference between platforms accessing 50 million papers versus 500 million papers significantly impacts research completeness for corporate R&D teams evaluating competitive landscapes.
Academic-focused tools often provide adequate coverage for established research domains where relevant literature concentrates in well-indexed journals. Corporate R&D intelligence requires broader coverage spanning patents, technical reports, conference proceedings, and scientific literature across multiple disciplines.
For emerging technology areas, comprehensive coverage becomes critical. Early research in novel fields may appear in diverse venues including preprint servers, conference papers, and journals across multiple disciplines before the field coalesces. Platforms with limited coverage risk missing crucial early work that provides competitive intelligence about emerging threats or opportunities.
Top AI Tools for Scientific Literature Review in 2026
1. Cypris - Enterprise R&D Intelligence Platform
Best for: Corporate R&D teams requiring comprehensive technology intelligence combining patents and scientific literature
Cypris serves as enterprise research infrastructure for Fortune 500 R&D and IP teams, providing unified access to over 500 million patents and scientific papers through a single AI-powered platform. Unlike academic literature tools focused exclusively on paper discovery, Cypris delivers complete technology intelligence by combining patent analysis, scientific literature review, and competitive R&D monitoring in one comprehensive system.
Comprehensive Data Integration
The platform's proprietary R&D ontology enables semantic understanding of research concepts across patents and papers simultaneously, letting corporate teams identify both academic findings and commercial applications in single searches. This integration proves essential for corporate R&D decision-making where understanding both scientific feasibility and patent landscape determines project viability.
For example, a pharmaceutical company researching novel drug delivery mechanisms needs to understand both academic research on biological transport systems and existing patents covering delivery technologies. Cypris enables simultaneous analysis across both domains, revealing which academic approaches already face patent barriers and which scientific findings offer clear commercial paths.
Advanced Search Capabilities
Multimodal search capabilities process natural language queries, technical diagrams, chemical structures, and product specifications to surface relevant prior art and research regardless of how information is expressed. This proves particularly valuable for materials science, chemistry, and engineering applications where visual information like molecular structures or technical diagrams conveys information that text descriptions cannot adequately capture.
Researchers can upload a technical drawing of a mechanical component and find both papers describing similar designs and patents covering related inventions. Similarly, chemists can search using molecular structures to find papers and patents discussing specific compounds or structural classes.
Enterprise Features and Security
For enterprises, Cypris distinguishes itself through SOC 2 Type II certification, US-based operations, and official API partnerships with OpenAI, Anthropic, and Google. These certifications and partnerships provide corporate R&D teams with the security guarantees, data protection, and integration capabilities that Fortune 500 compliance requirements demand.
The platform integrates with knowledge management systems used by corporate R&D teams, enabling systematic literature review as part of broader innovation workflows rather than isolated research activities. Teams can incorporate Cypris intelligence into product development cycles, IP strategy sessions, and competitive monitoring processes.
Corporate R&D Success at Scale
Hundreds of enterprise customers across Fortune 500 R&D organizations rely on Cypris for technology intelligence that combines patent landscapes with scientific research in unified analyses. This comprehensive approach provides the complete competitive context corporate teams need for strategic R&D decisions about technology investments, patent filing strategies, and market positioning.
Corporate teams report that Cypris's unified approach to patents and papers reduces the time required for comprehensive technology assessments by 60-70% compared to using separate patent and literature search tools. The elimination of manual data integration between disparate systems proves particularly valuable for fast-moving competitive intelligence projects.
Cypris pricing is customized for enterprise deployments serving R&D organizations and IP teams at scale.
2. Semantic Scholar - Free Academic Search Engine
Best for: Academic researchers needing free access to AI-powered paper discovery
Semantic Scholar from AI2 provides free access to over 200 million academic papers with AI-powered search and recommendation capabilities. The platform represents one of the largest openly available scientific search engines, making it valuable for researchers at institutions with limited journal subscription budgets or those prioritizing open access materials.
AI-Powered Discovery Features
The platform uses machine learning models to understand semantic relationships between papers, going beyond simple keyword matching to identify conceptually related research. Semantic Scholar's recommendation algorithms analyze paper content, citation patterns, and research trajectories to suggest related work researchers might otherwise miss.
The tool's "TL;DR" feature provides AI-generated summaries of paper abstracts, giving researchers quick overviews before committing time to full paper reading. These summaries extract key findings and methodology highlights, though researchers should verify important details against source material for critical applications.
Limitations for Corporate Use
Semantic Scholar excels at surfacing influential papers within specific research domains and identifying highly-cited works that represent field consensus. However, the platform lacks enterprise features, patent integration, and the comprehensive coverage corporate R&D teams require for competitive intelligence.
The tool serves academic literature discovery but cannot support technology landscape analysis that requires understanding both scientific research and patent protection status. Corporate teams evaluating commercialization opportunities need unified access to patents and papers that Semantic Scholar cannot provide.
Semantic Scholar is free for all users, supported by the Allen Institute for AI's research mission.
