
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
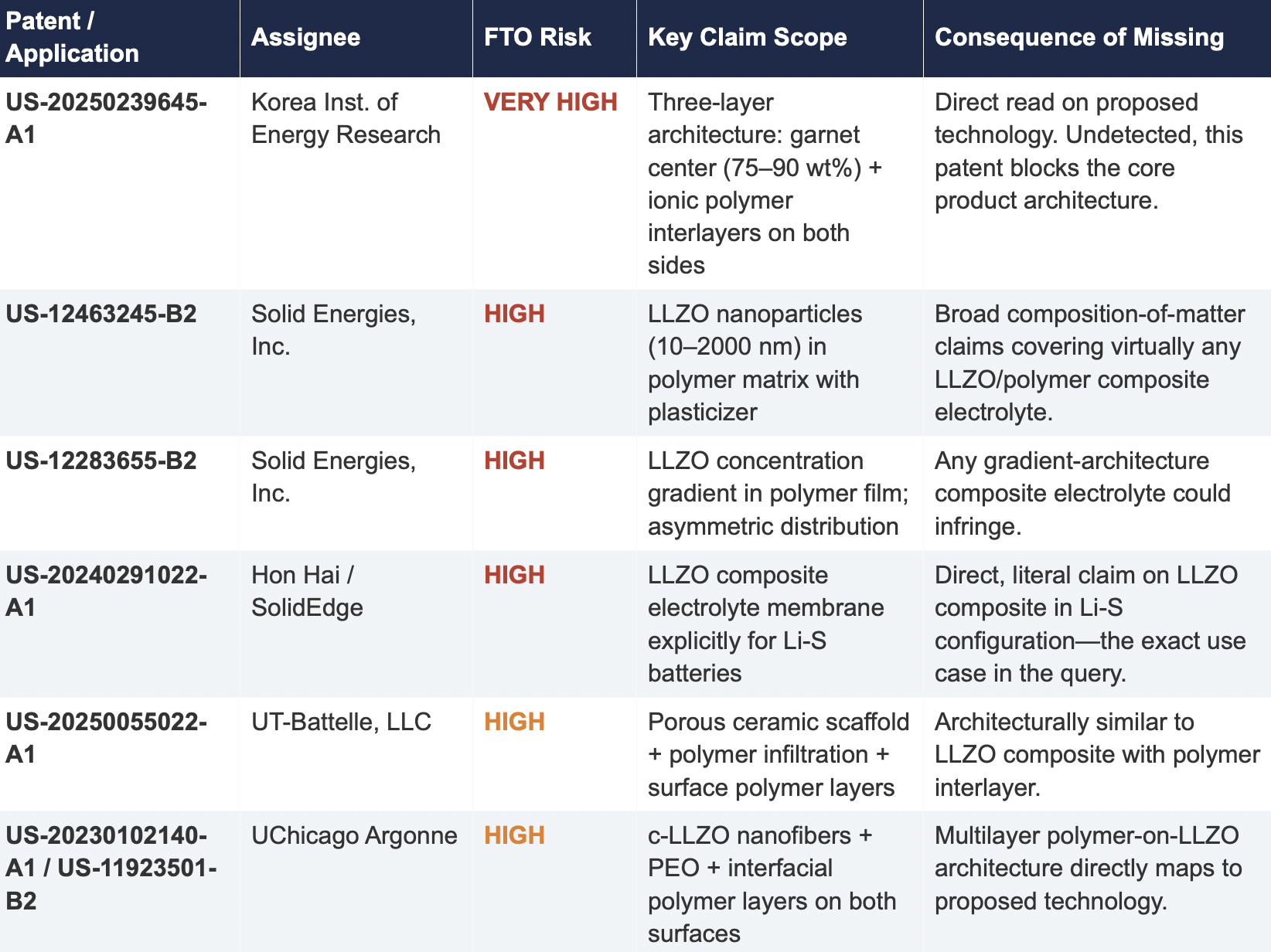
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
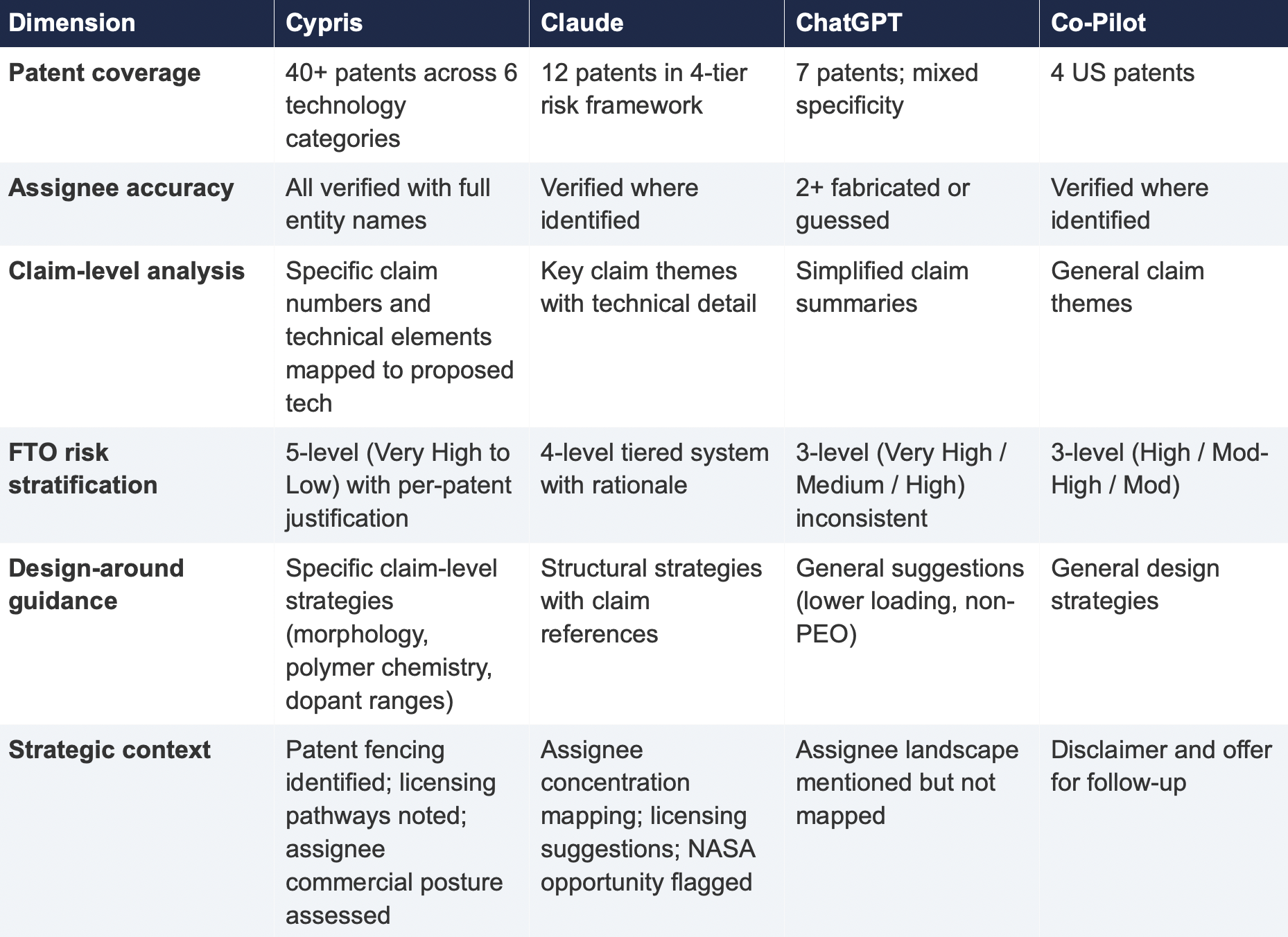
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

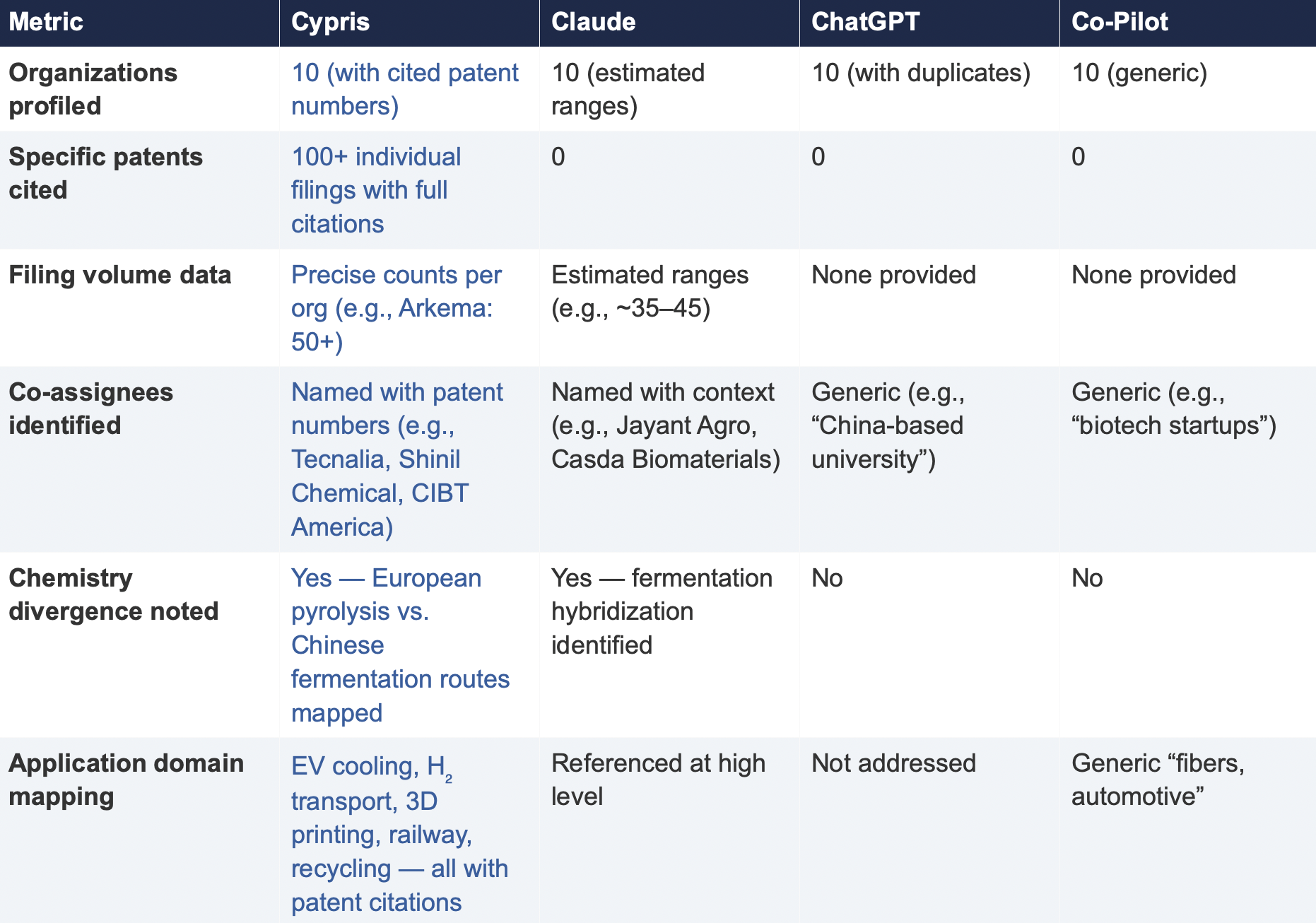
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

Agricultural science research and development is a rapidly evolving field. From advancements in technology to the rise of new funding sources, there are many opportunities for teams to advance their work and produce meaningful insights. To ensure success, it’s important that R&D managers understand the different types of agricultural science research and development projects available as well as what technologies can be used for them.
Additionally, exploring potential funding sources should also be part of any successful project plan. In this blog post, we’ll explore these topics further by taking a look at an overview of agricultural science research and development, the types available, associated technologies used in such projects, and how best practices can help you secure appropriate funding for your efforts.
