
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
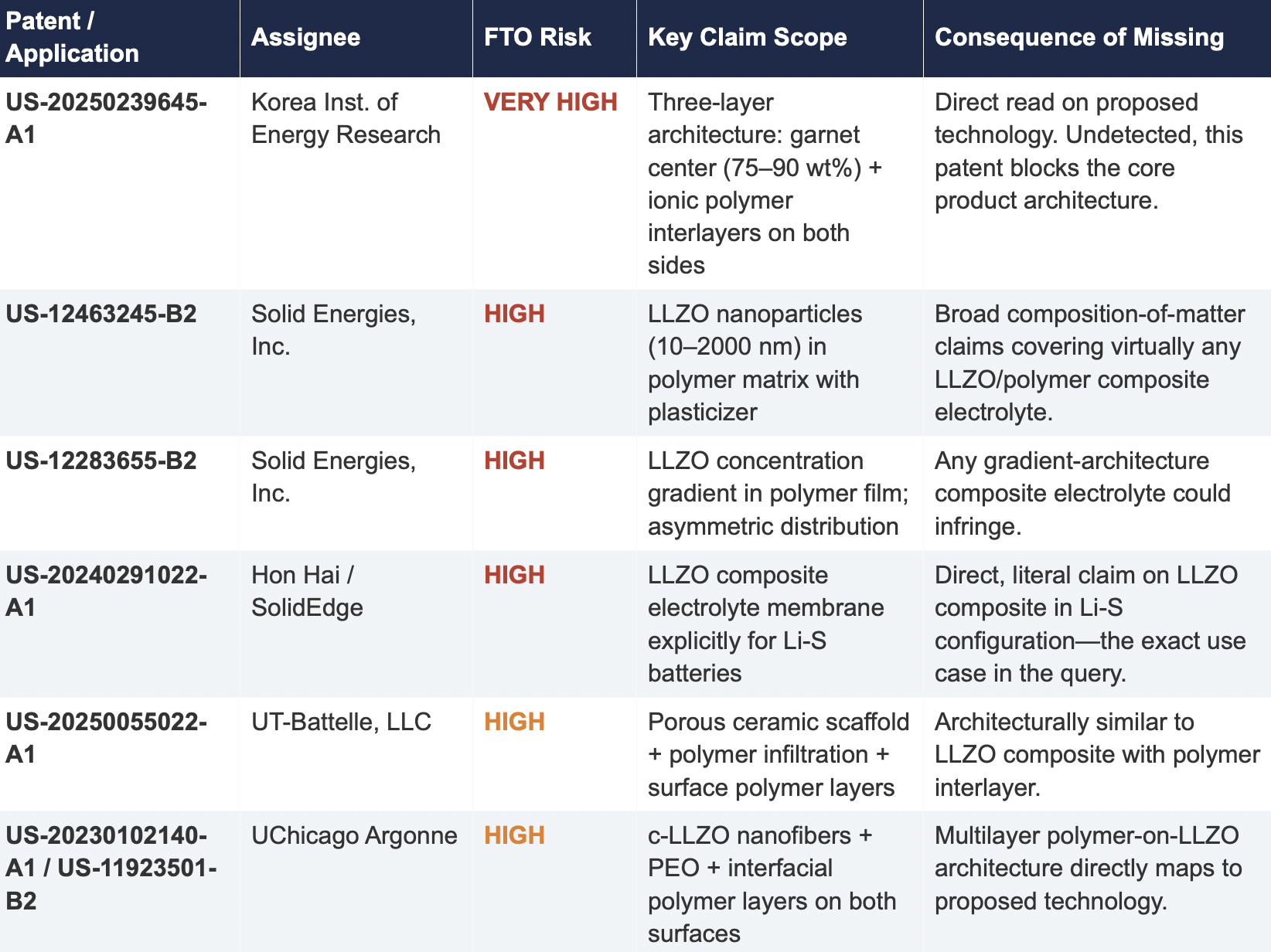
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
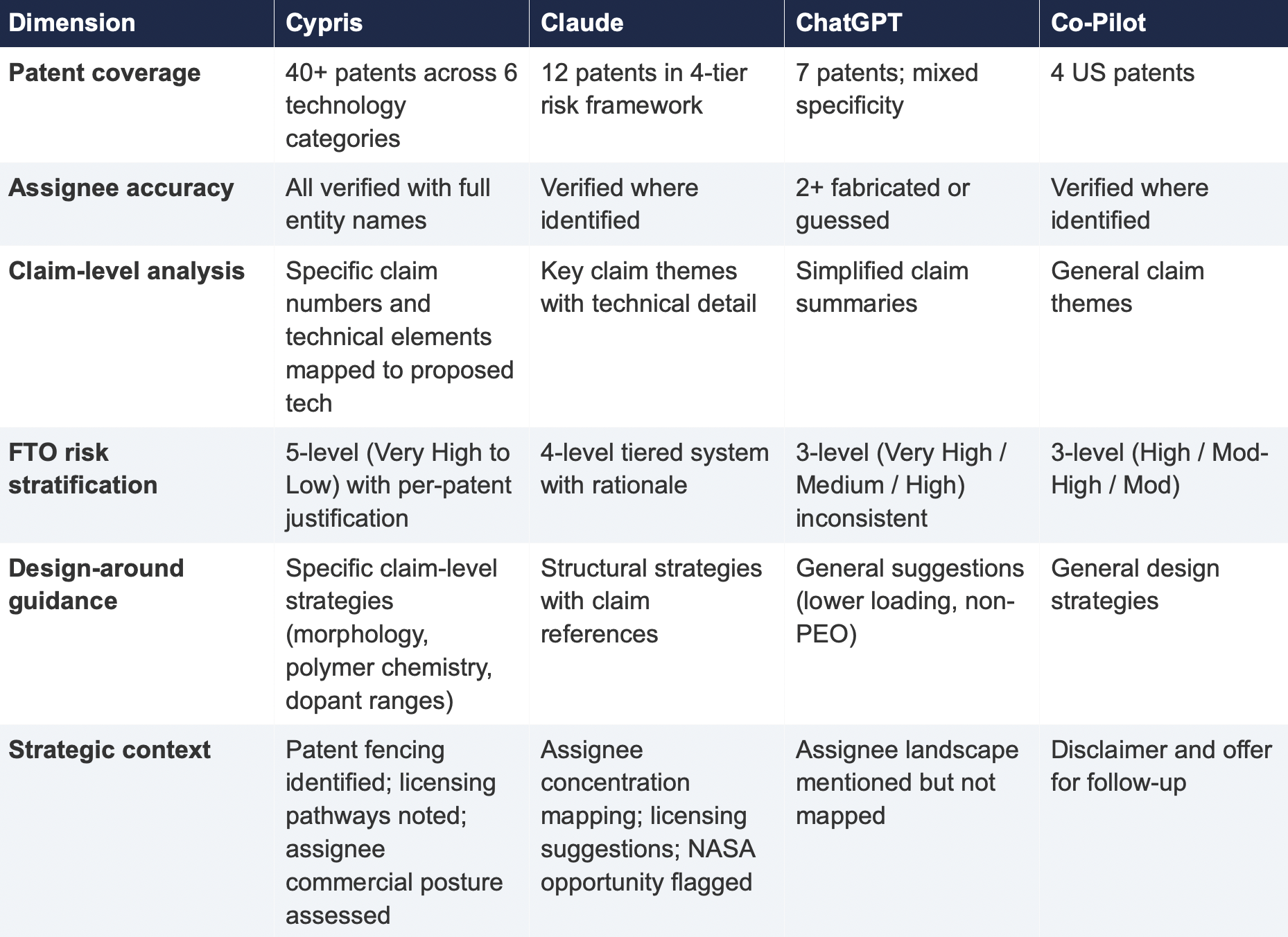
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

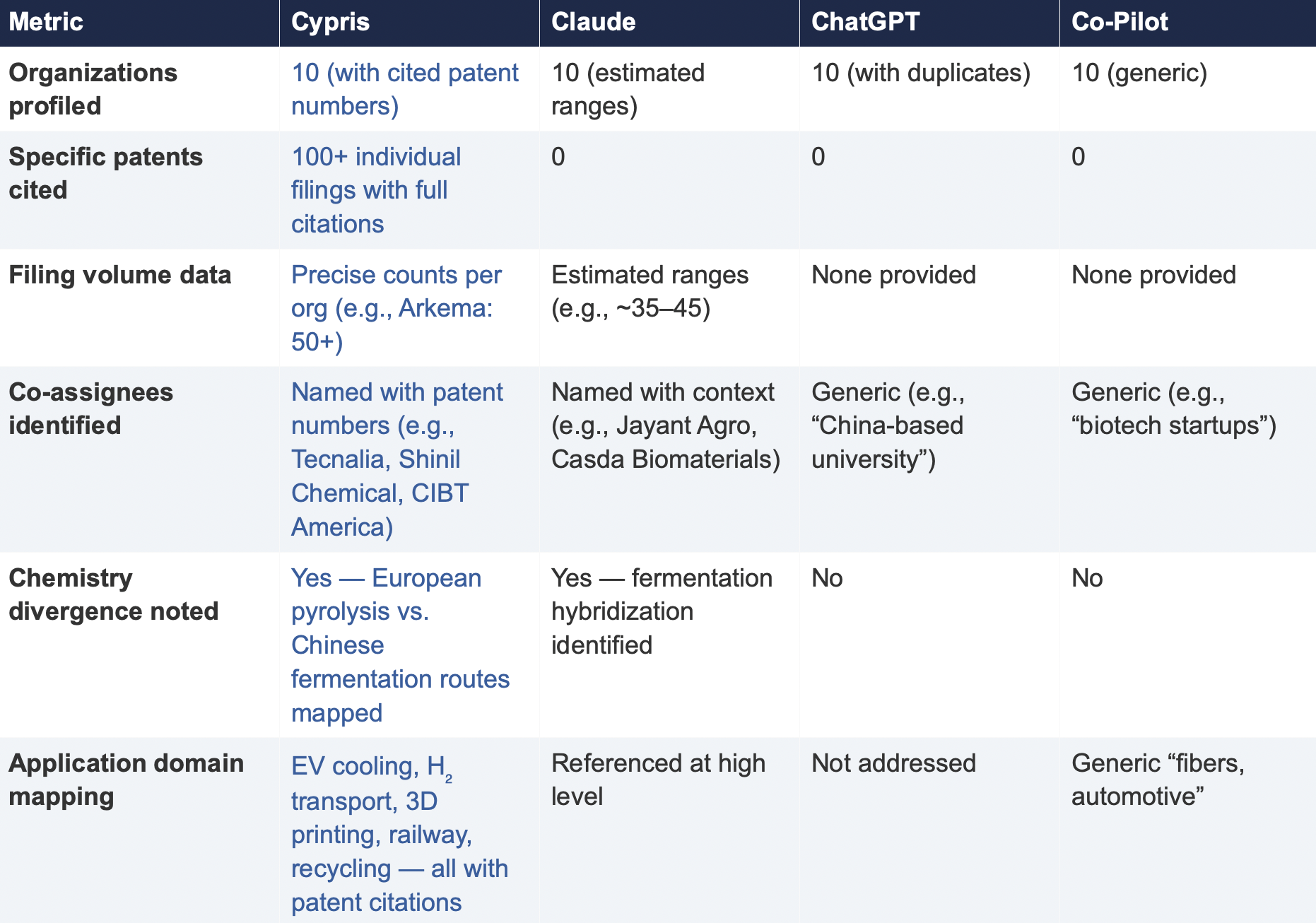
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

Top 8 Tech Scouting Platforms for Enterprise R&D Teams in 2026
Technology scouting platforms have become essential infrastructure for enterprise R&D teams seeking to identify emerging technologies, monitor competitive innovation landscapes, and discover partnership opportunities before competitors. A tech scouting platform is software that aggregates patent databases, scientific literature, startup information, and market intelligence to help R&D professionals systematically discover technologies relevant to their strategic priorities. The best tech scouting platforms combine comprehensive data coverage with AI-powered search capabilities that surface relevant innovations across technical domains.
Enterprise R&D teams face a fundamental challenge when evaluating tech scouting software. Most platforms in this category evolved from either startup databases designed for corporate venture capital teams or innovation management systems built for idea collection workflows. Neither origin serves the core technical scouting needs of R&D professionals who must understand the scientific foundations of emerging technologies, track patent landscapes across global jurisdictions, and identify technical capabilities that align with product development roadmaps. The platforms reviewed here represent the leading options available in 2025, evaluated specifically for their ability to support technical scouting workflows within enterprise R&D organizations.
Why Tech Scouting Has Become a Core R&D Function
The economics of industrial R&D have shifted fundamentally over the past two decades. Internal research laboratories once served as the primary source of breakthrough innovations for large corporations, but the distributed nature of modern scientific progress has made external technology acquisition essential for maintaining competitive position. Universities, government laboratories, startups, and competitors now generate innovations relevant to virtually every corporate R&D agenda, creating both opportunity and complexity for technology leaders.
Tech scouting addresses this complexity by systematizing the discovery process. Rather than relying on conference attendance, personal networks, and serendipitous discovery, R&D teams using tech scouting platforms can continuously monitor the global innovation landscape for developments relevant to their strategic priorities. The most effective tech scouting programs identify potential technologies years before they reach commercial maturity, providing time to evaluate technical fit, establish partnerships, or develop internal capabilities.
The challenge lies in signal extraction. Global patent offices publish millions of new applications annually. Scientific journals add millions of peer-reviewed papers to the literature each year. Thousands of technology startups launch and seek partnerships with established enterprises. Without systematic approaches to filtering this volume, R&D teams either miss relevant innovations or waste resources chasing technologies that prove irrelevant to their actual needs.
The Three Layers of Effective Tech Scouting
Mature tech scouting programs operate across three distinct layers, each requiring different data sources, analytical approaches, and organizational capabilities.
The first layer focuses on horizon scanning, the broad monitoring of scientific and technical developments across domains relevant to the organization's long-term strategy. Horizon scanning identifies emerging research directions that may yield breakthrough technologies in five to fifteen years. This layer relies heavily on scientific literature analysis, tracking publication patterns, citation networks, and funding flows that signal where research communities are concentrating attention. Effective horizon scanning reveals technological possibilities before they attract widespread commercial interest.
The second layer addresses landscape mapping, the detailed analysis of specific technology areas where the organization has active strategic interest. Landscape mapping produces comprehensive views of who is working on relevant technologies, what approaches they are pursuing, how intellectual property is distributed, and where technical bottlenecks remain unsolved. This layer combines patent analysis with scientific literature review and startup monitoring to construct actionable intelligence about competitive dynamics within defined technology domains.