3. Connected Papers - Visual Literature Mapping
Best for: Researchers exploring citation networks and research lineages around specific papers
Connected Papers creates visual graphs showing papers related to a seed paper, helping researchers discover connected work through citation networks. The platform's visualization approach makes it particularly useful for researchers entering new fields who need to quickly understand research landscapes and identify foundational papers.
Visual Discovery Approach
The tool generates network graphs where each node represents a paper and edges show citation or similarity relationships. The visual interface makes it easy to identify clusters of related research, see how ideas have evolved through citation relationships, and spot influential papers that many studies reference.
Researchers can start with a single known paper and expand outward to discover prior work that influenced it, subsequent papers building on its findings, and parallel research addressing similar questions through different approaches. This visual exploration approach complements traditional database searching by revealing relationships that keyword searches might miss.
Academic Focus and Limitations
However, the tool focuses exclusively on academic papers without patent integration, provides limited semantic search capabilities, and lacks enterprise features. Connected Papers serves academic literature exploration but cannot support comprehensive technology intelligence for corporate R&D teams evaluating competitive landscapes where patent analysis proves equally important.
The platform works well for PhD students mapping research fields for dissertation work or academic researchers identifying key papers for literature reviews. Corporate applications requiring patent integration, enterprise security, or commercial technology assessment need more comprehensive platforms.
Connected Papers offers free and paid subscription tiers with expanded features.
4. Research Rabbit - Citation Discovery Platform
Best for: Academic researchers building comprehensive reference collections through citation networks
Research Rabbit helps researchers discover papers through citation relationships and co-citation networks, making it valuable for systematic reference collection. The platform emphasizes collaborative features, enabling research teams to build shared collections and track emerging literature in areas of interest.
Collaborative Collection Building
The tool lets users create collections of papers and automatically suggests related work based on citation patterns, co-citation relationships, and bibliographic similarities. As researchers add papers to collections, Research Rabbit continuously updates suggestions based on the evolving collection profile.
Collaborative features enable research teams to build shared collections and track new papers in areas of interest through automated alerts. Teams receive notifications when new papers cite works in their collections or when influential papers appear in tracked fields, helping researchers maintain current awareness without constant manual searching.
Limitations for Corporate Intelligence
Research Rabbit serves academic research teams well but lacks the patent analysis, enterprise security certifications, and comprehensive coverage of engineering and applied science literature that corporate R&D organizations require. The platform focuses exclusively on published literature without commercial technology intelligence capabilities.
Corporate R&D teams need to understand patent landscapes, commercial applications, and competitive R&D activity alongside academic research. Research Rabbit's purely academic focus limits its utility for strategic technology intelligence that informs commercialization decisions.
Research Rabbit is currently free for all users, though premium features may be introduced as the platform develops.
5. Litmaps - Interactive Literature Mapping
Best for: Researchers visualizing research literature development over time
Litmaps creates interactive citation maps showing how research literature has developed chronologically, helping researchers understand field evolution. The platform visualizes citation relationships as networks evolving over time, providing temporal context that traditional citation lists lack.
Temporal Visualization
Users can identify seminal papers that launched new research directions, track how specific concepts emerged and spread through scientific communities, and discover recent work building on foundational studies. The temporal visualization shows which papers influenced subsequent research waves and how quickly ideas propagated through citation networks.
This approach proves particularly valuable for researchers investigating how fields developed, identifying paradigm shifts where research directions changed substantially, and understanding current research frontiers in relation to historical foundations.
Coverage and Feature Limitations
The tool serves academic researchers exploring established fields but provides limited coverage of recent literature, lacks patent integration, and offers no enterprise features for corporate R&D applications. Litmaps focuses on academic literature mapping without the comprehensive technology intelligence capabilities commercial organizations require.
Corporate teams investigating emerging technologies need current literature coverage, patent analysis, and competitive intelligence that extends beyond academic publication patterns. Litmaps' temporal focus on research history serves different needs than forward-looking competitive technology assessment.
Litmaps offers free and paid subscription options with different feature sets and usage limits.
6. Scholarcy - AI Article Summarization
Best for: Researchers processing large volumes of papers who need quick summaries during initial screening
Scholarcy uses AI to generate structured summaries of academic papers, extracting key findings, methodology, results, and conclusions into consistent formats. The tool can process PDFs and generate summary flashcards highlighting main points, making it useful for rapid literature screening.
Automated Summary Generation
For researchers conducting initial screening of papers during systematic reviews, Scholarcy accelerates the filtering process by providing structured overviews without requiring full paper reading. The tool extracts study design, participant information, key findings, and statistical results into standardized summary formats.
This proves particularly valuable during the early stages of systematic review when researchers must screen hundreds or thousands of papers for potential relevance. Scholarcy enables rapid assessment of whether papers merit full reading based on automatically extracted key information.
Limited Scope for R&D Intelligence
However, Scholarcy provides summarization rather than comprehensive search and discovery capabilities. The tool lacks semantic search, patent integration, and enterprise features that corporate R&D teams need for technology intelligence. Scholarcy works well for individual researchers processing academic papers but cannot support organizational knowledge management or competitive intelligence workflows.
Corporate R&D applications require tools that not only summarize individual papers but also synthesize findings across hundreds of documents, identify patterns in competitive research activity, and integrate patent landscape analysis with scientific literature review.