Table of Contents
Overview of Agricultural Science Research and Development
Benefits of Agricultural Science R&D
Challenges of Agricultural Science R&D
Types of Agricultural Science Research and Development
Technologies in Agricultural Science Research and Development
Sensors and Monitoring Technologies
Funding Sources for Agricultural Science Research and Development
Private Sector Funding and Investment
Overview of Agricultural Science Research and Development
Agricultural science R&D encompasses a wide variety of disciplines including agronomy, horticulture, animal husbandry, entomology, soil science, biochemistry, and genetics.
Research may involve field trials with different varieties or breeds of plants or animals, laboratory experiments using tissue cultures, genetic engineering techniques such as gene editing, computer simulations, remote sensing technology such as satellite imagery, or any combination thereof.
The ultimate aim is to develop sustainable farming practices that will increase crop yields while minimizing environmental impacts such as soil erosion or pollution runoff.
Benefits of Agricultural Science R&D
The benefits associated with agricultural science R&D are numerous.
Improved crop varieties can lead to higher yields per acre while reducing the need for chemical inputs like fertilizers and pesticides which can have negative environmental consequences.
New livestock breeds may offer greater disease resistance or increased milk production potentials which could benefit both producers’ bottom lines as well as consumers who rely on these products for nutrition.
Finally advances in precision agriculture technologies enable farmers to better monitor conditions in their fields so they can make informed decisions based on real-time data rather than guesswork alone – resulting in more efficient use of resources overall.
Challenges of Agricultural Science R&D
Despite its many advantages, there are also some challenges associated with agricultural science research and development projects due primarily to cost constraints imposed by governments along with limited access to private funding sources.
