
Insights on Innovation, R&D, and IP
Perspectives on patents, scientific research, emerging technologies, and the strategies shaping modern R&D

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
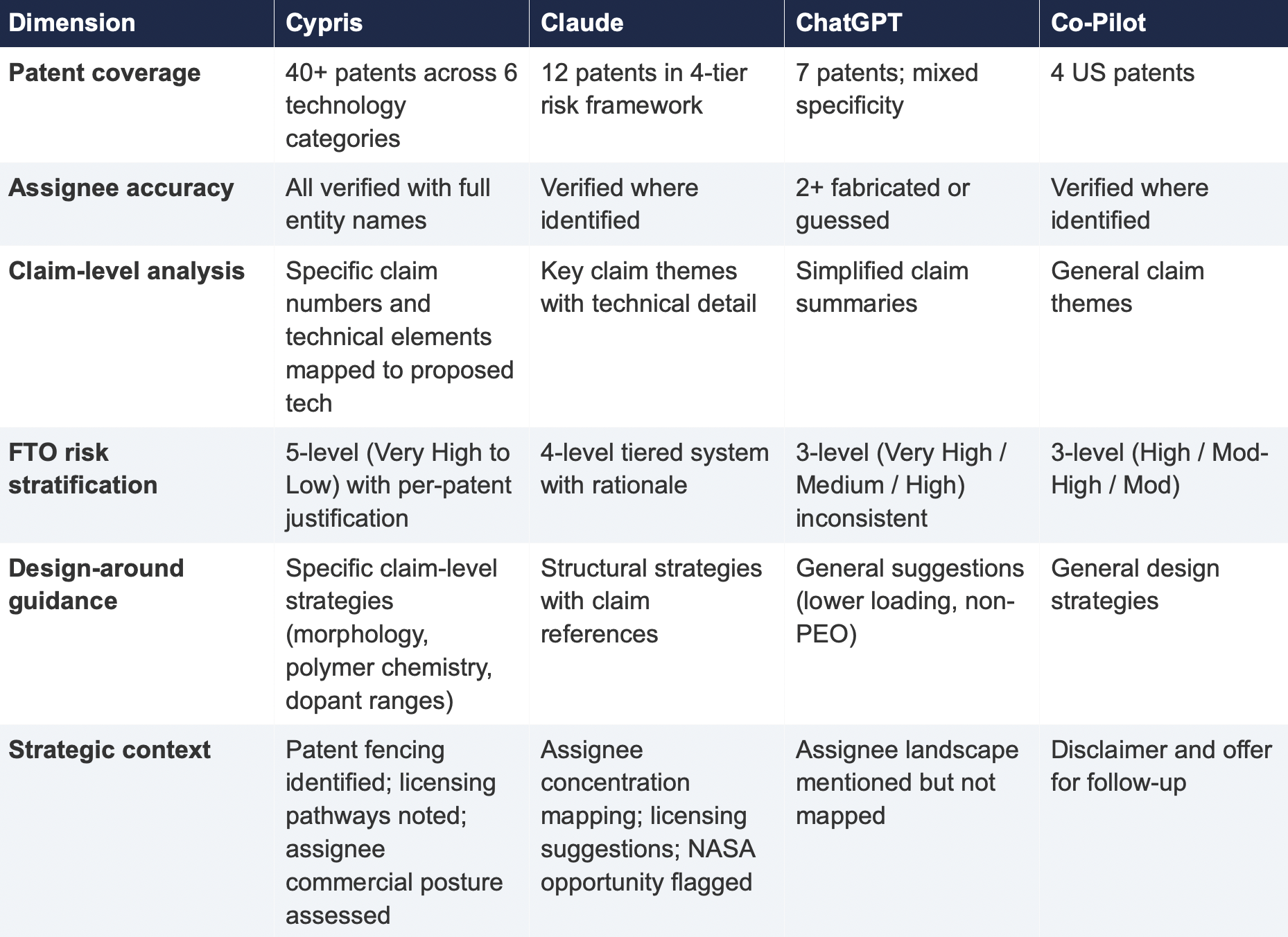
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
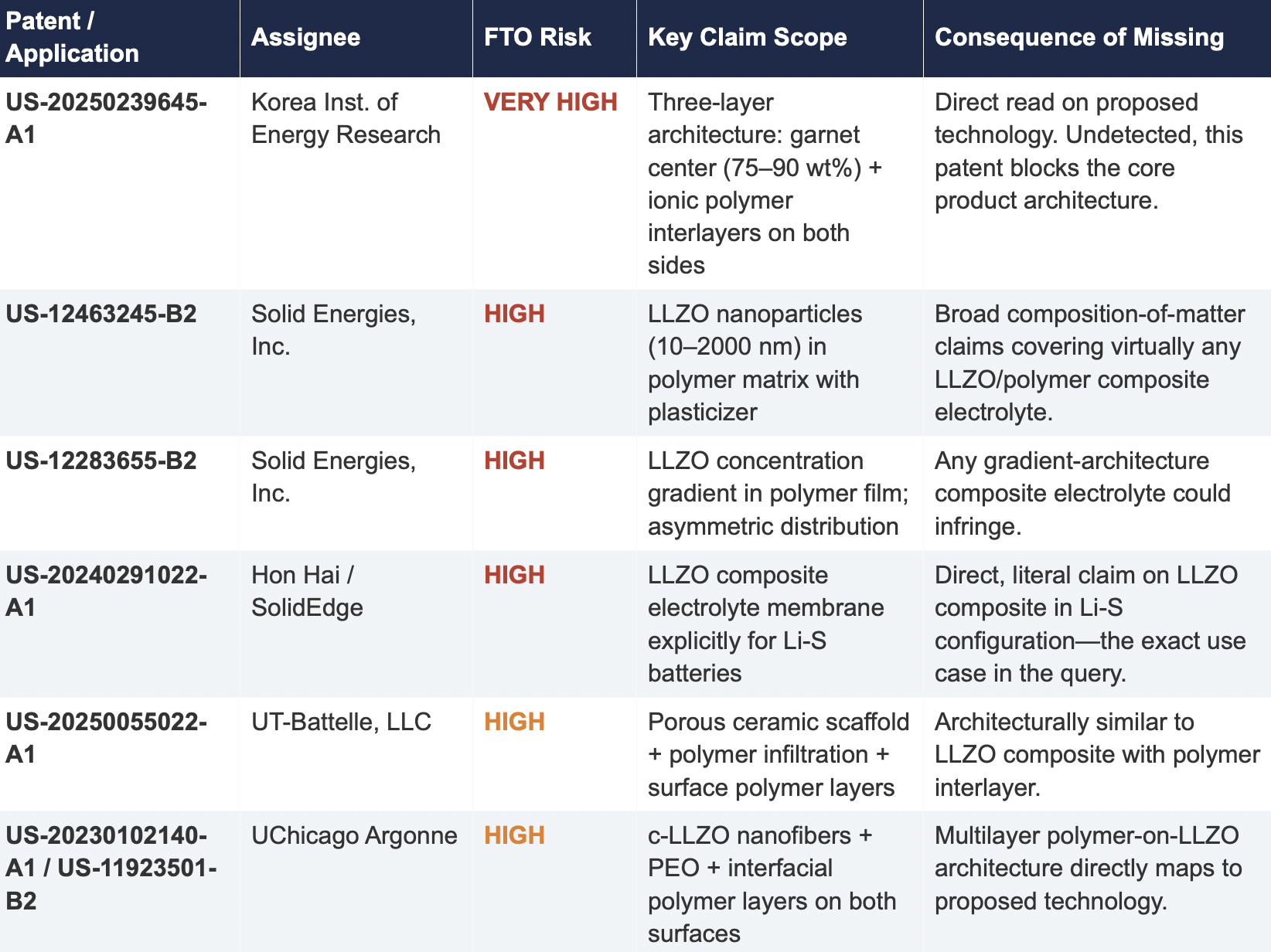
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

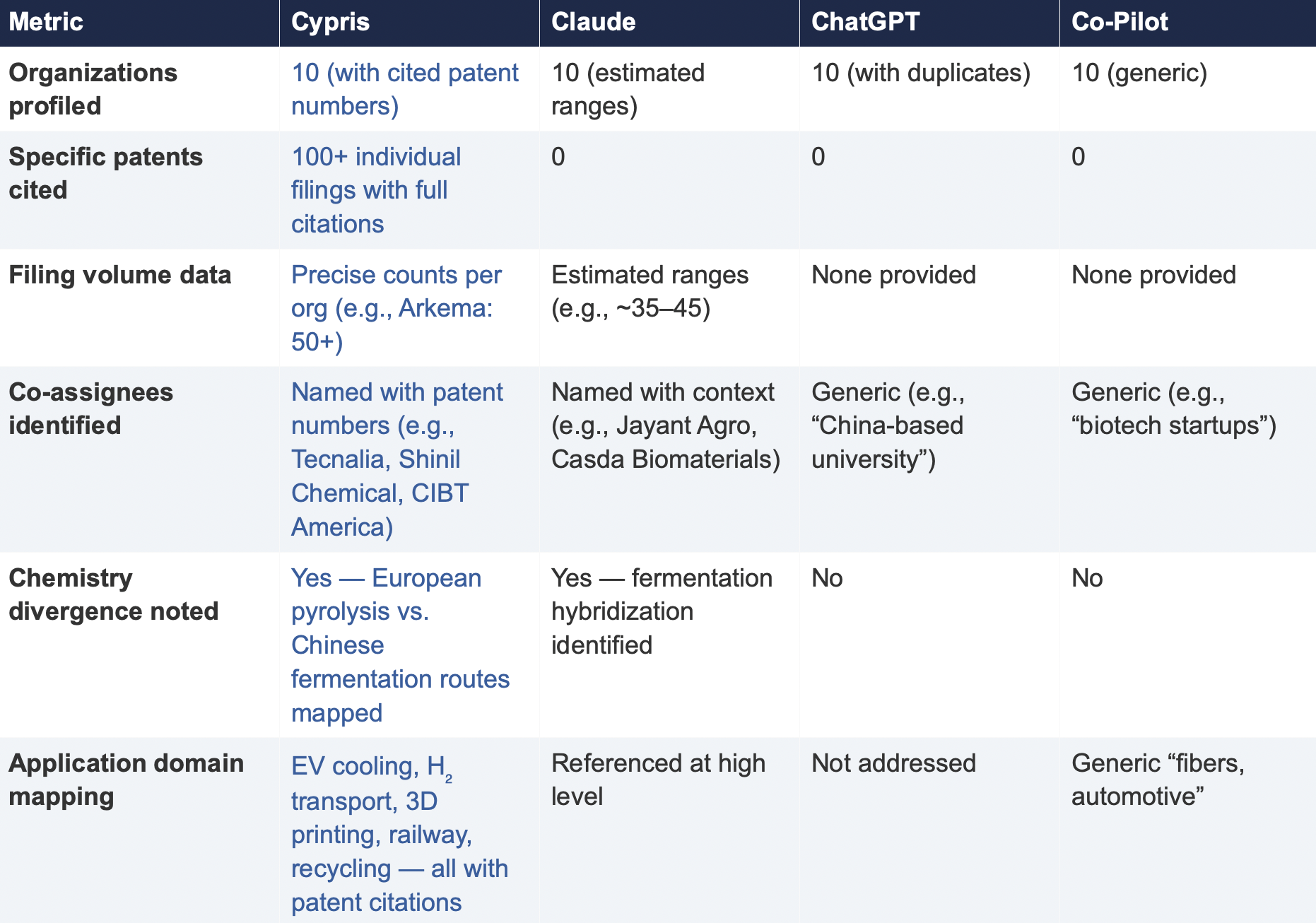
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
All Blogs

The freedom-to-operate search has always been one of the most consequential exercises in product development. Before a company commits significant capital to manufacturing, marketing, or licensing a new technology, it must determine with reasonable confidence that bringing the product to market will not infringe the valid and enforceable patent rights of a third party. That determination has never been simple, but the scale of the challenge in 2026 has grown to a point where traditional methods alone are no longer sufficient, and the rapid proliferation of general-purpose AI tools has introduced both new capabilities and new sources of confusion about what actually constitutes a defensible FTO workflow.
The Scale Problem: Why Traditional FTO Methods Are Breaking Down
The volume of global patent data is the first and most visible challenge. Innovators around the world filed 3.7 million patent applications in 2024, marking a 4.9 percent increase over 2023 and the fastest year-on-year growth since 2018 (1). Patents in force worldwide grew 6 percent in 2024 to reach an estimated 19.7 million (2). These are not evenly distributed. China's share of global patent applications jumped from 34.6 percent in 2014 to 49.1 percent in 2024, accounting for nearly half of all worldwide filings (3). For any R&D team conducting an FTO search across multiple jurisdictions, the corpus to be searched is not merely large but growing at a compounding rate, with an increasing share published in Chinese and other non-English languages that keyword searches in English will systematically miss.
The problem extends beyond sheer volume. Patent claims are written in deliberately broad and often abstract language. A single claim may describe a concept using terminology that varies dramatically from how an engineer or scientist would describe the same concept in a lab notebook or product specification. Traditional Boolean keyword searches depend on the searcher anticipating every synonym, variant, and adjacent phrasing that a patent drafter might have used. In crowded technology fields where hundreds of applicants have filed on overlapping concepts, the combinatorial explosion of possible keyword strings makes exhaustive manual search functionally impossible.
Jurisdictional complexity compounds the problem further. An FTO search is always territorial. A product that is clear in the United States may face blocking patents in Europe, Japan, or China. Each jurisdiction has its own patent database, its own classification scheme, and its own rules about claim interpretation. A thorough FTO search must account for granted patents, pending applications that may issue with claims covering the product, and patent families that span multiple national and regional offices.
General-Purpose AI vs. Verticalized LLMs: A Critical Distinction
The arrival of powerful general-purpose large language models such as GPT-4, Claude, and Gemini has created a tempting shortcut for teams looking to accelerate FTO work. These models can summarize patent documents, suggest search terms, and even draft preliminary claim comparisons. But there is a fundamental difference between a general-purpose LLM that has been exposed to some patent text during pre-training and a verticalized model that has been purpose-built for patent and technical literature analysis, and conflating the two introduces real risk into FTO workflows.
General-purpose LLMs suffer from several structural limitations in the FTO context. They do not have access to live patent databases. They cannot verify the legal status of a patent. They are prone to hallucination, meaning they may generate plausible-sounding but factually incorrect claim interpretations or invent patent numbers that do not exist. And they lack the domain-specific training that allows them to understand how patent claim language maps to technical concepts with the precision that FTO analysis demands.
Verticalized LLMs, by contrast, are models that have been fine-tuned or trained from the ground up on patent corpora, scientific literature, and technical taxonomies. These models understand the particular conventions of patent drafting: how means-plus-function claims work, how dependent claims narrow the scope of independent claims, how prosecution history estoppel affects claim interpretation, and how the same invention can be described using entirely different vocabulary across jurisdictions and technology domains. When integrated into a purpose-built search platform with access to live, structured patent data, verticalized LLMs can perform semantic retrieval at a level of precision and recall that general-purpose models cannot match.
The practical implication for FTO practitioners is straightforward: general-purpose AI is useful for background research, brainstorming search strategies, and explaining technical concepts to non-specialist stakeholders, but it should never be the primary engine of an FTO search. The search itself must be powered by domain-specific AI operating on a verified, structured, and continuously updated patent corpus.
Semantic Search: Moving Beyond Keywords to Concepts
The single most impactful AI technique for FTO searches on large datasets is semantic search. Unlike Boolean keyword search, which matches exact text strings, semantic search uses natural language processing and machine learning to understand the conceptual meaning of a query and return results that are conceptually related even when the specific terminology differs. This directly addresses the vocabulary problem that plagues patent searching: the same invention can be described using entirely different words depending on the drafter, the jurisdiction, and the era in which the patent was filed.
With semantic search, attorneys running freedom-to-operate searches no longer need to enumerate every synonym up front, and R&D teams can explore adjacent technology spaces without mastering classification schemes (4). Semantic search engines trained on patent corpora can interpret an invention disclosure or a set of product claims and retrieve conceptually similar documents from across the entire global patent landscape, surfacing references that a keyword search would have missed entirely.
The effectiveness of semantic search depends heavily on the quality of the underlying model and the data on which it was trained. This is where the distinction between general-purpose and verticalized AI becomes most consequential. A semantic search engine powered by a model trained specifically on patent text will understand that "photovoltaic energy conversion apparatus" and "solar cell" refer to the same concept, that "computing device" in one patent family may correspond to "mobile terminal" in another, and that a claim reciting a "plurality of elongated members" might cover the same structure as one describing "an array of fins." General-purpose embeddings miss these domain-specific equivalences at a rate that makes them unsuitable for production FTO work.
Automated Claim Element Mapping
Once a semantic search identifies a set of potentially relevant patents, the next step in any FTO analysis is claim mapping: comparing each element of the relevant patent claims against each feature of the product or process under review. This has traditionally been one of the most time-consuming and expertise-intensive steps in the FTO workflow, requiring a trained analyst to read each claim, decompose it into its constituent elements, and assess whether the product reads on those elements.
AI-powered claim mapping tools can now automate the initial pass of this analysis. These tools parse patent claims into individual elements, extract the corresponding features from a product description, and generate a preliminary mapping that highlights areas of potential overlap. Verticalized LLMs are particularly effective at this task because they can interpret the functional language and structural relationships embedded in patent claims with far greater accuracy than general-purpose models that lack exposure to the syntactic conventions of patent drafting. The output is not a final legal opinion, but it dramatically reduces the time required to triage a large set of potentially relevant patents down to a manageable shortlist of those that require detailed human review. For FTO searches that surface hundreds or even thousands of candidate patents from the initial semantic search, this triage step is essential to making the workflow practical.
Classification-Based Filtering and Clustering
Patent classification systems such as the Cooperative Patent Classification (CPC) and the International Patent Classification (IPC) provide a structured taxonomy that assigns each patent to one or more technology categories. While classification codes are not a substitute for full-text search, they are a powerful complement, especially for narrowing the initial scope of an FTO search to the most relevant technology areas.
AI-enhanced clustering takes this a step further. Rather than relying on the classification codes assigned by patent office examiners, machine learning algorithms can analyze the full text of search results and automatically cluster them into thematic groups based on their technical content. This allows the analyst to see at a glance which technology sub-areas are most densely populated with potentially relevant patents and to prioritize review accordingly. It also reveals patterns that might not be visible in a flat list of results, such as a concentration of filings from a particular competitor in a specific sub-technology that warrants closer scrutiny. The best clustering implementations use domain-specific ontologies rather than generic topic models, because a general-purpose topic model may group patents by surface-level keyword similarity rather than by the deeper technical relationships that matter for infringement analysis.
Citation Network Analysis
Patents do not exist in isolation. Each patent cites prior art references, and each patent is in turn cited by later filings. This web of citations creates a network that contains valuable information about the relationships between inventions, the evolution of a technology area, and the relative importance of individual patents within the landscape. AI-powered citation analysis tools can traverse this network to identify patents that are highly cited (suggesting broad influence), patents that share citation patterns with the product under review (suggesting technical proximity), and patents that have been cited in opposition or post-grant proceedings (suggesting contested validity).
Citation network analysis is particularly valuable for uncovering "hidden" prior art, meaning patents that would not surface through a keyword or semantic search because they use entirely different terminology but are technically relevant based on their position in the citation graph. For FTO searches in mature technology areas with deep citation histories, this technique can surface blocking patents that other methods would miss.
Incorporating Non-Patent Literature into FTO Workflows
One of the most significant blind spots in traditional FTO searches is the exclusive focus on patent data. A thorough clearance analysis must also consider non-patent literature (NPL), including scientific journal articles, conference proceedings, technical standards, and regulatory filings. NPL is relevant to FTO in two distinct ways. First, NPL may constitute prior art that could be used to invalidate a blocking patent, thereby eliminating the infringement risk. Second, NPL may describe the state of the art in ways that inform claim interpretation, helping the analyst understand the scope of a patent claim in the context of what was known at the time of filing.