Scholarcy offers individual subscription plans with different feature tiers and usage limits.
7. Iris.ai - AI Research Assistant
Best for: Researchers exploring new fields and discovering relevant papers through AI recommendations
Iris.ai uses AI to help researchers discover relevant papers when exploring unfamiliar research areas, making it useful for interdisciplinary investigations. The platform analyzes paper content semantically to suggest related research beyond simple keyword or citation matching.
Semantic Discovery Across Disciplines
Users can upload papers or abstracts and receive AI-generated recommendations for related work across disciplines. The tool particularly helps researchers identify relevant findings from adjacent fields that share conceptual similarities rather than direct citations, enabling cross-disciplinary knowledge transfer.
This capability proves valuable for applied research where solutions might come from unexpected disciplines. An engineer investigating bio-inspired design might benefit from biological papers describing natural structures, materials science research on biomimetic materials, and design research on biomimicry methodologies.
Individual Researcher Focus
Iris.ai serves individual researchers and small academic teams but lacks comprehensive data coverage, patent integration, and enterprise security features. The platform focuses on academic paper discovery without the commercial technology intelligence and competitive R&D monitoring capabilities corporate organizations require for strategic decision-making.
Corporate R&D teams need platforms that scale to organizational usage, integrate with enterprise systems, provide audit trails for compliance, and combine multiple intelligence sources including patents, papers, and market data in unified analyses.
Iris.ai offers subscription-based pricing for individual researchers and small teams.
8. Paper Digest - Automated Literature Digests
Best for: Researchers wanting daily or weekly summaries of new papers in specific fields
Paper Digest uses AI to generate daily digests of new academic papers in specified research areas, helping researchers maintain current awareness. The platform monitors publication feeds and creates three-point summaries of recent papers, delivering them via email or through the web interface.
Current Awareness Automation
For researchers wanting to stay current with literature in active fields without spending hours scanning new publication lists, Paper Digest provides efficient monitoring. The brief summaries help researchers quickly identify papers worth reading in full while avoiding information overload from monitoring multiple publication venues.
This automated current awareness proves particularly valuable in fast-moving research areas where important papers appear weekly. Researchers can maintain awareness without dedicating substantial time to literature monitoring.
Limited Analysis Capabilities
However, the tool provides notification and summarization rather than deep analysis capabilities. Paper Digest lacks semantic search, patent coverage, and enterprise features needed for corporate R&D workflows. It serves academic awareness needs but cannot support comprehensive technology intelligence or competitive landscape analysis that informs strategic R&D decisions.
Corporate teams require tools that not only notify about new publications but also analyze patterns in competitive research activity, identify emerging technology threats, and integrate scientific literature with patent landscapes for complete competitive intelligence.
Paper Digest offers free and paid subscription tiers with different notification frequencies and coverage options.
9. Publish or Perish - Citation Analysis Software
Best for: Researchers analyzing publication metrics and citation patterns for bibliometric studies
Publish or Perish retrieves and analyzes academic citations from Google Scholar and other sources, calculating various citation metrics. The tool provides quick access to bibliometric data including h-index, g-index, contemporary h-index, and other publication impact measures for authors, journals, or specific papers.
Bibliometric Analysis Focus
Researchers use Publish or Perish primarily for bibliometric analysis, evaluating research impact, and identifying highly-cited papers within fields. The tool enables quick assessment of author productivity, journal influence, and paper impact without requiring institutional database subscriptions.
This proves useful for academic hiring committees evaluating candidate research impact, librarians assessing journal importance, and researchers investigating field structure through citation pattern analysis.
Limited Research Discovery
The platform focuses on citation metrics rather than content analysis or semantic search. Publish or Perish lacks AI-powered discovery capabilities, patent integration, and enterprise features. It serves academic bibliometric needs but cannot support the comprehensive technology intelligence corporate R&D teams require for strategic planning.
Corporate applications need tools that discover relevant research based on content similarity, integrate patent analysis, and provide security certifications rather than purely calculating citation metrics.
Publish or Perish is free desktop software available for Windows and Mac operating systems.
10. CORE - Open Access Research Aggregator
Best for: Researchers prioritizing open access literature and freely available papers
CORE aggregates over 200 million open access research papers from repositories and journals worldwide, providing free access to full-text papers. The platform serves researchers at institutions with limited subscriptions or those prioritizing open science principles.
Open Access Focus
The tool particularly benefits researchers at under-resourced institutions, scientists in developing countries without expensive database subscriptions, and advocates for open science who prefer freely accessible literature. CORE's focus on open access means users can download full papers without subscription barriers that often impede research at smaller institutions.
This democratization of research access aligns with growing international movements toward open science and equitable access to scientific knowledge regardless of institutional resources.
Basic Functionality
However, CORE provides basic search functionality without advanced AI capabilities, semantic understanding, or citation analysis. The platform lacks patent integration, enterprise features, and the comprehensive technology intelligence capabilities corporate R&D organizations need for competitive analysis.
CORE serves open access discovery for researchers prioritizing freely available literature but cannot support strategic technology intelligence that requires comprehensive coverage across both open and subscription content, patent analysis, and commercial technology assessment.