Additionally, even when adequate financial support exists, it often takes several years before results become tangible enough to justify continued investment. This means that long-term planning must be taken into account when designing an effective strategy to ensure success.
(Source)
Types of Agricultural Science Research and Development
Agricultural R&D involves researching, developing, and implementing new technologies to improve crop yields, livestock health, soil fertility, water conservation, and other aspects of agricultural production.
Crop Improvement
Crop improvement R&D focuses on improving the quality and yield of crops through genetic engineering or selective breeding techniques. This type of research can involve creating new varieties that are more resistant to pests or diseases, increasing nutrient content in fruits and vegetables, or introducing traits that make them easier to store or transport.
For example, scientists have developed drought-resistant wheat varieties that are better able to withstand extreme weather conditions while still producing high yields.
Livestock Improvement
Livestock improvement R&D focuses on improving animal health by selecting desirable traits such as disease resistance or improved milk production.
Scientists also use genetic engineering techniques to create animals with specific characteristics such as leaner meat or higher wool yields. For instance, researchers have created goats with increased muscle mass which results in larger carcasses when slaughtered for meat consumption.
Soil and Water Conservation
Soil and water conservation R&D aims to reduce the environmental damage caused by agricultural activities such as overgrazing, deforestation, and excessive irrigation.
Sustainable farming methods are developed in order to conserve resources while maintaining productivity levels. Examples of these include using cover crops to reduce erosion, planting trees along riverbanks for shade, employing drip irrigation systems, and introducing integrated pest management strategies instead of chemical pesticides.
These efforts seek to decrease negative impacts on soil fertility and water availability while also increasing crop yields.
Key Takeaway: Agricultural science research and development is essential for the global food system. It includes crop improvement, livestock improvement, and soil and water conservation R&D to increase yields, improve animal health, conserve resources, and reduce environmental damage.
Technologies in Agricultural Science Research and Development
Automation Technologies
Automation technologies are being used in agricultural science research and development to improve efficiency and accuracy. These technologies can be used for tasks such as monitoring soil moisture, controlling irrigation systems, tracking crop growth, and managing livestock health.
Automated systems can also be used to detect pests or diseases that may affect crops or animals. By using automation technology, researchers can save time and money while still obtaining accurate results.
Sensors and Monitoring Technologies
Sensors and monitoring technologies are essential tools for agricultural science research and development projects. They allow researchers to collect data on a variety of factors including temperature, humidity, light levels, soil composition, soil water content, air quality measurements, and animal behavior patterns like grazing habits or movement patterns of livestock herds.
This data is then analyzed by scientists who use it to develop new strategies for improving crop yields or increasing the productivity of livestock operations.
Data Analysis Technologies
Data analysis technologies enable researchers to quickly analyze large amounts of data collected from sensors or other sources.
- Techniques such as machine learning algorithms can identify trends in the data over time.
- Predictive analytics uses past information to predict future outcomes.
- Statistical modeling helps understand relationships between different variables.
- Artificial intelligence (AI) automates decision-making processes based on inputted criteria.
- Computer vision enables machines to recognize objects within images.
- Natural language processing (NLP) allows computers to interpret human language inputs into structured outputs.
- Sentiment analysis measures people’s attitudes towards certain topics based on their words online.
- Deep learning algorithms process large amounts of unstructured data sets more efficiently than traditional methods do.
All these techniques help make sense of complex datasets so that researchers can draw meaningful conclusions about their experiments faster than ever before possible.
Key Takeaway: Agricultural science research and development projects are being revolutionized by automation technologies, monitoring technologies, machine learning algorithms, predictive analytics, and AI decision-making processes.
Funding Sources for Agricultural Science Research and Development
Government grants and programs are a popular source of funding for agricultural science research and development projects. These grants can be used to support initiatives such as crop improvement, livestock improvement, soil conservation, water conservation, and more.
Examples include the USDA’s Agriculture and Food Research Initiative (AFRI) which provides competitively awarded grants to address challenges in food safety, nutrition, animal health, and production efficiency.
Additionally, the National Institute of Food and Agriculture (NIFA) offers grant opportunities that focus on improving rural economies through sustainable agriculture research.
Private Sector Funding and Investment
Private sector funding is another important source of financial support for agricultural science R&D projects. Companies may provide direct investments or venture capital financing to help fund innovative ideas or technologies related to agriculture.
For example, Monsanto has invested heavily in biotechnology research with an emphasis on developing genetically modified crops that can resist pests or tolerate herbicides better than traditional varieties.
Other companies have focused their efforts on developing precision farming technologies such as drones for monitoring crop health or sensors for collecting data about soil conditions across large fields quickly and accurately.