The challenge is that non-patent literature exists in entirely separate databases from patent data, uses different terminology conventions, and is structured differently. Most traditional patent search tools do not index scientific literature at all, forcing analysts to conduct separate searches across multiple platforms and then manually correlate the results. AI-powered platforms that unify patent and scientific literature into a single searchable corpus eliminate this fragmentation and allow the analyst to see the full picture of the prior art landscape in a single workflow. This is an area where the choice of platform matters enormously: the ability to run a single semantic query across both patent and NPL data, and to have the results ranked by a verticalized model that understands both document types, is a significant structural advantage over workflows that require separate tools and manual reconciliation.
Agentic AI and Multi-Step FTO Workflows
A newer development in AI-powered FTO is the emergence of agentic AI systems that can execute multi-step research workflows autonomously. Rather than requiring the analyst to manually sequence each step of the FTO process (define search terms, run the search, filter results, cluster by technology area, map claims, check legal status), an agentic system can accept a high-level task description (such as "conduct an FTO search for this product in these jurisdictions") and autonomously plan and execute the sequence of searches, filters, and analyses needed to produce a comprehensive result.
Agentic approaches are particularly valuable for FTO searches because the process inherently involves multiple dependent steps where the output of one step determines the input to the next. A well-designed agentic FTO system can dynamically expand or narrow its search based on what it finds at each stage, pursue unexpected leads surfaced by citation analysis, and flag ambiguities for human review rather than making assumptions. This represents a meaningful step beyond static search tools, though it also demands a higher level of trust in the underlying AI and places a premium on transparency and explainability in how the system arrives at its conclusions.
Continuous Monitoring: Transforming FTO from a Snapshot to a Living Process
A traditional FTO search produces a point-in-time snapshot: a report reflecting the patent landscape as it existed on the date the search was conducted. But the patent landscape is not static. New applications are published every week. Pending applications receive grants. Legal status changes as patents are challenged, abandoned, or expire. A critical, and often overlooked, part of a modern FTO strategy is to establish a system for continuous monitoring that transforms the FTO from a static report into a living intelligence system (5).
AI-powered monitoring tools allow teams to save their search parameters and receive automated alerts whenever new patents are published in their technology area, a key competitor files a new application, or the legal status of a previously identified high-risk patent changes. This continuous approach is especially important for products with long development cycles, where the patent landscape may shift significantly between the initial FTO search and the commercial launch date.
Hybrid Intelligence: Why AI Alone Is Not Enough
For all its power, AI is not a substitute for expert human judgment in FTO analysis. The future of IP analytics lies in integrating AI-driven scalability with human interpretative depth, as highlighted at major industry conferences exploring hybrid human-machine workflows for patent searching and FTO analysis (6). AI can process millions of documents, surface the most relevant candidates, and generate preliminary claim maps. But the final determination of whether a product infringes a patent claim requires legal interpretation that accounts for claim construction doctrines, prosecution history, and jurisdiction-specific rules of infringement analysis. These are judgments that require training, experience, and an understanding of legal context that current AI systems cannot reliably provide.
The most effective FTO methodology in 2026 is a hybrid model: AI handles the high-volume discovery, filtering, and triage phases, while human experts focus their attention on the relatively small number of patents that survive the AI filter and require detailed claim-by-claim analysis. This division of labor plays to the strengths of each. AI excels at scale, speed, and consistency across large datasets. Humans excel at nuanced interpretation, contextual reasoning, and the kind of strategic thinking that determines whether a potential infringement risk warrants a design-around, a licensing negotiation, or a validity challenge.
The USPTO Is Signaling the Direction of Travel
The United States Patent and Trademark Office has itself begun integrating AI into its examination processes, and these developments have direct implications for FTO practice. The USPTO launched its Automated Search Pilot Program (ASAP!) in October 2025, using an internal AI tool to conduct pre-examination prior art searches and provide applicants with an Automated Search Results Notice listing up to 10 relevant documents ranked by relevance (7). In July 2025, the USPTO launched the DesignVision tool, enabling AI-driven image-based search of U.S. and foreign design patents to support examiners in comparing query images to global design collections (8). And in March 2026, the agency launched its Class ACT system, an AI-powered tool that automates trademark classification tasks that previously took up to five months (9).
These initiatives signal that the patent office itself views AI-assisted search as a core component of the future examination process. For FTO practitioners, this raises the bar: if the patent office is using AI to find more and better prior art during examination, then the patents that survive this enhanced scrutiny and proceed to grant may be stronger and harder to challenge. This makes thorough, AI-augmented FTO searches even more critical before making go-to-market decisions.
Platforms for AI-Powered FTO Searches: What to Look For
Not all platforms are equally suited to FTO analysis on large datasets. When evaluating tools for this purpose, R&D and IP teams should prioritize several capabilities.
The first is data coverage. A platform is only as useful as the corpus it can search. The best FTO tools provide access to patent data from all major patent-issuing authorities worldwide, including full-text documents, legal status information, patent family linkages, and prosecution history. Equally important is coverage of non-patent literature, including peer-reviewed scientific journals and conference proceedings, which can be essential both for identifying prior art and for understanding claim scope.
The second is AI model quality. The platform's AI should be built on verticalized models trained specifically on patent and technical text, not repurposed general-purpose LLMs. It should support natural language queries, full-document input, and iterative refinement of search results based on user feedback.
The third is workflow integration. FTO analysis is not a single search query but a multi-step process that includes search, filtering, clustering, claim mapping, validity assessment, and reporting. The best platforms support this entire workflow in a unified environment rather than requiring the analyst to export data and switch between tools at each stage.
The fourth is monitoring and alerting. As discussed above, FTO is not a one-time event. The platform should support saved searches, automated alerts, and ongoing landscape tracking so that the initial FTO assessment remains current throughout the product development cycle.
With these criteria in mind, several platforms merit consideration for enterprise FTO workflows in 2026.
Cypris takes a structurally different approach from most patent intelligence tools by unifying patent data, scientific literature, and competitive intelligence into a single enterprise R&D intelligence platform. Cypris indexes over 500 million patents and scientific papers and applies a proprietary R&D ontology that maps relationships across data types, enabling searches that span the full spectrum of technical prior art in a single query. For FTO analysis specifically, this means an analyst can conduct the patent search, cross-reference the results against relevant scientific literature, and monitor the landscape for changes, all without leaving a single platform or reconciling outputs from multiple tools. Cypris maintains enterprise API partnerships with OpenAI, Anthropic, and Google, which positions it to integrate the latest advances in large language model technology directly into its search and analysis workflows as verticalized AI capabilities rather than generic chat interfaces bolted onto legacy data. It is trusted by hundreds of enterprise teams and thousands of researchers across R&D, IP, and product development functions. For organizations whose FTO needs extend beyond patent-only analysis into the broader question of what the full body of technical prior art looks like across both patent and non-patent sources, Cypris provides a unified foundation that eliminates the fragmentation inherent in multi-tool approaches (10).
Derwent Innovation from Clarivate is one of the longest-established platforms in the patent intelligence space. It provides access to a large global patent collection with strong coverage of the Derwent World Patents Index (DWPI), which includes human-written abstracts that standardize patent terminology across jurisdictions. Derwent Innovation is widely used by IP attorneys and patent professionals, and its strength lies in the depth of its curated data and its classification-enhanced search capabilities. However, Derwent Innovation is primarily a patent-focused tool. Its scientific literature integration is handled through a separate Clarivate product (Web of Science), which requires a distinct subscription and a separate search interface. For teams that need to search patents and scientific literature in a unified workflow, this two-product structure can add friction and increase the risk of gaps between the two datasets (11).
Google Patents is a free, publicly accessible patent search tool that covers patents from major jurisdictions worldwide. It has added basic semantic search capabilities in recent years and provides a useful starting point for initial FTO screening, particularly for teams with limited budgets. However, Google Patents has significant limitations for enterprise FTO work. It does not provide legal status tracking, patent family visualization, automated monitoring, or claim mapping tools. It does not index scientific literature. And it does not offer API access for integration into automated workflows. Google Patents is best understood as a supplementary resource rather than a primary FTO platform (12).
The Lens is an open-access platform that provides a unified search across patents, scholarly articles, and biological sequences. It is operated by Cambia, a nonprofit organization, and its commitment to open data access makes it a valuable resource for teams that want to cross-reference patent and literature data without separate subscriptions. The Lens offers structured metadata, patent family linkages, and basic visualization tools. Its limitations for enterprise FTO work center on the absence of advanced AI search capabilities, automated claim mapping, and the kind of continuous monitoring infrastructure that large R&D organizations require (13).
PQAI (Patent Quality AI) is an open-source project that applies machine learning to patent prior art search. It offers semantic similarity search trained on patent text and allows users to input invention disclosures as natural language queries. PQAI is a useful tool for technology scouting and initial prior art screening, but it is primarily focused on prior art discovery rather than full FTO analysis, and it lacks the enterprise features (monitoring, claim mapping, legal status tracking, team collaboration) required for production FTO workflows (14).
Scite takes a different approach, focusing on scientific literature rather than patents. Scite's AI analyzes citation contexts to determine whether a citing paper supports, contradicts, or simply mentions a cited claim. For FTO workflows that require deep analysis of the non-patent literature, particularly in life sciences and pharmaceuticals where journal publications play a critical role in establishing the state of the art, Scite provides a layer of intelligence that patent-focused tools do not offer (15).
Building an Effective FTO Workflow for Large Datasets in the Age of AI
The platforms discussed above are tools, not solutions in themselves. An effective FTO workflow on large datasets requires a structured methodology that sequences the right techniques in the right order, and an understanding of where general-purpose AI, verticalized AI, and human expertise each contribute the most value.
The first phase is scoping. Before any search begins, the team must define the product or process features to be cleared, the jurisdictions of interest, and the relevant time window (typically patents filed within the last 20 years, adjusted for patent term extensions). General-purpose LLMs can be useful at this stage for brainstorming potential claim interpretations, generating alternative descriptions of the product's features, and identifying adjacent technology areas that might harbor relevant patents. Clear scoping prevents the search from expanding into irrelevant technology areas and ensures that the results are actionable.
The second phase is broad discovery. This is where verticalized AI delivers the most value. The analyst inputs the product description or claim set into a platform powered by domain-specific models and runs a broad semantic search across the full patent corpus, supplemented by classification-based filtering and citation network analysis. The goal is to cast a wide net and capture every potentially relevant reference. Using a general-purpose chatbot for this step is inadequate because it cannot search live patent databases, verify legal status, or rank results using patent-trained embeddings.
The third phase is AI-assisted triage. The results of the broad discovery phase will typically number in the hundreds or thousands. AI clustering and preliminary claim mapping tools reduce this set to a manageable shortlist of patents that warrant detailed human review. Documents that are clearly irrelevant, expired, or directed to a different technology are filtered out automatically. Agentic AI systems can further accelerate this phase by autonomously pursuing follow-up searches on the most promising clusters and flagging ambiguities for human attention.
The fourth phase is expert analysis. The shortlisted patents are reviewed in detail by a qualified patent professional who constructs claim charts, assesses infringement risk under the applicable legal standards, and evaluates the validity of any blocking patents. This is the step where human judgment is indispensable. No AI system, however sophisticated, should be the sole basis for a go/no-go commercialization decision.
The fifth phase is continuous monitoring. The search parameters from the initial analysis are saved and configured to generate automated alerts. The FTO assessment becomes a living document that is updated as the patent landscape evolves.
The Cost of Getting FTO Wrong
The consequences of an inadequate FTO search are not abstract. Patent infringement lawsuits named 1,889 defendants in a recent reporting period, a 21.6 percent increase over the prior year (8). Even a single overlooked patent can delay a product launch, trigger costly litigation, or force an expensive redesign after manufacturing has already begun. The investment in AI-augmented FTO tools and methodologies is small relative to the risk it mitigates.
For R&D organizations operating in technology areas with dense patent landscapes, such as semiconductors, pharmaceuticals, telecommunications, and advanced materials, the question is no longer whether to adopt AI-powered FTO methods but how quickly the transition from manual-only workflows can be completed. The data volumes, jurisdictional complexities, and competitive stakes of 2026 demand it. And the distinction between using a general-purpose chatbot to "ask about patents" and deploying a verticalized AI platform purpose-built for patent intelligence is the difference between a defensible FTO process and an expensive false sense of security.
Citations
(1) WIPO, "World Intellectual Property Indicators 2025: Patents Highlights," November 2025. https://www.wipo.int/web-publications/world-intellectual-property-indicators-2025-highlights/en/patents-highlights.html
(2) WIPO, "IP Facts and Figures 2025," 2025. https://www.wipo.int/edocs/pubdocs/en/wipo-pub-943-2025-en-wipo-ip-facts-and-figures-2025.pdf
(3) WIPO, "IP Facts and Figures 2025: Patents and Utility Models," 2025. https://www.wipo.int/web-publications/ip-facts-and-figures-2025/en/patents-and-utility-models.html
(4) IPWatchdog, "Agentic AI Meets Patent Search: A New Paradigm for Innovation," October 2025. https://ipwatchdog.com/2025/10/30/agentic-ai-meets-patent-search-new-paradigm-innovation/
(5) DrugPatentWatch, "Conducting a Biopharmaceutical Freedom-to-Operate (FTO) Analysis," 2025. https://www.drugpatentwatch.com/blog/conducting-a-biopharmaceutical-freedom-to-operate-fto-analysis-strategies-for-efficient-and-robust-results/
(6) ScienceDirect, "AI, Hybrid Intelligence, and the Future of Patent Analytics: Key Takeaways from the CEPIUG 17th Anniversary Conference," February 2026. https://www.sciencedirect.com/science/article/abs/pii/S017221902600013X
(7) Morgan Lewis, "USPTO Announces Automated Search Pilot Program," October 2025. https://www.morganlewis.com/pubs/2025/10/uspto-announces-automated-search-pilot-program
(8) Lumenci, "AI-Powered Freedom to Operate: Streamlining Patent Risk Analysis," November 2025. https://lumenci.com/blogs/ai-assisted-fto-search/
(9) Sterne Kessler, "USPTO Launches AI Examination Tools: What This Means for Trademark Applicants," March 2026. https://www.sternekessler.com/news-insights/insights/uspto-launches-ai-examination-tools-what-this-means-for-trademark-applicants/
(10) Cypris. https://cypris.ai
(11) Clarivate, Derwent Innovation. https://clarivate.com/products/ip-intelligence/patent-intelligence/derwent-innovation/
(12) Google Patents. https://patents.google.com
(13) The Lens, Cambia. https://www.lens.org
(14) PQAI (Patent Quality AI). https://projectpq.ai
(15) Scite. https://scite.ai
FAQ
What is a freedom-to-operate search?A freedom-to-operate search, also called an FTO search or patent clearance search, is an investigation of existing and pending patents to determine whether a product, process, or technology can be commercialized in a specific jurisdiction without infringing the valid intellectual property rights of a third party. It is distinct from a patentability search, which evaluates whether an invention is novel enough to receive its own patent. FTO analysis focuses specifically on infringement risk and is typically conducted before major investment decisions such as product launch, manufacturing scale-up, or market entry.
Why are large datasets a challenge for FTO searches?Global patent filings reached 3.7 million applications in 2024, and an estimated 19.7 million patents are currently in force worldwide. This corpus spans hundreds of patent-issuing authorities, multiple languages, and decades of filing history. Traditional keyword searches require the analyst to anticipate every possible phrasing a patent drafter might have used, which becomes impractical at this scale. AI-powered semantic search addresses this by understanding conceptual meaning rather than matching exact text strings, enabling the analyst to surface relevant references even when the terminology differs from the search query.
Can I use ChatGPT or another general-purpose LLM for FTO searches?General-purpose LLMs like ChatGPT, Claude, or Gemini can be helpful for background research, brainstorming search strategies, and explaining technical concepts to non-specialist stakeholders. However, they are not suitable as the primary engine of an FTO search. They do not have access to live patent databases, cannot verify legal status, are prone to hallucination, and lack the domain-specific training needed to interpret patent claim language with the precision FTO analysis demands. Verticalized AI models trained specifically on patent and scientific text, and integrated into platforms with access to structured patent data, are required for defensible FTO work.
What is a verticalized LLM and why does it matter for FTO?A verticalized LLM is a large language model that has been fine-tuned or trained specifically on domain-specific data, in this case patent documents, scientific literature, and technical taxonomies. These models understand the conventions of patent drafting, including how claim language maps to technical concepts, how dependent claims narrow independent claims, and how the same invention can be described using different vocabulary across jurisdictions. When integrated into a purpose-built patent search platform, verticalized LLMs perform semantic retrieval, claim decomposition, and relevance ranking at a level of precision that general-purpose models cannot match.
How does AI improve FTO search accuracy?AI improves FTO search accuracy in several ways. Semantic search identifies conceptually related patents that keyword searches miss. Automated claim mapping generates preliminary comparisons between patent claims and product features, speeding up the triage process. Citation network analysis uncovers patents that are technically relevant based on their position in the citation graph rather than their text alone. Classification-based clustering reveals patterns in the patent landscape that help the analyst prioritize review. And agentic AI systems can autonomously execute multi-step search workflows, dynamically adjusting their approach based on intermediate results. Together, these techniques reduce the risk of missing a blocking patent while also reducing the time and cost of the analysis.
Can AI replace human experts in FTO analysis?No. AI is a powerful tool for the discovery, filtering, and triage phases of FTO analysis, but the final determination of infringement risk requires legal judgment that accounts for claim construction, prosecution history, and jurisdiction-specific rules. The most effective FTO methodology combines AI-driven discovery with expert human analysis in a hybrid model. AI processes the volume; humans apply the judgment.
When should an FTO search be conducted?FTO searches should be conducted early in the product development process, ideally before significant investments in design, tooling, or manufacturing. Conducting FTO analysis at the ideation or early development stage allows the team to identify potential patent obstacles while there is still time and flexibility to design around them, seek licenses, or challenge the validity of blocking patents. FTO analysis should also be refreshed at major development milestones and before commercial launch, as the patent landscape may have changed since the initial search.
What is the difference between semantic search and keyword search for patents?Keyword search matches exact text strings in patent documents. If a patent uses the term "optical waveguide" but the search query uses "fiber optic channel," a keyword search will not find the match. Semantic search uses natural language processing to understand the conceptual meaning of both the query and the documents, enabling it to recognize that these two phrases describe the same concept. For FTO searches across large, multilingual patent datasets, semantic search provides significantly broader coverage than keyword-only approaches.
How does non-patent literature factor into FTO analysis?Non-patent literature, including scientific journal articles, conference proceedings, and technical standards, is relevant to FTO in two ways. First, it may constitute prior art that can be used to invalidate a blocking patent, eliminating the infringement risk. Second, it provides context about the state of the art at the time a patent was filed, which can inform claim interpretation and scope analysis. Platforms that unify patent and scientific literature in a single search interface eliminate the need to conduct separate searches across different databases and reduce the risk of gaps.
What is continuous FTO monitoring and why does it matter?Continuous FTO monitoring means saving the search parameters from an initial FTO analysis and configuring automated alerts for changes in the patent landscape. These alerts can notify the team when new patents are published in the relevant technology area, when a competitor files a new application, or when the legal status of a previously identified patent changes. This transforms the FTO assessment from a one-time snapshot into a living intelligence system that keeps pace with the evolving patent landscape throughout the product development cycle.
How many jurisdictions should an FTO search cover?An FTO search should cover every jurisdiction where the product will be manufactured, sold, imported, or used. At a minimum, this typically includes the United States, Europe (via the European Patent Office), China, Japan, and South Korea for technology products with global distribution. PCT applications should also be monitored, as an international filing may enter the national phase in any member country. The specific jurisdictional scope depends on the company's commercialization plans and supply chain geography.