The third layer involves target identification, the specific discovery of technologies, companies, or research groups that merit direct engagement. Target identification converts landscape intelligence into actionable opportunities, whether potential licensing deals, partnership discussions, acquisition targets, or research collaborations. This layer requires the most refined filtering, identifying not just relevant technologies but specifically those with sufficient maturity, strategic fit, and accessibility to warrant investment of relationship-building resources.
Most tech scouting platforms support some combination of these layers, but few handle all three with equal capability. Platforms originating from startup databases excel at target identification for company partnerships but lack depth for horizon scanning in scientific literature. Platforms built around patent analytics provide strong landscape mapping but may miss early-stage research that has not yet generated intellectual property filings. Understanding which layers matter most for your organization's scouting objectives helps guide platform selection.
Common Tech Scouting Mistakes and How to Avoid Them
Even well-resourced R&D organizations make predictable mistakes when establishing tech scouting capabilities. Recognizing these patterns helps teams avoid common pitfalls and accelerate time to value from scouting investments.
The keyword trap represents the most pervasive tech scouting failure mode. Teams define search queries using terminology familiar within their organization, then wonder why results miss obviously relevant technologies. The problem stems from terminology variation across industries, geographies, and research traditions. A pharmaceutical company searching for drug delivery innovations may miss relevant patents filed by materials science companies using polymer chemistry terminology. An automotive team scouting battery technologies may overlook academic research published using electrochemistry nomenclature unfamiliar to automotive engineers. Escaping the keyword trap requires either exhaustive synonym mapping, which proves impractical at scale, or semantic search capabilities powered by technical ontologies that understand conceptual relationships across terminology boundaries.
Recency bias causes tech scouting programs to overweight recent developments while undervaluing foundational patents and seminal research that shape entire technology domains. The most commercially relevant technologies often build on intellectual property filed years or decades earlier. Scouting programs that focus exclusively on recent activity may identify derivative innovations while missing the foundational technologies that control freedom to operate. Effective tech scouting balances monitoring of new developments with periodic landscape reviews that map historical intellectual property positions.
The startup fixation leads R&D teams to equate tech scouting with startup scouting, missing technologies developed within universities, government laboratories, and established corporations. Startups represent only one commercialization pathway for new technologies. Many breakthrough innovations transfer through licensing agreements with universities, joint development partnerships with research institutions, or acquisition of intellectual property from corporations exiting technology areas. Tech scouting programs that rely exclusively on startup databases systematically miss these alternative pathways.
Scouting without synthesis produces information without insight. Teams generate extensive lists of potentially relevant technologies but fail to synthesize findings into strategic recommendations that inform R&D investment decisions. The most valuable tech scouting programs connect discovery activities to decision-making processes, translating landscape intelligence into specific recommendations about where to build internal capabilities, where to seek external partnerships, and where to avoid investment due to competitive dynamics or intellectual property constraints.
Building a Tech Scouting Workflow That Delivers Results
Effective tech scouting requires more than platform access. Organizations that extract consistent value from scouting investments build workflows that connect discovery activities to strategic decision-making and R&D execution.
Start with strategic alignment before platform configuration. Tech scouting produces value only when focused on questions that matter for organizational strategy. Before defining searches or configuring alerts, identify the specific strategic uncertainties that scouting should address. Which technology areas could disrupt current product lines? Where do capability gaps limit pursuit of attractive market opportunities? What adjacent domains might enable diversification into new markets? These strategic questions should drive scouting priorities rather than allowing platform capabilities to define scope.