Non-Profit Organizations
Non-profit organizations play an important role in providing financial resources for agricultural science R&D projects through grant programs that promote innovation.
The Bill & Melinda Gates Foundation, for example, has provided over $1 billion dollars since 2006 towards initiatives aimed at increasing food security worldwide. These include advanced technology solutions such as genetic engineering tools or drought-tolerant seed varieties developed through gene editing techniques like CRISPR/Cas9 technology.
Similarly, the Howard G Buffett Foundation has funded numerous research studies looking into ways to improve smallholder farmer productivity around the world by investing in agroecological practices such as intercropping systems which increase nutrient availability while reducing erosion.
Conclusion
Agricultural science research and development is a complex field that requires careful planning, funding, and the use of appropriate technologies. With the right tools in place – such as Cypris’s research platform – teams can maximize their potential when it comes to agricultural science research and development.
Are you looking for an efficient way to access data sources and quickly gain insights? Cypris is the perfect platform for your needs. Our user-friendly interface makes it easy to centralize all of your required data into one place, helping you save time while achieving success in agricultural science R&D projects.
Try out Cypris today and revolutionize the way you work!

R&D is an ever-evolving field. With new technologies and data sources available, what does an R&D researcher do to stay ahead of the curve?
In this blog post, we’ll explore what does an R&D researcher do, the impact of technology on R&D researchers, what it takes to become one, and where the future of R&D is headed.
We’ll also answer that all-important question: What does an R&D researcher do exactly?
Table of Contents
What Does an R&D Researcher Do?
Job Description and Responsibilities
Skills and Qualifications Required for the Role
How to Become an R&D Researcher
The Impact of Technology on R&D Research
Automation and Artificial Intelligence
What is Research in R&D?
Research is a type of scientific inquiry that focuses on the development and improvement of products, processes, services, or technologies. It typically involves experimentation and analysis to find solutions to problems or create new products.
Research can be conducted in-house by a company’s own R&D team or externally through partnerships with universities and other organizations.
The research component of R&D includes both basic and applied science as well as engineering activities such as design, testing, prototyping, and optimization. The goal is to develop better products faster than competitors while staying within budget constraints.
Types of R&D Research
There are several types of R&D research.
- Fundamental (basic) research seeks to understand the underlying principles behind phenomena.
- Exploratory (preliminary) studies explore potential solutions without committing resources.
- Applied (developmental) research focuses on developing specific applications from existing knowledge.
- Commercialization studies involve taking an idea from its concept stage through product launch.
- Evaluation studies assess the performance characteristics and safety requirements for a given product.
- Market surveys/studies measure customer preferences for different features in order to guide product development decisions.
- Cost-benefit analyses compare costs against expected benefits over time.
- Feasibility assessments evaluate whether proposed projects are technically feasible before committing resources.
- Patent searches/analyses identify potentially infringing patents so companies can avoid costly legal disputes down the road.
Benefits of Research
The primary benefit of conducting research is gaining insight into how to improve existing products or develop new ones. This type of work often yields valuable intellectual property rights such as patents that can provide additional protection against competition in certain markets.
Conducting regular R&D helps keep teams up-to-date with emerging trends in their industry, allowing them to stay ahead when it comes to innovation initiatives.
Key Takeaway: R&D research is an organized effort to discover new knowledge about a product, process, service, or technology for the purpose of improving it. This type of work often yields valuable intellectual property rights such as patents that can provide additional protection against competition in certain markets.
What Does an R&D Researcher Do?
Job Description and Responsibilities
A researcher must identify problems, analyze data, design experiments, evaluate results, and report findings. This role requires strong analytical skills as well as the ability to work independently with minimal supervision.
Skills and Qualifications Required for the Role
To be successful in this role, a researcher should have a bachelor’s degree in engineering or a science-related field such as physics or chemistry. They should also possess the following qualifications:
- Excellent problem-solving skills.
- Knowledge of laboratory techniques.
- Familiarity with computer programming languages.
- Experience working with statistical software packages.
- Understanding of product development processes.
- Good communication skills both written and verbal.
- Great attention to detail.
- Creativity when it comes to developing solutions for complex problems.
So what does an R&D researcher do?
A typical day for an R&D researcher may involve the following tasks:
- Designing experiments based on hypotheses generated from previous research studies.
- Collecting data through laboratory testing or simulations using computers.
- Analyzing collected data using various statistical methods such as regression analysis or machine learning algorithms.
- Documenting results in reports that can be shared internally within the organization or externally with customers, partners and vendors.
- Attending meetings where progress updates are discussed amongst other team members.