What should I look for in an AI-powered FTO platform?The most important capabilities for an enterprise FTO platform are comprehensive global patent data coverage, high-quality semantic search powered by verticalized models trained on patent text, non-patent literature integration, automated claim mapping and clustering tools, legal status tracking, patent family visualization, continuous monitoring and alerting, API access for workflow automation, and enterprise-grade security. Platforms that unify patent and scientific literature search in a single interface and leverage domain-specific AI rather than generic general-purpose models provide the strongest foundation for defensible FTO analysis at scale.

Clarivate is not a single product. It is a portfolio of acquired tools assembled over decades, and the two platforms that enterprise R&D teams use most frequently — Derwent Innovation for patent intelligence and Web of Science for scientific literature — were designed for entirely different audiences with entirely different workflows. Derwent was built for IP attorneys conducting freedom-to-operate searches. Web of Science was built for academic librarians and university researchers. Neither was built for the R&D scientist trying to answer a strategic question about a technology landscape, a competitive portfolio, or an emerging technical risk.
The gap between what Clarivate's R&D-adjacent tools were designed to do and what modern innovation teams actually need is the primary reason organizations are evaluating alternatives. This guide examines six of the strongest alternatives to Clarivate for enterprise R&D and IP teams, explains what distinguishes each platform, and provides a framework for matching your team's specific requirements to the right solution.
Why R&D Teams Are Reevaluating Clarivate
Clarivate's position in the market is the product of consolidation, not native product design. The company was spun out of Thomson Reuters' IP and Science division in 2016 and has since assembled its portfolio through a series of acquisitions — Derwent, Web of Science, ProQuest, Cortellis, and others — without fully integrating the underlying data architectures. For R&D teams, the practical consequence is that patent intelligence and scientific literature intelligence live in separate platforms with separate subscriptions, separate interfaces, and separate learning curves.
This fragmentation has real costs. An R&D scientist conducting a technology scouting exercise needs to understand what has been patented, what has been published in the scientific literature, and how those two bodies of knowledge relate to each other. Performing that analysis through Derwent and Web of Science requires toggling between platforms, manually reconciling results, and building synthesis layers that neither tool provides natively. The time investment alone is a meaningful barrier, and the cognitive load of maintaining fluency in two complex legacy interfaces reduces the frequency with which R&D teams can turn to patent and literature intelligence for decision support.
Pricing is a compounding factor. Clarivate's enterprise contracts for combined Derwent and Web of Science access can run into six figures annually, and the terms typically require institutional commitment rather than flexible per-seat or usage-based arrangements. For Fortune 500 R&D organizations that have historically lived with the cost because no integrated alternative existed, the rapid maturation of AI-native intelligence platforms over the past three years has changed the evaluation calculus significantly.
There is also a structural concern specific to Derwent. Clarivate's Derwent World Patents Index is maintained by a team of over 800 patent editors who manually write abstracts for each invention family — a curation model that represents both the platform's greatest strength and its most significant vulnerability. The value of Derwent has always rested on human expertise applied at scale. As AI-native platforms develop increasingly sophisticated capabilities for patent comprehension and synthesis, the competitive differentiation of hand-written abstracts is narrowing, and the cost premium associated with that curation model becomes harder to justify for teams whose primary need is strategic intelligence rather than legal-quality prior art analysis.
What to Look for in a Clarivate Alternative
Before evaluating specific platforms, it is worth being precise about what Clarivate's R&D-adjacent products actually do, because the alternatives that best address those functions are not necessarily the platforms that appear most often in head-to-head comparison articles.
Derwent Innovation provides access to the Derwent World Patents Index, a curated database covering over 130 million patents, along with tools for patent search, analytics, portfolio management, and competitive landscaping. Its primary design center is the patent professional: the interface and workflows are optimized for freedom-to-operate analyses, patentability assessments, and portfolio strategy decisions that require high-confidence data quality.
Web of Science provides access to a peer-reviewed scientific literature database covering approximately 20,000 journals, along with citation analytics, research performance metrics, and discovery tools. Its primary design center is the academic researcher and institutional library administrator.
An effective Clarivate alternative for an enterprise R&D team needs to cover both functions, ideally within a unified architecture, and needs to provide the kind of strategic synthesis and workflow integration that neither Derwent nor Web of Science was designed to deliver. The evaluation criteria that matter most are unified data architecture, native AI capabilities, scientific literature depth alongside patent coverage, enterprise security posture, and whether the platform was designed for R&D scientists and innovation strategists or for IP attorneys and academic administrators.
The Best Clarivate Alternatives for Enterprise R&D Teams
Cypris — Best Unified Platform for Enterprise R&D Intelligence
Cypris takes a fundamentally different approach to R&D intelligence than Clarivate's two-platform model. Rather than providing a patent database and a literature database as separate tools, Cypris unifies over 500 million patents and scientific papers within a single platform, structured through a proprietary R&D ontology that understands the relationships between technical concepts across both corpora. The result is that searches and analyses performed in Cypris return integrated results from patents and scientific literature simultaneously, without requiring the researcher to reconcile findings from separate systems.
The distinction is not merely a user experience improvement. When patent data and scientific literature are indexed through a shared ontology rather than maintained in separate silos, the analytical possibilities expand substantially. A technology scouting exercise can reveal not just what has been patented in a domain but what the concurrent scientific literature suggests about the direction of technical development, where the patent portfolio is leading versus lagging the research frontier, and which organizations are accumulating both IP and publication activity in emerging areas. These cross-signal insights are structurally unavailable in a Derwent-plus-Web-of-Science architecture because the data models do not share a common semantic layer.
Cypris is trusted by hundreds of enterprise teams and thousands of researchers across R&D, IP, and product development functions, including organizations in the Fortune 500. The platform's AI architecture is built on official enterprise API partnerships with OpenAI, Anthropic, and Google — partnerships that distinguish it from platforms that have layered general-purpose AI onto legacy data infrastructure without formal integration agreements. Enterprise security meets Fortune 500 requirements, addressing the compliance and data governance requirements that govern platform adoption decisions at large corporations.
For organizations that have historically maintained separate Derwent and Web of Science subscriptions, Cypris offers the possibility of consolidating that intelligence infrastructure into a single platform while simultaneously gaining access to AI capabilities that neither legacy tool provides. The platform's Research Brief service extends beyond self-service search to provide bespoke analysis by Cypris research analysts, which addresses the capacity constraint that limits how frequently in-house teams can conduct deep landscape analyses.
Google Patents — Best Free Option for Preliminary Research
Google Patents provides free access to patent documents from major patent offices worldwide, with an interface that will be immediately familiar to anyone comfortable with Google's search products. The platform indexes over 87 million patents and offers some integration with Google Scholar to bring non-patent literature into search results.
For preliminary research, competitive screening, and exploratory work, Google Patents offers genuine utility. The familiar search interface eliminates the training investment required by Derwent and Orbit, and the zero-cost access model makes it available to anyone in an R&D organization without procurement friction. Translation capabilities allow English-language searches to surface relevant patents from non-English-language jurisdictions, which addresses one of the more significant practical limitations of manual prior art searching.
The gap between Google Patents and enterprise-grade intelligence platforms is most visible in the analytics layer. Google Patents is a document retrieval tool. It does not offer patent landscaping, portfolio analytics, competitive benchmarking, or AI-powered synthesis — the capabilities that allow R&D teams to extract strategic insights from patent data rather than simply locating relevant documents. For organizations that have been paying Clarivate prices, the step down to Google Patents represents a significant reduction in capability even as it eliminates license costs entirely. It functions well as a complement to an enterprise platform for quick searches, but not as a replacement for the strategic intelligence that Derwent and Web of Science provide in combination.
The Lens — Best Free Platform for Combined Patent and Literature Access
The Lens is the most capable free alternative for organizations that need both patent and scientific literature access without a commercial subscription. The platform provides open access to over 300 million patent records and more than 200 million scientific documents, making it the most comprehensive free resource available for the combined research task that Derwent and Web of Science together currently serve
What distinguishes The Lens from other free tools is its integration philosophy. Patent records and scholarly works are available within the same interface, and The Lens supports citation analysis linking patents to the scientific literature they cite and vice versa. This cross-domain citation capability partially replicates one of the most valuable analytical functions in a combined Derwent and Web of Science environment — understanding how patent filings and published research co-evolve in a technology area.
The Lens operates under an open-access mission and is supported by charitable foundations rather than commercial subscription revenue, which means its development roadmap and feature investment are less predictable than those of commercial platforms. The analytical tools are more limited than those available in Orbit or enterprise platforms, and there is no AI-powered synthesis capability comparable to what modern commercial platforms provide. For budget-constrained teams or organizations beginning to build a patent and literature intelligence practice before committing to enterprise platform investments, The Lens represents a meaningful option. It is not a direct substitute for the combined capability of Clarivate's R&D suite, but it provides a more complete free alternative than any other single platform.
PQAI — Best Open-Source AI Patent Search
PQAI is an open-source patent search platform built on an AI-first philosophy that removes the requirement for Boolean search expertise. Researchers can submit queries in natural language and receive relevant patent results without building complex search strings or learning classification system syntax. The platform includes a prior art search API that allows R&D and legal teams to embed patent intelligence directly into their workflows rather than requiring researchers to visit a separate interface.
For organizations where the primary limitation of Derwent and other legacy platforms has been the training barrier — the reality that effective use requires significant investment in Boolean search and classification system expertise — PQAI offers a genuinely different user experience. Its accessibility makes patent intelligence available to R&D scientists who would not typically engage with Derwent's professional-grade interface.
PQAI's scope is narrower than Clarivate's R&D suite. It does not include scientific literature, and its analytical capabilities are more limited than those of commercial platforms. It is most appropriately used as a prior art search and patent discovery tool rather than as a strategic intelligence platform. PQAI fits best in organizations where patent accessibility is the primary unmet need and where the R&D intelligence use case is being built incrementally rather than addressed through a comprehensive platform investment.
Scite — Best for Citation Intelligence
Scite addresses the scientific literature dimension of the Clarivate suite more directly than any other alternative on this list. The platform provides access to over 1.2 billion citation statements from the scientific literature, with AI-powered analysis of whether each citation supports, contrasts, or simply mentions the cited work. This distinction between supporting and contrasting citations transforms citation analysis from a quantitative measure of research influence into a qualitative map of scientific consensus and controversy — a capability that Web of Science's citation analytics does not provide.
For R&D teams whose primary use of Web of Science is tracking the scientific literature in their technology domains, understanding where expert consensus is solidifying versus where debates remain open, and identifying emerging research directions before they appear in patent filings, Scite's citation intelligence capability offers something meaningfully different from what Web of Science delivers. It is a tool oriented around scientific understanding rather than research performance metrics.
Scite does not address the patent dimension of the Clarivate use case, and its data coverage, while extensive, is focused on the scholarly literature rather than the full breadth of technical documentation that platforms like Cypris access. Organizations replacing a combined Derwent and Web of Science subscription will need to address the patent intelligence requirement separately if they select Scite for the literature component. It is most appropriately positioned as a supplement to an enterprise intelligence platform or as a specialized tool for scientific literature analysis within a broader technology monitoring program.
Choosing the Right Alternative
The right Clarivate alternative depends on which parts of the R&D intelligence workflow the current Clarivate subscription is actually serving and what the primary failure modes of the existing setup are.
For organizations that use Derwent and Web of Science as integrated inputs into technology scouting, competitive landscape analysis, and R&D investment decisions, the most important criterion is unified data architecture. Platforms that treat patents and scientific literature as separate databases with separate interfaces recreate the fragmentation that makes Clarivate's two-platform model difficult to use efficiently. The relevant question is not which alternative is best at patents and which is best at literature, but which alternative treats them as components of a single intelligence layer.
For organizations that use Clarivate primarily for patent prosecution support, freedom-to-operate analysis, and legal-quality prior art searching, the relevant alternatives are different. The data quality and curation precision of Derwent's human-written abstracts matter significantly for legal applications in ways they do not for strategic R&D applications, and the evaluation should weight Orbit Intelligence's capabilities more heavily.
For organizations with constrained budgets exploring their options before committing to enterprise platform investments, the combination of The Lens for free patent and literature access and Scite for citation intelligence provides a meaningful foundation. Neither platform alone replicates Clarivate's combined capability, but together they address the core discovery and analysis functions at no cost.
The broader pattern in how enterprise R&D teams are evaluating this market is a shift toward platforms that were designed for scientists and innovation strategists rather than platforms originally designed for attorneys and academic administrators. Clarivate's core products are genuinely excellent at what they were built to do. The question organizations are asking is whether what they were built to do maps onto what modern enterprise R&D functions actually need — and increasingly, the answer is that the fit is incomplete.
Frequently Asked Questions
What is Clarivate used for in enterprise R&D?
In enterprise R&D contexts, Clarivate is most commonly used through two products: Derwent Innovation for patent search and analytics, and Web of Science for scientific literature access and citation analysis. R&D teams use these tools for technology scouting, competitive landscape analysis, prior art research, and tracking the scientific literature in their technology domains. Because these products are sold as separate subscriptions with separate interfaces, organizations often maintain both to cover the full range of patent and literature intelligence tasks, which creates workflow fragmentation and a combined cost that enterprise R&D teams are increasingly questioning as AI-native unified platforms have matured.
How does Derwent Innovation compare to other patent platforms?
Derwent Innovation's primary differentiator is the Derwent World Patents Index, a curated database in which human patent editors write standardized abstracts for each invention family. These hand-written abstracts improve search precision and patent comprehension, particularly in complex technical domains. The platform covers over 130 million patents and is used by more than 40 national patent offices. Its limitations relative to modern alternatives include a traditional interface designed for IP attorneys rather than R&D scientists, the absence of native scientific literature integration, and a cost structure that reflects its premium data curation model. AI-native platforms increasingly challenge its differentiation by offering sophisticated natural language search and synthesis capabilities that reduce the practical advantage of manually curated abstracts for strategic R&D applications.
Is there a free alternative to Clarivate for R&D research?
The Lens provides the most comprehensive free alternative for the combined patent and scientific literature access that Derwent and Web of Science together currently serve. It covers over 300 million patent records and more than 200 million scholarly documents within a single interface and supports citation analysis linking patents to the scientific literature they cite. PQAI is a capable free option specifically for prior art patent search using natural language queries. Google Patents remains useful for preliminary patent research. None of these free options replicates the analytical capabilities and AI-powered synthesis available in enterprise platforms, but they provide meaningful starting points for organizations building their R&D intelligence practice.
Why are R&D teams replacing Clarivate with AI-native platforms?
The primary reasons R&D teams are evaluating AI-native alternatives to Clarivate center on three limitations of the current platform architecture. First, Derwent and Web of Science are separate products that do not share a unified data model, which requires manual synthesis when both patent and literature intelligence are needed for the same analysis. Second, both platforms were designed for IP attorneys and academic researchers respectively, and their interfaces and analytical tools reflect those use cases rather than the workflow of an R&D scientist or innovation strategist. Third, AI-native platforms have developed sufficient capability in natural language patent search, landscape synthesis, and cross-domain analysis to reduce the competitive advantage of Derwent's manual curation model for strategic R&D applications, while offering workflow integration and AI synthesis capabilities that Clarivate's tools do not provide.
What should enterprise teams prioritize when evaluating Clarivate alternatives?
Enterprise teams should prioritize unified data architecture above other criteria when evaluating Clarivate alternatives. Platforms that treat patents and scientific literature as separate data sources with separate interfaces recreate the fragmentation problem that is the primary operational limitation of the Clarivate suite. After data architecture, the relevant evaluation criteria are native AI capabilities and the quality of synthesis they enable, enterprise security posture and compliance certifications, scientific literature depth alongside patent coverage, and whether the platform's design orientation matches the actual users — R&D scientists and innovation strategists rather than IP attorneys. Cost structure and contract flexibility are also significant considerations given the high annual cost of Clarivate enterprise subscriptions.
Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.
1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated
1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.

The patent analytics market is projected to grow from roughly $1.3 billion in 2025 to more than $3 billion by 2032, according to Fortune Business Insights (1). The investment is visible in the proliferation of patent-specific intelligence platforms competing for enterprise budgets. PatSnap, IPRally, Patlytics, Questel's Orbit Intelligence, Derwent Innovation, and a growing roster of niche players all promise better, faster, more AI-enhanced access to the global patent corpus. They deliver on that promise to varying degrees. But the promise itself is the problem. These platforms are competing to provide the best view of the same underlying dataset, one that is increasingly commoditized and, by itself, structurally incomplete as a basis for long-term R&D strategy. Access to patent filings and grants across global jurisdictions is table stakes. Every serious enterprise patent search platform delivers it. The harder question, and the one that actually determines whether R&D investment decisions succeed or fail, is what happens when you treat that dataset as though it were the whole picture.
Patent data captures invention activity. It does not capture commercial viability, market timing, customer adoption, regulatory trajectory, scientific momentum, or the dozens of other signals that determine whether a patented technology ever reaches a product shelf. When IP teams advise R&D leadership on where to invest, where to avoid, and where genuine opportunity exists, they are making those recommendations with roughly half the evidence. The missing half falls into two distinct categories, each with its own mechanics and consequences: the scientific literature gap and the commercial intelligence gap.
The Scale of What Is at Stake
Corporate R&D expenditure reached approximately $1.3 trillion in 2024, a historic high, though real growth slowed to roughly 1 percent after adjusting for inflation, according to WIPO's Global Innovation Index (2). Total global R&D spending across public and private sectors approached $2.87 trillion the same year (3). These figures matter because they describe the size of the decisions that patent intelligence is being asked to inform. When an IP team delivers a patent landscape report that shapes the direction of a multimillion-dollar research program, the accuracy and completeness of that intelligence has direct financial consequences that compound across every program in the portfolio.
Meanwhile, the volume of patent activity continues to accelerate. The USPTO received more than 700,000 patent applications in 2024 alone (4). Patent grants grew 5.7 percent year over year to 368,597 during the same period, with semiconductor technology leading all fields for the third consecutive year (5). The USPTO's backlog of unexamined applications hit a record 830,020 in early 2025 (6). Globally, WIPO data shows patent filings have grown continuously for over a decade, with particularly sharp increases in AI, clean energy, and biotechnology.
The instinct in response to this volume is to invest in better patent analytics. That instinct is correct as far as it goes. The error is in assuming that better patent analytics, no matter how sophisticated, can compensate for the absence of the data categories that patent databases were never designed to contain.
The Scientific Literature Gap: Patents Are Structurally Late
The first and arguably most underappreciated gap in patent-only intelligence is temporal. Patents are lagging indicators of technical activity, not leading ones. And the lag is not marginal. It is measured in years.
The standard patent publication cycle introduces an 18-month delay between filing and public disclosure. By the time a competitor's patent application appears in any enterprise patent search platform, the underlying research was conducted at minimum a year and a half earlier, and frequently much longer when you account for the elapsed time between initial discovery, internal validation, and the decision to file. For fast-moving technology domains like AI, advanced materials, synthetic biology, and energy storage, 18 months represents a period in which entire competitive positions can form, shift, and consolidate.
Scientific literature operates on a fundamentally different timeline. Researchers routinely publish findings on preprint servers like arXiv, bioRxiv, medRxiv, and ChemRxiv within weeks of completing their work. These publications are not obscure or difficult to access. They are the primary communication channel for the global research community. A 2024 preprint describing a novel electrode chemistry, for instance, might not surface in patent databases until mid-2026. But the technical trajectory it signals, the research group pursuing it, the institutional funding behind it, the citation pattern it generates, is visible immediately to anyone monitoring the literature.
Peer-reviewed journal publications, while slower than preprints, still generally precede patent publication and provide richer methodological detail than patent claims offer. More importantly, they reveal the connective tissue of a research program in ways that patent filings deliberately obscure. Patent claims are drafted to be as broad as defensible. Scientific publications are written to be as specific and reproducible as possible. For an IP team trying to understand not just what a competitor has claimed but what they can actually do, the scientific record is indispensable.