Design scouting cadences that match technology maturity timelines. Horizon scanning for early-stage research requires different rhythms than landscape monitoring in fast-moving commercial domains. Academic research in fundamental science may warrant quarterly reviews, while competitive patent filings in active technology races may require weekly monitoring. Match monitoring frequency to the pace of relevant developments rather than applying uniform cadences across all scouting activities.
Establish clear handoff processes between scouting and evaluation. Discovery identifies candidates; evaluation determines fit. These functions require different expertise and often involve different organizational stakeholders. Define explicit criteria for when scouted technologies advance to detailed evaluation, who conducts technical assessment, and how evaluation findings feed back into scouting priorities. Without clear handoffs, promising discoveries languish without action while scouting teams continue generating new candidates that similarly stall.
Create feedback loops that improve scouting precision over time. Track which scouted technologies advance through evaluation to partnership discussions or internal development. Analyze patterns in technologies that prove relevant versus those that fail evaluation. Use these patterns to refine search strategies, adjust filtering criteria, and improve the ratio of actionable discoveries to noise. Tech scouting capabilities compound over time when organizations systematically learn from results.
Integrate scouting insights into existing R&D planning processes. Technology intelligence proves most valuable when it informs resource allocation decisions, shapes research priorities, and influences build-versus-partner choices during strategic planning cycles. Identify the specific planning processes where scouting insights should contribute and establish mechanisms for delivering relevant intelligence at decision points. Scouting programs disconnected from planning processes generate reports that inform no decisions.
Measuring Tech Scouting Effectiveness
Quantifying the value of tech scouting proves challenging because the function operates upstream of commercial outcomes. However, several metrics help organizations assess whether scouting investments generate appropriate returns.
Discovery-to-engagement conversion rate measures what percentage of scouted technologies advance to active engagement, whether partnership discussions, licensing negotiations, or detailed technical evaluation. Low conversion rates may indicate poor alignment between scouting priorities and strategic needs, overly broad discovery criteria that generate excessive noise, or bottlenecks in evaluation processes that prevent action on promising candidates. Tracking this metric over time reveals whether scouting precision improves as teams refine approaches.
Time-to-discovery measures how quickly tech scouting identifies technologies that ultimately prove strategically relevant. Organizations can assess this retrospectively by examining technologies that reached partnership or development stages and determining when scouting first surfaced them. Shorter time-to-discovery indicates effective horizon scanning that identifies opportunities before competitors, while longer timelines suggest scouting programs react to visible trends rather than anticipating emerging developments.
Coverage completeness assesses whether tech scouting captures the full landscape of relevant developments or systematically misses certain categories. Organizations can evaluate coverage by comparing scouted technologies against those identified through other channels, such as inbound partnership inquiries, conference presentations, or competitive intelligence. Gaps in coverage reveal blind spots in scouting methodology, data sources, or search strategies that warrant correction.
Strategic influence measures the degree to which scouting insights actually inform R&D decisions. This qualitative assessment examines whether technology intelligence shapes research priorities, influences partnership strategies, or affects resource allocation during planning processes. Scouting programs that generate extensive reports but rarely influence decisions warrant redesign regardless of discovery volume or quality.
When to Use Different Data Sources
Tech scouting platforms vary significantly in the data sources they aggregate, and understanding the strengths of different source types helps organizations extract maximum value from available intelligence.
Patent databases provide the most comprehensive record of technologies with commercial intent. Patent filings reveal not just what organizations are developing but what they consider sufficiently valuable to protect through intellectual property rights. Patent analysis supports competitive intelligence, freedom-to-operate assessment, and identification of potential licensing or acquisition targets. However, patents lag actual development by eighteen months or more due to publication delays, and not all valuable technologies generate patent filings. Organizations in certain industries rely on trade secrets rather than patents to protect innovations.
Scientific literature offers earlier visibility into emerging technologies than patent databases, often surfacing research directions years before commercial development begins. Publication analysis reveals where research communities are concentrating effort, which approaches show promising results, and who is generating breakthrough findings. For horizon scanning focused on technologies beyond the current development pipeline, scientific literature provides essential early warning capability. However, academic publications may describe approaches that prove commercially impractical or face insurmountable scaling challenges.
Startup databases capture technologies that have attracted entrepreneurial attention and venture investment, providing signals about which innovations the market considers commercially viable. Startup data supports identification of potential partnership targets and acquisition candidates while revealing competitive threats from emerging players. However, startup databases cover only one commercialization pathway and may miss technologies developed within universities, government labs, or established corporations.
Funding and grant databases reveal where governments and research institutions are directing resources, providing signals about technology areas receiving concentrated investment. Grant data proves particularly valuable for horizon scanning in domains where public funding drives research agendas, such as life sciences, energy, and defense-adjacent technologies.
Market intelligence sources provide context about commercial dynamics, customer needs, and industry trends that help evaluate strategic relevance of scouted technologies. Market data helps distinguish technically interesting innovations from those addressing genuine commercial opportunities.
The most effective tech scouting programs combine multiple source types, using scientific literature for early horizon scanning, patents for landscape mapping and competitive intelligence, and startup databases for partnership target identification. Platforms that aggregate diverse sources into unified search environments simplify this multi-source approach.
1. Cypris
Cypris stands as the most comprehensive tech scouting platform purpose-built for enterprise R&D teams conducting technical scouting at scale. The platform aggregates over 500 million patents and scientific papers into a unified search environment, providing R&D professionals with the deepest technical intelligence coverage available in any single platform. What distinguishes Cypris from competitors in the tech scouting category is its proprietary R&D ontology, an AI-powered semantic layer that understands technical concepts and relationships across scientific domains rather than relying solely on keyword matching.
The Cypris R&D ontology transforms technical scouting by enabling semantic search that recognizes when different terminology describes the same underlying technology. An R&D team searching for innovations in battery chemistry will surface relevant patents and papers regardless of whether they use terms like solid-state electrolyte, lithium-ion cathode materials, or energy storage compounds. This ontology-driven approach addresses the fundamental limitation of traditional patent search tools, which require users to anticipate every possible term variation and miss relevant results when terminology differs across industries, geographies, or research traditions.
For technical scouting specifically, Cypris provides capabilities that general-purpose innovation platforms cannot match. The platform combines patent intelligence with scientific literature analysis, allowing R&D teams to trace technologies from early-stage academic research through patent protection and commercial development. This longitudinal view proves essential for technical scouts who need to understand not just what technologies exist today but which emerging research directions may yield breakthrough innovations in three to five years.
Cypris has established official API partnerships with OpenAI, Anthropic, and Google, positioning the platform as foundational R&D intelligence infrastructure for organizations building AI-powered research workflows. These partnerships reflect the platform's technical architecture, which emphasizes structured data accessibility and integration capabilities that enterprise R&D technology stacks require. Enterprise customers including Johnson & Johnson, Honda, Yamaha, and Philip Morris International rely on Cypris for technical scouting across pharmaceutical research, automotive innovation, and consumer product development.
The platform maintains SOC 2 Type II certification and operates entirely within the United States, addressing compliance requirements that enterprise R&D teams face when handling sensitive competitive intelligence. For organizations where technical scouting involves proprietary research directions or pre-patent innovations, Cypris provides the security infrastructure necessary for enterprise deployment.
2. Wellspring Worldwide
Wellspring offers a tech scouting platform called Scout that provides access to over 400 million records spanning patents, publications, startups, and research grants. The platform emphasizes discovery of external innovation partners and includes tools for tracking relationships with universities and research institutions. Wellspring serves technology transfer offices and corporate innovation teams seeking to identify licensing opportunities and research collaborations. The platform includes visualization tools for analyzing technology landscapes and portfolio management features for tracking scouting activities through evaluation stages.
3. Traction Technology
Traction Technology provides a tech scouting platform focused specifically on enterprise-ready startups, maintaining a curated database of over 50,000 vetted technology companies. The platform targets corporate innovation teams and technology scouts evaluating vendors and partnership candidates rather than conducting deep technical research. Traction emphasizes workflow management for the startup evaluation process, including scoring templates, comparison matrices, and collaboration features for distributed teams. The company also offers research analyst services to supplement platform capabilities with human-powered scouting support.
4. HYPE Innovation
HYPE Innovation delivers an enterprise innovation management platform that includes technology scouting capabilities within a broader suite of idea management and innovation program tools. The platform provides access to a database of technologies and startups while emphasizing collaborative evaluation workflows that engage internal stakeholders in assessing external innovations. HYPE serves organizations seeking to connect technology scouting with employee innovation programs and strategic planning processes. The platform has operated for over twenty years and maintains a client base across Fortune 500 companies and public sector organizations.
5. ITONICS
ITONICS provides an innovation operating system that incorporates technology scouting alongside trend monitoring, ideation, and portfolio management capabilities. The platform offers radar visualization tools for tracking emerging technologies across industries and AI-enhanced discovery features for identifying startups and research trends. ITONICS targets innovation strategy teams seeking to connect external technology intelligence with internal innovation planning and resource allocation decisions.
6. Qmarkets Q-scout
Qmarkets offers Q-scout as a dedicated technology scouting module within its broader innovation management platform. The solution focuses on startup scouting and deal flow management, providing tools for identifying, tracking, and evaluating potential technology partners. Q-scout includes AI-powered insights for assessing startup fit and risk, along with visualization tools for mapping scouting portfolios. The platform targets corporate innovation and venture teams managing pipelines of external partnership opportunities.