CORE is free for all users, supported by research grants and institutional partners.
11. PubMed - Biomedical Literature Database
Best for: Researchers focused specifically on biomedical and life sciences literature
PubMed from the National Library of Medicine provides free access to over 35 million biomedical literature citations, making it the authoritative source for medical research. The database covers medical research, life sciences, clinical studies, and related fields with comprehensive indexing through MeSH (Medical Subject Headings) terms.
Biomedical Authority
For biomedical researchers, PubMed remains the primary literature source with comprehensive coverage, authoritative indexing, and structured vocabulary that enables precise searching within medical domains. The platform's specialized focus on life sciences provides depth in its domain that general literature tools cannot match.
Medical researchers conducting systematic reviews, clinicians investigating treatment options, and pharmaceutical R&D teams researching drug mechanisms rely heavily on PubMed's comprehensive biomedical coverage and structured indexing system.
Domain-Specific Limitations
However, PubMed lacks AI-powered semantic search, provides limited coverage outside biomedical fields, and offers no patent integration. The tool serves academic biomedical research but cannot support cross-disciplinary corporate R&D needs or comprehensive technology intelligence that combines scientific literature with patent landscapes.
Corporate R&D teams in biotechnology need platforms that integrate PubMed's biomedical literature with patent analysis, materials science papers, engineering research, and regulatory intelligence for complete technology assessments.
PubMed is free for all users as a U.S. government resource managed by the National Library of Medicine.
How Corporate R&D Teams Approach Literature Review Differently Than Academics
Corporate R&D literature review requires fundamentally different tools and approaches than academic research, driven by distinct objectives and decision-making contexts.
Strategic Intelligence vs. Theoretical Foundation
Academic researchers conduct literature reviews primarily to establish theoretical foundations for new research, identify gaps in existing knowledge, and demonstrate thorough understanding of field history. The goal centers on contributing new knowledge to scientific discourse through peer-reviewed publication.
Corporate R&D teams conduct literature review for strategic technology intelligence that informs commercial decisions about product development, IP strategy, and competitive positioning. The questions driving corporate literature review focus on what competitive R&D activity threatens market position, which academic findings offer commercialization opportunities with clear patent paths, what technology readiness levels emerging approaches represent, where patents should be filed to protect innovations and block competitors, and which technical approaches face patent barriers that make commercialization infeasible.
These strategic intelligence needs require different capabilities than academic literature review tools provide.
Patent Integration as Essential Requirement
Patent integration separates academic tools from enterprise platforms in fundamental ways. Academic literature reviews focus exclusively on peer-reviewed scientific publications to establish what the research community knows about specific topics. This makes sense for PhD students writing dissertations or professors preparing grant proposals.
Corporate R&D teams cannot evaluate technology opportunities based solely on scientific literature. Understanding whether research findings have been commercialized, who holds relevant patents, and what freedom-to-operate exists proves equally important to commercial success as scientific feasibility.
Platforms that provide only scientific literature coverage leave corporate teams with incomplete intelligence requiring manual integration of patent analysis from separate tools. This fragmented approach slows decision-making, increases analysis costs, and risks missing critical patent barriers that make promising scientific approaches commercially infeasible.
Enterprise Security and Compliance Requirements
Enterprise security and compliance requirements eliminate most academic tools from corporate consideration regardless of their research capabilities. Fortune 500 companies require SOC 2 Type II certification demonstrating security controls, audit trails showing who accessed what information when, data privacy guarantees and contractual protections, service level agreements for uptime and support, integration capabilities with enterprise knowledge management systems, and formal compliance with data residency and protection regulations.
Academic tools built for individual researchers typically provide none of these enterprise features. Free platforms cannot offer SLAs, security audits, or contractual protections that corporate compliance requirements demand.
Scale of Data Coverage for Competitive Intelligence
The scale of data coverage significantly impacts competitive intelligence quality and completeness. Platforms providing access to 50-100 million papers may suffice for academic literature reviews in established fields where relevant literature concentrates in well-indexed journals.
Corporate R&D teams evaluating emerging technologies across multiple disciplines need access to 500+ million documents spanning patents, papers, technical reports, and conference proceedings to ensure comprehensive competitive analysis. Emerging technology areas require particularly broad coverage since early research may appear in diverse venues before fields coalesce around standard publication channels.
Missing even 10-20% of relevant prior art due to limited data coverage can result in costly mistakes including patent applications that fail due to unidentified prior art, technology investments in approaches already patented by competitors, or strategic decisions based on incomplete competitive intelligence.
Speed Requirements for Strategic Decisions
Academic literature reviews often unfold over months as part of multi-year research programs. PhD students might spend a semester on comprehensive literature review before beginning experimental work. This timeline aligns well with academic research cycles and publication schedules.
Corporate R&D teams make technology investment decisions on quarterly timelines where comprehensive competitive intelligence must be delivered in weeks rather than months. Platforms requiring months to train users, lacking intuitive interfaces, or providing results that require extensive manual synthesis delay strategic decisions in ways that corporate timelines cannot accommodate.