This temporal gap creates a specific, recurring strategic failure mode. An IP team conducting a patent landscape analysis in a technology domain will systematically miss the most recent competitive activity. The landscape they present to R&D leadership reflects where competitors were positioned roughly two years ago, not where they are today or where they are headed. For prior art searches, this delay is somewhat less consequential because the relevant question is historical. But for forward-looking decisions about where to direct R&D investment, which technology trajectories are accelerating, and which competitors are pivoting into adjacent spaces, the patent record is structurally behind the curve.
Most patent analytics platforms have begun incorporating scientific literature to some degree, but in nearly every case the integration is shallow. Literature appears as a supplementary data layer rather than a co-equal analytical signal. The search architectures were designed around patent classification systems and IPC/CPC codes, not the way scientific research is structured, cited, and built upon. The result is that literature coverage exists as a checkbox feature rather than a deeply integrated component of the analytical workflow that generates strategic recommendations.
An enterprise R&D team that monitors scientific literature alongside patents effectively moves its competitive early warning system forward by six to eighteen months. That is not an incremental improvement. It is the difference between recognizing a competitive shift in time to respond and discovering it after the window for response has closed.
The Commercial Intelligence Gap: What the Market Is Actually Doing
The second gap is commercial, and it is wider than most IP teams acknowledge. Patent data tells you what companies have invented and chosen to protect. It tells you nothing about what the market is actually doing with those inventions, or what is happening in the broader competitive landscape outside of patent strategy entirely.
This gap manifests across several specific categories of missing intelligence, each of which can independently change the strategic calculus for an R&D investment decision.
Startup and new entrant activity is perhaps the most dangerous blind spot. Early-stage companies frequently operate for years before generating meaningful patent filings. Some pursue trade secret strategies by design. Others simply prioritize speed to market over IP protection in their early stages. Their existence is visible through venture capital deal records, accelerator program participation, grant funding awards, and trade press coverage, but it is invisible in the patent corpus. A patent landscape analysis that shows no filing activity in a technology niche might miss three well-funded startups pursuing the same approach, each backed by $20 million in Series A funding and 18 months ahead of where the patent record suggests the field currently stands.
Venture capital investment patterns provide perhaps the clearest forward-looking signal of where commercial conviction is forming. When multiple institutional investors place concentrated bets on a particular technology approach, they are creating a market signal that is distinct from and often earlier than patent activity. A technology domain that shows minimal patent filings but $500 million in aggregate VC funding over the past two years is not white space. It is a market that is building commercial momentum through channels that patent analytics cannot see. Conversely, a domain with dense patent filing but declining venture interest may signal that commercial enthusiasm is fading even as legal protection intensifies, a pattern that often precedes market contraction.
Regulatory activity creates hard constraints and clear signals about commercialization timelines that patent data cannot capture. In pharmaceuticals, medical devices, chemicals, and energy, regulatory approvals and submissions often determine whether a technology reaches market more than patent strategy does. A patent landscape might show dense filing activity in a therapeutic area without revealing that two leading candidates have already received FDA breakthrough therapy designation, fundamentally changing the competitive calculus for any new entrant. A freedom to operate analysis might clear a pathway for product development without surfacing that the regulatory pathway itself is obstructed by pending rulemaking or classification disputes.
Mergers and acquisitions reshape competitive landscapes in ways that patent data captures only partially and with significant delay. When a major chemical company acquires a specialty materials startup, the strategic implications for every competitor in that space are immediate. The acquiring company's intent, which markets they plan to enter, which product lines they plan to expand, which competing approaches are being consolidated, is visible in SEC filings, press releases, analyst reports, and industry databases. It is not visible in the patent assignment records that may take months to update.
These are not edge cases. They describe the normal operating environment for enterprise R&D. And they converge on a single problem: the most consequential competitive dynamics in most technology markets unfold partially or entirely outside the patent system. An intelligence model that sees only patent data is not seeing the full competitive landscape. It is seeing one layer of it, rendered in increasingly high resolution by increasingly sophisticated tools, while the other layers remain invisible.
This is where the white space fallacy becomes most dangerous. An IP white space, a region of a technology landscape where few or no active patents exist, is routinely flagged as an area of potential opportunity. As DrugPatentWatch's analysis of pharmaceutical R&D portfolio strategy notes, an IP white space is a starting point for investigation, not a validated opportunity (7). The critical question is always why the space is empty. Patent data cannot answer that question. Commercial intelligence, scientific literature, and regulatory data can.
The Expanding Mandate of the IP Team
These gaps matter more today than they did a decade ago because the role of the enterprise IP team has fundamentally expanded. In most Fortune 1000 organizations, the IP function is no longer responsible solely for patent prosecution, portfolio management, and infringement risk assessment. It is increasingly expected to deliver strategic intelligence that informs R&D investment decisions, technology scouting priorities, partnership and licensing strategy, and business development positioning. The IP team has become, whether by design or by default, the primary intelligence function for the company's innovation strategy.
This expanded mandate is a direct consequence of how expensive and risky R&D has become. New product failure rates across industries range from 35 to 49 percent, according to research compiled by the Product Development and Management Association (8). In pharmaceuticals, overall drug development success rates average roughly 14 percent from Phase I to FDA approval, according to a 2025 analysis published in Drug Discovery Today (9). Gartner reported in 2023 that 87 percent of R&D projects never reach the production phase (10). Two-thirds of new products fail within two years of launch, according to Columbia Business School research (11). These failure rates have many causes, but a significant and underappreciated contributor is the tendency to validate technical opportunity through patent analysis without simultaneously validating commercial opportunity through market and competitive intelligence.
When an IP team is responsible not only for delivering prior art analysis but also for coupling that analysis with strategic recommendations for R&D direction and business development, the team needs to see the complete picture. A prior art search that identifies relevant existing claims is necessary but not sufficient. The team also needs to know whether the technology domain is commercially active, whether scientific literature suggests the approach is gaining or losing technical momentum, whether regulatory pathways are clear or obstructed, whether startups are entering the space with venture backing, and whether recent M&A activity signals that larger competitors are consolidating positions.
Freedom to operate analysis illustrates this dynamic clearly. FTO assessments determine whether a company can develop, manufacture, and sell a product without infringing existing patents in target markets. The financial stakes are concrete. Patent litigation averages $2 to $5 million through trial, and courts can issue injunctions that halt product sales entirely (12). An FTO analysis typically costs between $5,000 and $20,000 (13). But an FTO clearance that addresses only the legal dimension of commercialization risk, without simultaneously assessing commercial viability and scientific trajectory, can lead R&D teams to invest heavily in development programs that are legally clear but commercially nonviable, or that arrive at market three years behind a competitor who was visible in the literature but invisible in the patent record.
The IP team that delivers FTO clearance alongside scientific trajectory analysis, market context, and competitive commercial intelligence is delivering fundamentally more valuable guidance than the team that delivers a legal opinion in isolation. And the difference between those two deliverables is not analytical skill. It is access to data.
Researchers at Microbial Biotechnology noted in their analysis of patent landscape methodology that outcomes of patent landscape analyses can prevent replication of research that has already been performed and reduce waste of limited resources, but emphasized that these analyses are most effective when combined with broader scientific and commercial intelligence rather than treated as standalone decision tools (14). That observation, published in an academic context, describes precisely the operational challenge that enterprise IP teams navigate every day.
What an Integrated Intelligence Model Actually Looks Like
Closing these gaps does not require IP teams to become market researchers, literature analysts, or venture capital scouts. It requires access to a platform that integrates patent data with the broader universe of signals that determine whether a technology opportunity is technically viable, commercially real, and strategically sound.
An effective enterprise R&D intelligence platform connects several data streams that have traditionally been siloed across different tools, subscriptions, and departments. Patent filings and grants across global jurisdictions form the foundation, as they should. Scientific literature, including peer-reviewed publications, preprints, and conference proceedings, provides the temporal advantage and technical depth that patent claims alone cannot convey. Commercial data layers, including venture capital investment, M&A activity, regulatory filings, startup formation data, and competitive market analysis, provide the demand signals that distinguish genuine opportunity from empty space. Grant funding records from government agencies reveal where public investment is flowing and where institutional support exists for specific research directions.
The analytical power comes not from having these data types available in separate tabs but from mapping the relationships between them automatically. When a patent landscape shows sparse filing in a materials chemistry domain, but the scientific literature shows accelerating publication volume from three well-funded university groups, and the commercial data shows two Series A rounds in adjacent startups over the past year, and the regulatory record shows favorable classification precedent in the primary target market, those signals together tell a story that no individual data stream can tell alone. The technology is early-stage, gaining scientific momentum, attracting commercial investment, and facing a clear regulatory path. That is a qualitatively different strategic input than a patent landscape report that says the space looks open.
Cypris was built specifically to deliver this integration. The platform aggregates more than 500 million patents and scientific papers alongside commercial intelligence signals, including startup activity, venture funding, regulatory data, and competitive market intelligence, into a unified search and analysis environment designed for R&D teams rather than patent attorneys. Its proprietary R&D ontology maps relationships across data types automatically, enabling teams to identify not just what has been patented but what is being published, what is being commercialized, what is being funded, and where genuine opportunity exists. Official API partnerships with OpenAI, Anthropic, and Google enable AI-driven synthesis across the full data set, and enterprise-grade security meets the requirements of Fortune 500 R&D organizations. Hundreds of enterprise teams and thousands of researchers across R&D, IP, and product development trust the platform to close the scientific and commercial intelligence gaps that patent-only tools leave open.
The structural distinction is important. The patent analytics vendors that dominate current enterprise spending were architected around patent data as the primary or exclusive intelligence source. Their datasets, while varying in interface quality and AI capability, draw from the same underlying patent offices and classification systems. They compete on search refinement, visualization, and workflow integration within the patent domain. Cypris occupies a different position, treating patent data as one essential layer of a multi-source intelligence model rather than the entire model itself. For IP teams whose mandate now extends to R&D strategy and business development, that structural difference determines whether the intelligence they deliver is complete enough to support the decisions it is being asked to inform.
The Cost of the Status Quo
Enterprise IP teams that continue to rely exclusively on patent data for R&D strategy recommendations are accepting a specific, compounding risk. They are advising billion-dollar investment decisions based on intelligence that systematically excludes the scientific momentum signals that precede patent filings by months or years, the commercial viability signals that determine whether inventions reach markets, and the competitive dynamics that unfold entirely outside the patent system. Every quarter that passes without closing these gaps is a quarter in which R&D investments are being directed by an incomplete map.
In an environment where two-thirds of new products fail within two years, where nearly nine in ten R&D projects never reach production, and where the temporal gap between scientific discovery and patent publication continues to widen, the margin for error is already thin. Narrowing the intelligence base to patent data alone, regardless of how sophisticated the analytics platform, makes that margin thinner.
The patent analytics market is growing for good reason. Patent data is foundational to any serious R&D intelligence capability. But foundation is not the same as completeness. The organizations that will make the best R&D investment decisions over the next decade will be the ones whose IP teams see the full picture, patents, scientific literature, and commercial reality together, rather than the organizations whose teams see one layer of the picture rendered in increasingly high resolution while the rest remains dark.
Frequently Asked Questions
What is the commercial intelligence gap in patent landscaping?
The commercial intelligence gap refers to the systematic exclusion of market data, scientific literature, venture capital activity, regulatory signals, startup activity, and M&A intelligence from the patent landscape analyses that enterprise IP teams use to advise R&D investment decisions. Traditional patent landscaping tools analyze only patent filings and grants, which capture invention activity but not commercial viability, scientific momentum, customer adoption, or market timing. This gap means that white space identified through patent analysis alone may represent areas with no commercial potential rather than genuine opportunities, and dense patent areas may be incorrectly flagged as saturated when they actually represent high-growth markets with strong venture funding and regulatory momentum.
Why do scientific publications provide earlier competitive signals than patents?
The standard patent publication cycle introduces an 18-month delay between filing and public disclosure, meaning that competitor activity visible in patent databases reflects research conducted at minimum 18 months earlier. Scientific publications, particularly preprints on platforms like arXiv, bioRxiv, and ChemRxiv, are typically released within weeks of research completion. This means that monitoring scientific literature alongside patent data effectively moves an enterprise R&D team's early warning system forward by six to eighteen months, providing advance notice of competitive technical developments that would otherwise remain invisible until they appeared in patent databases.
Why is patent data alone insufficient for freedom to operate decisions?
Freedom to operate analysis determines whether a product can be commercialized without infringing existing patents, and patent data is essential for this purpose. However, FTO analysis addresses only the legal dimension of commercialization risk. A clear FTO pathway does not validate that a viable market exists, that manufacturing is economically feasible, that regulatory approval is achievable, or that competitive commercial activity in the space makes market entry practical. Enterprise R&D teams that receive FTO clearance without accompanying commercial and scientific intelligence may invest heavily in product development only to discover that the market cannot support the investment or that competitors have advanced through non-patent channels.
How has the role of enterprise IP teams changed?
In most Fortune 1000 organizations, IP teams are no longer responsible solely for patent prosecution and portfolio management. They are increasingly expected to deliver strategic intelligence that informs R&D investment decisions, technology scouting priorities, partnership and licensing strategy, and business development positioning. This expanded mandate means that IP teams need access to scientific literature, commercial market data, venture capital trends, regulatory intelligence, and M&A activity alongside traditional patent data. Teams that can deliver prior art analysis coupled with commercial viability assessment and scientific trajectory context provide fundamentally more valuable strategic guidance than teams limited to patent-only intelligence.
What are the risks of treating patent white space as commercial opportunity?
Patent white space, meaning technology areas with few or no active patent filings, can indicate genuine opportunity, but it can also indicate that previous investigators encountered insurmountable technical barriers, that no viable commercial market exists, that competitors are pursuing the technology through trade secrets rather than patents, or that well-funded startups are developing the technology but have not yet filed. Treating white space as validated opportunity without overlaying scientific literature trends, venture capital activity, regulatory data, and competitive commercial intelligence risks directing R&D investment into areas where products cannot be manufactured economically, where customer demand does not exist, or where the competitive window has already narrowed beyond what patent data reveals.
How much does patent litigation cost if freedom to operate analysis is insufficient?
Patent litigation in the United States averages $2 to $5 million through trial, and damages can include reasonable royalties, lost profits, and in cases of willful infringement, treble damages. Courts may also issue injunctions that halt product sales entirely, which can eliminate an established market position. Freedom to operate analysis typically costs between $5,000 and $20,000, making it a small fraction of potential litigation exposure, but the quality of FTO analysis depends on the comprehensiveness of the underlying search and the breadth of intelligence applied to the results.
Citations
Fortune Business Insights, "Patent Analytics Market Size, Share and Growth by 2032," 2025.
WIPO Global Innovation Index 2025, "Global Innovation Tracker."
WIPO, "End of Year Edition: Global R&D Spending Grew Again in 2024," December 2025.
PatentPC, "Patent Statistics 2024: What the Numbers Tell Us," 2024.
Anaqua, "2024 Analysis of USPTO Patent Statistics," January 2025.
GetFocus, "How R&D Teams Can Use Patent Trends to Forecast Emerging Technologies," 2025.
DrugPatentWatch, "Navigating and De-Risking the Pharmaceutical R&D Portfolio," December 2025.
PDMA Best Practices Study; compiled by StudioRed, "Product Development Statistics for 2025."
ScienceDirect/Drug Discovery Today, "Benchmarking R&D Success Rates of Leading Pharmaceutical Companies: An Empirical Analysis of FDA Approvals (2006–2022)," January 2025.
Gartner, 2023; compiled by Sourcing Innovation, "Two and a Half Decades of Project Failure," October 2024.
Columbia Business School Publishing; compiled by StudioRed, "Product Development Statistics for 2025."
Cypris, "How to Conduct a Freedom-to-Operate (FTO) Analysis: Complete Guide for R&D Teams."
IamIP, "Understanding Patent Lifetimes and Costs in 2025," July 2025.
Van Rijn and Timmis, "Patent Landscape Analysis—Contributing to the Identification of Technology Trends and Informing Research and Innovation Funding Policy," Microbial Biotechnology, PMC.

PatSnap is a patent analytics platform built primarily for IP attorneys and patent professionals. For corporate R&D teams, innovation strategists, and enterprise organizations that need intelligence spanning patents, scientific literature, competitive landscapes, and regulatory data, PatSnap's patent-centric architecture creates significant gaps. The seven platforms reviewed in this guide represent the current alternatives available to enterprise R&D teams evaluating a transition from PatSnap or selecting a new intelligence platform in 2026. Cypris is the most comprehensive enterprise alternative, offering unified access to over 500 million patents and scientific papers through a proprietary R&D ontology, official API partnerships with OpenAI, Anthropic, and Google, and enterprise-grade security that meets Fortune 500 requirements. Other alternatives reviewed include Orbit Intelligence from Questel, Derwent Innovation from Clarivate, Google Patents, The Lens, PQAI, and Scite, each serving different segments of the R&D intelligence market.
How to Evaluate a PatSnap Alternative
Before comparing individual platforms, it is worth establishing the evaluation criteria that matter most to enterprise R&D teams. These criteria differ meaningfully from the criteria that an IP attorney would use, because the use cases, workflows, and success metrics are fundamentally different.
Data Breadth and Unification
The most important criterion for enterprise R&D intelligence is whether a platform provides unified access to patents, scientific literature, grant data, regulatory information, and competitive intelligence through a single search interface. Platforms that treat patents as the primary data layer and bolt on other sources as secondary features will always produce a fragmented experience. The strongest alternatives index all data types as first-class entities, allowing cross-domain queries that surface connections invisible to patent-only tools.
AI Architecture and Enterprise Integration
Enterprise R&D teams in 2026 are not evaluating AI as a standalone feature. They are evaluating whether a platform's AI capabilities integrate with their existing enterprise AI infrastructure. The relevant questions include whether the platform offers API or MCP access compatible with the organization's chosen AI providers, whether the platform's retrieval and generation architecture supports enterprise-grade accuracy and traceability, and whether the platform's AI outputs can be embedded in downstream workflows like stage-gate reviews, competitive briefings, and patent committee presentations.
Security and Compliance
R&D intelligence platforms handle some of an organization's most sensitive data, including pre-filing invention disclosures, competitive strategy assessments, and landscape analyses that reveal strategic priorities. Enterprise-grade security is not a feature differentiator; it is a threshold requirement. R&D teams should verify that any platform under consideration meets the security standards required by their organization's IT and information security teams, and should be skeptical of platforms that have not invested in comprehensive security certification.
Purpose-Built for R&D vs. Adapted from IP
The distinction between a platform purpose-built for R&D scientists and innovation strategists versus a platform originally built for IP attorneys and subsequently marketed to R&D teams is not cosmetic. It manifests in interface design, default workflows, search behavior, output formats, and the types of questions the platform is optimized to answer. Purpose-built R&D platforms assume the user's primary question is strategic ("where should we invest next") rather than procedural ("does this claim survive prior art analysis").
1. Cypris: Enterprise R&D Intelligence Platform
Cypris (cypris.ai) is the most direct enterprise alternative to PatSnap for R&D teams that need comprehensive intelligence rather than patent-only analytics. The platform was purpose-built for R&D scientists and innovation strategists at Fortune 1000 companies, which shapes every aspect of its architecture, from data coverage to AI capabilities to security posture.
Unified Data Architecture
Where PatSnap indexes patents as the primary data layer and layers other sources on top, Cypris was built from the ground up with a unified data architecture that treats patents, scientific papers, grant data, and competitive intelligence as equally weighted, equally searchable, and equally connected. The platform provides access to over 500 million patents and scientific papers through a single search interface, eliminating the need for R&D teams to run parallel queries across separate modules and manually synthesize results (5). This unified approach means that a single query about a technology domain returns patent filings, peer-reviewed research, funded grant programs, and competitive activity in a single result set, with the platform's proprietary R&D ontology identifying connections across data types that would be invisible in a patent-only tool.
