
Insights on Innovation, R&D, and IP
Perspectives on patents, scientific research, emerging technologies, and the strategies shaping modern R&D

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
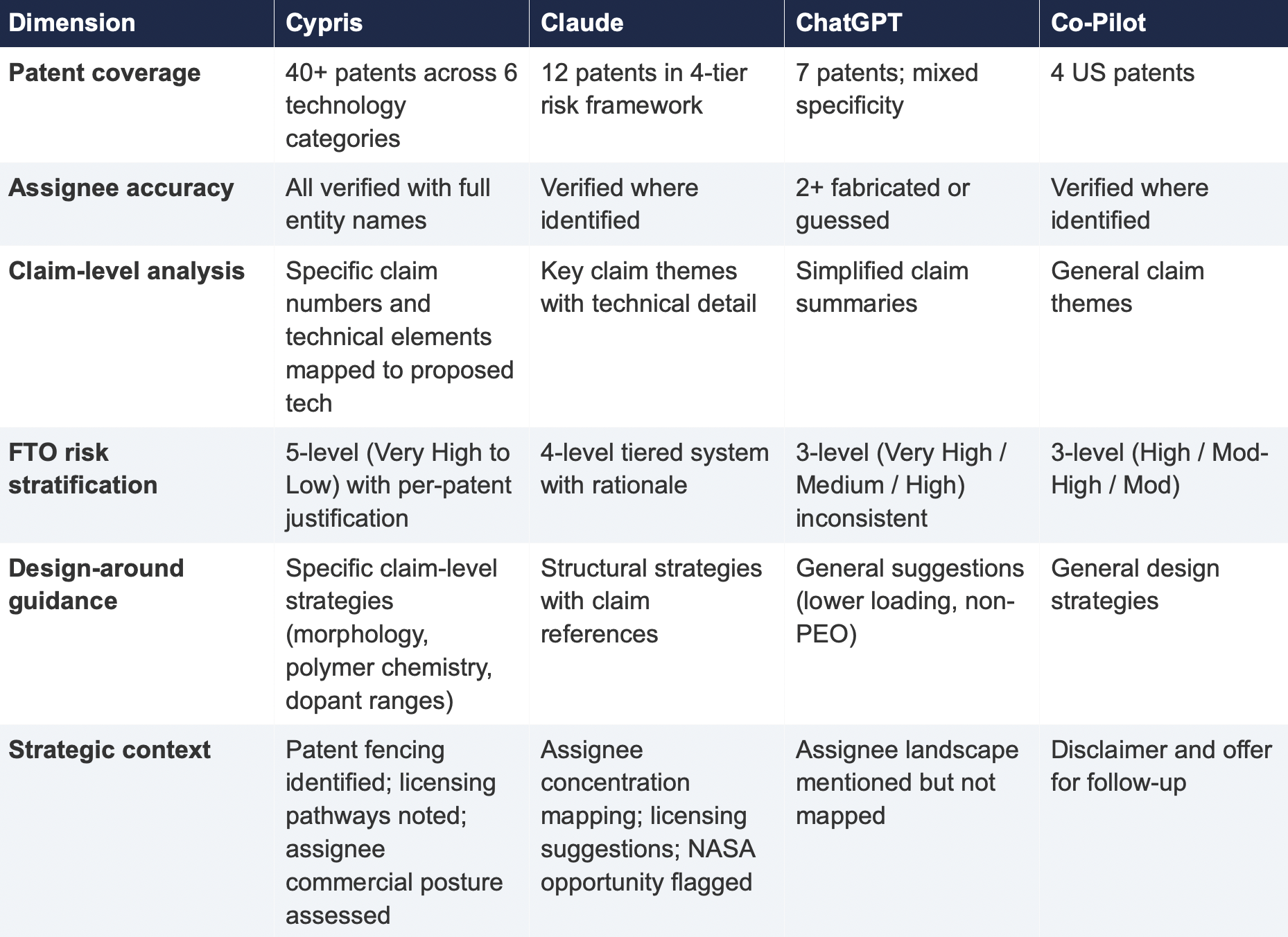
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
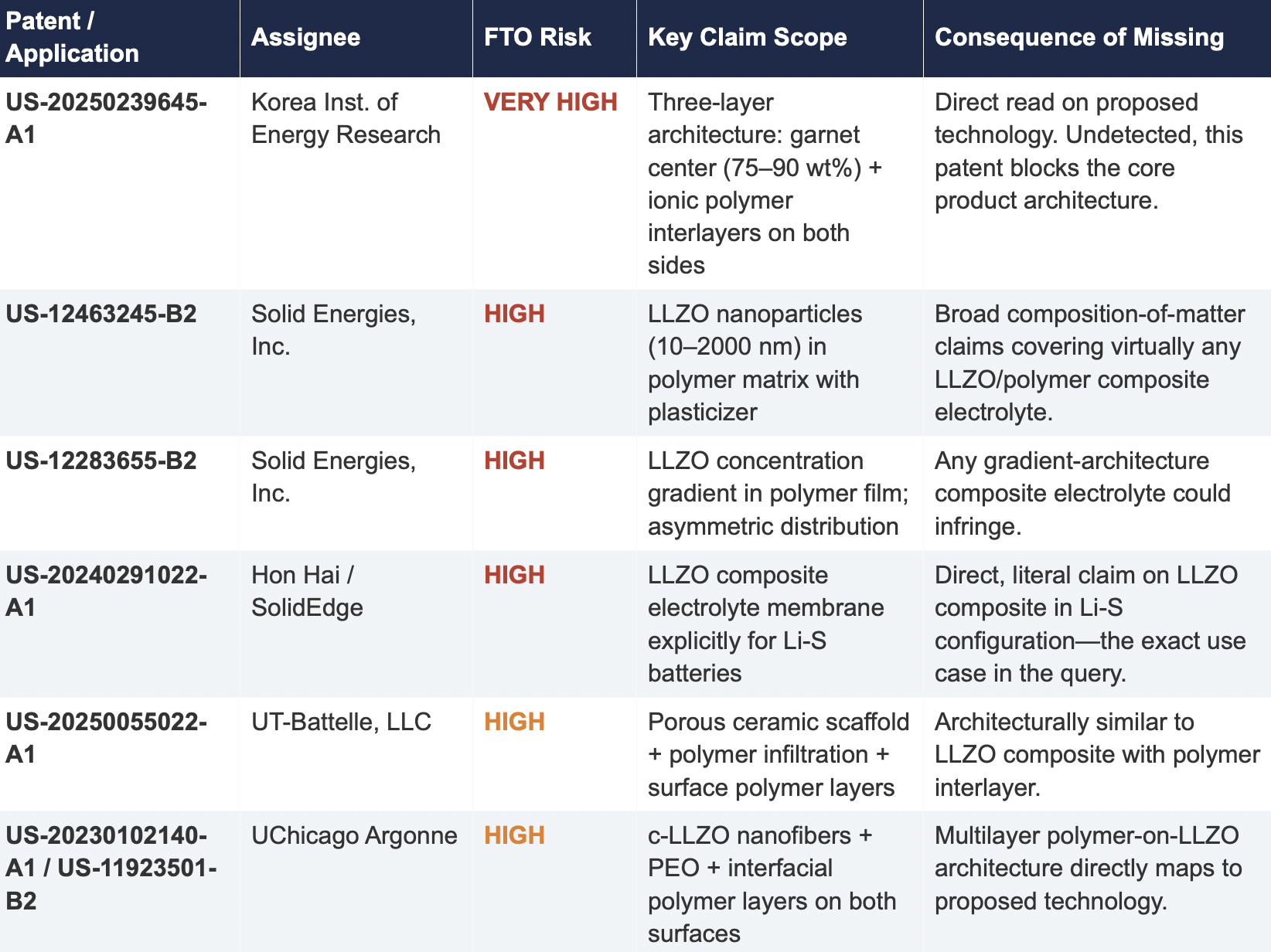
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