R&D researchers: We’re the ones who solve complex problems, design experiments, analyze data and report findings. It’s a tough job but someone has to do it! #researchanddevelopment #innovation Click To Tweet
How to Become an R&D Researcher
Becoming an R&D researcher requires a combination of education, training, and experience. To start, you’ll need to have at least a bachelor’s degree in a related field such as engineering or science. Depending on the specific role you’re looking for, some employers may require higher levels of education such as master’s degrees or PhDs.
In addition to educational requirements, many employers will also look for professional certifications and licenses that demonstrate your knowledge and skillset in the field. These can include certifications from organizations like the American Society for Quality (ASQ) or the Institute of Electrical and Electronics Engineers (IEEE).
Finally, having relevant work experience is essential for becoming an R&D researcher. Employers typically prefer candidates who have prior research experience in their industry or similar roles within other companies. This could include internships or part-time jobs while completing a degree program.
Additionally, gaining additional technical skills through courses offered by universities or online platforms can be beneficial when applying for these types of positions.
Are you an R&D researcher? Get the education, training, and experience you need to succeed! Plus, don’t forget certifications and licenses that show off your skillset. #ResearchAndDevelopment #RnD Click To Tweet
The Impact of Technology on R&D Research
Automation and Artificial Intelligence
Automation and artificial intelligence (AI) are having a profound impact on the way research is conducted. AI-powered algorithms can quickly analyze large datasets, identify patterns, and generate insights that would be difficult or impossible for humans to uncover. This has enabled researchers to focus their efforts on more complex tasks such as developing new products or processes instead of spending time manually analyzing data.
AI also enables researchers to make faster decisions based on real-time data analysis, allowing them to respond quickly to changing market conditions.
Data Analysis Tools
Data analysis tools are essential for modern R&D research. These tools allow researchers to quickly process large amounts of data from multiple sources into meaningful information they can use in their work.
Popular tools include:
- Statistical software packages like SPSS and SAS,
- Machine learning libraries like TensorFlow and PyTorch.
- Natural language processing frameworks like spaCy and NLTK.
- Visualization programs like Tableau and Power BI.
- Database management systems such as MySQL and MongoDB.
- Predictive analytics platforms such as IBM Watson Analytics.
- Cloud computing services such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure Machine Learning Studio (MLS).
- Hadoop clusters for big data processing applications.
Cloud computing is revolutionizing the way research is conducted by providing access to powerful computing resources at an affordable cost. By leveraging cloud services such as AWS or GCP’s Infrastructure-as-a-Service offerings, researchers can easily scale up their computing power when needed without investing in expensive hardware or dealing with complicated setup procedures.
Additionally, cloud providers offer a variety of specialized services tailored specifically for scientific research which enable teams to collaborate efficiently across geographic boundaries while securely storing all their project assets in one place online.

(Source)
The Future of R&D Research
The field of R&D is constantly evolving and the future looks brighter than ever. Emerging trends in the field are focused on automation, data analysis tools, cloud computing, and artificial intelligence (AI).
Automation is becoming increasingly important for streamlining processes and reducing manual labor.
Data analysis tools are being used to quickly analyze large datasets to identify patterns or correlations that may not be visible with traditional methods.
Cloud computing has revolutionized how researchers store and access their data, allowing them to collaborate more easily across teams and locations.
AI is also playing an increasingly important role in R&D research by providing insights into complex problems that would otherwise be difficult or impossible to solve manually.
Challenges facing the industry include a lack of skilled personnel, limited resources, tight budgets, and rapidly changing technology landscapes. To overcome these challenges it’s essential for organizations to invest in training programs that can help develop employees’ skill sets so they can keep up with advances in technology.
Additionally, organizations must ensure they have adequate resources available such as software licenses or hardware needed for specific tasks.
Finally, budget constraints should be taken into account when planning projects so there aren’t any surprises down the line due to cost overruns or other unexpected expenses.
Despite these challenges, there are still many opportunities for growth within this field. New technologies such as blockchain could provide increased security measures when dealing with sensitive information. Big data analytics could lead to better decision-making.
Virtual reality applications could improve product design capabilities. Three-dimensional printing solutions could reduce costs associated with prototyping products. Machine learning algorithms could automate tedious tasks like image recognition.
Natural language processing techniques could enable faster communication between humans and machines. Robotic advancements would make certain processes easier or more efficient. Augmented reality applications would allow users greater control over their environment through digital overlays on physical objects.
As technology continues advancing at an exponential rate, we will continue to see new opportunities arise within this space.
Conclusion
R&D is a vital part of the innovation process. It requires creativity and problem-solving skills to come up with new solutions that can help businesses succeed. By understanding what does an R&D researcher do, we can see how they contribute to the success of a company or organization.