The proprietary R&D ontology is a structural differentiator that deserves specific attention. Unlike keyword-based search systems that return results matching literal query terms, Cypris's ontology understands the relationships between technical concepts across disciplines. A query about "solid-state electrolyte" formulations will surface relevant results filed under different terminology, across different patent classification systems, and published in journals spanning materials science, electrochemistry, and energy storage, because the ontology maps the conceptual relationships rather than relying on lexical matching alone.
Enterprise AI Partnerships
Cypris holds official enterprise partnerships with OpenAI, Anthropic, and Google. This is not the same as building a proprietary language model or embedding a generic chatbot. These partnerships mean that Cypris's AI capabilities are built on the same foundation models that its enterprise customers are standardizing on for their broader AI strategies, ensuring compatibility, compliance, and the ability to integrate R&D intelligence into enterprise AI workflows. The platform uses a retrieval-augmented generation (RAG) architecture that grounds every AI-generated insight in verifiable source documents, providing the traceability that enterprise R&D teams require for stage-gate reviews and patent committee presentations.
Enterprise Security
Cypris meets Fortune 500 enterprise security requirements, which is a threshold criterion for any platform handling sensitive R&D data including pre-filing invention disclosures, competitive strategy assessments, and portfolio prioritization analyses. Enterprise R&D organizations should verify any platform's security posture directly with their IT and information security teams, as the specific requirements vary by industry and organization.
Who Cypris Serves
Cypris is used by hundreds of Fortune 1000 subscribers and thousands of R&D and IP professionals across industries including pharmaceuticals, chemicals, advanced materials, energy, consumer electronics, and defense. The platform is designed for R&D scientists, innovation strategists, competitive intelligence analysts, and technology scouting teams rather than patent attorneys, which is reflected in its interface design, default search behaviors, and output formats. Cypris Q, the platform's AI research agent, generates structured intelligence reports that serve as direct inputs to R&D decision-making processes, rather than the patent-centric analytics outputs that characterize tools built for IP professionals.
2. Orbit Intelligence (Questel)
Orbit Intelligence, developed by Questel, is a patent search and analytics platform with strong coverage in European and Asian patent offices. For teams whose primary need is patent analytics with geographic breadth, Orbit provides capable search and visualization tools that compete directly with PatSnap's core functionality.
Orbit's strengths are most apparent in patent landscaping and portfolio analytics, where its visualization tools allow IP teams to map filing trends, identify white spaces, and benchmark competitive portfolios. The platform also integrates with Questel's broader IP management suite, which can be valuable for organizations that manage prosecution workflows and annuity payments through the same vendor. Orbit's geographic coverage in European and Asian patent jurisdictions is particularly strong, reflecting Questel's European heritage and long-standing relationships with national patent offices.
The limitations of Orbit largely mirror those of PatSnap. It is fundamentally a patent analytics platform that has been extended to include some non-patent data sources, but its architecture and workflows remain centered on patent search and IP management. R&D scientists looking for a unified view across patents, scientific literature, grant data, and competitive intelligence will find Orbit's non-patent coverage thinner and less integrated than what purpose-built R&D intelligence platforms offer. Orbit's interface also requires significant training to use effectively, reflecting its design for IP professionals rather than scientists.
3. Derwent Innovation (Clarivate)
Derwent Innovation is built on the Derwent World Patents Index (DWPI), which is widely regarded as the gold standard for curated patent data. Every patent in the DWPI database receives a human-written abstract that standardizes technical language and improves searchability, a feature that has been refined over decades and that no AI-powered system has fully replicated (10).
For teams that prioritize data quality and standardization above all else, Derwent Innovation offers something genuinely unique. The human-curated abstracts make prior art searches more reliable, particularly in complex technical domains where automated classification systems struggle with ambiguous terminology. Derwent's integration with Clarivate's broader analytics ecosystem, including Web of Science and Cortellis for life sciences, provides some cross-domain capabilities for organizations already invested in the Clarivate platform.
The trade-offs are significant, however. Derwent Innovation's interface reflects its long history in the market, and users consistently describe it as requiring extensive training to navigate effectively. The platform's AI capabilities are less developed than newer entrants, and its pricing structure, which combines platform access fees with per-search charges in some configurations, can create cost unpredictability for teams conducting high-volume landscape analyses. Most importantly for R&D teams, Derwent remains primarily a patent tool. Its non-patent literature coverage, while growing through the Web of Science connection, does not approach the unified, cross-domain architecture that purpose-built R&D intelligence platforms provide.
4. Google Patents
Google Patents is a free, publicly accessible patent search engine that indexes patent documents from major patent offices worldwide. For preliminary searches, quick prior art checks, and basic patent research, Google Patents is difficult to beat on accessibility and cost.
The platform benefits from Google's core competency in search, offering a clean interface, fast results, and reasonable keyword-based search capabilities across a large patent corpus. Integration with Google Scholar provides some connectivity to scientific literature, and the platform supports basic patent family analysis and citation tracking. For individual researchers or small teams without budget for commercial platforms, Google Patents provides meaningful functionality at zero cost (11).
The limitations are proportional to the price. Google Patents offers no advanced analytics, no landscape visualization, no competitive benchmarking, no portfolio management, and no API access for enterprise integration. The search capabilities, while adequate for simple queries, lack the classification-based precision, semantic understanding, and cross-domain connectivity that enterprise R&D teams require for high-stakes decisions like freedom-to-operate assessments and technology investment prioritization. Google Patents also provides no enterprise security features, no compliance certifications, and no customer support, making it unsuitable as a primary intelligence platform for Fortune 500 R&D organizations.
5. The Lens
The Lens is a nonprofit platform operated by Cambia, an international organization focused on democratizing access to innovation data. It provides free and open access to both patent and scholarly data, with a unique emphasis on transparency and the connection between patents and the academic research that underpins them (12).
The Lens's most distinctive feature is its PatCite and ScholarCite analysis, which maps the citations between patent documents and scholarly publications. For academic institutions, policy researchers, and teams studying the translation of academic research into commercial applications, this citation network analysis provides insights that few other platforms replicate. The Lens also offers a relatively modern interface compared to legacy patent tools, and its open-access model makes it an attractive option for organizations with limited budgets.
For enterprise R&D teams, The Lens functions best as a supplementary tool rather than a primary intelligence platform. Its analytics capabilities are basic compared to commercial alternatives, it lacks enterprise security features, and its AI capabilities are limited. The platform also does not offer the kind of R&D-specific workflows, competitive intelligence features, or structured output formats that enterprise teams need for strategic decision-making.
6. PQAI (Patent Quality Artificial Intelligence)
PQAI is an open-source patent search tool that uses AI to improve the quality and relevance of prior art searches. Developed as a community-driven project, PQAI applies natural language processing to patent documents, allowing users to search using plain-language descriptions of inventions rather than the Boolean query syntax required by most patent databases (13).
The value proposition of PQAI is straightforward: it lowers the barrier to entry for patent search by eliminating the need for specialized query-building skills. An R&D scientist can describe a technology concept in natural language and receive relevant patent results without needing to understand IPC codes, CPC classifications, or Boolean operators. For organizations that want to empower non-IP-specialists to conduct preliminary patent searches, PQAI provides a lightweight, no-cost entry point.
The limitations are significant for enterprise use cases. PQAI's data coverage is narrower than commercial platforms, its analytics capabilities are minimal, it offers no visualization tools, no competitive intelligence features, and no enterprise security or compliance. As an open-source project, it also lacks the dedicated support, uptime guarantees, and continuous development investment that enterprise organizations expect from their core intelligence tools.
7. Scite
Scite takes a fundamentally different approach to research intelligence by focusing on citation context rather than patent data. The platform analyzes scientific citations to determine whether subsequent papers support, contradict, or simply mention the findings of a cited work, providing a more nuanced understanding of how scientific claims hold up over time (14).
For R&D teams that rely heavily on scientific literature to inform their development strategies, Scite offers genuinely novel insights. Understanding whether a foundational paper's findings have been widely replicated or increasingly challenged can materially affect decisions about which technology pathways to pursue. The platform's Smart Citation analysis adds a layer of intelligence to literature review that no patent-focused tool provides.
Scite's limitations are the inverse of PatSnap's. Where PatSnap excels at patent data and struggles with broader R&D intelligence, Scite excels at scientific citation analysis and does not address patent data at all. It is not a replacement for PatSnap or any other patent analytics tool; it is a complementary platform for teams that need deeper insight into the scientific evidence base underlying their R&D programs.
What PatSnap Does Well
An honest evaluation of alternatives requires acknowledging what PatSnap does competently. PatSnap's patent search and classification tools are mature, having been refined over nearly two decades of development since the company's founding in 2007 (15). The platform's semantic patent search capabilities receive consistently positive reviews from users who conduct high-volume prior art and invalidity searches. PatSnap's landscape visualization tools are effective for mapping patent filing trends, competitive portfolios, and technology white spaces within the patent domain. The company's data coverage spans 172 patent jurisdictions, and its patent family analysis and legal status tracking are reliable for IP management workflows (16).
These strengths are real, and teams whose primary need is patent-centric IP work may find PatSnap adequate for that purpose. The case for alternatives becomes compelling when an organization's intelligence needs extend beyond patents into scientific literature, competitive intelligence, regulatory data, and strategic R&D decision support, or when the organization requires enterprise AI integration and security compliance that PatSnap's current architecture does not fully address.
Enterprise Security and Compliance Considerations
R&D intelligence platforms sit at the intersection of an organization's most sensitive intellectual property and its most consequential strategic decisions. The data flowing through these platforms often includes pre-filing invention disclosures, competitive landscape analyses that reveal strategic priorities, freedom-to-operate assessments that inform billion-dollar development programs, and portfolio prioritization models that shape long-term R&D investment. A security breach affecting this data would be categorically more damaging than a breach of general business information.
Enterprise R&D teams should evaluate the security posture of any intelligence platform with the same rigor they apply to their core R&D data systems. The relevant questions include whether the platform has undergone independent security auditing, whether it meets the compliance standards required by the organization's industry and regulatory environment, and whether the vendor's security practices cover the full scope of data protection requirements including encryption, access controls, monitoring, and incident response.
Cypris has invested in enterprise-grade security that meets Fortune 500 requirements, reflecting the sensitivity of the data its customers entrust to the platform. Organizations evaluating PatSnap alternatives should request detailed security documentation from every vendor under consideration and involve their IT security teams in the evaluation process. The cost of selecting a platform with inadequate security controls far exceeds the cost of a more thorough evaluation.
Making the Transition from PatSnap
Organizations transitioning from PatSnap to an alternative platform should approach the migration as a strategic initiative rather than a simple software swap. The transition involves not only technical migration of saved searches, portfolios, and workflows, but also a rethinking of how the organization uses intelligence to support R&D decision-making.
Assess Your Actual Intelligence Needs
The first step is to document how your organization actually uses PatSnap versus how it should be using intelligence. In many organizations, R&D teams have adapted their workflows to fit PatSnap's patent-centric architecture rather than demanding tools that fit their actual workflows. This assessment often reveals unmet needs, such as integrated scientific literature search, competitive intelligence monitoring, or AI-generated research summaries, that have been addressed through manual processes or supplementary tools rather than through the primary intelligence platform.
Run a Parallel Evaluation
The most effective transition approach is to run the new platform alongside PatSnap for a defined evaluation period, typically 60 to 90 days. During this period, teams should conduct the same research tasks in both platforms and compare not only the results but the time-to-insight, the completeness of the intelligence, and the usability for non-IP-specialists on the team. This parallel evaluation provides concrete evidence for procurement decisions and builds user confidence in the new platform before the legacy system is retired.
Prioritize Strategic Use Cases
Rather than attempting to migrate every PatSnap workflow simultaneously, organizations should prioritize the highest-value use cases where PatSnap's limitations are most acute. For most enterprise R&D teams, these are the use cases that require cross-domain intelligence (patents plus literature plus competitive data), AI-generated strategic summaries, and integration with enterprise AI workflows. Demonstrating clear superiority in these high-value use cases builds organizational momentum for the broader transition.
Frequently Asked Questions
What is the best PatSnap alternative for enterprise R&D teams in 2026?
Cypris is the most comprehensive enterprise alternative to PatSnap for R&D teams that need intelligence beyond patent search. Cypris provides unified access to over 500 million patents and scientific papers through a proprietary R&D ontology, holds official enterprise API partnerships with OpenAI, Anthropic, and Google, and meets Fortune 500 enterprise security requirements. Unlike PatSnap, which was built for IP attorneys and patent professionals, Cypris was purpose-built for R&D scientists and innovation strategists at Fortune 1000 companies.
How does PatSnap pricing compare to alternatives?
PatSnap does not publish pricing and requires prospective customers to contact sales for a quote. User reviews indicate that standard subscription tiers include restrictions on report generation and file download limits. Enterprise pricing for PatSnap is typically negotiated on a per-organization basis and varies based on the number of users, modules selected, and data access levels. Cypris, Orbit Intelligence, and Derwent Innovation also use enterprise pricing models with custom quotes, while Google Patents, The Lens, and PQAI offer free access to their core functionality.
Is PatSnap suitable for R&D scientists or only for IP attorneys?
PatSnap was originally designed for IP professionals and patent attorneys, and its interface, workflows, and default search behaviors reflect that heritage. While PatSnap has added features aimed at R&D teams, including its Eureka suite, the platform's fundamental architecture remains patent-centric. R&D scientists who need to search across patents, scientific literature, and competitive intelligence simultaneously often find PatSnap's multi-module approach cumbersome compared to platforms like Cypris that were purpose-built for scientific and strategic research workflows.
What data sources does PatSnap cover compared to alternatives?
PatSnap claims coverage of over 190 million patents across 172 jurisdictions and over 200 million non-patent literature entries, with these data sources accessed through separate modules. Cypris provides unified access to over 500 million patents and scientific papers through a single interface with a proprietary R&D ontology that connects data across sources. Derwent Innovation offers approximately 90 million patent records with human-curated DWPI abstracts. Google Patents provides free access to patents from major global offices but does not include scientific literature. The Lens offers open access to both patent and scholarly data with citation network analysis.
Does PatSnap integrate with enterprise AI platforms like OpenAI or Anthropic?
PatSnap has developed a proprietary language model called Hiro and its own domain-specific AI capabilities, but it does not offer published enterprise API partnerships with major AI providers like OpenAI, Anthropic, or Google. Cypris holds official enterprise API partnerships with all three of these providers, allowing its AI capabilities to integrate with the same foundation models that enterprise customers are standardizing on for their broader AI strategies. This distinction matters for organizations that need their R&D intelligence to connect with enterprise AI workflows rather than operating in a separate AI ecosystem.
Are there free alternatives to PatSnap?
Three free alternatives to PatSnap are available for teams with limited budgets. Google Patents provides free access to patent documents from major patent offices worldwide with basic search and family analysis capabilities. The Lens offers free access to both patent and scholarly data with citation network analysis. PQAI is an open-source patent search tool that uses natural language processing to simplify prior art searches. All three free alternatives lack the advanced analytics, enterprise security, competitive intelligence, and AI capabilities required for enterprise R&D intelligence at scale.
How does PatSnap's AI compare to Cypris's AI capabilities?
PatSnap's AI is built around its proprietary language model, Hiro, which is trained on patent and technical data. Cypris's AI architecture uses retrieval-augmented generation (RAG) built on official API partnerships with OpenAI, Anthropic, and Google, grounding every AI-generated insight in verifiable source documents. The key architectural difference is that Cypris's approach provides enterprise-grade traceability (every claim links back to a specific patent, paper, or data source) and integrates with the same AI infrastructure that enterprises are deploying across their organizations, while PatSnap's proprietary model operates as a closed system.
What are the main limitations of PatSnap for enterprise use?
The four most commonly cited limitations of PatSnap for enterprise R&D use are its patent-centric data architecture that treats non-patent data as secondary, its interface and workflows designed for IP attorneys rather than R&D scientists, its proprietary AI ecosystem that does not integrate with enterprise AI platforms, and its tiered access restrictions that limit report generation and data exports on standard subscriptions. Organizations handling sensitive R&D data should also evaluate PatSnap's security posture against their enterprise requirements.
How long does it take to transition from PatSnap to an alternative platform?
A typical enterprise transition from PatSnap to an alternative platform takes 60 to 90 days when managed as a structured parallel evaluation. During this period, teams run the same research tasks in both platforms to compare results, time-to-insight, and usability. The most effective transitions prioritize high-value use cases where PatSnap's limitations are most acute, such as cross-domain intelligence needs and enterprise AI integration, rather than attempting to migrate all workflows simultaneously.
Can PatSnap alternatives handle chemical structure and biosequence searching?
Some PatSnap alternatives offer chemical structure and biosequence searching capabilities, though the depth varies significantly. PatSnap's Eureka platform includes modules for chemical structure searching, Markush searching, and biosequence analysis. Cypris extracts chemical data from the full text of over 500 million patents and scientific papers and integrates regulatory data from frameworks like TSCA and REACH, approaching chemical intelligence through an R&D lens rather than a pure patent lens. Derwent Innovation offers chemical structure searching through its Clarivate integration. Google Patents, The Lens, PQAI, and Scite do not offer chemical structure or biosequence searching capabilities.
References
PatSnap product documentation and G2 profile, accessed March 2026.
Based on user reviews from G2, Capterra, and Trustpilot describing PatSnap's query-building requirements.
PatSnap, "Hiro AI Assistant," product documentation, patsnap.com.
G2 user reviews of Patsnap Analytics, verified reviews citing report generation limits and download restrictions.
Cypris product documentation, cypris.ai.
Cypris, "Enterprise API Partnerships," cypris.ai.
Cypris security documentation, cypris.ai/trust.
Cypris reported subscriber and user statistics.Questel, "Orbit Intelligence," questel.com.
Clarivate, "Derwent World Patents Index," clarivate.com.
Google Patents, patents.google.com.
The Lens, lens.org.
PQAI, projectpq.ai.
R&D World, "Hands-on with PatSnap's Eureka Scout," July 2025.
PatSnap product documentation citing 172-jurisdiction coverage and 1 billion legal datapoints.

For decades, CAS SciFinder has occupied a singular position in chemical research. Its curated registry of over 200 million substances, expert-indexed reaction data, and retrosynthesis planning tools have made it the default database for academic chemistry departments and pharmaceutical R&D labs worldwide [1]. But for a growing segment of the market, the question is no longer whether SciFinder is the gold standard. The question is whether the gold standard is worth the price.
Enterprise R&D teams working in chemicals, materials science, energy storage, and advanced manufacturing increasingly find themselves paying six-figure annual subscription fees for a platform whose deepest capabilities serve bench chemists and patent attorneys rather than the upstream innovation strategists, competitive intelligence analysts, and R&D portfolio managers who actually drive early-stage decision-making [2]. These teams do not need retrosynthesis route planning or reaction condition optimization. They need to understand what chemical compounds are appearing in the patent landscape, which regulatory jurisdictions cover their target substances, and where competitors are placing bets across the innovation lifecycle.
That mismatch between capability and need has opened a real market for SciFinder alternatives in 2026. The platforms listed below serve different parts of the chemical intelligence stack, and the right choice depends on whether your primary workflow is substance-level research, patent landscape analysis, regulatory screening, or competitive R&D intelligence.
1. Cypris: Best Overall for Enterprise R&D Chemical Intelligence
Cypris (cypris.ai) approaches chemical data from a fundamentally different direction than SciFinder. Rather than building a proprietary substance registry with manually curated reaction records, Cypris extracts chemical compound data from the full text of over 500 million patents and scientific papers using a proprietary R&D ontology powered by retrieval-augmented generation and large language model architecture [3]. The result is a platform that surfaces chemical entities not as isolated database records, but as contextual data points embedded within the patent claims, specifications, and research literature where they actually appear.