7. Ezassi
Ezassi provides technology scouting software that combines discovery tools with open innovation challenge management capabilities. The platform includes access to patent databases covering over 90 countries and integrates Crunchbase data for company research. Ezassi emphasizes customizable workflows and offers full-service scouting research programs where the company's team conducts technology discovery on behalf of clients. The platform serves organizations seeking to supplement internal scouting capacity with external research support.
8. PatSnap Discovery
PatSnap Discovery offers patent analytics and technology intelligence capabilities within a platform primarily designed for intellectual property professionals. The solution provides patent landscape analysis, competitive intelligence features, and innovation tracking tools. While PatSnap serves IP departments and patent attorneys as its primary audience, the Discovery product extends capabilities toward R&D teams conducting technology assessments and freedom-to-operate analyses.
How to Evaluate Tech Scouting Platforms for R&D
Enterprise R&D teams evaluating tech scouting platforms should assess candidates across several critical dimensions that determine long-term value for technical scouting workflows.
Data coverage represents the foundational consideration for any tech scouting platform. The most effective technical scouting requires access to both patent databases and scientific literature, since breakthrough technologies often appear in academic research years before patent filings. Platforms offering only startup databases or limited patent coverage constrain the scope of technical discovery possible. R&D teams should verify total record counts, geographic coverage of patent jurisdictions, and depth of scientific publication indexing when comparing platforms.
Search intelligence determines whether R&D professionals can actually find relevant technologies within large datasets. Keyword-based search requires users to anticipate terminology variations and often misses relevant results. Semantic search powered by technical ontologies recognizes conceptual relationships and surfaces relevant innovations regardless of specific terminology used. For technical scouting across scientific domains, ontology-driven search provides significantly higher recall than traditional approaches.
Enterprise integration capabilities matter for organizations seeking to embed tech scouting within broader R&D workflows. API access, single sign-on support, and compatibility with existing research tools determine whether a platform functions as integrated infrastructure or remains a standalone application. R&D teams should evaluate how scouting insights flow into product development processes and strategic planning systems.
Security and compliance requirements vary across industries but represent non-negotiable criteria for enterprises handling sensitive competitive intelligence. SOC 2 certification, data residency options, and access control capabilities determine whether platforms meet enterprise procurement standards. R&D teams in regulated industries should verify compliance certifications before engaging in detailed evaluations.
Frequently Asked Questions
What is a tech scouting platform?
A tech scouting platform is software that helps R&D teams systematically discover emerging technologies, monitor innovation landscapes, and identify potential technology partners or acquisition targets. Tech scouting platforms aggregate data from patent databases, scientific publications, startup information sources, and market intelligence providers into unified search environments. The best tech scouting platforms use AI-powered semantic search to surface relevant technologies based on conceptual meaning rather than requiring exact keyword matches.
What is the difference between tech scouting and startup scouting?
Tech scouting focuses on discovering technologies regardless of their source, including academic research, patent filings, and established company R&D activities, while startup scouting specifically targets early-stage companies as potential partners or investment opportunities. Tech scouting platforms designed for R&D teams emphasize patent analysis and scientific literature coverage, whereas startup scouting tools focus on company databases, funding information, and relationship management workflows. Enterprise R&D teams typically require tech scouting capabilities that extend beyond startup databases to include the full landscape of technical innovation.
Which tech scouting platform has the largest database?
Cypris maintains the largest unified database among tech scouting platforms purpose-built for R&D teams, with over 500 million patents and scientific papers accessible through a single search interface. Wellspring claims over 400 million records across patents, publications, and startup information. Database size alone does not determine platform value, as search intelligence and data quality significantly impact whether users can find relevant technologies within large datasets.
What is an R&D ontology and why does it matter for tech scouting?
An R&D ontology is a structured representation of technical concepts and their relationships that enables AI-powered semantic search across scientific and patent literature. Ontology-driven tech scouting platforms understand that different terms may describe the same technology and surface relevant results regardless of specific terminology used in source documents. For technical scouting, an R&D ontology addresses the fundamental challenge of terminology variation across industries, geographies, and research traditions that causes keyword-based search to miss relevant innovations.
What should enterprise R&D teams look for in a tech scouting platform?
Enterprise R&D teams should prioritize tech scouting platforms offering comprehensive data coverage spanning patents and scientific literature, semantic search powered by technical ontologies, API access for workflow integration, and enterprise security certifications including SOC 2 compliance. The most effective platforms for technical scouting combine depth of technical data with AI-powered search intelligence that understands scientific concepts rather than simply matching keywords.
How long does it take to implement a tech scouting program?
Most organizations can begin extracting value from tech scouting platforms within four to eight weeks of initial deployment. The first two weeks typically involve platform configuration, user training, and definition of initial search strategies aligned with strategic priorities. Weeks three through six focus on refining search approaches based on initial results and establishing workflows that connect discovery to evaluation processes. By week eight, teams generally have functioning scouting rhythms producing actionable technology intelligence. Full program maturity, including optimized search strategies, established feedback loops, and integration with R&D planning processes, typically requires six to twelve months of iterative refinement.
Should tech scouting be centralized or distributed across R&D teams?
The optimal organizational model depends on R&D structure and strategic objectives. Centralized tech scouting teams provide consistency in methodology, avoid duplication of effort, and build specialized expertise in discovery techniques. Distributed models embed scouting capability within business units or technology domains, enabling closer alignment with specific strategic needs and faster translation of insights into action. Many organizations adopt hybrid approaches, maintaining central teams for horizon scanning and landscape mapping while distributing target identification responsibilities to business units with direct accountability for partnership and development decisions.

AI-Accelerated Materials Discovery: How Generative Models, Graph Neural Networks, and Autonomous Labs Are Transforming R&D
This article was powered by Cypris Q, an AI agent that helps R&D teams instantly synthesize insights from patents, scientific literature, and market intelligence from around the globe.
Last Updated: December 2025
AI-accelerated materials discovery has emerged as one of the most transformative developments in corporate R&D over the past 18 months, fundamentally reshaping how research teams approach materials innovation. The convergence of generative AI, graph neural networks (GNNs), and autonomous experimentation platforms is compressing discovery timelines from years to weeks while expanding the accessible chemical space by orders of magnitude.
What is AI-Accelerated Materials Discovery?
AI-accelerated materials discovery refers to the application of machine learning and artificial intelligence techniques to predict, design, and synthesize new materials with desired properties. Unlike traditional trial-and-error approaches that can take 10-20 years to bring a material from concept to commercialization, AI-driven methods reduce this timeline to 1-2 years through computational prediction, inverse design, and automated experimentation (He et al., 2025).
The field encompasses three primary technological pillars. Generative models propose novel molecular structures optimized for target properties. Graph neural networks predict material properties with unprecedented accuracy. Autonomous laboratories synthesize and validate AI-designed materials in closed-loop systems.
Generative Models and Inverse Design: A Paradigm Shift
How Do Generative Models Work for Materials Discovery?
The shift from screening to generation represents a fundamental paradigm change. Rather than evaluating millions of existing candidates, generative models now propose entirely new molecular structures optimized for specific target properties—a process called inverse design (Gao et al., 2025).
Transformer-Based Architectures
Recent transformer-based architectures treat crystal structures as sequences, enabling GPT-style generation of materials with specified characteristics.
AtomGPT uses natural language processing techniques to generate atomic structures for tasks like superconductor design, with predictions validated through density functional theory (DFT) calculations (Choudhary, 2024).
MatterGPT is a generative transformer for multi-property inverse design of solid-state materials, capable of targeting both lattice-insensitive properties such as formation energy and lattice-sensitive properties such as band gap simultaneously (Deng et al., 2024).
AlloyGAN combines large language model-assisted text mining with conditional generative adversarial networks, predicting thermodynamic properties of metallic glasses with less than 8% discrepancy from experiments (Wen et al., 2025).
Diffusion Models for Crystal Generation
Diffusion models have proven particularly effective for crystal structure generation, offering superior control over chemical validity.
CrysVCD (Crystal generator with Valence-Constrained Design) integrates chemical valence constraints directly into the generative process, achieving 85% thermodynamic stability and 68% phonon stability in generated structures. The valence constraint enables orders-of-magnitude more efficient chemical validation compared to pure data-driven approaches with post-screening (Li et al., 2025).
Diffusion models with transformers combine the generative power of diffusion processes with transformer attention mechanisms for inverse design of crystal structures (Mizoguchi et al., 2024).
Active Learning and Closed-Loop Optimization
Active learning frameworks close the loop between generation and validation, iteratively improving material proposals.
InvDesFlow-AL is an active learning-based workflow that iteratively optimizes material generation toward desired performance characteristics. The system successfully identified LiAuH as a BCS superconductor with a 140K transition temperature, progressively generating materials with lower formation energies while expanding exploration across diverse chemical spaces (arXiv, 2025).
Gated Active Learning integrates prior knowledge and expert insights in autonomous experiments, using dynamic gating mechanisms to streamline exploration and optimize experimental efficiency (Liu, 2025).