With technology continuing to evolve at a rapid pace, there are many opportunities for R&D researchers to make their mark in the world. As such, those interested in becoming an R&D researcher should take advantage of this exciting field and see where it takes them!
Are you looking for a way to simplify and expedite the R&D process? Cypris is here to help! Our research platform provides teams with all of their data sources in one centralized place, allowing them to quickly gain insights that can be used to create meaningful solutions.
With our platform, your team will save time while simultaneously improving results – giving you an edge over competitors. Take advantage of this innovative solution today and see what it can do for your R&D team!

Research and development in science have become increasingly important for businesses as they strive to stay competitive. But how can R&D teams create effective strategies that yield meaningful results? What challenges must be overcome during the process of research and development in science?
To answer these questions and more, we’ll explore what it takes to successfully implement an R&D strategy, identify best practices for research and development in science, discuss common obstacles encountered along the way, and look ahead at what’s next on the horizon.
With all this information combined into one comprehensive guide about research and development in science, you won’t want to miss out!
Table of Contents
What is Research and Development in Science?
How to Implement an Effective R&D Strategy
Establish Goals and Objectives
Identify Resources and Allocating Funds
Challenges of Research and Development in Science
Best Practices for Research and Development in Science
Utilizing Technology to Streamline Processes
Leverage Data Analytics to Make Informed Decisions
The Future of Research and Development in Science
Increased Focus on Sustainability
Interdisciplinary Collaboration
What is Research and Development in Science?
Research and development (R&D) in science is the process of creating new products or services through research, experimentation, and innovation. It involves identifying a need or opportunity for improvement, researching potential solutions to that need, testing those solutions in controlled environments, and then refining them until they are ready for commercialization.
Research and development is an organized effort by scientists, engineers, and other professionals to develop new knowledge or technologies that will lead to improved products or processes. The goal of R&D is to create value by developing innovative solutions that solve problems more effectively than existing methods.
Types of R&D in Science
There are two main types of research and development activities: basic research which focuses on understanding fundamental principles, and applied research which seeks practical applications for the knowledge gained from basic research.
Basic research often leads directly to technological advances while applied research usually results in tangible outcomes such as a product prototype or patentable invention.
Benefits of R&D in Science
Investing resources into scientific inquiry can provide organizations with valuable insights into their industry’s current trends and future opportunities. Engaging with cutting-edge technology helps them stay competitive within their markets, giving them an edge over competitors who have not invested similarly in internal capabilities.
Successful implementation of these advancements can result in increased profits due to cost savings associated with streamlining operations via automation, higher customer satisfaction due to improved quality control measures, and reduced environmental impact thanks to sustainable practices being adopted.
Key Takeaway: Research and development in science is a key component of innovation, allowing teams to explore new ideas and uncover valuable insights.
How to Implement an Effective R&D Strategy
An effective R&D strategy can help companies stay ahead of the competition, develop innovative products and services, and increase their bottom line. To ensure success, it’s important to have a well-thought-out plan in place for implementing an effective R&D strategy.
Establish Goals and Objectives
Before beginning any research or development project, it’s essential to establish clear goals and objectives that are aligned with the company’s overall mission. This will provide direction for the team throughout the process.
Additionally, having specific milestones in place will allow teams to measure progress toward achieving those goals over time.
Identify Resources and Allocating Funds
Once you have established your goals and objectives, you need to identify what resources are necessary to achieve them. This includes both human resources and financial resources.
It is also important to consider potential external partners who may be able to contribute expertise or funding that could accelerate progress toward reaching your desired outcomes.
Create a Project Outline
After identifying all necessary resources, it is time to create a plan outlining how they will be used most effectively during each stage of the project from conception through completion. The plan should include details on tasks assigned at each step along with timelines so everyone knows when certain activities must be completed.
Key Takeaway: By implementing an effective R&D strategy, organizations can maximize their resources and investments to achieve greater results. With the right tools and platforms like Cypris, teams can take their research initiatives to the next level.
Challenges of Research and Development in Science
Finding the Right Talent Pool
One of the biggest challenges faced during research and development in science is finding the right talent pool. It can be difficult to find qualified individuals with the skillset necessary for a particular project, especially when it comes to highly specialized fields.
To overcome this challenge, organizations should look beyond traditional recruitment methods and consider alternative sources such as online job boards or freelancing websites. They should also focus on developing their own internal talent by providing training opportunities and encouraging employees to develop new skill sets.
Securing Funding
Securing funding for projects can also be a major obstacle in research and development in science. Many organizations rely on grants from government agencies or private foundations which can take months or even years to acquire due to long application processes and intense competition between applicants.
Organizations should explore other options such as crowdfunding campaigns or venture capital investments if available in order to obtain funds more quickly.