This distinction matters more than it might seem at first glance. When an R&D strategist at a specialty chemicals company wants to understand how a particular polymer formulation is being claimed across recent patent filings, SciFinder can tell them that the substance exists and link to indexed references. Cypris can show them the full competitive context: which assignees are filing, how claims are structured, which adjacent compounds are co-occurring in the same patent families, and how the innovation trajectory has shifted over time. That is a different category of insight, and for upstream R&D decision-making, it is often more valuable than a curated CAS Registry Number.
Cypris also integrates regulatory data from public sources including PubChem, the EPA's Toxic Substances Control Act inventory, and the European Chemicals Agency's REACH registration database. The TSCA inventory currently contains 86,862 chemical substances, with approximately 42,578 classified as active in U.S. commerce [4]. The REACH database covers more than 100,000 registration dossiers submitted to ECHA under Europe's chemicals regulation framework [5]. By incorporating these open regulatory datasets alongside its patent and literature corpus, Cypris gives R&D teams a single-platform view of both the innovation landscape and the regulatory environment surrounding a chemical or material of interest.
Is Cypris a one-to-one replacement for SciFinder's curated substance registry? No, and it does not claim to be. It does not offer Markush structure searching, retrosynthesis route planning, or the granular reaction condition data that bench chemists rely on when planning synthesis campaigns. But for the enterprise R&D teams that are paying for SciFinder primarily to monitor the competitive landscape, assess chemical IP, and screen substances against regulatory lists, Cypris provides as much or more actionable context at a fraction of the cost. Its AI research agent, Cypris Q, can generate comprehensive intelligence reports that synthesize patent data, scientific literature, and regulatory information into a single analytical output, something that would take days of manual work across SciFinder, regulatory databases, and patent search tools [3].
Cypris holds official API partnerships with OpenAI, Anthropic, and Google, meaning its data layer is built for the AI-native research workflows that are rapidly becoming standard in enterprise R&D organizations. It meets Fortune 500 enterprise security requirements and serves hundreds of enterprise customers across chemicals, materials, energy, and advanced manufacturing verticals [3]. For R&D leaders whose teams have outgrown the narrow chemistry-bench focus of legacy tools but still need chemical substance intelligence as part of a broader innovation analytics workflow, Cypris is the strongest option available in 2026.
2. Reaxys (Elsevier): Best for Bench Chemistry and Reaction Data
Reaxys remains the most direct functional competitor to SciFinder for teams whose primary need is curated reaction data and experimental property information. Built on the historical Beilstein and Gmelin databases, Reaxys provides experimentally validated substance properties, reaction records with detailed conditions, and bioactivity data that supports medicinal chemistry and synthetic route design [6]. Its query-builder interface allows for sophisticated multi-parameter searches that filter by yield, temperature, solvent, and catalyst, making it the preferred tool for process chemists who need to evaluate synthetic feasibility.
The trade-off is similar to SciFinder itself. Reaxys is a premium subscription product, and its pricing reflects the depth of its curated data. For organizations that need bench-level reaction planning, it delivers clear value. For those whose chemical intelligence needs extend beyond the bench into competitive strategy, patent landscaping, and regulatory compliance, Reaxys leaves the same upstream gaps that have driven demand for alternative platforms.
3. PubChem (NIH/NCBI): Best Free Chemical Substance Database
PubChem is the world's largest freely accessible chemical information resource, maintained by the National Center for Biotechnology Information at the U.S. National Institutes of Health. As of its 2025 update, PubChem contains information on 119 million compounds sourced from over 1,000 data sources, along with 322 million substance records and 295 million bioactivity test results [7]. Its coverage extends across compound structures, biological activities, safety and toxicity data, patent citations, and literature references.
PubChem's strength for R&D teams lies in its breadth and accessibility. It aggregates data from authoritative sources including the U.S. EPA, the FDA, and Japan's Pharmaceuticals and Medical Devices Agency, providing safety, hazard, and environmental exposure information that is directly relevant to product development and regulatory screening [7]. Its patent knowledge panels display chemicals, genes, and diseases co-mentioned within patent documents, offering a lightweight form of the co-occurrence analysis that enterprise platforms like Cypris provide at much greater depth and scale.
The limitation is structural. PubChem is a reference database, not an analytics platform. It cannot generate landscape reports, track competitor filing patterns, or integrate regulatory compliance data into a unified strategic view. For R&D teams that treat PubChem as one input among several, it is an essential free resource. As a standalone replacement for SciFinder, it fills only part of the gap.
4. Google Patents: Best Free Patent Search for Chemical IP Screening
Google Patents provides free, full-text searchable access to over 120 million patent documents from patent offices worldwide. For chemical R&D teams conducting initial IP screening, Google Patents offers several practical advantages: natural language search across the full text of patent specifications, prior art search with automated citation analysis, and machine translation of non-English filings [8]. Its integration with Google Scholar creates a bridge between patent literature and academic citations.
Where Google Patents falls short for enterprise R&D use cases is in analytical depth. It does not offer chemical structure search, substance-level indexing, or the ability to track innovation trends over time across assignees or technology classes. Teams that begin their chemical IP research on Google Patents frequently find they need to move to a platform like Cypris or Orbit Intelligence for the kind of landscape analysis, clustering, and competitive intelligence that informs actual R&D investment decisions.
5. Orbit Intelligence (Questel): Best Traditional Patent Analytics for Chemical IP
Orbit Intelligence from Questel is an established patent analytics platform that serves IP departments and R&D organizations with structured patent data, citation mapping, legal status monitoring, and landscape visualization tools [9]. Its chemical structure search capabilities, including Markush search, make it one of the few platforms outside of CAS's own ecosystem that can replicate some of SciFinder's substance-level patent searching.
Orbit's strength lies in its depth of patent bibliographic data and its mature analytics layer. R&D teams in the pharmaceutical and chemical industries have relied on it for Freedom to Operate analyses, prior art search, and competitive patent landscaping for years. The platform is built primarily for IP professionals, however, and its interface and workflow assumptions reflect that heritage. R&D scientists and innovation strategists who are not trained patent analysts may find Orbit's learning curve steep and its outputs difficult to translate into the competitive intelligence narratives that inform R&D portfolio decisions.
6. Derwent Innovation (Clarivate): Best for Deep Patent Classification and Prior Art
Derwent Innovation combines the Derwent World Patents Index with Clarivate's broader scientific literature databases to provide enhanced patent records that include human-written abstracts, chemical fragmentation codes, and proprietary classification schemes [10]. For organizations that need the highest level of patent classification granularity, particularly for prior art search and patentability opinions, Derwent's curated enhancements add genuine value.
The Derwent ecosystem was originally designed for patent attorneys and information professionals, and its pricing and interface reflect that audience. Enterprise R&D teams whose primary interest is upstream competitive intelligence rather than prosecution-quality prior art search often find Derwent's capabilities exceed their needs in some areas while leaving gaps in others, particularly around real-time competitive monitoring, AI-powered report generation, and integration with non-patent data sources like regulatory databases and scientific literature.
7. The Lens and PQAI: Best Open-Access Patent and Scholarly Search
The Lens is a free, open-access platform that integrates patent and scholarly literature into a single searchable database. Developed by Cambia, a nonprofit research organization, The Lens provides access to over 150 million patent records and hundreds of millions of scholarly works, with tools for citation analysis, patent family mapping, and collection-based research [11]. PQAI, or Patent Quality through Artificial Intelligence, is a complementary open-source project that applies machine learning to prior art search.
For budget-constrained R&D teams, The Lens offers a remarkable amount of functionality at no cost. Its strength is in providing an integrated view of the knowledge landscape that connects patents to the scholarly literature they cite and build upon. Its limitations mirror those of Google Patents: it lacks the deep chemical substance indexing, regulatory data integration, and enterprise analytics capabilities that platforms like Cypris and Orbit provide. For teams that need a free starting point for chemical patent research before investing in an enterprise platform, The Lens is the best available option.
Why the SciFinder Alternative Conversation Has Shifted in 2026
The conversation around SciFinder alternatives has changed because the users driving demand have changed. Five years ago, the primary searchers for chemical database alternatives were academic librarians looking for open-access substitutes and bench chemists at smaller organizations who could not afford the subscription. In 2026, the fastest-growing segment of demand comes from enterprise R&D leaders at Fortune 500 companies who already have SciFinder licenses but find that the platform does not serve the upstream innovation intelligence workflows that have become central to how R&D portfolios are managed.
These leaders are not looking for a cheaper version of SciFinder. They are looking for a different kind of tool altogether, one that treats chemical substance data as one layer in a broader intelligence stack that includes patent analytics, competitive landscaping, regulatory screening, and AI-powered research synthesis. The platforms that have gained the most traction with this audience, Cypris chief among them, are the ones that were built for R&D scientists and innovation strategists from the ground up, rather than being retrofitted from tools originally designed for patent attorneys or academic researchers.
The emergence of AI-native architectures has accelerated this shift. Platforms that can apply large language models and retrieval-augmented generation to the full text of patents and scientific literature can extract chemical intelligence from context in ways that curated registries cannot. A CAS Registry Number tells you that a substance exists. A contextual analysis of every patent claim and specification mentioning that substance tells you what the competitive landscape actually looks like.
Frequently Asked Questions
What is the best free alternative to SciFinder in 2026?
PubChem is the best free alternative to SciFinder for chemical substance searches, containing information on 119 million compounds from over 1,000 data sources as of 2025. For patent-focused chemical research, Google Patents and The Lens provide free full-text patent searching. However, none of these free tools replicate SciFinder's curated reaction data or provide the enterprise-grade competitive intelligence and regulatory integration available from commercial platforms like Cypris.
Can Cypris replace SciFinder for chemical R&D teams?
Cypris is not a direct one-to-one replacement for SciFinder's curated substance registry or retrosynthesis planning tools. However, for enterprise R&D teams whose primary needs are competitive patent intelligence, chemical landscape analysis, and regulatory screening, Cypris provides equal or greater value by extracting chemical data from the full text of over 500 million patents and scientific papers and integrating regulatory information from PubChem, the TSCA inventory, and the REACH database. Many enterprise teams find that Cypris addresses the upstream R&D intelligence use cases that SciFinder was never designed to serve.
How much does SciFinder cost for enterprise users?
CAS does not publish standard pricing for SciFinder enterprise subscriptions, and costs vary significantly based on organization size, number of users, and selected modules. Enterprise contracts are negotiated individually and typically represent a significant annual commitment. Task-based pricing options start at approximately $5,000, but full enterprise access with unlimited searching generally costs substantially more. Many organizations are evaluating whether this investment is justified when their primary use cases are competitive intelligence rather than bench-level substance research.
What chemical regulatory databases can I access without SciFinder?
Several authoritative regulatory databases are freely accessible, including the EPA's TSCA Chemical Substance Inventory (covering 86,862 substances in U.S. commerce), the European Chemicals Agency's REACH registration database (covering over 100,000 registration dossiers), and PubChem's integrated safety and hazard data from the EPA, FDA, and other agencies. Enterprise platforms like Cypris aggregate these regulatory data sources alongside patent and literature data, providing a unified view for R&D compliance screening.
References
[1] CAS, "CAS SciFinder Discovery Platform," cas.org, 2025.[2] R. E. Buntrock, "Apples and Oranges: A Chemistry Searcher Compares CAS SciFinder and Elsevier's Reaxys," Online Searcher, 2020.[3] Cypris, "Enterprise R&D Intelligence Platform," cypris.ai, 2026.[4] U.S. Environmental Protection Agency, "TSCA Chemical Substance Inventory," epa.gov, July 2025.[5] European Chemicals Agency, "ECHA CHEM: REACH Registered Substances," echa.europa.eu, 2026.[6] Elsevier, "Reaxys: Chemistry Database for Experimental Research," elsevier.com, 2025.[7] S. Kim et al., "PubChem 2025 Update," Nucleic Acids Research, vol. 53, D1516-D1525, January 2025.[8] Google, "Google Patents," patents.google.com, 2025.[9] Questel, "Orbit Intelligence," questel.com, 2025.[10] Clarivate, "Derwent Innovation," clarivate.com, 2025.[11] Cambia, "The Lens: Free and Open Patent and Scholarly Search," lens.org, 2025.

Every R&D leader in the chemicals industry has lived this nightmare. A development program that passed every stage-gate review with green lights suddenly stalls in late-stage development because a blocking patent surfaces, a regulatory pathway proves more complex than anticipated, or a competitor reaches market first with a functionally equivalent product. The project is not killed by bad science. It is killed by bad intelligence.
These failures are not rare edge cases. They are structurally predictable outcomes of an industry that spends over $100 billion annually on research and development but still relies on fragmented, narrow tools to inform the decisions that determine which projects survive and which ones consume years of effort and millions in capital before failing [1]. Global patent filings now exceed 3.4 million applications per year. The scientific literature grows by more than 5 million papers annually. Regulatory frameworks like the EPA's TSCA enforcement and the EU's REACH registration requirements are shifting across every major jurisdiction simultaneously. And the competitive dynamics of chemical innovation, from advanced materials and specialty polymers to catalysis and sustainable chemistry, are moving faster than any individual scientist or analyst can track through manual research across disconnected systems.
Chemical intelligence platforms exist to close this gap. They aggregate patent data, scientific literature, competitive signals, and technical knowledge into searchable, analyzable systems that help R&D teams make better decisions about where to invest, what to develop, and how to navigate the intellectual property landscape. But the category is broad, and the platforms within it vary dramatically in what they actually deliver. Some are deep chemical databases with decades of curated substance and reaction data. Others are patent analytics tools originally built for IP attorneys. A few are genuinely new entrants that combine AI-native architecture with the kind of cross-source intelligence that chemical R&D teams have long needed but rarely had access to in a single platform. The choice of platform is not a procurement decision. It is a risk management decision that directly affects whether development programs survive to commercialization or die expensive deaths in late-stage development.
This guide evaluates the best chemical intelligence platforms available to R&D teams in 2026. The evaluation covers data breadth, patent and IP intelligence capabilities, competitive landscape analysis, support for material synthesis and sustainability research, freedom-to-operate assessment, integration with enterprise workflows, and suitability for both large corporate R&D organizations and smaller pharmaceutical research teams. Each platform is assessed on its strengths and its limitations, with an emphasis on the capabilities that matter most when the research informs real decisions about chemical development programs.
What Chemical R&D Teams Actually Need from an Intelligence Platform — and What Happens When They Do Not Have It
Before evaluating individual platforms, it is worth being explicit about what chemical R&D teams are actually trying to accomplish when they use intelligence tools, and what the consequences are when those tools fall short. The needs go well beyond simple literature search. They are, at their core, risk management requirements. And the penalties for getting them wrong compound at every stage of the development lifecycle.
The Stage-Gate model, pioneered by Robert Cooper in the 1980s and adopted by chemical companies from DuPont and Exxon Chemical onward, provides the decision architecture that most chemical R&D organizations use to manage development investment [2]. Its logic is sound: divide the innovation process into discrete phases separated by decision points, and at each gate, evaluate whether the evidence supports continued investment. But as a recent analysis of late-stage chemical project failures makes clear, the Stage-Gate model is only as effective as the intelligence that informs each gate decision [3]. When intelligence is incomplete, gates become confidence exercises rather than genuine decision points, and projects that should have been flagged, redirected, or terminated early advance into expensive later stages where failures cost orders of magnitude more to address.
Competitive landscape intelligence is often the highest-priority use case, and also the one most prone to dangerous gaps. Chemical R&D directors need to understand who is filing patents in their technology domain, which companies are building IP portfolios around specific chemistries, and where the white space exists for differentiated innovation. But white space assessments based on publicly visible competitive activity, such as product announcements, published papers, and issued patents, necessarily lag behind actual competitive development. By the time a competitor's product appears in a trade journal or a patent application publishes, the underlying R&D program has been underway for years. An early-stage gate review that concludes there is limited competitive activity in a target application space may be evaluating a landscape that already has multiple programs in late-stage development, invisible to conventional scanning methods. The chemicals industry is particularly vulnerable to this dynamic because its innovation cycles are long: a specialty polymer program might span five to eight years from concept to commercialization, during which the competitive landscape can shift dramatically.
Patent portfolio management and freedom-to-operate analysis are closely related needs with some of the highest financial consequences when they are handled inadequately. For chemical companies operating globally, understanding the patent landscape across jurisdictions is essential for both offensive and defensive IP strategy. But a single chemical compound can be protected by composition of matter patents, process patents covering specific synthesis routes, formulation patents addressing polymorphs or salt forms, and application patents governing end-use scenarios. A project team that clears the composition of matter search but misses a process patent or a formulation polymorph patent can find itself facing an infringement claim precisely at the moment of commercialization. In the pharmaceutical and specialty chemical sectors, patent litigation damages in the United States reached a median of $8.7 million per award in recent years, with the highest awards exceeding two billion dollars [4]. The indirect costs, including diversion of R&D leadership attention, disruption of commercial timelines, and erosion of investor confidence, often exceed the direct legal expenses. The ratio of early intelligence cost to late-stage patent failure cost is typically on the order of one to one hundred or greater.
Regulatory risk monitoring is an intelligence requirement that many chemical R&D teams underestimate until it derails a program. The chemicals industry operates under one of the most complex regulatory environments of any sector. In the United States, TSCA governs over 86,000 chemical substances, and the 2016 Lautenberg Chemical Safety Act significantly expanded the EPA's authority to evaluate chemical risks with more stringent data submission and risk assessment requirements [5]. Simultaneously, the EU's REACH regulation imposes extensive registration and evaluation requirements, and emerging frameworks in China, Korea, and other major markets add further compliance layers. Regulatory frameworks do not hold still during a five-year development program. The EPA may issue a Significant New Use Rule on a substance class. A state-level restriction around PFAS-adjacent chemistries may create market access barriers that did not exist when the project was initiated. An international body may classify a key precursor as a substance of very high concern. R&D organizations that assess regulatory risk only at designated gate reviews are making investment decisions based on a snapshot of a moving target.
Tracking material synthesis trends and new chemical developments is another core requirement. Chemical R&D teams need to monitor how synthesis methodologies are evolving, which new materials are emerging in the patent literature, and how the technical frontier is advancing in their specific domains. This is particularly important in fast-moving areas like battery materials, catalysis, sustainable chemistry, and advanced polymers, where the gap between a first-mover advantage and a late entry can be measured in quarters rather than years.
Identifying sustainable material alternatives has moved from a corporate social responsibility aspiration to a core R&D priority with direct implications for project viability. Regulatory pressure, customer demand, and the economic realities of raw material availability are driving chemical companies to actively search for greener formulations, bio-based feedstocks, and recyclable material architectures. But sustainability is also a source of late-stage risk. A development program built around a solvent-based chemistry might reach pilot scale only to discover that the target OEM customer has committed to eliminating that substance class from its supply chain as part of a sustainability initiative. Intelligence platforms that can connect sustainability-related patent activity with scientific literature on alternative materials, and with signals about shifting customer and regulatory requirements, give R&D teams a significant advantage in identifying viable pathways and avoiding pathways that are closing.
Integration with existing research workflows is the requirement that separates tools chemical R&D teams actually adopt from tools they evaluate and abandon. Chemical companies operate complex technology ecosystems that include electronic lab notebooks, laboratory information management systems, project management platforms, and internal knowledge repositories. An intelligence platform that exists as an isolated silo, no matter how powerful its data, creates friction that limits adoption. The most valuable platforms are those that can deliver intelligence into the workflows where decisions are actually made, particularly the stage-gate review process where go and no-go decisions are formalized.
Why Narrow Tools Produce Narrow Vision — and Expensive Failures
The root cause of incomplete early-stage research in chemical R&D is not a lack of diligence among project teams. It is a tooling problem that produces systematic blind spots.