6.2 Summary of Results
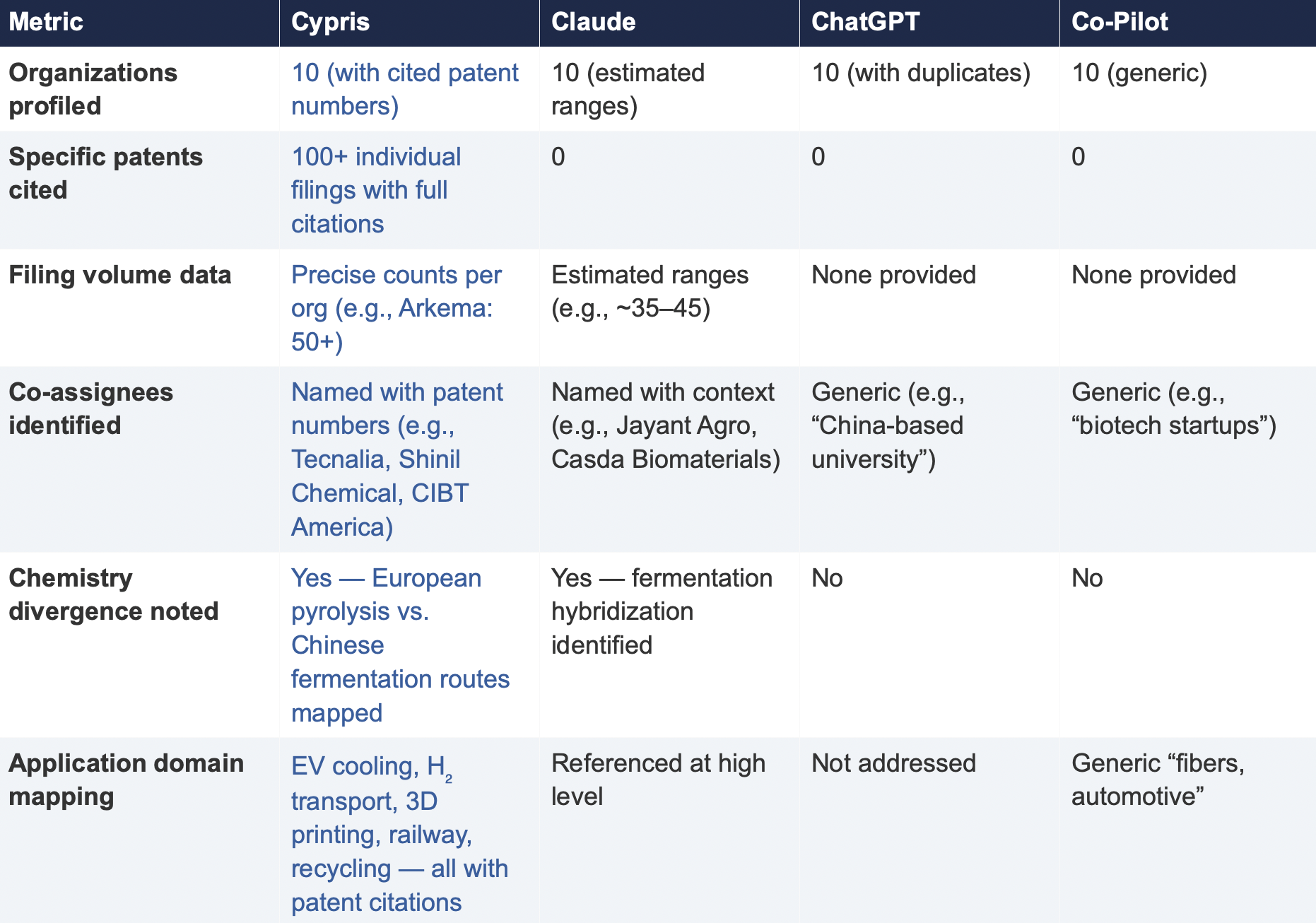
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
All Blogs

With the growing interest in space flight and deep space exploration, more research is focusing on how to make life outside of earth habitable for human beings, and at what cost. In this blog, we’ll look at the market landscape of space travel, recent innovation activity, and scientific literature to gain a full picture of where our understanding of life beyond earth is headed.
Market Overview:
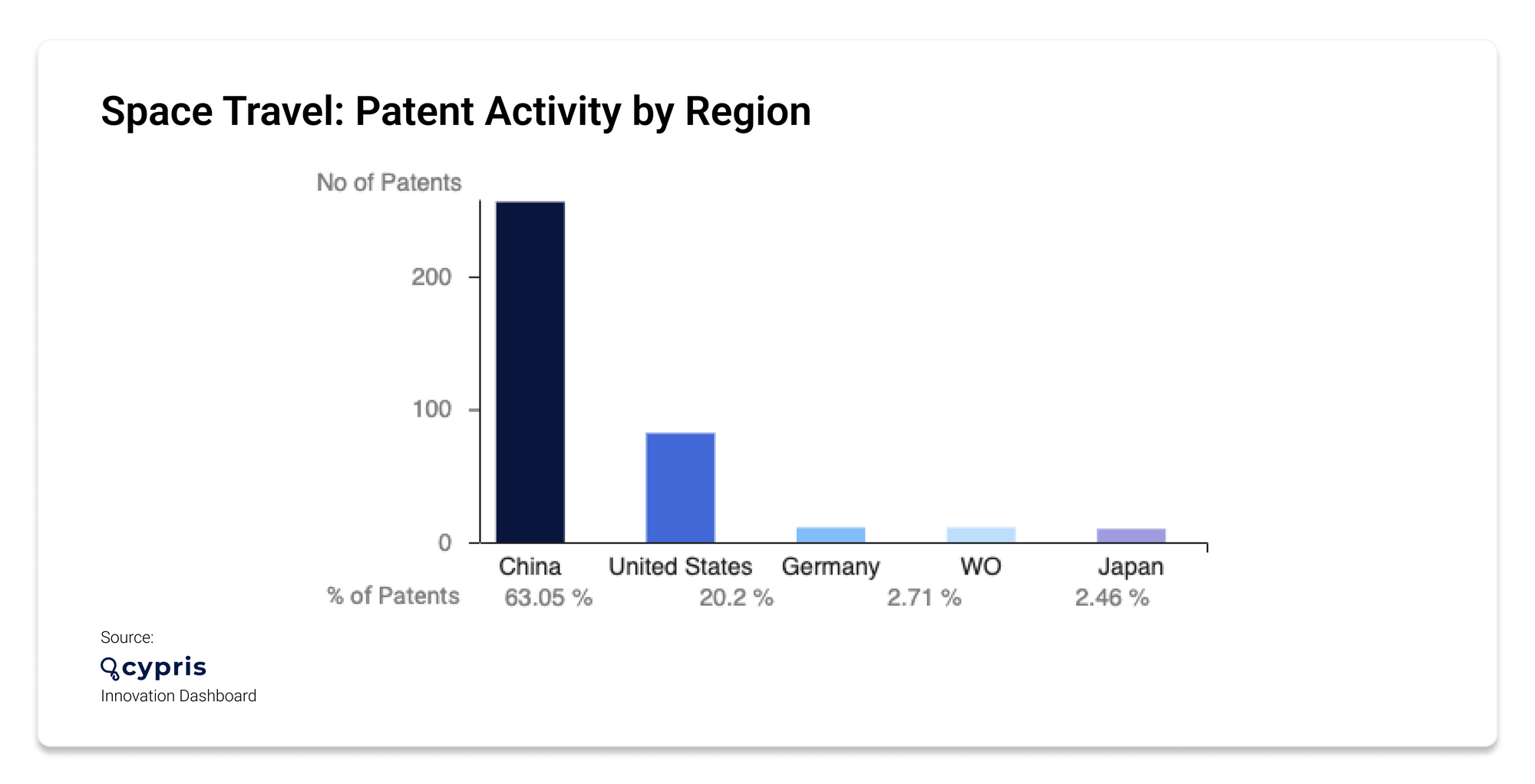
According to the Cypris Innovation Dashboard, over the past year alone, 15 new organizations entered the space travel industry (13 of which were startups) and the majority were based in USA. The past year also saw 406 new patents across 22 different countries, 10,549 new research papers, and 26,156 news articles published in the space. The majority of news articles focused on new products, and across the board media coverage was positive.
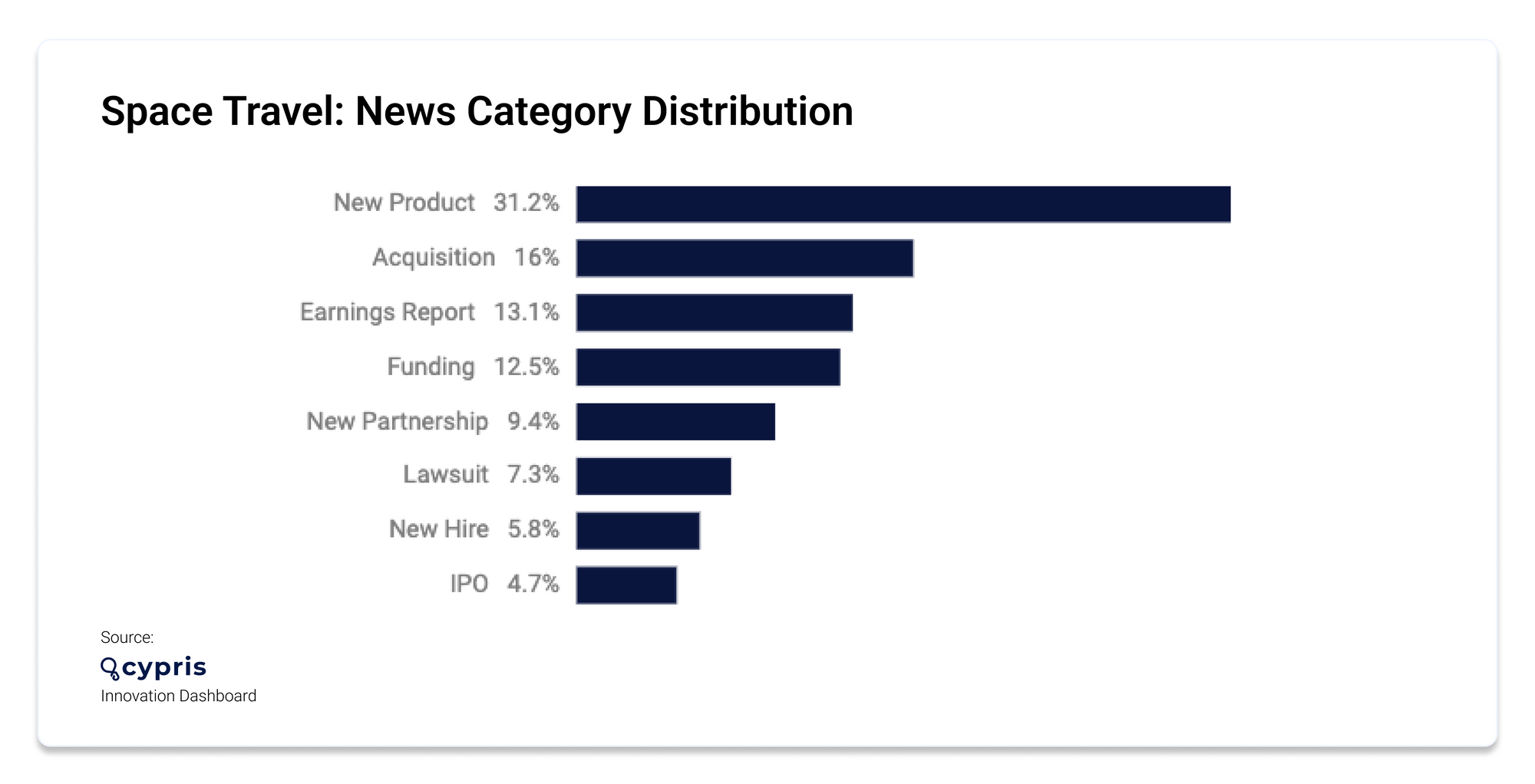
Of the patents published, 15.46% were created by the top 3 entities: NANJING SANLE GROUP CO LTD, ANHUI HUADONG PHOTOELEC TECH, and EMULATE INC. Below, you can see the breakdown of patent activity by region.
In the recent months, a number of new scientific studies have been released on efforts to make life in outer space habitable for human beings, and the impact of travel on the body and brain. Let's dive into a few of these findings.
Creating Oxygen in Space Using Magnets:

Researchers at the University of Warwick have invented a new way to make oxygen for astronauts using magnets. To provide oxygen in space, NASA currently uses centrifuges, which are large machines that require significant mass, power, and maintenance. As a result, scientists have been looking for a sustainable way to create air in space.
This study focused on the phenomenon of magnetically-induced buoyancy. The researchers engineered a procedure to detach gas bubbles from electrode surfaces in microgravity environments at the Bremen Drop Tower. The results revealed for the first time that gas bubbles can be ‘attracted to’ and ‘repelled from’ a neodymium magnet in microgravity within various solutions.
According to Dr. Katharina Brinkert of the University of Warwick Department of Chemistry Center for Applied Space Technology and Microgravity (ZARM), “Efficient phase separation in reduced gravitational environments is an obstacle for human space exploration and known since the first flights to space in the 1960s. This phenomenon is a particular challenge for the life support system onboard spacecraft and the International Space Station (ISS) as oxygen for the crew is produced in water electrolyzer systems and requires separation from the electrode and liquid electrolyte.”
The results of this study could help generate breathable atmospheres for future space travel to the moon and Mars.
Space Travel’s Impact on the Body's Bone Mass & Stem Cells:

For those who stay in space for longer periods of time, the most prominent side effect is the loss of bone mass. New research now claims that living in space can also accelerate the process of bone aging, and irreparably damage bone structure.
The study assessed 14 male and three female astronauts, average age 47, whose missions ranged from four to seven months in space, with an average of about 5-1/2 months. The results showed that 1 year after their return from space, the astronauts on average exhibited 2.1% reduced bone mineral density at the tibia and 1.3% reduced bone strength. Nine of the 17 astronauts had not completely recovered a full year after returning from space.
"Astronauts experienced significant bone loss during six-month spaceflights - loss that we would expect to see in older adults over two decades on Earth, and they only recovered about half of that loss after one year back on Earth," Gabel said.
Additionally, another recent study focused on 14 astronauts from NASA’s space shuttle program whose white blood samples were stored for 20 years. Researchers found that the astronauts were more likely to have somatic mutations in their genes. The DNA mutations in blood-forming stem cells are at the root of several types of blood cancer.
Space Travel’s Impact on the Brain:
We know that space travel impacts the body, but what does it do to the brain? In this study, 12 cosmonauts who spent an average of six months aboard the International Space Station were scanned in an MRI scanner pre-flight, ten days after flight, and at a follow-up time point seven months after flight.
The results revealed "significant microstructural changes" in the white matter that manages communications within the brain, and to and from the rest of the body, as well as fluid shifts. In particular, the research team spotted changes in neural tracts related to sensory and motor functions, and believe this could have something to do with the cosmonauts' adaptation to life in microgravity while in outer space.
Whether through creating oxygen in outer space, or studying how travel impacts the brain and body, significant advances are being made in the space travel industry. For more data on patents and innovative research papers in the space travel field, visit cypris.ai and get started with access to the innovation dashboard.
If you’d like to explore recent patents filed, you can search through our global patent search engine for free here: https://cypris.ai/patents/allrecords
Sources:
Cypris innovation dashboard cypris.ai ; Query: space travel
https://www.precedenceresearch.com/space-tourism-market
https://interestingengineering.com/science/first-researchers-invent-oxygen-magnets-space-exploration
https://www.nature.com/articles/s41526-022-00212-9
https://www.sciencedaily.com/releases/2022/07/220729173222.htm
https://www.nature.com/articles/s41598-022-13461-1
https://www.slashgear.com/946243/scientists-discover-space-travel-accelerates-aging/
https://www.frontiersin.org/articles/10.3389/fncir.2022.815838/full


The brain processes 70,000 thoughts each day using 100 billion neurons that connect at more than 500 trillion points through synapses that travel 300 miles/hour. More and more, scientific advances are breaking down what's really going on behind these numbers. In this blog, we'll look at innovation in the area of artificial brain cells specifically.
Groundbreaking advances in artificial brain cell research are bridging the gap between man and machine, and paving the way for life-changing advances. Innovation in the artificial brain cell space is skyrocketing—experiencing a 61.79% growth rate over the past 5 years. The fastest growing category is Medical with an 133.33% increase in new patents filed over the last 5 years. Additionally, the IT Computing and Data Processing category is seeing a lot of filings by new entrants, so it might be an emerging space worth looking into.
Let’s take a look at the recent research that’s transforming the artificial brain cell space.
Artificial Neurons & Dopamine

Researchers at Nanjing University of Posts and Telecommunications and the Chinese Academy of Sciences in China and Nanyang Technological University and the Agency for Science Technology and Research in Singapore recently developed an artificial neuron with the ability to communicate using the neurotransmitter dopamine. Dopamine is our feel-good neurotransmitter, involved in the brain’s reward system.
The research team built an artificial neuron that can both release and receive dopamine. The neuron was made using graphene and a carbon nanotube electrode, to which they added a sensor to detect dopamine and a device called a memristor. If enough dopamine is detected by the sensor, a component called a memristor triggers the release of more dopamine at the other end through a heat-activated hydrogel.
To test the ability of the artificial neuron to communicate, they placed it in a petri dish alongside rat brain cells and found that the neuron was able to sense and respond to dopamine created and sent by the rat brain cells. The artificial neuron was also able to product some of its own, which triggered a response in the rat brain cells. Additionally, their results revealed that they could activate a small mouse muscle sample by sending dopamine to a sciatic nerve, which they use to move a robot hand.
Reviving Deceased Animal Brains
In 2019, Yale scientists restored cellular function in 32 pig brains that had been deceased for hours. The team used a system called BrainEx, which consisted of computer-controlled pumps and filters that sent a nourishing solution through a dead, surgically exposed brain, with an ebb and flow that mimics the body's natural circulation. The proprietary solution was based on hemoglobin, the oxygen-ferrying protein in red blood cells, and was made to show up during ultrasound scans, to enable researchers to track its flow through the brain. The process was found to restore circulation and oxygen flow to a dead brain.
Continuing their research, the same team published findings this month on reviving pig organs, rather than just the brain. Researchers connected pigs that had been dead for one hour to a system called OrganEx that pumped a blood substitute throughout the animals’ bodies. The solution they circulated contained the animal’s blood, as well as 13 compounds including as anticoagulants — to slow the decomposition of the bodies and quickly restore some organ function. Although OrganEx helped to preserve the integrity of some brain tissue, researchers did not observe any coordinated brain activity that would indicate the animals had regained any consciousness or sentience.
Graphene Synapses