Overcoming Technical Barriers
Another challenge faced during research and development is overcoming technical barriers that may arise due to limited resources or lack of knowledge about certain technologies. In order to address these issues, organizations should invest in advanced tools that allow them to access data faster while also ensuring accuracy.
Consider seeking out experts who have experience working with specific technologies so that any potential problems can be identified early on before becoming too costly.
Managing Time Constraints
Managing time constraints is essential for research and development projects to succeed. Delays can lead to costly overruns, missed deadlines, and potential loss of funding opportunities if products are released past their expected date.
Organizations must plan tasks ahead of time with realistic timelines so that progress toward completion remains consistent throughout each stage without any unexpected issues.
Research and development in science can be a complex process with numerous challenges, but with the right platform such as Cypris, teams can overcome these obstacles and achieve success.
(Source)
Best Practices for Research and Development in Science
Utilizing Technology to Streamline Processes
Technology can be a powerful tool for research and development teams, allowing them to automate mundane tasks and free up time for more creative pursuits. For example, cloud-based platforms like Cypris allow R&D teams to centralize their data sources into one platform, making it easier to access the information they need quickly.
Automation tools can also help streamline processes such as data collection or analysis, freeing up valuable resources that would otherwise be spent on manual labor.
Leverage Data Analytics to Make Informed Decisions
Data analytics is an invaluable asset when it comes to research and development. By leveraging data analytics tools, organizations can gain insights into customer behavior or market trends that may not have been apparent before. This allows them to make informed decisions about product design or marketing strategies based on hard evidence rather than guesswork.
Additionally, predictive analytics can provide insight into future trends so companies are better prepared for what lies ahead in their industry.
Encourage Collaboration
Encouraging collaboration across teams is essential for research and development projects to be successful. Open communication between team members is key in order for everyone involved to stay up-to-date on progress and share ideas effectively. Utilizing online collaboration tools such as Slack or Zoom can help facilitate this process by providing a centralized space where all team members have access to the same information at any given time.
Research and development teams: streamline processes with tech, leverage data analytics to make informed decisions, and encourage collaboration for success! #RD #Innovation #DataAnalytics Click To Tweet
The Future of Research and Development in Science
Advances in Technology
The future of research and development in science is likely to be heavily impacted by advances in technology. This could include the use of artificial intelligence (AI) and machine learning (ML) to automate certain processes, as well as the increased availability of data-driven insights.
Additionally, new technologies such as 3D printing are already being used to create prototypes faster than ever before. These advancements will help organizations speed up their R&D cycles while also allowing them to stay ahead of the competition.
Increased Focus on Sustainability
With climate change becoming an increasingly pressing issue, there is a growing need for sustainable solutions that can reduce our impact on the environment. Organizations are now looking for ways to incorporate sustainability into their R&D efforts, whether it’s through developing renewable energy sources or finding more efficient ways to produce products and services with minimal environmental damage.
Interdisciplinary Collaboration
Organizations must look beyond traditional approaches to develop innovative solutions that address complex problems. To do this, they must embrace interdisciplinary collaboration between different teams within their organization or even across industries.
By bringing together experts from various fields such as engineering, biology, chemistry, and computer science, companies can gain access to a wider range of perspectives which can lead them toward breakthrough discoveries faster than ever before. This approach is becoming increasingly necessary in order for organizations to stay competitive in today’s market.
The future of research and development in science looks brighter than ever, with new technologies, a greater focus on sustainability, and an increased need for interdisciplinary approaches.
It’s time to get creative with R&D! From AI and ML to 3D printing, sustainability initiatives, and interdisciplinary collaboration – the future of science is here. #ResearchAndDevelopment #Innovation #Science Click To Tweet
Conclusion
R&D is an essential part of innovation and progress. It requires careful planning, implementation of best practices, and a thorough understanding of the challenges that may arise along the way. Research and development in science will continue to play a vital role in driving forward progress within our society, so it’s important that we continue to invest resources into this field.
The future of research and development in science relies on finding faster ways to gain insights. Cypris is the perfect platform for R&D and innovation teams looking to speed up their workflows. Our intuitive interface makes it easy for your team to access data from multiple sources, all within one convenient platform.
Sign up now and start exploring new possibilities with our powerful analytics tools!
Reports
%20-%20Competitive%20Benchmarking%20for%20Industrial%20Robotics%20OEMs.png)
%20-%20Competitive%20Benchmarking%20of%20EV%20Battery%20Material%20%26%20Cell%20Manufacturers.png)
%20-%20Competitive%20Benchmarking%20for%20Wearable%20%26%20Biosensor%20Device%20Manufacturers.png)
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)