These approaches address the "one-to-many" problem in inverse design—where multiple different materials can exhibit the same target property—by exploring diverse solutions rather than converging to a single answer.
Graph Neural Networks: Achieving Predictive Precision
Why Are Graph Neural Networks Effective for Materials?
Graph neural networks represent materials as graphs where atoms are nodes and chemical bonds are edges. This representation naturally captures the structural relationships that determine material properties, making GNNs particularly effective for property prediction tasks (Shi et al., 2024).
State-of-the-Art GNN Architectures
EOSnet (Embedded Overlap Structures) incorporates Gaussian Overlap Matrix fingerprints as node features, capturing many-body interactions without explicit angular terms. The architecture achieves 0.163 eV mean absolute error for band gap prediction—surpassing previous state-of-the-art models—and demonstrates 97.7% accuracy in metal/nonmetal classification while providing rotationally invariant and transferable representation of atomic environments (Zhu & Tao, 2024).
CTGNN (Crystal Transformer Graph Neural Network) combines transformer attention mechanisms with graph convolution, using dual-transformer structures to model intra-crystal and inter-atomic relationships comprehensively. This architecture significantly outperforms existing models like CGCNN and MEGNET in predicting formation energy and bandgap properties, particularly for perovskite materials (Shu et al., 2024).
SA-GNN (Self-Attention Graph Neural Network) employs multi-head self-attention optimization, allowing nodes to learn global dependencies while providing different representation subspaces. This approach improves predictive accuracy compared to traditional machine learning and deep learning models (Cui et al., 2024).
Kolmogorov-Arnold Graph Neural Networks (KA-GNN) integrate Kolmogorov-Arnold networks with GNN architectures, offering improved expressivity, parameter efficiency, and interpretability. These networks consistently outperform conventional GNNs in molecular property prediction while highlighting chemically meaningful substructures (Xia et al., 2025).
Hybrid Approaches: Combining GNNs with Large Language Models
Hybrid-LLM-GNN integrates graph-based structural understanding with large language model semantic reasoning, achieving up to 25% improvement over GNN-only models in materials property predictions. This fusion approach leverages both the structural precision of GNNs and the contextual understanding of language models (Li et al., 2024).
ChargeDIFF represents the first generative model for inorganic materials that explicitly incorporates electronic structure (charge density) into the generation process, enabling inverse design based on three-dimensional charge density patterns—useful for designing battery cathode materials with desired ion migration pathways (arXiv, 2025).
Autonomous Laboratories: From Prediction to Reality
What Are Self-Driving Laboratories?
Self-driving laboratories (SDLs) or autonomous laboratories combine robotic synthesis, in situ characterization, and AI-driven decision-making to create closed-loop experimental systems (Nematov & Raufov, 2025). These platforms can autonomously design experiments, execute synthesis, characterize results, and iteratively optimize toward target materials—all without human intervention.
Key Autonomous Laboratory Platforms
AlabOS (Autonomous Laboratory Operating System) provides a reconfigurable workflow management framework specifically designed for autonomous materials laboratories. The system enables simultaneous execution of varied experimental protocols through modular task architecture, making it well-suited for rapidly changing experimental protocols that define self-driving laboratory development (Jain et al., 2024).
NanoChef is an AI framework for simultaneous optimization of synthesis sequences and reaction conditions. The system incorporates positional encoding and MatBERT embedding to represent reagent sequences. For silver nanoparticle synthesis, NanoChef achieved 32% reduction in size distribution (FWHM) and reached optimal recipes within 100 experiments. The framework discovered a novel "oxidant-last" strategy that yielded the most uniform nanoparticles in three-reagent systems (Han et al., 2025).
Rainbow (Multi-Robot Self-Driving Laboratory) integrates automated nanocrystal synthesis, real-time characterization, and ML-driven decision-making. The system uses parallelized, miniaturized batch reactors with continuous spectroscopic feedback and autonomously optimizes metal halide perovskite nanocrystal optical performance through closed-loop experimentation, identifying scalable Pareto-optimal formulations for targeted spectral outputs (Mukhin et al., 2025).
Active Learning in Autonomous Synthesis
Pulsed Laser Deposition (PLD) Automation combines in situ Raman spectroscopy with Bayesian optimization. The system autonomously identified growth regimes for WSe films by sampling only 0.25% of a 4D parameter space, achieving throughputs 10× faster than traditional PLD workflows. This demonstrates a workflow applicable across diverse materials synthesized by PLD (Vasudevan et al., 2024).
Protein Nanoparticle Synthesis platforms use active transfer learning and multitask Bayesian optimization, leveraging knowledge from previous synthesis tasks to accelerate optimization of new materials. These systems address data-scarce scenarios through mutual active learning where parallel synthesis systems dynamically share data (Kim et al., 2024).
Autonomous 2D Materials Growth employs neural networks trained by evolutionary methods for efficient graphene production. The system iteratively and autonomously learns time-dependent protocols without requiring pretraining on effective recipes, with evaluation based on proximity of Raman signature to ideal monolayer graphene structure (Forti et al., 2024).
Reaction-Diffusion Coupling for Materials Synthesis
Recent work demonstrates autonomous materials synthesis via reaction-diffusion coupling, targeting periodic precipitation patterns (Liesegang bands) with well-defined spacing. Machine learning models process scalarized pattern descriptors and inform experimental conditions to converge toward target precipitation patterns without human input—opening pathways for creating complex products with user-defined chemistry, morphology, and spatial distribution (Butreddy et al., 2025).
Commercial Applications and Industry Adoption
Which Companies Are Leading AI Materials Discovery?
While specific commercial implementations are often proprietary, several indicators point to widespread industrial adoption.
Academic-Industrial Partnerships
Johns Hopkins APL is employing AI-driven materials discovery for national security applications (JHU APL, 2024).
Arizona State University is collaborating on optimizing materials processes through AI and machine learning (ASU News, 2024).
Google DeepMind released GNoME (Graph Networks for Materials Exploration), predicting 2.4 million stable materials and expanding known stable materials by nearly 10× (DeepMind, 2023).
Patent Activity
Recent patent filings reveal significant commercial interest in autonomous robotic systems for laboratory operations, inverse design methods for compound synthesis, and AI-powered materials discovery platforms. The emphasis on modular, reconfigurable platforms reflects industry recognition that materials discovery requires flexible automation rather than fixed protocols.
Real-World Applications
In battery materials, researchers are conducting autonomous search for materials with high Curie temperature using ab initio calculations and machine learning (Iwasaki, 2024), while inverse design of battery cathode materials with desired ion migration pathways uses charge density-based generation.
For catalysts, generative language models are being applied to catalyst discovery (Mok & Back, 2024), and high-entropy catalyst design using spectroscopic descriptors and generative ML has achieved a 32 mV reduction in overpotential (Liu et al., 2025).
In photovoltaics, self-driven autonomous material and device acceleration platforms (AMADAP) are being developed for emerging photovoltaic technologies, enabling discovery of photovoltaic materials based on spectroscopic limited maximum efficiency screening (Brabec et al., 2024).
For sustainable materials, sensor-integrated inverse design of sustainable food packaging materials via generative adversarial networks is enabling chemical recycling and circular economy applications (Hu et al., 2025).
Key Challenges and Limitations
What Are the Main Obstacles to AI Materials Discovery?
Data Quality and Availability remain significant barriers. Limited availability of high-quality experimental data for training, inconsistent or incomplete datasets that produce unreliable predictions, and the need for standardized data practices across the field all contribute to this challenge.
Model Interpretability presents ongoing difficulties. The "black box" nature of deep learning models limits understanding of failure modes, making it difficult to extract design rules or chemical insights from model predictions. There is a clear need for explainable AI (XAI) tools to interpret model decisions (Dangayach et al., 2024).
The Experimental Validation Bottleneck persists as computational predictions far outpace experimental synthesis and characterization capabilities. Synthetic feasibility constraints are often not incorporated into generative models, creating a gap between computationally predicted stability and actual synthesizability (Ceder et al., 2025).
Integration Challenges include seamless integration of in situ characterization techniques with autonomous platforms, coordination between different autonomous laboratory modules, and standardization of interfaces and data formats.
Regulatory and Ethical Considerations also require attention. Regulatory frameworks for AI-discovered materials lag behind technological capabilities, validation requirements for safety-critical applications need development, and intellectual property questions around AI-generated inventions remain unresolved.
Future Directions and Emerging Trends
What's Next for AI Materials Discovery?
Foundation Models for Materials Science represent a major emerging direction. Development of large-scale pre-trained models similar to GPT for language that can be fine-tuned for specific materials tasks is underway, along with integration of multiple data modalities including structure, properties, synthesis conditions, and characterization data, as well as universal embeddings that work across different material classes.
Physics-Informed Machine Learning is advancing rapidly, incorporating physical constraints and domain knowledge directly into model architectures (Wang et al., 2024). Hybrid approaches combining data-driven learning with physics-based simulations ensure that generated materials obey fundamental thermodynamic and chemical principles.
Multi-Objective Optimization enables simultaneous optimization of multiple competing properties such as strength and ductility, Pareto frontier exploration for trade-off analysis, and integration of sustainability metrics and lifecycle considerations.