A team at The University of Texas at Austin just published their research on how they developed synaptic transistors for brain-like computers using the thin, flexible material graphene. These transistors are similar to synapses in the human brain. Synapses connect neurons in the brain to neurons in the rest of the body and from those neurons to the muscles.
Graphene and nafion, a polymer membrane material, were used to create the backbone of the synaptic transistor. These materials demonstrate the ability for the pathways to strengthen over time as they are used more often, a type of neural muscle memory. When it comes to computing, this means that devices will improve in their ability and speed to recognize and interpret images over time.
Notably, these transistors are biocompatible, which means they can interact with living cells and tissue. For medical devices that interact with the human body, biocompatibility is key. Currently, most materials used for these early brain-like devices are toxic, so they would not be able to contact living cells.
Whether through creating artificial cells capable of transmitting and receiving dopamine, or reviving deceased brain cells in pigs, research is transforming our relationship to technology, and our understanding of the brain. To learn more about patents and new innovations in the artificial brain cell space, visit cypris.ai and get started with access to the innovation dashboard.
Sources:
https://www.nytimes.com/2022/08/03/science/pigs-organs-death.html
https://www.health.harvard.edu/mind-and-mood/dopamine-the-pathway-to-pleasure
Ting Wang et al, A chemically mediated artificial neuron, Nature Electronics (2022). DOI: 10.1038/s41928-022-00803-0
https://www.nature.com/articles/d41586-022-02112-0
https://techxplore.com/news/2022-08-graphene-synapses-advance-brain-like.html
https://www.miragenews.com/graphene-synapses-advance-brain-like-computers-833930/
https://healthybrains.org/brain-facts/#:~:text=Your brain is a three,that travel 300 miles%2Fhour.

In recent years, a digital transformation of intimacy has taken place—the Internet has become the new matchmaker. Today, it's not uncommon for people to use dating apps and meet their significant other online. In fact, over 323 million people worldwide currently use dating apps.
With more and more people turning to online dating, technologies are being created for things like measuring emotional compatibility, facilitating blind dating, danger prevention, and more. In this blog, we'll look at innovation activity in the online dating market, as well as a few of the new technologies changing how we navigate relationships.
Market Overview:
Using the Cypris Innovation Dashboard, we identified innovation activity in the online dating market has grown over the last 5 years, with a 20.91% average growth rate. The top players in the market are Match Group, LLC, Match.com Europe, and e2interactive, Inc., which collectively own 16.9% of IP in the market.
The fastest growing category is Computing Software which saw an 27.92 % increase in new patents filed over the last 5 years, as well as a lot of filings by new entrants.
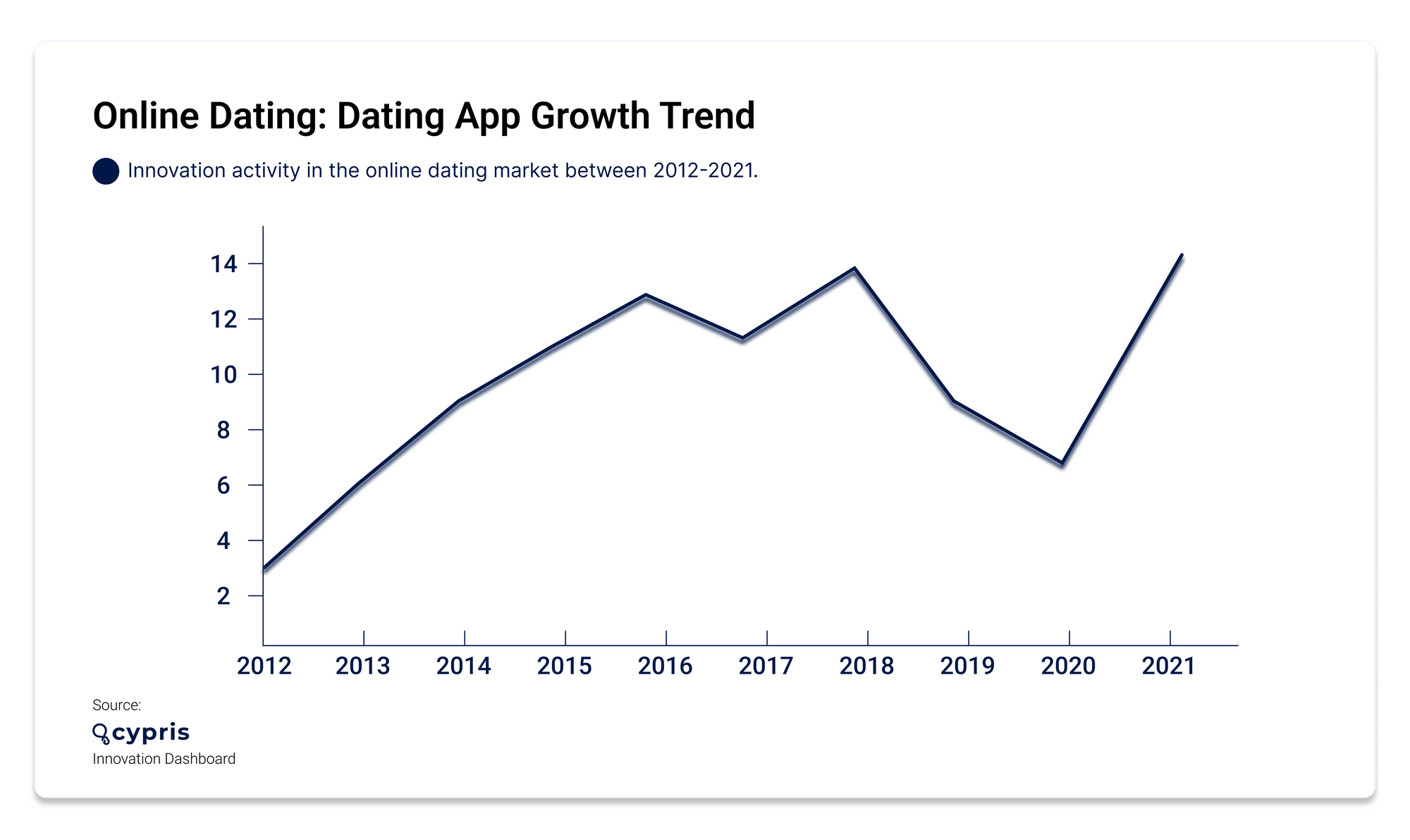
As of January 2022, Tinder dominated 32% of the U.S. market, followed by Bumble (22%), Hinge (15%), Plenty of Fish (15%), Grindr (7%), Badoo (6%), OKCupid (4%), Match.com (4%) and Zoosk (2%). In 2021, the dating app market made $5.61 billion revenue, with almost $3 billion made by Match Group.
Innovation in Online Dating
Let's dive into some of the fascinating patented technologies in the online dating space:
Method and Apparatus for Monitoring Emotional Compatibility in Online Dating: This patent covers methods, devices, and systems for capturing and sharing objective emotion data in dating interactions for the selection of suitable partners, or to enhance social dynamics in online interactions. An emotion monitoring device (EMD) measures physiological signals, obtained from biosensors, captured from a couple during a face-to-face or online dating interaction, and computes emotion data. The emotion data for each person is transmitted to an internet server, and each person shares their emotion data with the other during the interaction. The emotion data is then displayed to each person on a virtual or augmented reality device.
Inventor: Roger J. Quy; Patent Number: 20210267514

An Activity-Centric System and Method for Relationship Matching: This technology is for an online dating and relationship system that relies on common interests in, and arranging for specific face-to-face in-person activities. Potential activities are ranked by an activity ranking engine drawing on activity-related attributes of the users and of the activities. Mutual selection of an in-person activity enables the users to vet potential matches and to proceed to engage in the activity together. The ranking and match engines may take into account intrinsic user and activity attributes as well as activity- related attributes derived from the behavior of the users in relation to the activities.
Inventors: Perry Stevan, Stann Dominic, Petry James; Patent Number: WO2017054081A1
Online Dating Danger Prevention System: This patent covers an online dating danger prevention system. The online dating danger prevention system includes a database that holds information, including geo-location data and photographs, to make online dating safer. Users enter a set of contacts that the system can reach in the event of an emergency.
Inventors: Simard Marcellin; Patent Number: WO2015191090A1
Friend Matching Application: This patent includes a system and method for third-party matchmaking in an online or electronic dating app or system. A friend may review user profiles to select potential matches for another friend. Generating a match may require approval from one or more trusted users, or confirmation through a voting or similar mechanism. A user's matchmaking prowess may be ranked or scored based on success and accuracy. Matches may be anonymous or non-anonymous. A user desiring to be matched may seek out and request that a particular search user identify matches.