The 30-40% time savings that AI literature review tools provide compared to traditional methods becomes strategically significant when competitive intelligence deliverables determine whether companies pursue technology opportunities or market timing advantages.
Systematic Literature Review Process with AI Tools
Systematic literature review follows structured methodologies to ensure comprehensive coverage and minimize bias in identifying, evaluating, and synthesizing research evidence. AI tools in 2026 accelerate each stage while maintaining methodological rigor.
Stage 1: Protocol Development and Research Questions
Every systematic review begins with clearly defined research questions and search protocols. Researchers establish specific research questions the review will address, inclusion and exclusion criteria for paper selection, search strategies and databases to query, data extraction frameworks for consistent information gathering, and quality assessment criteria for evaluating study validity.
AI tools like Cypris can assist protocol development by analyzing existing systematic reviews in similar areas to identify standard inclusion criteria, commonly used search terms, and typical quality assessment frameworks. This accelerates protocol development while ensuring alignment with field standards.
Stage 2: Comprehensive Literature Search
Traditional systematic review searches multiple databases using carefully constructed query strings combining Boolean operators, controlled vocabulary terms, and field-specific terminology. This process typically requires librarian expertise and produces thousands of potentially relevant papers.
AI-powered platforms enable semantic search that interprets research questions in natural language rather than requiring complex Boolean query construction. Instead of crafting "(battery OR energy storage) AND (lithium OR sodium) AND (electrolyte OR separator) AND (solid state OR polymer)", researchers can simply ask "What are the most promising solid electrolyte materials for rechargeable batteries?"
The AI system interprets this question, searches millions of papers using semantic understanding rather than literal keyword matching, and ranks results by relevance to the specific research question. This reduces the skill barrier for comprehensive literature search while often improving recall compared to Boolean query approaches that miss papers using unexpected terminology.
Stage 3: Title and Abstract Screening
Initial screening involves reviewing titles and abstracts to eliminate obviously irrelevant papers before full-text review. For systematic reviews identifying thousands of potentially relevant papers, this screening stage requires substantial time.
AI screening tools can achieve 85%+ accuracy in identifying relevant papers according to defined inclusion criteria, as demonstrated in 2024 research on clinical systematic reviews. Corporate R&D teams report reducing initial screening time by 60-70% using AI-assisted screening while maintaining or improving screening quality through consistent application of inclusion criteria.
The key advantage involves consistent application of criteria. Human reviewers experience fatigue, interpret criteria differently, and make inconsistent decisions across thousands of papers. AI systems apply criteria uniformly across all candidates, though human oversight remains essential for final decisions on borderline cases.
Stage 4: Full-Text Review and Data Extraction
Papers passing initial screening require full-text review and systematic data extraction. Reviewers extract specific information according to predefined frameworks, such as patient populations, interventions, comparators, outcomes, and results for clinical reviews using the PICO framework.
AI tools can automate data extraction by identifying specific information types within full-text papers. Systems trained on scientific literature can locate methodology sections, extract statistical results, identify study limitations, and populate data extraction templates automatically. Research shows LLMs like GPT-4 and Claude achieve over 85% accuracy in extracting structured information from clinical papers.
This automation saves substantial time while enabling extraction consistency across hundreds of papers. Manual extraction requires human reviewers to consistently interpret and categorize information across diverse paper formats and writing styles. AI extraction applies uniform interpretation rules across all papers.
Stage 5: Quality Assessment and Bias Evaluation
Systematic reviews typically assess included study quality using domain-specific frameworks evaluating methodology rigor, potential biases, and result reliability. This requires expert judgment about study design appropriateness, statistical analysis validity, and potential confounding factors.
AI tools can assist quality assessment by identifying common bias indicators like inadequate randomization, missing baseline characteristics, selective outcome reporting, or inappropriate statistical methods. Systems trained on quality assessment frameworks can flag potential issues for human expert review rather than requiring experts to manually screen all studies for every quality criterion.
Stage 6: Synthesis and Meta-Analysis
The final systematic review stage synthesizes findings across included studies, identifies patterns, resolves contradictions, and draws conclusions about what the evidence base shows. For quantitative reviews, this includes meta-analysis combining statistical results across studies.
AI platforms excel at synthesis by analyzing hundreds of papers simultaneously to identify common findings, contradictory results, methodology patterns, and knowledge gaps. Tools like Cypris can generate synthesis reports highlighting consensus findings that most studies support, controversial results where studies reach contradictory conclusions, methodology trends showing which approaches researchers favor, temporal patterns in how findings evolved as research progressed, and geographic patterns in which research groups pursue which approaches.
Frequently Asked Questions About AI Literature Review Tools
How accurate are AI literature review tools compared to manual review?
AI literature review tools achieve 75-90% accuracy rates for most tasks, with performance varying significantly by specific application and paper domain. Screening accuracy for identifying relevant papers from larger sets reaches 85%+ for well-defined inclusion criteria in established research domains. Data extraction accuracy varies from 70% for complex qualitative information to 90%+ for structured quantitative data like statistical results.
The key insight is that AI tools augment rather than replace human expertise. Most effective workflows combine AI screening to efficiently filter large paper sets with human expert review for final decisions. This hybrid approach maintains review quality while achieving 30-40% time savings compared to purely manual processes.