Federated Learning for Materials enables collaborative model training across institutions without sharing proprietary data, continuous improvement through distributed experimentation (Liu et al., 2025), and building on collective knowledge while preserving competitive advantages.
Digital Twins and Simulation involve creating virtual replicas of materials and processes for scenario planning, enabling predictive maintenance and process optimization, and accelerating testing of extreme conditions.
How to Get Started with AI Materials Discovery
Practical Steps for Corporate R&D Teams
The first step is to assess current capabilities by evaluating existing data infrastructure and quality, identifying high-value use cases where AI could accelerate discovery, and determining computational resources and expertise gaps.
Teams should then start with predictive models by implementing graph neural networks for property prediction on existing materials databases, validating predictions against experimental data, and building confidence in AI approaches before investing in generative models.
Piloting autonomous experimentation involves beginning with semi-automated workflows for specific synthesis tasks, integrating active learning for data-efficient optimization, and gradually increasing autonomy as systems prove reliable.
Building cross-functional teams requires combining materials science expertise with machine learning capabilities, fostering collaboration between computational and experimental researchers, and investing in training to bridge knowledge gaps.
Establishing data infrastructure means implementing standardized data collection and storage protocols, creating pipelines for integrating experimental and computational data, and ensuring data quality and traceability for model training.
Conclusion: The Strategic Imperative
AI-accelerated materials discovery is no longer experimental—it's becoming essential infrastructure for competitive R&D organizations. The integration of generative models, predictive graph neural networks, and autonomous experimentation creates a complete discovery pipeline that compresses development cycles from 10-20 years to 1-2 years, expands accessible chemical space by orders of magnitude through inverse design, improves prediction accuracy to near-experimental precision (such as 0.163 eV for band gaps), enables data-efficient optimization through active learning (sampling less than 1% of parameter space), and accelerates experimental validation with throughputs 10-100× faster than traditional methods.
Organizations that successfully integrate these approaches will maintain competitive advantage in materials innovation. The question is no longer whether to adopt AI-accelerated discovery, but how quickly to deploy these capabilities at scale.
Keywords: AI materials discovery, generative models for materials, graph neural networks, autonomous laboratories, self-driving labs, inverse design, materials informatics, machine learning materials science, AI-accelerated R&D, computational materials discovery, active learning materials, transformer models materials, diffusion models crystals, GNN property prediction, autonomous synthesis, closed-loop optimization, materials acceleration platforms
Related Topics: density functional theory (DFT), crystal structure prediction, high-throughput screening, Bayesian optimization, reinforcement learning materials, transfer learning chemistry, federated learning materials, physics-informed neural networks, explainable AI materials science
About Cypris
Cypris is the leading R&D intelligence platform purpose-built for corporate innovation teams navigating rapidly evolving technology landscapes like AI-accelerated materials discovery. With access to over 500 million data points spanning patents, scientific literature, funding activity, and market intelligence, Cypris enables R&D leaders at companies like Johnson & Johnson, Honda, Yamaha, and Philip Morris International to monitor emerging research, track competitor filings, and identify collaboration opportunities across the full innovation ecosystem. Unlike traditional patent databases designed for IP attorneys, Cypris combines comprehensive data coverage with AI-powered analysis to deliver actionable insights for product development and strategic decision-making. To see how Cypris can accelerate your materials innovation pipeline, visit cypris.ai.
Citations
[2] "Discovering new materials using AI and machine learning." ASU News
[5] "Millions of new materials discovered with deep learning." Google DeepMind
[6] "Johns Hopkins APL Employing AI to Discover Materials..." JHU APL
[11] Anubhav Jain, Gerbrand Ceder, Nathan J. Szymanski, Bernardus Rendy, and Zheren Wang. "AlabOS: A Python-based Reconfigurable Workflow Management Framework for Autonomous Laboratories". arXiv
[12] Yongtao Liu. "(Invited) Gated Active Learning: Integrating Prior Knowledge and Expert Insights in Autonomous Experiments". Meeting Abstracts
[13] Dilshod Nematov and Iskandar Raufov. "The Bright Future of Materials Science with AI: Self-Driving Laboratories and Closed-Loop Discovery". Preprints
[14] Dilshod Nematov, Anushervon Ashurov, Iskandar Raufov, Sakhidod Sattorzoda, and Saidjaafar Murodzoda. "The Bright Future of Materials Science with AI: Self-Driving Laboratories and Closed-Loop Discovery". Journal of Modern Nanotechnology
[15] Pravalika Butreddy, Maxim Ziatdinov, Elias Nakouzi, Sarah I. Allec, and Heather Job. "Toward autonomous materials synthesis via reaction–diffusion coupling". APL Machine Learning
[17] Jinlu He, Yuze Hao, and Lamberto Duò. "Autonomous Materials Synthesis Laboratories: Integrating Artificial Intelligence with Advanced Robotics for Accelerated Discovery". ChemRxiv
[18] Dong‐Pyo Kim, Gi-Su Na, Amirreza Mottafegh, and Jianwen Yang. "Self-Driving Synthesis of Protein Nanoparticles by Active Transfer-Learning-Assisted Autonomous Flow Platform". ACS Sustainable Chemistry & Engineering
[21] Stiven Forti, Edward S. Barnard, Fabio Beltram, Camilla Coletti, and Corneel Casert. "Adaptive AI-Driven Material Synthesis: Towards Autonomous 2D Materials Growth". arXiv
[22] Sang Soo Han, Sehyuk Yim, Hyuk Jun Yoo, and Daeho Kim. "NanoChef: AI Framework for Simultaneous Optimization of Synthesis Sequences and Reaction Conditions at Autonomous Laboratories". ChemRxiv
[23] Sehyuk Yim, Hyuk Jun Yoo, Daeho Kim, and Sang Soo Han. "NanoChef: AI Framework for Simultaneous Optimization of Synthesis Sequences and Reaction Conditions in Autonomous Laboratories". ChemRxiv
[24] Christoph J. Brabec, Jiyun Zhang, and Jens Hauch. "Toward Self-Driven Autonomous Material and Device Acceleration Platforms (AMADAP) for Emerging Photovoltaics Technologies". Accounts of Chemical Research
[25] Yang Liu, Tianyi Gao, and Honghao Huang. "Machine Learning‐Driven Nanoscale Synthesis for Electrocatalytic Performance: From Data‐Driven Methodologies to Closed‐Loop Optimization". Advanced Materials
[27] Nikolai Mukhin, James A. Bennett, Laura Politi, Fazel Bateni, and Arup Ghorai. "Autonomous multi-robot synthesis and optimization of metal halide perovskite nanocrystals". Nature Communications
[28] Yuma Iwasaki. "Autonomous search for materials with high Curie temperature using ab initio calculations and machine learning". Science and Technology of Advanced Materials Methods
[31] Rama K. Vasudevan, Christopher M. Rouleau, Seok Joon Yun, Kai Xiao, and Alexander A. Puretzky. "Autonomous Synthesis of Thin Film Materials with Pulsed Laser Deposition Enabled by In Situ Spectroscopy and Automation". Small Methods
[36] Tongqi Wen, Qingyao Wu, Zhifeng Gao, Peilin Zhao, and Beilin Ye. "Inverse Materials Design by Large Language Model-Assisted Generative Framework". arXiv
[38] Mingda Li, Weiliang Luo, Weiwei Xie, Yongqiang Cheng, and Heather J. Kulik. "Enhancing Materials Discovery with Valence Constrained Design in Generative Modeling". Research Square
[39] "InvDesFlow-AL: Active Learning-based Workflow for Inverse Design of Functional Materials". arXiv
[40] Kamal Choudhary. "AtomGPT: Atomistic Generative Pretrained Transformer for Forward and Inverse Materials Design". The Journal of Physical Chemistry Letters
[41] Kamal Choudhary. "AtomGPT: Atomistic Generative Pre-trained Transformer for Forward and Inverse Materials Design". arXiv
[42] Dong Hyeon Mok and Seoin Back. "Generative Language Model for Catalyst Discovery". arXiv
[43] Xiaobin Deng, Xueru Wang, Hang Xiao, Xi Chen, and Yan Chen. "MatterGPT: A Generative Transformer for Multi-Property Inverse Design of Solid-State Materials". arXiv
[46] Teruyasu Mizoguchi, Kiyou Shibata, and Izumi Takahara. "Generative Inverse Design of Crystal Structures via Diffusion Models with Transformers". arXiv
[48] Ze-Feng Gao, Xin-De Wang, Zhong-Yi Lu, M. Xu, and Xu Han. "AI-driven inverse design of materials: Past, present and future". Chinese Physics Letters
[49] Xiaoyu Hu, Yang Liu, Lijie Guo, and Ziqi Zhou. "Sensor-Integrated Inverse Design of Sustainable Food Packaging Materials via Generative Adversarial Networks". Sensors
[50] Zong-xian Gao, Xin-De Wang, Zhong-Yi Lu, M. Xu, and Xu Han. "AI-driven inverse design of materials: Past, present and future". arXiv
[51] Raghav Dangayach, Elif Demirel, Nohyeong Jeong, Niğmet Uzal, and Victor Fung. "Machine Learning-Aided Inverse Design and Discovery of Novel Polymeric Materials for Membrane Separation". Environmental Science & Technology
[52] Ceder, Gerbrand, Zhang Yu-Meng, Link Paul, Petrova Mariana, and Friederich, Pascal. "Generative models for crystalline materials". arXiv
[53] Ceder, Gerbrand, Zhang Yu-Meng, Link Paul, Petrova Mariana, and Friederich, Pascal. "Generative models for crystalline materials". arXiv
[54] "Integrating electronic structure into generative modeling of inorganic materials". arXiv
[58] Daobin Liu, Donglai Zhou, Qing Zhu, Guilin Ye, and Linjiang Chen. "A Practical Inverse Design Approach for High-Entropy Catalysts with Generative AI". Research Square
[61] Le Shu, Yongfeng Mei, Yuanfeng Xu, Hao Zhang, and Yan Cen. "CTGNN: Crystal Transformer Graph Neural Network for Crystal Material Property Prediction". arXiv
[64] Li Zhu and Shuo Tao. "EOSnet: Embedded Overlap Structures for Graph Neural Networks in Predicting Material Properties". The Journal of Physical Chemistry Letters
[66] Yuxian Cui, Shu Zhan, Huaijuan Zang, Yongsheng Ren, and Jiajia Xu. "SA-GNN: Prediction of material properties using graph neural network based on multi-head self-attention optimization". AIP Advances
[68] Xingyue Shi, Linming Zhou, Zijian Hong, Yuhui Huang, and Yongjun Wu. "A review on the applications of graph neural networks in materials science at the atomic scale". Materials Genome Engineering Advances
[69] Z N Wang, Hao Cheng, Haokai Hong, Kay Chen Tan, and Tong Yang. "A physics-informed cluster graph neural network enables generalizable and interpretable prediction for material discovery". Research Square
[70] Qingxu Li and Ke-Lin Zhao. "Recent Advances and Applications of Graph Convolution Neural Network Methods in Materials Science". Advances in Applied Sciences
[72] Youjia Li, Ankit Agrawal, Daniel Wines, Kamal Choudhary, and Vishu Gupta. "Hybrid-LLM-GNN: Integrating Large Language Models and Graph Neural Networks for Enhanced Materials Property Prediction". Digital Discovery
[83] Kelin Xia, Longlong Li, Guanghui Wang, and Yipeng Zhang. "Kolmogorov–Arnold graph neural networks for molecular property prediction". Nature Machine Intelligence
[86] Shanghai Artificial Intelligence Innovation Center and TSINGHUA UNIVERSITY. Molecular multi-step inverse synthesis path planning method and device based on large language model. Patent No. CN-120954565-A. Issued Nov 13, 2025.