Inventor: Christopher Jordan Hurley; Patent Number: 20180130139
Dating Service with Restaurant Selection, Reservations, and Video Promotion Included: This patent covers a systematic method for securely setting up a date in online dating applications. The first step allows a requesting member to request a date with a requested member. Next, the requesting member can enter a meeting date, place, and time. The requested member will then be prompted to either accept or decline the date request from the requesting member. The method also provides a dating history database which records a members' dating history. In addition, a method of ensuring a member's safety by allowing members to choose to have someone contacted if the member does not update the dating history database after a date is disclosed.
Inventors: Stephone Belton; Patent Number: 20210287304
Systems and Methods for Initiating Conversations within an Online Dating Service: This technology is for a computer-implemented method for initiating conversations within an online dating service. It covers identifying a potential match for a user of an online dating service, automatically generating, in response to identifying the potential match, a customized interactive ice breaker widget that is customized to facilitate conversation between the user and the potential match, presenting the customized interactive ice breaker widget to the user, obtaining the user's response to the customized interactive ice breaker widget, and presenting, to the potential match, both the customized interactive ice breaker widget and the user's response to the customized interactive ice breaker widget to facilitate conversation between the user and the potential match.
Inventors: Qiang Wang, Nathan Andrew Sharp; Patent Number: 20200364806

Online Dating Service System: This patent covers an online blind date arranging service system and method that provides information on the opposite sex that can be connected by an acquaintance to a blind date applicant so that the other party can be verified through the acquaintance, and matchmaking can be arranged by an acquaintance.
Inventor: Kwon Nam Yeol; Patent Number: KR101759285B1
Whether through measuring emotional compatibility and setting up blind dates, or through danger prevention and matching based on mutual activity interests, technologies are transforming how we date. To learn more about patents and new innovations in the online dating space, visit cypris.ai and get started with access to the innovation dashboard.
If you’d like to explore recent patents filed, you can search through our global patent search engine for free here: https://cypris.ai/patents/allrecords
Sources:

In 2001, the tiny home trend emerged in the United States as an affordable and sustainable living alternative to traditional housing. Defined as less than 400 square feet, tiny homes are primarily full-time dwellings that can be permanent or mobile, on wheels or a skid [8]. The appeal? They require fewer resources, save on costs, and offer increased flexibility and mobility to tenants.
In this blog, we explore how the tiny home became popularized in the United States, how they’re changing the way we live, and the potential challenges living in a tiny home poses using research from the Cypris Innovation Dashboard.
The tiny home trend—how did it get here?
The current tiny housing trend as we see it in North America began when Jay Shafer founded the Tumbleweed Tiny House Company, the first company aimed specifically at producing designs for tiny houses in 2001. A tiny house enthusiast, Jay Shafer decided to start the company after helping others with design plans and implementation of tiny houses [7]. A year later, he founded the Small House Society alongside Greg Johnson, Shay Solomon, and Nigel Valdez [7]. Now, Tumbleweed is one of several companies building tiny homes made to order and deliver in the United States.
Over the years, the popularization of tiny homes has steadily increased. According to the Cypris Innovation Dashboard, innovation activity in the tiny home market has been, as a whole, growing over the last 5 years, with a 29.17% average growth rate. Today, the demand for alternative housing options like tiny homes is expected to increase, as housing prices climb.

How tiny homes are changing how we live.
The idea of intentionally downsizing ones living quarters begs the question: how much does a person need to live comfortably? Those who have chosen the tiny home lifestyle are working to change how they view what is “necessary” to live life. Of the many drivers that push people toward the tiny home life are a desire for cost-efficiency, a reduced impact on the environment, and a more mobile way of living which we explore more in-depth below.
Reduced Cost:
Tiny homes offer a unique solution to the lack of housing affordability. As the cost of conventional housing in the United States increases, the demand for tiny homes is expected to increase as well. Tiny homes in general are much cheaper to build and maintain. While many people can barely afford a down payment on a larger home, many tiny homes cost between $20,000 and $50,000 [10]. The general cost of living is also lower. One study found that a tiny homeowner is able to live on only $15,000 a year including luxuries such as a car, eating out, and comprehensive insurance [6]. As a result, people are left with more money to spend on things aside from housing costs.
Sustainable Living:
As the global population and urbanization continue to increase, so do consumption and our impact on the environment. Tiny homes are often viewed as a solution to unsustainable development, a building option that reduces the impact on the environment. While efforts have been taken in recent decades to improve energy efficiency in housing, the residential sector still contributes a significant proportion of global greenhouse gas (GHG) emissions [2]. Buildings account for over 1/3 of global energy use and nearly 40% of GHG emissions [2]. Studies indicate that there is a direct correlation between house size and operational energy use [1,4]. In the United States, the average size of a single-family home has doubled since 1950, leading to a profound environmental impact [11]. With their smaller size, tiny homes offer an ideal solution to reducing energy use and environmental impact. One particular tiny home study found that on a per capita basis, tiny homes lead to at least a 70% reduction in life cycle GHG emissions compared to a traditional house [2].
Freedom and Mobility:
Since the onset of COVID-19, remote work has become increasingly popular. Statistics on remote workers reveal that more than 4.7 million people work remotely at least half the time in the United States, while 16% of companies globally are fully-remote [12]. Remote workers are typically less stressed, and maintain a better work-life balance. Fewer people commuting to offices also means fewer cars on the road, which contributes to reducing greenhouse gas emissions. As more and more people gain the ability to work from anywhere, they can also decide the live anywhere. Tiny homes facilitate easy movement— instead of packing up things and finding someone to care for your home, you can just hitch your home to a trailer and go [7].
The challenges of tiny homes.
Many tiny homeowners face legality issues, primarily due to zoning restricting mobile homes. Municipalities also often have minimum size limits for habitability [7] typically between, 850 and 1,800 square feet (roughly 79 to 167 square meters) which can pose a challenge.
“Zoning regulations, restrictive covenants (i.e. provisions in the deed for the property that restrict the way the property may be used by the owners) and design standards for specific subdivisions, and even mortgage banking requirements can significantly limit options for creating small, space-efficient, single-family houses” [11].
As a result, many choose to build tiny homes on trailers, subjecting them to different restrictions than stationary homes [11]. However, this practice can be challenging since in some areas they are considered part-time residences.
Despite their issues, tiny homes provide a unique way of living that can save on costs, reduce environmental impact, and improve mobility. As housing costs and the focus on sustainable living continue to increase, innovation and adoption in the tiny home space will continue to grow.
For more insights on the tiny home space or another research area, please visit cypris.ai to get started using the Innovation Dashboard and gain access to 500M+ global data points.
Sources:
- Clune S, Morrissey J and Moore T (2012) Size matters: House size and thermal efficiency as policy strategies to reduce net emissions of new developments Energy Policy 48 657–667
- Crawford, R H, and A Stephan. "Tiny House, Tiny Footprint? The Potential For Tiny Houses To Reduce Residential Greenhouse Gas Emissions". IOP Conference Series: Earth And Environmental Science, vol 588, no. 2, 2020, p. 022073. IOP Publishing
- Foreman, P.; Lee, A.W. (2005). A tiny home to call your own: Living well in just write houses. Buena Vista, VA: Good Earth Publications.
- Guerra Santin O, Itard L and Visscher H (2009) The effect of occupancy and building characteristics on energy use for space and water heating in Dutch residential stock Energy and Buildings 41(11) 1223-1232
- Krista Evans (2020) Tackling Homelessness with Tiny Houses: An Inventory of Tiny House Villages in the United States, The Professional Geographer, 72:3, 360-370, DOI: [10.1080/00330124.2020.1744170]
- Mitchell, R. (2013, April 3). How Little Can You Live On?
- Mutter, Amelia (2013) Growing Tiny Houses Motivations and Opportunities for Expansion Through Niche Markets. iiiee.
- Shearer H and Burton P 2019 Towards a typology of tiny houses Housing, Theory and Society 36(3) 298-318
- Wagner, Ron '93 (2018) "Tiny Houses, Big Dreams,"Furman Magazine: Vol. 61: Iss. 1 , Article 20.
- Wax, E. (2012, November 28). Home, squeezed home: Living in a 200-square-foot space, The Washington Post.
- Wilson, A., & Boehland, J. (2005). Small is beautiful - US house size, resource use, and the environment. Journal of Industrial Ecology, 9(1-2), 277-287.
- [https://www.apollotechnical.com/statistics-on-remote-workers/#:~:text=Statistics on remote workers reveal,to an Owl labs study]
- Cypris Innovation Dashboard; Query: Tiny + Houses; https://cypris.ai