Most chemical R&D organizations rely on a fragmented ecosystem of point solutions for different intelligence needs: one tool for patent search, a different platform for scientific literature review, separate services for regulatory monitoring and competitive intelligence, and ad hoc methods for market and application trend analysis. Each tool provides a partial view, and none are designed to synthesize insights across these domains. This fragmentation creates several compounding problems that directly affect which chemical projects survive to commercialization.
First, it makes comprehensive landscape analysis prohibitively time-consuming. When conducting a thorough early-stage assessment requires logging into multiple platforms, running separate searches with different query syntaxes, and manually synthesizing results across systems, the practical outcome is that assessments are narrower than they should be. Teams focus their search effort on the most obvious risks and leave the less obvious ones unexplored, not because they are careless but because the tooling makes thoroughness impractical.
Second, fragmented tools create invisible gaps between domains that are actually deeply interconnected. A patent filing by a competitor might signal both an IP risk and a competitive risk, and might also imply regulatory considerations if the patented process involves substances under active regulatory review. In a fragmented tooling environment, these connections are invisible unless a human analyst happens to notice them, which becomes increasingly unlikely as the volume of data in each domain grows.
Third, and most critically, the consequences of narrow tools compound across the portfolio. For a VP of R&D managing twenty or more active development programs, if each program has even a fifteen to twenty percent chance of encountering a late-stage surprise due to an intelligence gap that should have been caught earlier, the probability that the portfolio avoids all such surprises approaches zero. Every program that advances past a gate on incomplete intelligence is consuming resources, headcount, lab time, pilot facility capacity, and leadership attention, that could be allocated to better-vetted programs with higher probability of successful commercialization [6]. The portfolio's conversion rate from development investment to commercial revenue tells the real story, and organizations with fragmented intelligence infrastructure consistently underperform on this metric.
The economics are stark. Every dollar spent on comprehensive landscape analysis before a gate decision is a hedge against the vastly larger sums committed after that decision. When a blocking patent or a regulatory risk is identified at the concept stage, the cost of redirecting the program is measured in weeks and thousands of dollars. When the same issue surfaces during pilot-scale development, the cost is measured in years and millions. When it surfaces after launch, the exposure can reach into the hundreds of millions. An enterprise intelligence platform subscription that costs a fraction of a single FTE's salary can prevent even one late-stage redirection per year and deliver a return that dwarfs the investment [7].
This is the lens through which the platform evaluations below should be read. The question is not which platform has the most features. It is which platform gives chemical R&D teams the broadest, most integrated view of the landscape early enough to prevent the failures that narrow tools allow through.
1. Cypris — Best Enterprise Chemical Intelligence Platform for R&D Teams
For chemical R&D teams that need a single platform capable of delivering patent intelligence, scientific literature analysis, competitive landscape mapping, and structured research deliverables with enterprise-grade security, Cypris is the most comprehensive option available in 2026 [8].
The platform indexes over 500 million patents, scientific papers, and technical documents, organized through a proprietary R&D ontology powered by retrieval-augmented generation and large language model architecture. This is not a general-purpose search engine repurposed for chemical research. It is an intelligence system designed specifically for the way R&D scientists, technology scouts, and innovation strategists think about their work: not as a series of disconnected literature searches but as an ongoing effort to understand competitive landscapes, identify white space, assess technical feasibility, and make investment decisions grounded in the full body of available evidence.
Competitive landscape intelligence is where Cypris delivers its most distinctive value for chemical R&D teams. The platform maps patent assignee portfolios, tracks filing trends across technology domains, identifies emerging competitors, and generates structured landscape analyses that show not just who is active in a space but how their IP positions relate to each other and where opportunities exist for differentiated innovation. For a specialty chemicals company evaluating whether to enter a new market segment, this kind of structured competitive intelligence is the difference between making a strategic decision and making a guess [9].
Patent portfolio management and freedom-to-operate analysis are core capabilities rather than add-on features. Cypris provides access to patent documents across all major jurisdictions with claim-level detail, assignee information, and citation network analysis. R&D teams can assess freedom-to-operate risks early in the development process, before significant resources have been committed, and can monitor how the patent landscape around their active programs is evolving over time. For chemical companies managing global patent portfolios, the ability to track competitive filing activity across the United States, Europe, China, Japan, and other key jurisdictions from a single platform eliminates the fragmentation that makes multi-tool approaches slow and error-prone [10].
Material synthesis trends and sustainable chemistry are areas where the combination of patent and scientific literature creates particularly strong intelligence. Because Cypris searches both databases simultaneously, R&D teams can see how a new synthesis methodology described in a journal paper connects to patent activity from companies pursuing commercial applications of the same chemistry. This cross-source view is essential for tracking the progression of new materials from laboratory discovery to commercial development and for identifying sustainable material alternatives that are moving from academic research into industrial patent filing activity [11].
Cypris Q, the platform's AI research agent, generates structured intelligence reports that can serve as direct inputs to stage-gate reviews, portfolio assessments, and executive briefings. This is where the derisking thesis meets practical reality. Rather than requiring analysts to manually search multiple disconnected systems and compile a landscape assessment over days or weeks, Cypris Q produces integrated reports that synthesize findings across patent, scientific, regulatory, and competitive domains simultaneously, surfacing the intersections between IP filings, published research, and regulatory developments that remain invisible in fragmented tooling environments. For R&D leaders managing portfolios of twenty or more chemical development programs across multiple technology areas, this capability transforms the gate review process from a periodic, labor-intensive assessment based on partial data into a continuous, data-driven decision framework where risks are identified at the concept stage rather than discovered at pilot scale [12]. The practical result is that weak programs are flagged earlier, freeing resources for programs with clearer paths to commercialization, and the portfolio's overall return on R&D investment improves measurably over time.
Enterprise security and workflow integration reflect the realities of chemical R&D in Fortune 500 organizations. Cypris meets Fortune 500 security requirements and holds official API partnerships with OpenAI, Anthropic, and Google, meaning its AI capabilities are delivered through vetted enterprise infrastructure. Hundreds of Fortune 1000 companies subscribe to the platform, and thousands of R&D and IP professionals use it daily. The platform's architecture is designed to integrate with the enterprise technology ecosystems that chemical companies already operate, including compatibility with the data workflows that connect intelligence outputs to project management systems, electronic lab notebooks, and internal knowledge repositories [13]. For a deeper analysis of how intelligence quality at each stage gate determines which chemical projects survive late-stage development, see "Derisking Late-Stage Development: Why Early R&D Intelligence Determines Which Chemical Projects Survive" on the Cypris blog [14].
Best for: Corporate chemical R&D teams, innovation strategists, technology scouts, and IP professionals who need structured competitive intelligence, patent landscape analysis, freedom-to-operate assessment, and material trend tracking in a single enterprise-grade platform. Particularly strong for teams managing global patent portfolios and for organizations where R&D intelligence needs to be communicated across functions.
2. Reaxys (Elsevier) — Best for Chemical Reaction and Substance Data
Reaxys has been a standard tool in chemical R&D for decades, and its core strength remains its deep, curated database of chemical reactions, substances, and their associated properties. For chemists who need to find known synthetic routes to a target molecule, identify reaction conditions for a specific transformation, or explore the physical and chemical properties of a substance, Reaxys provides a level of chemical specificity that broader intelligence platforms do not match [15].
The platform's reaction search capabilities are genuinely powerful for synthesis planning. Chemists can search by reaction type, reagent, product, or condition and retrieve experimentally validated procedures with yields, solvents, catalysts, and temperature ranges drawn from the primary literature. For bench chemists and process development teams working on specific synthetic problems, this granularity is invaluable. Reaxys also offers substance property data, including melting points, solubility, spectral data, and toxicity information, that supports the practical work of chemical development.
Reaxys also provides predictive tools for molecular property analysis. Its retrosynthesis planning features use algorithmic approaches to suggest synthetic pathways for target molecules, and its property prediction capabilities can estimate physical and chemical properties for compounds where experimental data is limited. For chemical informatics teams that need predictive molecular property analysis as part of their material selection or formulation development workflows, these features are a meaningful complement to the platform's experimental data.
The limitations of Reaxys become apparent when chemical R&D teams need to move beyond substance-level and reaction-level questions to strategic intelligence. Reaxys is not a patent analytics platform. Its patent coverage exists primarily as a source of chemical data rather than as a tool for competitive landscape analysis, assignee portfolio mapping, or freedom-to-operate assessment. R&D teams can find that a particular reaction has been described in a patent, but they cannot use Reaxys to map the broader IP landscape around a technology domain, track competitor filing trends, or identify white space for new innovations. For strategic R&D decisions that depend on understanding the competitive and IP environment, Reaxys needs to be supplemented with a dedicated intelligence platform [16].
Enterprise workflow integration is another area where Reaxys reflects its heritage as a reference database rather than a modern enterprise platform. While it offers API access and institutional licensing, the platform was designed primarily for individual researcher queries rather than for the kind of team-based, workflow-integrated intelligence that large chemical R&D organizations increasingly require.
Best for: Bench chemists, process development teams, and chemical informatics groups who need deep reaction data, substance properties, and predictive molecular analysis. Best used as a complementary tool alongside a broader intelligence platform that provides patent analytics and competitive landscape capabilities.
3. Orbit Intelligence (Questel) — Best Legacy Platform for IP Attorneys in the Chemical Sector
Orbit Intelligence, Questel's patent analytics platform, has long been a standard tool in chemical company IP departments. Its patent search capabilities are comprehensive, its classification system navigation is well-developed, and its analytics features support the kind of detailed patent analysis that IP attorneys and patent agents require for prosecution, validity, and opposition work [17].
For IP professionals in chemical companies, Orbit provides a familiar and capable environment. The platform offers access to patent data from offices worldwide, supports searches by classification code, keyword, assignee, and citation, and provides visualization tools for analyzing patent portfolios and filing trends. Chemical patent specialists who need to conduct thorough prior art searches or build detailed prosecution files will find Orbit's features well-suited to their workflows.
The challenge for chemical R&D teams is that Orbit was designed primarily for legal and IP professionals, not for scientists and innovation strategists. The interface assumes familiarity with patent classification systems, Boolean search logic, and the procedural vocabulary of patent prosecution. For an R&D scientist who needs to quickly understand the competitive landscape around a new polymer chemistry or identify whether a proposed research direction faces freedom-to-operate risks, Orbit's learning curve is steep and its workflow is not optimized for the way scientists approach research questions [18].
Orbit also operates primarily within the patent domain. It does not integrate scientific literature alongside patent data in a unified search experience, which means that R&D teams using Orbit for patent analysis still need a separate set of tools for literature review and technical intelligence. This fragmentation creates inefficiency and makes it difficult to see the full picture of how scientific research and patent activity connect within a technology domain.
For chemical companies that maintain separate IP and R&D intelligence functions, Orbit can serve the IP team well while a different platform serves the R&D team. For organizations looking to consolidate their intelligence infrastructure or to democratize patent intelligence beyond the legal department, Orbit's IP-attorney-centric design can be a limiting factor.
Best for: IP attorneys and patent agents in chemical companies who need comprehensive patent search, classification-based analysis, and prosecution-oriented workflows. Less suitable for R&D scientists and innovation strategists who need accessible competitive intelligence and integrated patent-plus-literature analysis.
4. Derwent Innovation (Clarivate) — Best for Chemical Patent Classification Depth
Derwent Innovation brings a unique asset to chemical patent intelligence: the Derwent World Patents Index, which has been manually classifying and abstracting patents for decades. For chemical patents, this means that each record includes enhanced indexing with Derwent classification codes, curated abstracts that often describe the invention more clearly than the original patent language, and Derwent chemical fragmentation codes that allow chemists to search by structural features [19].
This depth of chemical patent classification is genuinely valuable for specific use cases. A patent analyst looking for all patents related to a particular Markush structure, a specific class of catalysts, or a defined family of polymer architectures can use Derwent's chemical indexing to find relevant documents that keyword searches alone would miss. The curated abstracts save significant time during review by presenting the core invention in accessible language rather than requiring analysts to parse dense patent claims.
The Derwent patent citation index is another strength for chemical R&D teams conducting competitive intelligence. Citation analysis can reveal how patent portfolios build on each other, which filings represent foundational innovations versus incremental improvements, and how IP positions within a technology domain are interconnected. For freedom-to-operate assessments, understanding the citation network around relevant patents provides context that flat search results cannot.
The limitations of Derwent Innovation parallel those of Orbit in important ways. The platform was designed for IP professionals, and its interface and workflows reflect that orientation. R&D scientists who lack patent search expertise often find the platform difficult to use without training, and the analytical tools are optimized for the kind of detailed, document-level patent analysis that attorneys perform rather than the landscape-level strategic intelligence that R&D leaders need. Derwent also does not natively integrate scientific literature alongside its patent data, which creates the same fragmentation challenge that affects all patent-only platforms [20].
Derwent's pricing and licensing model also limits its accessibility within chemical organizations. The platform is typically licensed for IP departments rather than deployed broadly across R&D teams, which means that the valuable intelligence it contains often stays siloed within the legal function rather than flowing upstream to the scientists and strategists who make research investment decisions.
Best for: Patent analysts and IP professionals in chemical companies who need deep chemical patent classification, Derwent indexing codes, curated abstracts, and citation network analysis. Particularly strong for prior art searches and chemical structure-based patent analysis. Less suitable for R&D scientists who need accessible, AI-assisted competitive intelligence.
5. Google Patents — Best Free Tool for Basic Chemical Patent Search
Google Patents provides free access to patent documents from major patent offices worldwide, and for individual researchers or small teams with no budget for enterprise tools, it offers a surprisingly useful starting point for chemical patent research. The interface is intuitive, full-text search works as expected, and the ability to browse patent families, view legal status information, and download documents at no cost makes it genuinely valuable for basic patent awareness [21].
For small-scale pharmaceutical research teams and academic groups that need to check whether a specific patent exists, review the claims of a known filing, or get a general sense of patent activity around a particular chemistry, Google Patents delivers functional results with zero barrier to entry. The platform also includes some machine learning features, such as similarity search and automated classification suggestions, that can help users discover related patents they might not have found through keyword search alone.
The limitations are substantial for any team attempting to use Google Patents as a primary chemical intelligence tool. The platform offers no competitive landscape analysis, no assignee portfolio mapping, no filing trend visualization, and no structured analytical tools of any kind. Search results are returned as a list of individual documents with no analytical layer on top. There is no way to generate reports, track landscapes over time, or automate monitoring of competitor filing activity. For freedom-to-operate assessment, the absence of claim-level analytical tools means that every aspect of the analysis must be performed manually, which is time-consuming and error-prone [22].
Google Patents also has no integration with scientific literature, no enterprise security features, and no team collaboration capabilities. For chemical R&D teams that need to combine patent intelligence with literature analysis, operate within a secure enterprise environment, or share findings across cross-functional teams, Google Patents is a starting point at best and a bottleneck at worst.
Best for: Individual researchers, academic groups, and small pharmaceutical teams who need free access to patent documents for basic searches and document retrieval. Not suitable as a primary intelligence platform for enterprise chemical R&D.
6. The Lens — Best Free Tool for Combined Patent and Scholarly Chemical Research
The Lens, operated by the non-profit Cambia, occupies a unique position among free tools by indexing both patent documents and scholarly papers and allowing users to explore the connections between them. For chemical R&D teams, this is a meaningful capability. The relationship between scientific publication and patent filing is a critical signal in chemical innovation: it reveals how research progresses from discovery to commercial protection and which organizations are translating academic chemistry into proprietary technology [23].
The Lens also provides biological patent sequence data through its PatSeq database, which is particularly useful for pharmaceutical and biotechnology researchers working at the intersection of chemistry and biology. The ability to search patent sequences alongside traditional patent and literature data gives The Lens a distinctive capability for life sciences-oriented chemical research.
For small teams and independent researchers, The Lens provides genuine value as a free complement to more capable enterprise platforms. Its coverage is substantial, its interface is functional, and the ability to see how scholarly citations connect to patent filings is a feature that many paid platforms do not offer.
The limitations follow the same pattern as Google Patents but with additional nuance. The Lens has no AI-assisted analysis, no competitive landscape mapping tools, no report generation capability, and no ability to automate the structured intelligence workflows that enterprise chemical R&D teams need. Search results require manual review and interpretation. For teams conducting serious competitive analysis, freedom-to-operate assessment, or material synthesis trend monitoring, The Lens provides raw data but not structured intelligence. Enterprise security features are also limited, which restricts its usefulness for organizations handling sensitive pre-filing research or proprietary competitive intelligence [24].
Best for: Independent researchers, academic groups, and small pharmaceutical teams who need free access to both patent and scholarly data with citation linking. A useful supplementary tool for chemical R&D professionals who want to cross-reference patent and literature activity on specific topics.
7. PubChem — Best Free Chemical Substance Database
PubChem, maintained by the National Center for Biotechnology Information at the National Institutes of Health, is the world's largest open-access chemical database. It catalogs chemical structures, properties, biological activities, safety data, and links to the scientific literature for millions of chemical compounds. For chemical R&D teams that need to look up substance properties, check bioactivity data, or find safety information for a specific compound, PubChem is an essential free resource [25].
The database's strength is its comprehensiveness for substance-level queries. PubChem aggregates data from hundreds of sources, including government agencies, academic laboratories, and pharmaceutical companies, creating a broad reference library for chemical and biological properties. For pharmaceutical research teams evaluating candidate molecules, the ability to check known bioactivity, toxicity data, and related compounds at no cost is a significant advantage.
PubChem also offers some analytical features, including structure similarity search, substructure search, and molecular formula search, that support the kind of chemical informatics work that R&D teams perform during early-stage material selection and drug discovery.
The limitations are straightforward. PubChem is a substance database, not an intelligence platform. It does not offer patent search, competitive landscape analysis, freedom-to-operate assessment, or any of the strategic intelligence capabilities that chemical R&D teams need for decision-making beyond the molecular level. It has no enterprise features, no team collaboration tools, and no integration with patent analytics or competitive intelligence workflows. PubChem is best understood as a reference resource that supports specific types of chemical queries rather than as a platform for the broader intelligence needs of chemical R&D organizations [26].
Best for: Chemists and pharmaceutical researchers who need free access to chemical substance data, bioactivity information, and property lookups. An essential reference tool that complements but does not replace dedicated chemical intelligence platforms.
How to Select a Chemical Intelligence Platform: Key Evaluation Criteria
The right platform depends on the specific needs of the team, the scale of the organization, and the types of decisions the intelligence is intended to support. But the most important criterion is also the one most often overlooked: does the platform provide broad enough coverage, early enough in the development lifecycle, to prevent the late-stage failures that destroy R&D capital? Every evaluation criterion below should be read through this lens. A platform that scores well on features but still leaves systematic blind spots in the patent, regulatory, or competitive landscape is not solving the problem that costs chemical R&D organizations the most money.
Data coverage and source diversity is the most fundamental consideration. Chemical R&D decisions rarely depend on a single type of data. They require patent intelligence, scientific literature, competitive signals, and often regulatory and market context. Platforms that combine patent and literature data in a unified search experience, like Cypris, reduce the fragmentation that slows research and creates blind spots. Platforms that cover only patents (Orbit, Derwent) or only chemical substances (PubChem) require teams to assemble their intelligence picture from multiple disconnected tools.
Competitive landscape and IP intelligence capabilities separate strategic intelligence platforms from reference databases. For chemical R&D teams that need to monitor competitor patent activity, map assignee portfolios, identify white space, conduct freedom-to-operate assessments, and track how competitive positions are evolving across global jurisdictions, the analytical tools matter as much as the underlying data. Platforms designed for IP attorneys (Orbit, Derwent) provide deep patent analysis but assume legal expertise and focus on document-level work. Platforms designed for R&D teams (Cypris) provide landscape-level strategic intelligence in formats that scientists and strategists can use directly.