[89] ZHEJIANG UNIVERSITY. Template-free molecular multi-step inverse synthesis prediction method and device. Patent No. CN-117292763-A. Issued Dec 25, 2023.
[91] EAST CHINA NORMAL UNIVERSITY. Molecular inverse synthetic route planning method and planning system. Patent No. CN-119207637-B. Issued Jul 21, 2025.
[103] ZHEJIANG UNIVERSITY. Inverse synthetic route planning method and system based on multi-mode large model. Patent No. CN-120089250-A. Issued Jun 2, 2025.
[104] ZHEJIANG UNIVERSITY. Inverse synthetic route planning method and system based on multi-mode large model. Patent No. CN-120089250-B. Issued Jul 10, 2025.
[133] Noodle.ai. Artificial intelligence platform. Patent No. US-11636401-B2. Issued Apr 24, 2023.
[146] AUTONOMOUS LABORATORY MONITORING ROBOT AND METHOD THEREOF. Patent No. IN-202321042221-A. Issued Dec 26, 2024.
[148] F. HOFFMANN-LA ROCHE AG, KARLSRUHE INSTITUTE OF TECHNOLOGY, and ROCHE DIAGNOSTICS GMBH. AUTONOMOUS MOBILE ROBOT MODULE AND AUTOMATED MODULAR LAB ASSISTANT SYSTEM COMPRISING THE AUTONOMOUS MOBILE ROBOT MODULE FOR PERFORMING MULTIPLE LABORATORY OPERATIONS. Patent No. WO-2025202059-A1. Issued Oct 1, 2025.
[153] DALIAN DAHUAZHONGTIAN TECHNOLOGY Co.,Ltd. Autonomous management scheduling system and method for automatic multi-chain DNA (deoxyribonucleic acid) synthesis laboratory robot. Patent No. CN-121061858-A. Issued Dec 4, 2025.

Prior art search software has undergone three distinct generations of technical evolution. First-generation tools relied on Boolean keyword matching, requiring users to anticipate exact terminology appearing in patents and publications. Second-generation platforms introduced semantic search using vector embeddings to identify conceptually similar documents regardless of keyword matches. The current generation leverages retrieval-augmented generation architectures, domain-specific ontologies, and large language models to deliver contextual intelligence that earlier approaches cannot match.
For R&D and innovation teams conducting prior art analysis, understanding these architectural differences matters because they directly affect search quality, result interpretability, and integration with AI-powered workflows. As organizations increasingly embed AI capabilities into research and product development processes, prior art search infrastructure must evolve beyond simple document retrieval toward genuine technical intelligence.
The Limitations of Basic Semantic Search
Semantic search represented a meaningful advance over keyword matching by using embedding models to represent documents and queries as vectors in high-dimensional space. Documents with similar vector representations surface as relevant results even when they use different terminology than the query. This approach dramatically improved recall compared to Boolean search, particularly for users unfamiliar with patent claim language or technical jargon.
However, semantic search based purely on embedding similarity has significant limitations for R&D applications. Vector similarity captures surface-level conceptual relationships but misses the structured technical knowledge that distinguishes one chemical compound from another, one mechanical configuration from a related design, or one algorithm from a functionally similar approach. Two documents may have similar embedding vectors while describing fundamentally different technical implementations.
The problem intensifies in specialized domains where precise technical distinctions carry significant implications. In pharmaceutical research, the difference between two molecular structures may be invisible to a general-purpose embedding model but critical for patentability and freedom-to-operate analysis. In electronics, subtle circuit topology differences distinguish patentable innovations from prior art. Generic semantic search lacks the domain knowledge to recognize these distinctions.
Additionally, embedding-based search provides ranked lists of similar documents without explaining why they are relevant or how they relate to specific aspects of a technical query. R&D teams need more than document rankings; they need structured analysis of how prior art relates to particular technical features, components, or claims. Basic semantic search cannot deliver this level of analytical depth.
Retrieval-Augmented Generation for Prior Art Intelligence
Retrieval-augmented generation, or RAG, represents the current state of the art for AI-powered information systems. RAG architectures combine the knowledge retrieval capabilities of search systems with the natural language understanding and generation capabilities of large language models. Rather than simply returning ranked document lists, RAG systems retrieve relevant information and synthesize it into contextual responses that directly address user queries.
For prior art search, RAG enables fundamentally different user interactions. Instead of constructing queries and manually reviewing result lists, R&D teams can describe technical concepts in natural language and receive synthesized analyses of relevant prior art. The system retrieves pertinent patents and publications, then generates explanations of how retrieved documents relate to the query, what technical features they disclose, and where potential novelty or freedom-to-operate issues may exist.
The quality of RAG-based prior art analysis depends critically on the retrieval layer. Generic RAG implementations using standard embedding models inherit the limitations of basic semantic search: they retrieve documents based on surface similarity without understanding structured technical relationships. Sophisticated RAG architectures address this limitation by incorporating domain-specific retrieval mechanisms that understand technical knowledge structures.
Enterprise R&D intelligence platforms like Cypris implement RAG architectures specifically designed for technical and scientific content. By combining retrieval across patents, scientific literature, and market intelligence with LLM-powered synthesis, these platforms enable R&D teams to conduct prior art analysis through natural language interaction while maintaining access to the underlying source documents for verification and deeper investigation.
The Role of Domain-Specific Ontologies
Ontologies provide structured representations of knowledge within specific domains, defining concepts, their properties, and the relationships between them. In contrast to the unstructured similarity captured by embedding vectors, ontologies encode explicit technical knowledge: the hierarchy of chemical compound classes, the functional relationships between mechanical components, the dependencies between software system elements.
Domain-specific ontologies dramatically improve retrieval quality for technical prior art search. When a query involves a particular polymer chemistry, an ontology-aware system understands the broader class of polymers to which it belongs, related synthesis methods, typical applications, and adjacent chemical structures. This structured knowledge enables retrieval that captures technically relevant documents a generic embedding model would miss while filtering out superficially similar but technically irrelevant results.
For R&D applications, ontology-based retrieval provides another critical benefit: explainability. When results are retrieved based on explicit ontological relationships, the system can explain why particular documents are relevant. A patent surfaces not merely because its embedding vector is similar but because it discloses a specific catalyst type within the same ontological category as the query compound. This transparency enables R&D teams to evaluate result relevance with confidence.
Cypris employs a proprietary R&D ontology spanning technical domains across patents, scientific literature, and market intelligence sources. This ontology enables the platform to understand queries in terms of structured technical concepts rather than treating them as unstructured text for embedding. The result is retrieval that reflects genuine technical relationships rather than superficial linguistic similarity.