Carbon dioxide (Co2) is one of the atmospheric "greenhouse gases" that absorbs and radiates heat gradually over time and contributes to the natural warming of the Earth known as the greenhouse effect. Notably, increases in atmospheric CO2 are responsible for about 2/3 of the total energy imbalance that is causing Earth's temperature to rise.
The built environment generates nearly 50% of annual global CO2 emissions. Of those total emissions, building operations are responsible for 27% annually, while building materials and construction are responsible for an additional 20% annually.
As a result, measures are being taken to create structures and building materials that are carbon-neutral, and even carbon negative, to reduce the amount of CO2 in the atmosphere. One such project was announced this week by the U.S. Department of Energy.
About the project
The U.S. Department of Energy (DOE) announced Monday that it is awarding $39 million in grants, primarily to universities, for 18 projects seeking to develop technologies that can transform buildings into net carbon storage structures.
The awards are part of DOE’s Harnessing Emissions into Structures Taking Inputs from the Atmosphere (HESTIA) program, and will prioritize overcoming barriers associated with carbon-storing buildings, including scarce, expensive, and geographically limited building materials. The overarching goal is to increase the amount of carbon that can be stored in buildings so they become “carbon sinks”— materials or processes that absorb more carbon from the atmosphere than they release. The decarbonization goals for this program fall in line with President Jo Biden’s call for the federal government to reach net-zero emissions by 2050.
Why it's significant
Of the greenhouse gases, carbon dioxide is known to absorb less heat per molecule than the greenhouse gases methane or nitrous oxide, be more abundant, and stay in the atmosphere much longer. When it comes to how CO2 factors into buildings, the DOE reports that greenhouse gas emissions associated with material manufacturing and construction, renovation and disposal of buildings at the end of their service life are concentrated at the start of a building's lifetime. As a result, it's important to address greenhouse gas emissions when it comes to materials, design, and building techniques.
According to U.S. Secretary of Energy Jennifer M. Granholm, “There’s huge, untapped potential in reimagining building materials and construction techniques as carbon sinks that support a cleaner atmosphere and advance President Biden’s national climate goals. This is a unique opportunity for researchers to advance clean energy materials to tackle one of the hardest to decarbonize sectors that is responsible for roughly 10% of total annual emissions in the United States.”
Who’s working on the project
The teams are comprised of universities, private companies, and national laboratories, and will develop and demonstrate building materials and net carbon negative whole-building designs. HESTIA project titles, locations, and award amounts are listed below. For more detailed information on each project, visit HESTIA project descriptions.
- National Renewable Energy Laboratory – Golden, CO; High-Performing Carbon-Negative Concrete Using Low Value Byproducts from Biofuels Production - $1,749,935
- Texas A&M University – College Station, TX; Hempcrete 3D Printed Buildings for Sustainability and Resilience - $3,742,496
- University of Colorado Boulder – Boulder, CO; A Photosynthetic Route to Carbon-Negative Portland Limestone Cement Production - $3,193,063
- University at Buffalo – Buffalo, NY; Modular Design and Additive Manufacturing of Interlocking Superinsulation Panel from Bio-based Feedstock for Autonomous Construction - $2,179,852
- University of Pennsylvania – Philadelphia, PA; High-Performance Building Structure with 3D-Printed Carbon Absorbing Funicular Systems – $2,407,390
- National Renewable Energy Laboratory – Fairbanks, AK; Celium: Cellulose-Mycelium Composites for Carbon Negative Buildings/Construction - $2,476,145
- Pacific Northwest National Laboratory – Richland, WA; The Circular Home: Development and Demonstration of a Net-Negative-Carbon, Reusable Residence - $2,627,466
- Oregon State University – Corvallis, OR; Cellulose Cement Composite (C3) for Residential and Commercial Construction - $2,500,000
- Oak Ridge National Laboratory – Oak Ridge, TN; Renewable, Carbon-negative Adhesives for OSB and Other Engineered Woods - $1,098,000
- University of Wisconsin-Madison – Madison, WI; Carbon-Negative Ready-Mix Concrete Building Components Through Direct Air Capture - $2,256,250
- Northeastern University – Boston, MA; 4C2B: Century-scale Carbon-sequestration in Cross-laminated Timber Composite Bolted-steel Buildings - $3,150,000
- Purdue University – West Lafayette, IN; Strong and CO2 Consuming Living Wood for Buildings - $958,245
- University of Tennessee-Knoxville – Knoxville, TN; Lignin-derived Carbon Storing Foams for High Performance Insulation - $2,557,383
- Clemson University – Clemson, SC; An Entirely Wood Floor System Designed for Carbon Negativity, Future Adaptability, and End of Life De/re/Construction - $1,042,934
- Aspen Products Group – Marlborough, MA; High Performance, Carbon Negative Building Insulation - $1,152,476
- BamCore – Ocala, FL; Maximizing Carbon Negativity in Next Generation Bamboo Framing Materials - $2,230,060
- SkyNano – Knoxville, TN; CO2mposite: Recycling of CO2, Carbon Fiber Waste, and Biomaterials into Composite Panels for Lower Embodied Carbon Building Materials - $2,000,000
- Biomason – Durham, NC; Soteria - Carbon Negative Bioconcrete Unit Production Concept - $1,812,118
Given the funding the DOE is devoting to decarbonization technologies, it's safe to say that research and investment into the area is on the rise. According to our data, there are 1584 players in the market operating across 3723 technologies. To learn more about innovation activity in the decarbonization space, visit cypris.ai and get started with access to the innovation dashboard.
Sources:

We are in the midst of the biggest wave of urbanism in human history. Today, more than 4.3 billion people or 55% of the world’s population live in urban settings. By 2050, the share of the world’s population living in cities is expected to rise to 80% (World Economic Forum).
With more people concentrated in urban areas, cities must adapt to new challenges when it comes to infrastructure, housing, material consumption, accessibility, sustainability, and much more. In this blog, we’ll look at new innovations that have emerged to combat new challenges cities are facing.
Market Overview
Using the Cypris innovation dashboard, we identified innovation activity in the urban development market has grown over the past 5 years, with a 62.5% average growth rate. Within the vertical, there are 392 technologies being applied within 38 different categories. The fastest growing category is Signaling with an 125.0% increase in new patents filed over the last 5 years.
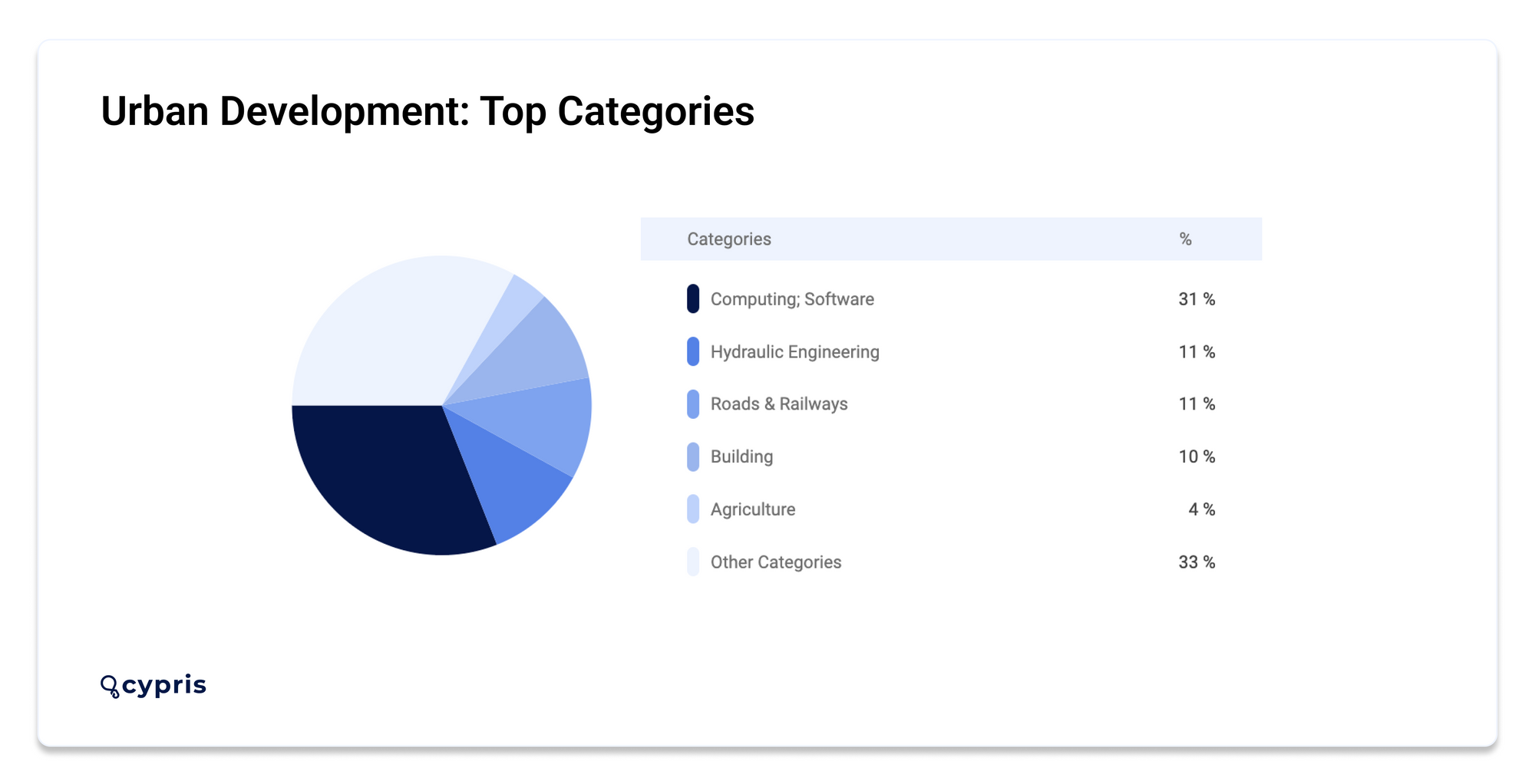
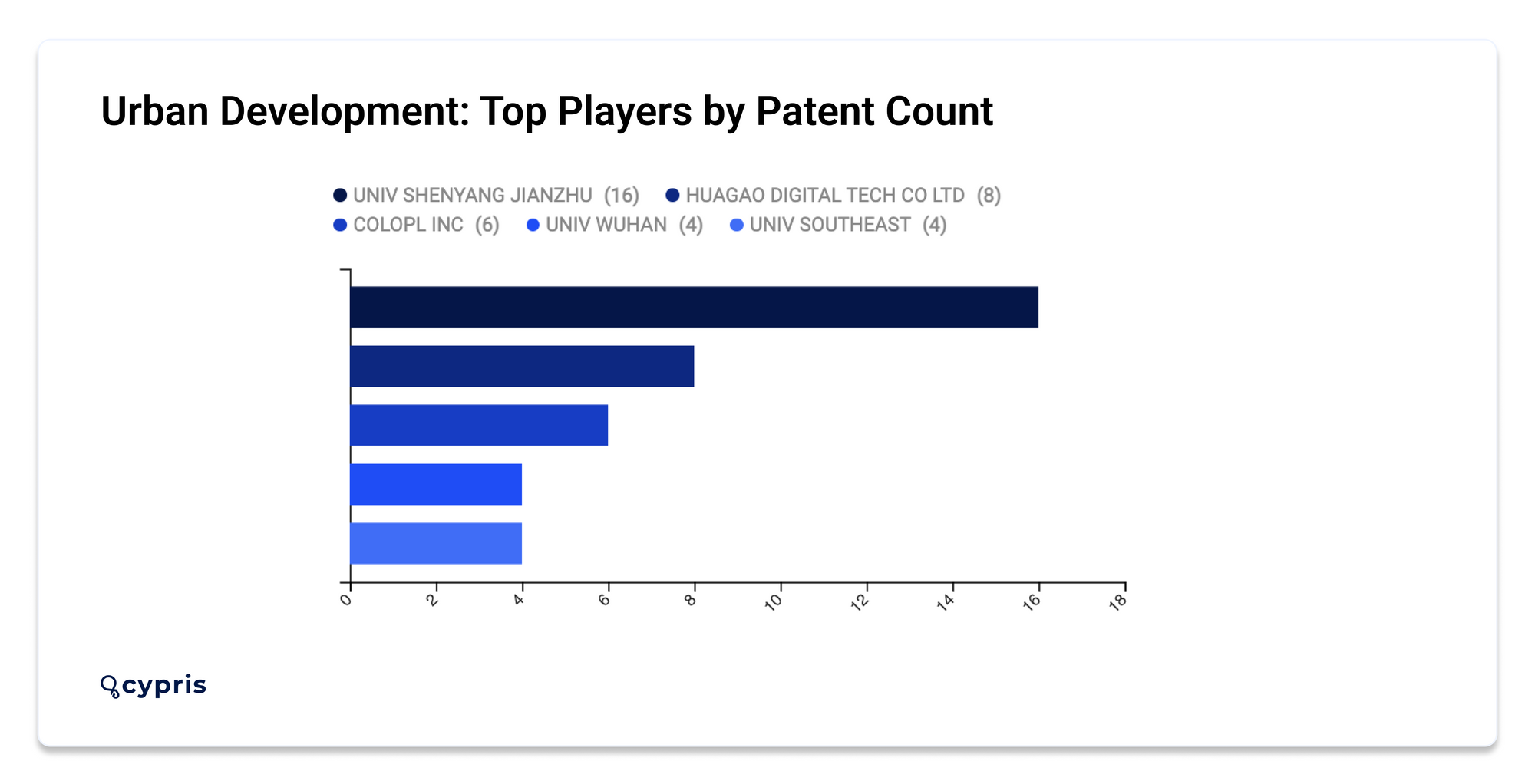
The most active top players in Urban Development by patent number include UNIV SHENYANG JIANZHU (16), HUAGAO DIGITAL TECH CO LTD (8), and COLOPL INC (6).
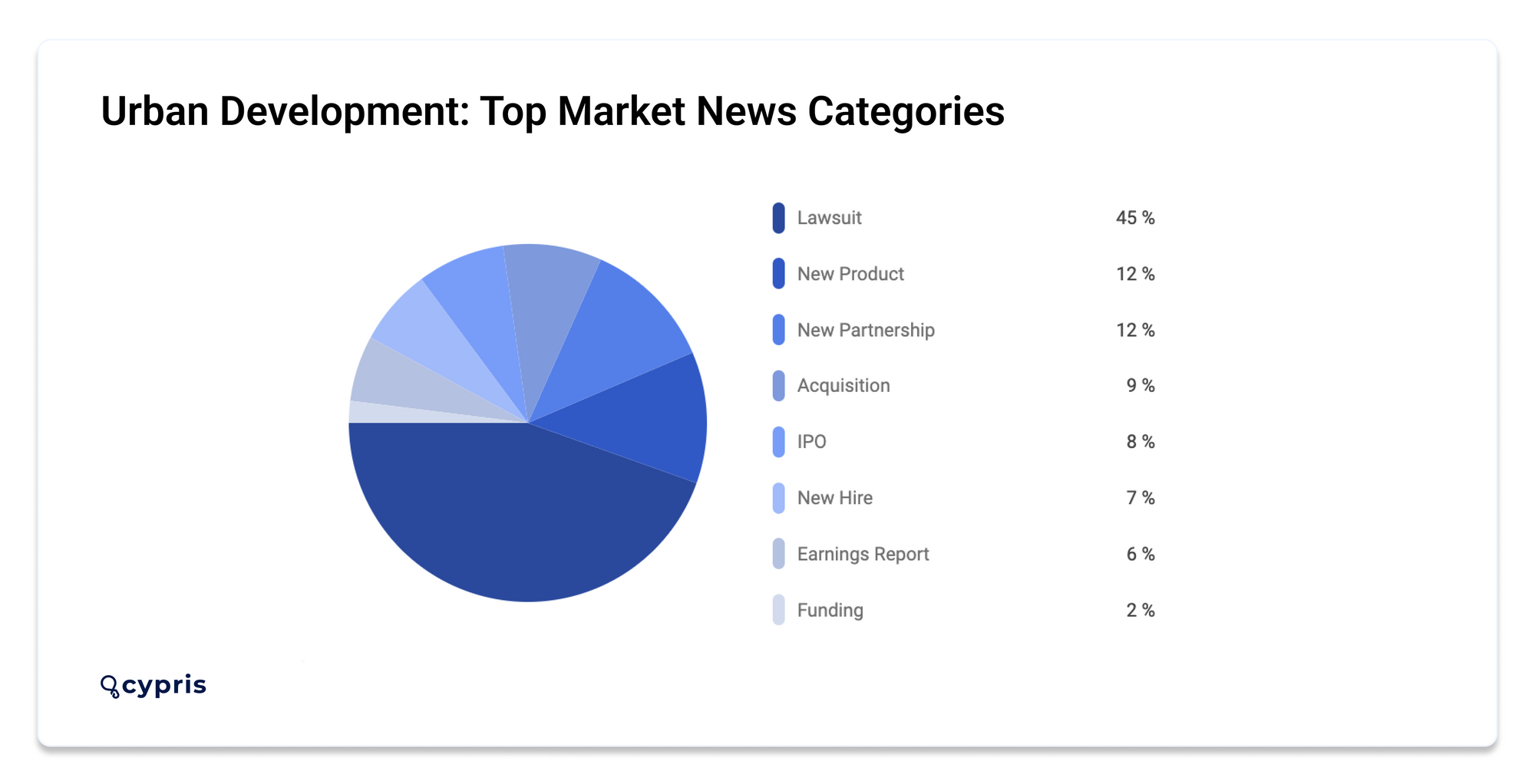
Market news in the space is dominated primarily by lawsuits (45%), followed by new products (12%) and new partnerships (12%).
Notably, while diving into urban development market news, we discovered that Google released a new tool that provides real-time land cover data called Dynamic World, created in partnership with global nonprofit organization World Resources Institute (WRI). Prior to its creation, it was difficult to access detailed and up-to-date land cover, across land and water types. Dynamic World reveals how the earth’s surface is changing from various activities, and allows viewers to track land cover changes from environmental factors, like floods and snowstorms, and changes induced by human activity like urban development and deforestation. The tool will help generate awareness around issues facing the planet, and equip scientists, environmental researchers, policymakers, and the general public with the information to better understand environmental disturbances and plan for future disasters.
Innovative Patents in Urban Development
Here are 5 of the most fascinating patents within the urban development space:
Method for constructing artificial islands with reefs from urban construction waste: This invention provides a 5-step method for constructing artificial islands with reefs from urban construction waste. The method includes 1) recycling the urban construction waste; 2) bonding and pouring the urban construction waste by the aid of cement to obtain large cement brick specimens; 3) transporting the cement specimens to coastal regions by the aid of unidirectional logistics empty materials; 4) transporting the cement specimens to the reefs; and 5) constructing the islands by the aid of cement bricks in falling tide periods.
Inventors: WANG XIAOJIN, & LAI BINGHONG; Patent #: CN103882831A
Roadside dedicated to people with reduced mobility: This invention is a curb specially designed to facilitate movement on the sidewalk for people using wheelchairs and the blind or visually impaired. The invention makes it possible to guide the wheels of a wheelchair, and protect pedestrians from cars. The regularly spaced outfalls in the invention contain a slight slope in order to evacuate rainwater as well. This invention can be precast in concrete and is particularly intended for road and urban development projects in the building and public works industry.
Inventor: GILLET ENGUERRAN; Patent #: FR3115300A1
Underwater Two-Level Tunnel in the Zone of Dense Urban Development: This patent is an underwater two-level tunnel designed for a dense urban area. The tunnel consists of a main two-tier tunnel with separate traffic lanes located inside and additional branches connecting the main tunnel with its terminals located on road sections of the road network adjacent to the tunnel. A second level in the main tunnel and the presence of at least one lane of free movement helps to eliminates the intersection of additional branches and the need to build traffic interchanges.
Inventor: Unlisted; Patent #: RU196900U1
Container House: This invention is a prefabricated transportable container house with a foundation of stainless steel pipe bodies that helps with earthquake and hurricane resistance. Mega structures with numerous container homes can be used when stacking of two or more container homes is insufficient and large-scale urban development is required, and they'll be able to withstand earthquakes and hurricanes due to a net-cladding system of wire.
Inventor: KANGNA NELSON SHEN; Patent #: BR112012010096A2
Solar pedestrian overpass: This patent is a solar pedestrian overpass which comprises a connecting column, a sliding groove formed in the outer wall of the connecting column, four solar panels arranged in the sliding groove, and an output port formed in the end face of the upper end of the connecting column. The bottom surface of the connecting column and the solar panel at the lowermost layer are positioned on the same horizontal plane.
Inventor: LING JIEYONG; Patent #: CN211815496U
Whether through sustainability initiatives, mobility and accessibility efforts, or structures made more resistant to natural disasters, new innovations are changing how we plan and create cities. To learn more about patents and new innovations in the urban development space, visit cypris.ai and get started with access to the innovation dashboard.
Sources:
Cypris Innovation Dashboard, Query: Urban Development
https://cypris.ai/patents/detail/roadside-dedicated-to-people-with-reduced-mobility/FR3115300A1
https://cypris.ai/patents/detail/solar-pedestrian-overpass/CN211815496U
https://www2.deloitte.com/xe/en/insights/industry/public-sector/future-of-cities.html
https://www.futuresplatform.com/blog/3-trends-driving-future-cities-and-urban-living
https://www.weforum.org/agenda/2022/04/global-urbanization-material-consumption/