Can AI tools conduct complete literature reviews without human involvement?
No, current AI tools cannot conduct complete literature reviews meeting academic standards without substantial human oversight and expertise. AI excels at specific subtasks including paper discovery, relevance screening, data extraction, and pattern identification. However, humans remain essential for defining appropriate research questions and inclusion criteria, evaluating study quality and methodology appropriateness, interpreting contradictory findings and resolving inconsistencies, assessing bias and limitations not obvious from paper text, drawing nuanced conclusions that require domain expertise, and writing synthesis narratives that communicate findings appropriately.
The most effective approach treats AI as a powerful research assistant that handles time-intensive mechanical tasks while human experts provide judgment, interpretation, and synthesis.
Do I need technical expertise to use AI literature review tools?
Most modern AI literature review platforms require no technical expertise, offering interfaces designed for researchers without programming or machine learning knowledge. Tools like Semantic Scholar, Research Rabbit, and Cypris provide point-and-click interfaces where users interact through web browsers using natural language queries.
Some advanced features like custom AI model training, API integration, or automated systematic review pipelines may require technical expertise. However, core functionality including semantic search, paper discovery, and basic analysis works through intuitive interfaces accessible to any researcher comfortable with web applications.
How do AI literature review tools handle papers behind paywalls?
AI literature review tools vary substantially in their ability to access full-text papers behind subscription paywalls. Free platforms like Semantic Scholar and CORE typically access only openly available papers including open access publications, preprints, and author-uploaded versions. These tools can search metadata like titles, abstracts, authors, and citations for all papers but provide full-text access only for openly available content.
Enterprise platforms like Cypris often integrate with institutional subscriptions, enabling full-text access for papers where the organization holds subscription rights. Corporate R&D teams working with enterprise platforms can typically access papers through their existing institutional subscriptions integrated with the platform.
For papers without access, most tools provide sufficient metadata to identify relevant papers, which researchers can then access through institutional library services, interlibrary loan, or direct author requests.
What's the difference between AI literature review tools and general AI like ChatGPT?
AI literature review tools are specialized systems trained specifically for scientific paper analysis, with access to dedicated scientific literature databases. General AI assistants like ChatGPT or Claude are trained on broad internet content and lack direct database access to scientific papers. Key differences include data access where literature review tools search millions of papers in real-time while general AI relies on training data with knowledge cutoffs and cannot access current papers or search scientific databases.
Citation accuracy differs substantially, with specialized tools citing specific papers with verifiable DOIs, page numbers, and exact quotes while general AI sometimes generates plausible-sounding but fabricated citations through hallucinations. Scientific understanding is stronger in tools trained on scientific literature that understand research methodology terminology, statistical concepts, and field-specific conventions better than general AI trained primarily on web content.
Systematic features available in literature review tools include citation network analysis, structured data extraction, and systematic review workflows that general AI cannot replicate.
For serious research applications, specialized literature review tools substantially outperform general AI assistants in accuracy, citation reliability, and comprehensive coverage.
Can AI tools find papers that traditional keyword search misses?
Yes, semantic search capabilities in modern AI tools identify relevant papers that keyword search misses entirely, often improving recall by 20-30% compared to traditional Boolean queries. This happens because researchers describe the same concepts using different terminology across papers, disciplines, and time periods. Keyword search finds only papers using exact searched terms while semantic search understands that "machine learning bias," "algorithmic fairness," and "model discrimination" refer to related concepts and surfaces papers regardless of specific terminology used.
Conceptual similarity means papers may be relevant through shared concepts without using any common keywords. A paper about "neural network robustness to adversarial perturbations" and another about "deep learning model vulnerability to malicious inputs" discuss related ideas without keyword overlap. Semantic AI recognizes the conceptual similarity.
Cross-disciplinary discovery finds important methods or findings that may appear in unexpected disciplines using completely different terminology. A materials scientist might benefit from biological papers about membrane transport or physics papers about diffusion, but would never find them through keyword search. AI trained across disciplines recognizes conceptual applicability across fields.
What happens to my research data when using cloud-based AI tools?
Data privacy and security vary dramatically across AI literature review platforms. Free academic tools typically include terms of service allowing broad data usage rights, with uploaded papers and search queries potentially used to improve AI models or included in aggregated research about platform usage.
Enterprise platforms like Cypris provide contractual data protection guarantees, ensuring that proprietary research queries, uploaded documents, and analysis results remain confidential. SOC 2 Type II certification requires platforms to implement security controls protecting customer data from unauthorized access, modification, or disclosure.
Corporate R&D teams should carefully evaluate platform privacy policies, security certifications, and data residency before using tools for proprietary research. Important questions include where data is physically stored since geographic location matters for data protection regulations, who can access customer research queries and uploaded documents, whether customer data is used to train AI models accessible to other users, what contractual protections exist against data disclosure, and whether independent security audits verify claims.
Free tools appropriate for academic research may be inappropriate for corporate applications involving proprietary technology intelligence.
How do AI tools handle papers in languages other than English?