LLM Integration and the Hallucination Problem
Large language models have transformed expectations for information system interactions. Users increasingly expect to engage with technical content through natural language dialogue rather than query construction and manual document review. LLMs enable this conversational interaction, but they introduce a significant risk for prior art applications: hallucination.
LLMs can generate plausible-sounding technical content that has no basis in actual documents. For prior art search, hallucination is not merely inconvenient but potentially dangerous. An LLM confidently asserting that no relevant prior art exists when relevant documents actually exist could lead to patent applications that face rejection, products that infringe existing rights, or R&D investments duplicating existing work. Conversely, hallucinated prior art references could cause organizations to abandon genuinely novel directions.
RAG architectures mitigate hallucination risk by grounding LLM responses in retrieved documents. The LLM synthesizes and explains information from actual sources rather than generating content from its parametric knowledge. However, the effectiveness of this grounding depends on retrieval quality. If the retrieval layer misses relevant documents or returns irrelevant ones, the LLM's grounded response will reflect these retrieval failures.
This is precisely why ontology-enhanced retrieval matters for LLM-powered prior art search. By ensuring that retrieval captures technically relevant documents based on structured domain knowledge, ontology-aware systems provide LLMs with appropriate source material for grounded responses. The combination of ontology-based retrieval, comprehensive data coverage, and LLM synthesis creates prior art intelligence that is both conversationally accessible and technically reliable.
Enterprise platforms with official API partnerships with major AI providers, including OpenAI, Anthropic, and Google, offer organizations the ability to integrate prior art intelligence into their own AI-powered applications and workflows. These partnerships ensure that enterprise API access meets reliability, security, and compliance standards required for production deployment in corporate R&D environments.
Comprehensive Data Coverage as the Foundation
Sophisticated retrieval architectures and LLM capabilities deliver value only when applied to comprehensive underlying data. The most advanced RAG implementation provides limited utility if it searches only a subset of relevant patents or excludes scientific literature where critical prior art disclosures appear.
Effective prior art search requires unified access to global patent databases, scientific literature across disciplines, technical standards, conference proceedings, and market intelligence sources. Patents alone capture only a portion of the prior art landscape. Scientific papers frequently disclose concepts years before related patent applications are filed. Technical standards may describe implementations that anticipate patent claims. Market research reveals commercial applications that constitute prior art through public use or sale.
Enterprise R&D intelligence platforms differentiate themselves through data breadth. Cypris provides access to more than 500 million documents spanning patents, scientific papers from over 20,000 journals, market research, and technical standards. This comprehensive corpus ensures that ontology-based retrieval and RAG-powered synthesis operate across the full landscape of potential prior art rather than an artificially constrained subset.
The integration of diverse data sources within a unified platform enables analyses that siloed tools cannot support. Tracing how a technical concept evolves from academic publication through patent protection to commercial application requires visibility across all three domains. Understanding competitive positioning requires simultaneous access to patent portfolios, publication records, and market activity. R&D intelligence increasingly demands this integrated view.
Enterprise Infrastructure for AI-Powered R&D
The evolution from prior art search tools to enterprise R&D intelligence platforms reflects a broader transformation in how organizations conduct research and development. AI capabilities are increasingly embedded throughout R&D workflows, from initial technology scouting through concept development, competitive analysis, and intellectual property strategy. Prior art intelligence must integrate into this AI-powered ecosystem rather than existing as a standalone search function.
Enterprise API access enables organizations to incorporate prior art intelligence into internal AI applications. Rather than requiring researchers to access a separate platform, organizations can embed prior art search within innovation management systems, competitive intelligence dashboards, R&D project management tools, and custom AI assistants. This integration supports workflow efficiency while ensuring that prior art considerations inform decisions throughout the innovation process.
API reliability and security matter significantly for enterprise deployment. Official partnerships between R&D intelligence platforms and major AI providers signal that integrations have been validated for enterprise use cases. SOC 2 Type II certification provides independent verification of security controls appropriate for handling confidential invention disclosures and competitive intelligence. US-based operations and data residency address compliance requirements for organizations with government contracts or regulatory obligations.
The distinction between platforms built for individual practitioners versus enterprise teams manifests in these infrastructure considerations. R&D organizations require not just capable search functionality but robust APIs, enterprise security, administrative controls, and deployment flexibility appropriate for production use across large teams.
Evaluating Prior Art Search Platforms for Technical Sophistication
Organizations evaluating prior art search software should assess technical architecture alongside surface-level features. Key questions reveal whether a platform implements state-of-the-art approaches or relies on previous-generation technology:
Does the platform employ domain-specific ontologies or rely solely on generic embedding models? Ontology-based retrieval provides structured technical understanding that generic semantic search cannot match. The presence of a proprietary ontology designed for R&D and intellectual property applications indicates investment in domain-specific technical infrastructure.
Does the platform implement RAG architecture for AI-powered synthesis? RAG enables natural language interaction with prior art while maintaining grounding in source documents. Platforms offering only ranked document lists without synthesis capabilities require users to manually review and analyze results.
How does the platform address LLM hallucination risk? Reliable prior art intelligence requires mechanisms ensuring that AI-generated analysis is grounded in actual documents. Platforms should provide transparent source attribution enabling users to verify AI-synthesized conclusions against underlying evidence.
What is the scope of data coverage? Comprehensive prior art search requires unified access to patents, scientific literature, and market intelligence. Platforms offering only patent search or treating scientific literature as a secondary add-on provide incomplete coverage for R&D applications.
Does the platform offer enterprise API access with appropriate partnerships and certifications? Integration into AI-powered R&D workflows requires robust APIs validated for enterprise deployment. Security certifications and official partnerships with major AI providers indicate infrastructure maturity.
Frequently Asked Questions
How does RAG differ from basic semantic search for prior art?
Basic semantic search returns ranked lists of documents with similar vector embeddings to a query. RAG architectures retrieve relevant documents and then use large language models to synthesize information into contextual responses that directly address user queries. For prior art search, this means receiving synthesized analysis of how retrieved patents and publications relate to specific technical concepts rather than manually reviewing document lists.
Why do ontologies matter for prior art search quality?
Ontologies encode structured domain knowledge including concept hierarchies, technical relationships, and property definitions. This structured understanding enables retrieval based on genuine technical relationships rather than surface-level text similarity. For R&D applications where precise technical distinctions matter, ontology-based retrieval significantly outperforms generic embedding models that lack domain-specific knowledge.
What risks do LLMs introduce for prior art analysis?
LLMs can hallucinate plausible-sounding technical content without basis in actual documents. For prior art search, this could mean incorrectly asserting that no relevant prior art exists or citing nonexistent references. RAG architectures mitigate this risk by grounding LLM responses in retrieved documents, but effective grounding requires high-quality retrieval that captures technically relevant sources.
Why does scientific literature coverage matter beyond patent databases?
Scientific publications frequently disclose technical concepts before related patent applications are filed. Papers, conference proceedings, and dissertations may constitute prior art that patent examiners focused on patent databases overlook. Comprehensive prior art search requires unified access to scientific literature alongside patents to identify all potentially relevant disclosures.
What should enterprises look for in API access and security?
Enterprise deployment of prior art intelligence requires robust APIs capable of production-scale integration, official partnerships with major AI providers validating enterprise readiness, SOC 2 Type II certification verifying security controls, and potentially US-based operations for organizations with government contracts or regulatory requirements. These infrastructure considerations distinguish enterprise platforms from tools designed for individual practitioners.
Reports

This Cypris research brief maps the full ecosystem and value chain of electric vehicle battery systems and advanced battery materials, tracing the pathway from raw material extraction through precursor and active material production, cell component manufacturing, battery cell production, pack assembly, vehicle integration, and end-of-life recycling. The brief defines each segment's functional role, identifies key players across upstream, midstream, and downstream layers, and analyzes the structural forces — including critical mineral supply volatility, geographic concentration, OEM vertical integration strategies, recycling-driven circularity, and solid-state battery development — that are reshaping where value concentrates and where supply-chain risk resides.

This Cypris research brief maps the ecosystem and value chain of the specialty polymers and high-performance materials industry, covering the full pathway from raw material and monomer suppliers through polymer manufacturers, compounders, additive suppliers, specialty distributors, converters, and end-use OEMs across aerospace, automotive, electronics, medical, energy, and industrial markets. Beyond the segment-by-segment breakdown and player landscape, the brief analyzes the structural forces shaping the ecosystem — including vertical integration strategies, supplier concentration and consolidation patterns, geographic clustering, circularity constraints, and shifting end-market demand — with a central thesis that leverage in this ecosystem concentrates wherever technical specialization overlaps with requalification burden.

Cypris Research Services' inaugural Innovation Outlook examines how AI-driven data center demand is reshaping U.S. power infrastructure — and why hyperscalers have stopped waiting for the grid to catch up. The report synthesizes commercial activity, market sizing, technology trends, and patent-based competitive positioning into a single ecosystem view of behind-the-meter generation, sizing the U.S. opportunity at $35.8B and tracking 56 GW of contracted bypass capacity already in the pipeline. It identifies where the defensible whitespace actually sits — and it's not where most of the market is currently looking.
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)