Competitive Intelligence (CI) is the process of analyzing, gathering, and using information collected on competitors, customers, and other market factors that contribute to your competitive advantage. Companies rely on CI data to develop effective and efficient business practices.
CI consists of two types of intelligence: tactical and strategic. Tactical is shorter-term intelligence, which seeks to provide input into issues like capturing market share or increasing revenues, while strategic focuses on longer-term issues, like key risks and opportunities facing the organization, and emerging trends and patterns.
Why competitive intelligence matters, particularly real-time CI.
Understanding competitor motivations and behaviors is critical to driving innovation, shaping product development, establishing pricing and brand positioning, and so much more. Companies must collect proper CI in order to identify challenges, advantages, and white spaces and build a competitive strategy equipped to compete and thrive.
Technology has transformed the CI industry, making it possible for organizations to compile data from multiple sources in a timely manner to facilitate rapid decision-making. Through actionable insights, companies can respond to changes in their markets quickly to keep up with competition. At the core of actionable insights is real-time CI. With real-time CI, companies deliver timely intelligence to the right people, increasing organizational agility.
When looking to collect CI, it’s important to plan out which insights are of value to you, how to identify your competitors, and which markets to spend time on. Take time to narrow in on your direct competitors, research objectives, and areas of interest.
Are companies focusing on CI? These metrics might surprise you.
90% of Fortune 500 companies practice competitive intelligence. (Source: Emerald Insight)
Over 73% of businesses are investing more than 20% of overall technology budgets on intelligence and data analytics. (Source: Forbes)
61% of executives view rapid decision-making and execution as essential factors for a company’s success, and 34% consider the ability to access the right information at the right time as key factors for a company’s success. (Source: The Economist)
69% of organizations that have used an external partner to gain better data insight report positive results from that decision. (Source: The Economist)
57% of companies state that gaining a competitive advantage is one of the top 3 priorities in their industry. (Source: Forbes)
The 6 ways CI benefits your organization.

CI empowers everyone on teams, from product managers and marketers, to sales and executive teams. With the right CI, you can:
Uncover Key Data Points: Through examining new data points like significant acquisitions, new patent filings, startup investments, technology transfer agreements, research papers, etc., you can uncover pivotal data points that have the potential to influence major decisions.
Plan Strategic Moves: CI facilitates building your long-term business strategy and finding market gaps, allowing you to make the right business decisions for your organization.
Track industry Trends: Live-data CI lets you watch for new technologies, track new movement, stay on top of industry innovation trends, and predict future movement.
Drive Innovation: CI helps you to identify new market opportunities and spaces to innovate, accelerate your new product development, design better products, and improve market positioning.
Outsmart Competition: Think of CI as competitive insurance to ensure you stay on top of competitor strengths and weaknesses, anticipate what they’re planning, and identify competitor position and messaging. With CI you can uncover new product launches and services your competitors are adding, and benchmark your company against others.
Minimize Risk: Making the wrong move is costly. CI helps you prevent unsuccessful projects from taking off, save on costs, and improve decision-making ROI. With CI data, you can identify and prioritize any gaps within your business, and feel comfortable knowing you're making data-backed decisions.
Where to go from here: Actionable intelligence platforms are here to help.
Manually collecting CI takes time, and is costly. Not to mention doing your own research digging on the Internet for low-hanging fruit means you'll likely miss key data points that don't provide you with the whole picture. In the time it takes traditional market intelligence or research analysts to gather data to build into basic and applied research reports, you can receive data automatically through a platform like Cypris.
Designed specifically to deliver actionable innovation intelligence to R&D teams, Cypris improves the efficiency of data collation and interpretation. By aggregating your desired data, Cypris enables users to answer critical questions that influence the brand, margin, and profitability of your organization. Users have identified new entrants, significant IP, groundbreaking research papers, and more that have ultimately swayed the course of major projects.
Ready for real-time data on your competitors? Visit cypris.ai to get started by booking a demo.
Sources:
https://www.jimmynewson.com/10-important-competitive-intelligence-statistics/
https://www.gartner.com/en/information-technology/glossary/ci-competitive-intelligence
https://www.antara.ws/en/blog/competitive-intelligence-benefits-for-the-company

.avif)