Multilingual capabilities vary significantly across platforms. Most AI literature review tools train primarily on English scientific literature, with varying support for other languages. Common patterns include major scientific languages where tools generally handle papers in Chinese, Spanish, German, French, and Japanese reasonably well, though often translating content to English for analysis rather than truly understanding non-English papers natively.
Metadata availability means most platforms can search papers in any language by title, author, and keywords if this metadata exists in databases. Full-text analysis capabilities for non-English papers remain more limited. Translation integration in some platforms uses machine translation to analyze non-English papers, though translation quality varies and technical terminology may not translate accurately across domains.
For primarily English-language research, language limitations rarely matter. For researchers needing comprehensive coverage of Chinese, Japanese, or other non-English literature, platform language capabilities become selection criteria requiring evaluation.
What citation formats do AI literature review tools support?
Most AI literature review tools support standard academic citation formats including APA, MLA, Chicago, IEEE, and Vancouver styles. Platforms typically generate properly formatted citations automatically from paper metadata, eliminating manual citation formatting work.
Many tools integrate with reference management software like Zotero, Mendeley, or EndNote, enabling researchers to export discovered papers directly to preferred citation management systems. This integration proves particularly valuable for researchers managing large reference libraries across multiple projects.
For corporate technical reports, platforms often support custom citation styles matching specific organization requirements. Enterprise tools like Cypris typically accommodate custom citation formatting for internal documentation standards.
How often do AI literature review tools update their paper databases?
Update frequency varies by platform and content type. Leading platforms typically update databases with new papers daily or weekly, though timing depends on publication sources and indexing processes. Preprint servers see papers appearing on arXiv, bioRxiv, or other preprint servers typically appear in tools within 24-48 hours of posting, making preprints the fastest-available content.
Journal articles appear as publishers make them available to indexing services, typically within days to weeks of publication. Retroactive additions happen as databases continuously add older papers when publishers digitize archives or make previously un-indexed content available. This means comprehensive coverage improves over time even for historical literature.
Patent databases update as patent offices publish applications and issue grants, typically within weeks of official publication.
For current awareness applications, researchers should verify platform update frequency matches their needs. Some research domains move so quickly that weekly updates lag too far behind the literature front.
Choosing the Right AI Literature Review Tool: Decision Framework
Selecting appropriate AI literature review tools depends entirely on your specific use case, organizational context, and workflow requirements. This framework guides tool selection.
For Academic PhD Students and Researchers
Academic researchers conducting literature reviews for dissertations, grant proposals, or peer review are well-served by free academic tools. Recommended combinations include Semantic Scholar for broad paper discovery across disciplines with AI-powered search, Research Rabbit for building reference collections through citation networks, Connected Papers for visualizing research field structure and identifying seminal papers, and PubMed for biomedical and life sciences literature with authoritative indexing.
This free tool combination provides adequate coverage for academic literature reviews, though researchers sacrifice advanced AI features, enterprise integration, and patent analysis available in commercial platforms.
For Individual Researchers Exploring New Fields
Researchers entering unfamiliar research domains benefit from visualization and discovery tools that reveal field structure. Connected Papers or Litmaps help map research landscapes through citation networks. Semantic Scholar provides AI-powered discovery of foundational papers. Iris.ai enables cross-disciplinary discovery when investigating applications beyond your primary field.
These tools excel at helping researchers quickly understand new research areas, identify key papers and influential authors, and grasp field history without deep prior knowledge.
For Corporate R&D Teams Conducting Competitive Intelligence
Corporate R&D teams conducting competitive technology intelligence require enterprise platforms combining multiple capabilities.
Cypris emerges as the clear choice for corporate applications because it uniquely provides unified access to 500+ million patents and papers eliminating need for separate patent and literature tools, semantic search understanding technology concepts across both scientific and patent literature, enterprise security with SOC 2 Type II certification meeting Fortune 500 compliance requirements, multimodal search processing diagrams, structures, and specifications alongside text, integration with corporate knowledge management systems, and proprietary R&D ontology enabling semantic understanding across domains.
The platform difference for corporate teams is substantial. Academic tools provide paper discovery. Enterprise platforms provide technology intelligence combining scientific research with patent landscapes, competitive monitoring, and commercial technology assessment that inform strategic R&D decisions worth millions in R&D investment.
For Systematic Review Teams in Healthcare and Evidence Synthesis
Healthcare researchers conducting systematic reviews and meta-analyses need PubMed as primary source for biomedical literature, specialized systematic review software for protocol management and quality assessment, and AI screening tools to accelerate title and abstract screening while maintaining accuracy.
Healthcare systematic reviews follow established methodological standards like PRISMA and Cochrane requiring specialized tool support that general literature review platforms may not provide.
For High-Volume Screening Applications
Researchers processing hundreds or thousands of papers for relevance screening benefit from Scholarcy for generating structured summaries during initial screening, Paper Digest for automated monitoring of new publications in active research areas, and AI screening features in platforms like Cypris that automate relevance assessment.
High-volume screening applications prioritize efficiency while maintaining accuracy through AI automation of repetitive decision-making about paper relevance.
The Future of AI-Powered Scientific Literature Review
AI literature review capabilities will continue advancing rapidly through 2026 and beyond, with several clear trends emerging.
Multimodal Understanding Beyond Text
Future AI systems will understand scientific information expressed in diverse formats including technical diagrams, chemical structures, mathematical equations, data visualizations, and experimental images. Current tools primarily analyze text, with limited ability to interpret visual information that often conveys crucial scientific details.
Advanced multimodal AI will process figures showing experimental setups, interpret chemical reaction schemes, analyze data plots, and understand technical drawings at human expert levels. This will enable discovery of relevant prior art based on visual similarity even when text descriptions differ substantially.
Real-Time Research Tracking and Alerts
AI systems will monitor research activity in real-time, alerting corporate R&D teams immediately when competitors publish papers, file patents, or present conference talks in strategic technology areas. Current tools primarily support retrospective analysis rather than forward-looking competitive monitoring.
Real-time intelligence enables proactive rather than reactive R&D strategy. Companies will detect competitive threats earlier, identify commercialization opportunities faster, and make technology investment decisions with more current intelligence.
Integration with Laboratory Information Systems
Enterprise platforms will integrate directly with laboratory information management systems, electronic lab notebooks, and R&D project management tools. This integration will enable AI to contextualize literature findings against internal research data, suggesting relevant papers based on current experimental results rather than requiring explicit queries.
Imagine an AI assistant that monitors your laboratory results, automatically identifies related scientific literature, flags relevant patents that might impact your work, and alerts you to competitive research activity in your technology area, all without manual queries. This represents the next evolution beyond query-based search.
Automated Hypothesis Generation
Advanced AI will synthesize knowledge across massive literature corpuses to generate novel research hypotheses, identify unexplored combinations of existing approaches, and suggest experiments addressing knowledge gaps. Rather than purely searching existing knowledge, AI will help researchers identify what questions to ask next.
This represents a fundamental shift from AI as research assistant to AI as research collaborator suggesting creative directions that human researchers might not conceive independently.
Personalized Research Assistants
AI literature review assistants will learn individual researcher preferences, areas of expertise, and research goals to provide increasingly personalized results over time. Systems will understand which types of papers you find most relevant, which methodologies you prefer, and which research questions interest you, tailoring recommendations accordingly.
This personalization will make AI tools feel less like generic search engines and more like knowledgeable colleagues who understand your research program and scientific interests at deep levels.
Conclusion: AI Literature Review as Essential R&D Infrastructure in 2026
AI has fundamentally transformed scientific literature review in 2026, making comprehensive analysis of research landscapes accessible in hours rather than months. With over 5.14 million academic papers published annually and growth rates showing no signs of slowing, AI-powered literature analysis has transitioned from convenient enhancement to essential infrastructure for serious research.
The tool landscape has fragmented between free academic platforms serving student researchers and thesis development, and enterprise R&D intelligence platforms serving corporate strategic decision-making. This fragmentation reflects fundamentally different use cases and requirements rather than simple feature differences.
For academic researchers, free tools like Semantic Scholar, Research Rabbit, and domain-specific databases like PubMed provide adequate coverage for literature reviews supporting scholarly publication and grant proposals. These platforms enable comprehensive paper discovery, citation network analysis, and reference collection at no cost, making them appropriate for academic workflows where time horizons extend across semesters or years.
For corporate R&D teams, the requirements differ substantially. Academic literature tools provide paper discovery. Enterprise platforms provide technology intelligence combining scientific research with patent landscapes, competitive monitoring, and commercial technology assessments that inform strategic decisions about which technologies to commercialize, where to invest R&D resources, and how to position products competitively.
The most sophisticated AI literature review tools in 2026 don't just search papers. They provide comprehensive technology intelligence that connects academic research to commercial applications, patent landscapes to scientific breakthroughs, and competitive activity to emerging opportunities. This comprehensive approach has become essential infrastructure for corporate R&D organizations maintaining competitive advantage in rapidly evolving technology markets.
Platforms like Cypris that combine over 500 million patents and papers with semantic search understanding, multimodal analysis capabilities, and enterprise security provide the comprehensive intelligence Fortune 500 R&D teams require. The value proposition centers not on finding individual papers but on synthesizing complete competitive landscapes that inform strategic technology investments, IP strategy decisions, and market positioning.
As scientific publication volumes continue growing and technology development cycles accelerate, the gap between academic literature tools and enterprise R&D intelligence platforms will likely widen further. Organizations serious about technology leadership will increasingly recognize that comprehensive R&D intelligence infrastructure provides competitive advantages measured in time-to-market improvements, patent strategy optimization, and strategic investment accuracy worth far more than tool costs.
The era of manual literature review has ended for serious R&D applications. AI-powered intelligence platforms now represent essential infrastructure for corporate innovation, much as computational tools became essential for engineering design in previous generations. Organizations failing to adopt comprehensive R&D intelligence infrastructure risk falling behind competitors who leverage AI to accelerate innovation cycles, identify opportunities earlier, and make technology decisions based on more complete competitive intelligence.

%20-%20Slaughterhouse%20Wastewater%20Treatment%20Market%20-%20%5B1%5D.png)
%20-%20Sustainable%20Packaging%20in%20Food%20%26%20Beverage.png)
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)