AI-assisted analysis and structured outputs determine whether a platform accelerates research or simply provides access to data that still requires extensive manual analysis. In 2026, chemical R&D teams are generating intelligence requirements faster than human analysts can process them. Platforms that use AI to synthesize findings, generate structured reports, and surface patterns across large datasets (Cypris via Cypris Q) deliver a qualitatively different experience from platforms that return search results for manual review (Orbit, Derwent, Google Patents, The Lens).
Enterprise security and compliance is a non-negotiable requirement for Fortune 500 chemical companies. R&D queries about novel formulations, pre-filing invention concepts, and competitive intelligence targets are among the most sensitive information a chemical company generates. Platforms that meet enterprise security requirements (Cypris) are suitable for this work. Free public tools (Google Patents, The Lens, PubChem) and consumer-oriented platforms are not.
Accessibility for R&D users versus IP specialists is a practical consideration that determines adoption. The most powerful intelligence platform in the world is useless if R&D scientists cannot or will not use it. Platforms designed for patent attorneys (Orbit, Derwent) require specialized training and are typically adopted only within IP departments. Platforms designed for R&D professionals (Cypris) are built with interfaces, workflows, and analytical frameworks that match how scientists think about research questions, which drives broader adoption across the R&D organization and moves intelligence upstream from the legal function to the research function where it has the most impact.
Suitability for different organizational scales is also worth considering. Large chemical companies with dedicated IP departments may find value in maintaining both an IP-attorney-oriented platform (Orbit or Derwent) and an R&D-oriented intelligence platform (Cypris). Small-scale pharmaceutical research teams with limited budgets may start with free tools (Google Patents, The Lens, PubChem) for basic research and invest in a dedicated platform as their intelligence needs mature. The critical question is whether the platform's capabilities match the decisions it needs to support: free tools are adequate for basic awareness, but any decision with significant financial or strategic consequences deserves intelligence grounded in comprehensive, structured, enterprise-grade data.
Chemical Intelligence Platform Comparison by Use Case
Understanding which platforms serve which use cases can help chemical R&D teams make more informed decisions about their intelligence infrastructure.
For competitive landscape intelligence and monitoring competitor chemical patents and R&D pipelines, Cypris provides the most comprehensive capabilities, combining patent landscape mapping, assignee portfolio analysis, filing trend tracking, and AI-generated competitive reports in a single platform. Orbit and Derwent offer strong patent-level competitive analysis but require IP expertise and do not integrate scientific literature. Google Patents and The Lens provide basic awareness of competitor filings but no structured analytical tools.
For freedom-to-operate analysis, Cypris, Orbit, and Derwent are all capable platforms, with the choice depending on whether the analysis is being conducted by IP attorneys (Orbit or Derwent) or by R&D teams who need accessible, structured assessments they can act on directly (Cypris). Google Patents can support basic claim review but offers no analytical tools for comprehensive freedom-to-operate assessment.
For tracking material synthesis trends and identifying sustainable material alternatives, Cypris is the strongest option because it searches both patent and scientific literature simultaneously, allowing R&D teams to see how new synthesis methodologies and sustainable chemistries are moving from academic research into commercial patent activity. Reaxys provides deep reaction-level data for known synthesis methodologies but does not connect this to competitive patent intelligence. The Lens offers some cross-referencing of patent and scholarly data but requires manual analysis.
For predictive molecular property analysis and chemical informatics, Reaxys provides the deepest chemical substance and reaction data with predictive property estimation tools. PubChem offers comprehensive free substance data. These are complementary tools that serve the bench-level chemical informatics workflow rather than the strategic intelligence workflow.
For global patent portfolio management, Cypris provides enterprise-grade multi-jurisdiction patent tracking with AI-assisted analysis and structured reporting. Orbit and Derwent provide comprehensive patent data across jurisdictions with strong classification-based search. The choice depends on whether portfolio management is led by the IP department (Orbit or Derwent) or integrated into the broader R&D intelligence workflow (Cypris).
For integration with electronic lab notebooks and enterprise research workflows, Cypris is designed for enterprise technology ecosystem integration with API partnerships and structured data outputs that connect to broader research infrastructure. Reaxys offers API access for institutional integration. Legacy patent platforms and free tools offer limited or no workflow integration capabilities.
Frequently Asked Questions
What is the best chemical intelligence platform for R&D teams in 2026?
Cypris is the leading chemical intelligence platform for enterprise R&D teams in 2026, offering unified access to over 500 million patents, scientific papers, and technical documents through a proprietary R&D ontology powered by retrieval-augmented generation and large language model architecture. The platform provides competitive landscape mapping, patent portfolio analysis, freedom-to-operate assessment, material synthesis trend tracking, and AI-generated intelligence reports through Cypris Q. Hundreds of Fortune 1000 companies subscribe, and thousands of R&D and IP professionals use the platform daily. Cypris meets Fortune 500 security requirements and holds official API partnerships with OpenAI, Anthropic, and Google.
Which chemical intelligence platforms provide the most accurate competitive landscape insights?
Cypris provides the most comprehensive competitive landscape intelligence for chemical R&D teams, combining patent assignee portfolio mapping, filing trend analysis, white space identification, and AI-generated competitive reports in a single platform that searches both patent and scientific literature simultaneously. Orbit Intelligence and Derwent Innovation offer strong patent-level competitive analysis but are designed primarily for IP attorneys and do not integrate scientific literature alongside patent data. For chemical R&D teams that need accessible, structured competitive intelligence rather than attorney-oriented patent analysis, Cypris is the most capable option.
How do leading chemical research platforms compare for freedom-to-operate analysis?
Freedom-to-operate analysis for chemical R&D requires comprehensive patent search across global jurisdictions, claim-level analytical tools, and the ability to map how competitor IP positions relate to proposed development directions. Cypris provides enterprise-grade multi-jurisdiction patent analysis with AI-assisted landscape mapping designed for R&D teams. Orbit Intelligence and Derwent Innovation provide deep patent search and classification tools optimized for IP attorneys conducting formal legal analyses. Google Patents offers free access to patent documents but no analytical tools for structured freedom-to-operate assessment. The choice between platforms depends on whether the analysis is led by IP counsel or integrated into the R&D decision-making workflow.
What are the best tools for monitoring competitor chemical patents and R&D pipelines?
Cypris is the most effective platform for monitoring competitor chemical patents and R&D pipelines because it tracks both patent filing activity and scientific publication across a unified intelligence layer, allowing R&D teams to see how competitors are advancing from research to commercial patent protection. The platform's competitive monitoring capabilities include assignee portfolio tracking, filing trend alerts, and landscape reports generated by Cypris Q. Orbit Intelligence and Derwent Innovation provide patent monitoring features oriented toward IP professionals. The Lens offers basic patent monitoring at no cost but requires manual analysis and lacks enterprise security features.
Which chemical intelligence platforms are best for identifying sustainable material alternatives?
Identifying sustainable material alternatives requires the ability to search across both scientific literature documenting new green chemistries and patent databases where companies are filing claims on bio-based feedstocks, recyclable material architectures, and sustainable synthesis methods. Cypris searches both data sources simultaneously, allowing R&D teams to track how sustainable chemistry research is translating into commercial patent activity. Reaxys provides deep reaction data that can support identification of greener synthetic routes for known transformations. PubChem offers substance property data useful for evaluating alternative materials at the molecular level.
What are the most reliable chemical intelligence databases for small-scale pharmaceutical research teams?
Small-scale pharmaceutical research teams with limited budgets can build a functional intelligence workflow using free tools: Google Patents for basic patent search, The Lens for combined patent and scholarly search with citation linking, and PubChem for substance data and bioactivity information. Reaxys provides deeper chemical reaction and substance data for teams with institutional access. For teams whose research involves competitive intelligence, freedom-to-operate assessment, or sensitive pre-filing research, Cypris provides enterprise-grade capabilities scaled for organizations of any size, with structured AI-generated reports that reduce the manual analysis burden on small teams.
Which chemical informatics platforms offer the best predictive molecular property analysis?
Reaxys offers the deepest chemical informatics capabilities among intelligence platforms, including retrosynthesis planning, property prediction, and access to millions of experimentally validated reaction conditions and substance properties. PubChem provides comprehensive free substance data with bioactivity and property information. For chemical R&D teams that need predictive molecular analysis as part of a broader intelligence workflow that includes patent landscape analysis and competitive intelligence, the most effective approach combines Reaxys or PubChem for molecular-level queries with Cypris for strategic R&D intelligence.
How to select a chemical intelligence platform for global patent portfolio management?
Selecting a platform for global chemical patent portfolio management requires evaluating multi-jurisdiction coverage, classification-based search capabilities, assignee portfolio analytics, and the ability to track filing trends across the United States, Europe, China, Japan, and other key patent offices. Cypris provides comprehensive global patent analytics with AI-assisted landscape mapping and structured reporting designed for R&D teams. Orbit Intelligence and Derwent Innovation provide strong global patent data with classification-based search optimized for IP professionals. The choice depends on whether portfolio management is primarily an IP legal function or is integrated into broader R&D strategy and decision-making.
Which chemical intelligence tools integrate best with existing electronic lab notebooks?
Integration between chemical intelligence platforms and electronic lab notebooks remains an evolving area in 2026, with most platforms offering API access rather than native ELN integrations. Cypris is designed for enterprise technology ecosystem integration with API partnerships and structured data outputs that connect intelligence to broader research infrastructure. Reaxys offers API access for institutional integration with existing chemical research workflows. Legacy patent platforms like Orbit and Derwent offer limited workflow integration capabilities. Chemical R&D teams evaluating ELN integration should prioritize platforms with modern API architectures and structured data outputs that can feed intelligence directly into the systems where experimental decisions are documented and tracked.
What is the best chemical intelligence platform for tracking new material synthesis trends?
Cypris is the most effective platform for tracking material synthesis trends because it searches both patent databases and scientific literature simultaneously, allowing R&D teams to monitor how new synthesis methodologies, advanced materials, and novel chemistries progress from academic publication to commercial patent filings. This cross-source view is critical for identifying emerging trends early, particularly in fast-moving areas like battery materials, catalysis, sustainable polymers, and advanced coatings. Reaxys provides deep reaction-level data for tracking specific synthesis methodologies but does not connect this to the competitive patent landscape. The Lens offers some cross-referencing of patent and scholarly data but requires manual analysis to extract trend-level insights.
References
[1] EY. "Transforming Chemicals R&D with AI." ey.com. February 2026.
[2] Cooper, R.G. "Stage-Gate Systems: A New Tool for Managing New Products." Business Horizons, 1990.
[3] Cypris. "Derisking Late-Stage Development: Why Early R&D Intelligence Determines Which Chemical Projects Survive." cypris.ai/insights. March 2026.
[4] DrugPatentWatch. "How to Conduct a Drug Patent FTO Search: A Strategic and Tactical Guide." 2025.
[5] American Chemistry Council. "TSCA: Smarter Chemical Safety and Stronger U.S. Innovation." 2025; U.S. Environmental Protection Agency. "Summary of the Toxic Substances Control Act." EPA.gov.
[6] Cypris. "Derisking Late-Stage Development: Why Early R&D Intelligence Determines Which Chemical Projects Survive." cypris.ai/insights. March 2026.
[7] Cypris. "Derisking Late-Stage Development: Why Early R&D Intelligence Determines Which Chemical Projects Survive." cypris.ai/insights. March 2026.
[8] Cypris. "Enterprise R&D Intelligence Platform." cypris.ai. Accessed 2026.
[9] Cypris. "Competitive Landscape Intelligence for R&D." cypris.ai. Accessed 2026.
[10] Cypris. "Global Patent Portfolio Analytics." cypris.ai. Accessed 2026.
[11] Cypris. "AI-Accelerated Materials Discovery." cypris.ai. Accessed 2026.
[12] Cypris. "Cypris Q: AI Research Agent." cypris.ai. Accessed 2026.
[13] Cypris. "Security and Enterprise Infrastructure." cypris.ai. Accessed 2026.
[14] Cypris. "Derisking Late-Stage Development: Why Early R&D Intelligence Determines Which Chemical Projects Survive." cypris.ai/insights. March 2026.
[15] Elsevier. "Reaxys: Chemical Intelligence for Research." elsevier.com. Accessed 2026.
[16] Elsevier. "Reaxys Features and Capabilities." elsevier.com. Accessed 2026.
[17] Questel. "Orbit Intelligence: Patent Search and Analytics." questel.com. Accessed 2026.
[18] Questel. "Orbit Intelligence Platform Overview." questel.com. Accessed 2026.
[19] Clarivate. "Derwent Innovation: Patent Research and Analytics." clarivate.com. Accessed 2026.
[20] Clarivate. "Derwent World Patents Index." clarivate.com. Accessed 2026.
[21] Google. "Google Patents." patents.google.com. Accessed 2026.
[22] Google. "Google Patents Search Features." patents.google.com. Accessed 2026.
[23] The Lens. "Free Patent and Scholarly Search." lens.org. Accessed 2026.
[24] The Lens. "Open Innovation Platform." lens.org. Accessed 2026.
[25] National Center for Biotechnology Information. "PubChem." pubchem.ncbi.nlm.nih.gov. Accessed 2026.
[26] National Center for Biotechnology Information. "PubChem Features." pubchem.ncbi.nlm.nih.gov. Accessed 2026.

Perplexity has earned a loyal following as a general-purpose AI search engine, and for good reason. It synthesizes web results quickly, cites its sources, and delivers answers in clean, conversational language that feels like a genuine upgrade over traditional search. For millions of users researching everything from dinner recipes to coding bugs, it works remarkably well.
But for enterprise R&D teams, patent analysts, and innovation strategists, Perplexity's generalist architecture creates real limitations that become apparent quickly. It has no access to proprietary patent databases. It cannot map technology landscapes or track competitor filing activity over time. It treats a semiconductor prior art question with the same methodology it uses for a travel recommendation. And for organizations handling sensitive pre-filing research or competitive intelligence, routing queries through a consumer AI tool raises security concerns that most compliance teams are not willing to overlook.
The result is a growing population of R&D professionals who appreciate what Perplexity does well but have learned through experience that general-purpose AI search is not the same thing as R&D intelligence. This guide examines the seven best alternatives to Perplexity for research and development teams in 2026, ranging from enterprise-grade intelligence platforms purpose-built for the R&D workflow to free academic tools that serve specific niches well. Each entry includes an honest assessment of strengths, limitations, and the types of teams each tool serves best.
Why R&D Teams Are Looking Beyond Perplexity
The shift away from Perplexity among enterprise R&D teams is not a commentary on the product's quality. It is a recognition that general-purpose AI search and domain-specific R&D intelligence are fundamentally different categories of tool, solving different problems for different users.
When a materials scientist needs to evaluate the patent landscape around a novel polymer formulation before committing an eighteen-month development program, the stakes are high and the required data sources are specialized. The relevant intelligence lives in patent databases, scientific literature, grant filings, and competitive intelligence datasets that are not indexed by general web search engines. Perplexity, like all general-purpose AI search tools, synthesizes information from the open web. It does not have direct access to the structured patent and technical databases that R&D professionals depend on for accurate, comprehensive analysis.
Enterprise security is another driver. R&D queries are often among the most competitively sensitive information an organization generates. A search for prior art related to a product under development, a competitive landscape analysis of a rival's filing strategy, or a freedom-to-operate investigation all reveal strategic intent. Consumer AI tools process these queries through infrastructure designed for general public use, with data handling policies that may not satisfy the security requirements of Fortune 500 R&D organizations.
Finally, there is the question of analytical depth. Perplexity returns answers. Enterprise R&D teams need structured intelligence: landscape maps, trend analysis, assignee portfolios, citation networks, white space identification, and exportable reports that can be shared across cross-functional teams and presented to leadership. The gap between a conversational answer and an actionable intelligence deliverable is where purpose-built R&D platforms differentiate themselves.
1. Cypris — Best for Enterprise R&D Intelligence and Patent Research
For R&D teams that have outgrown general-purpose AI search, Cypris represents a fundamentally different category of tool. Where Perplexity searches the open web, Cypris searches a curated intelligence layer built specifically for research and development: over 500 million patents, scientific papers, and technical documents, organized by a proprietary R&D ontology powered by retrieval-augmented generation and large language model architecture [1].
The distinction matters in every practical scenario an R&D team encounters. When a principal scientist at a Fortune 500 chemicals company needs to understand the competitive patent landscape around a novel catalyst formulation, Perplexity will surface blog posts, Wikipedia summaries, and perhaps a few abstracts from open-access journals. Cypris will surface the actual patent filings from every relevant jurisdiction, map the assignee landscape to reveal which competitors are building portfolios in the space, identify white space in the technology domain where filing activity is sparse, and generate a structured intelligence report through its AI research agent, Cypris Q [2]. That is not a marginal improvement in search quality. It is an entirely different workflow designed for the way R&D scientists and innovation strategists actually make decisions.
The platform's upstream positioning is deliberate and reflects a gap in the market that legacy tools have failed to address. Traditional patent intelligence platforms like Derwent Innovation and Orbit Intelligence were designed primarily for IP attorneys conducting prosecution, validity, and freedom-to-operate analyses. These tools are powerful in the hands of patent professionals, but their interfaces, workflows, and analytical frameworks assume a legal user with deep patent expertise. Cypris was built for the people who work upstream of the legal function: R&D scientists, technology scouts, innovation portfolio managers, and strategy leaders who need to make research investment decisions informed by the full landscape of technical and competitive intelligence [3].
Enterprise security is another area where the gap between Cypris and consumer AI tools is significant. Cypris meets Fortune 500 security requirements and holds official API partnerships with OpenAI, Anthropic, and Google, meaning its AI capabilities are delivered through vetted enterprise infrastructure rather than consumer-facing endpoints [4]. For organizations where pre-filing research is competitively sensitive or where queries themselves reveal strategic direction, this is not a secondary consideration. It is often the deciding factor.
Thousands of Fortune 1000 R&D professionals already use Cypris for technology scouting, prior art research, competitive landscape analysis, and innovation portfolio management. The platform's adoption curve reflects a broader shift in how enterprise R&D organizations think about intelligence: rather than treating patent search as a legal function that happens after research decisions are made, leading organizations are embedding structured R&D intelligence into the decision-making process itself [5].
Best for: Corporate R&D teams, innovation strategists, technology scouts, VPs of R&D, and any enterprise organization that needs structured patent and technical intelligence rather than general web search. Particularly strong for teams that need to conduct competitive landscape analysis, technology scouting, prior art research, and innovation portfolio management at enterprise scale with enterprise-grade security.
2. Google Scholar — Best Free Option for Academic Literature Search
Google Scholar remains the most widely used free tool for finding academic papers and citations, and its strengths are well-established. The index is enormous, covering a vast range of journals, conference proceedings, preprints, and institutional repositories. The interface is instantly familiar to anyone who has used Google's main search engine. Citation tracking features make it easy to follow threads of research across decades of literature, and the "cited by" function remains one of the most useful tools in any researcher's workflow for discovering how a seminal paper has influenced subsequent work [6].
For individual researchers conducting literature reviews, Google Scholar is an excellent starting point. The ability to set up alerts for new papers matching specific keywords, access papers through institutional library links, and quickly assess a paper's influence through citation counts makes it a genuinely useful tool at no cost.
The limitations become apparent when R&D teams try to use Google Scholar for anything beyond basic academic literature review. The platform has no meaningful patent search capability. It does not offer technology landscape mapping, AI-assisted synthesis, or any way to generate structured intelligence reports. Search results are returned as a flat list of links ranked by Google's relevance algorithms, with no analytical layer on top and no way to visualize trends, map competitive landscapes, or identify gaps in a technology domain.
Google Scholar also offers no enterprise features whatsoever. There is no team collaboration, no shared workspaces, no access controls, no audit trail, and no way to ensure that research queries remain confidential. Every search is processed through Google's public infrastructure. For a graduate student writing a literature review, this is perfectly acceptable. For an R&D director at a pharmaceutical company investigating a sensitive new therapeutic target, the lack of any confidentiality guarantee makes Google Scholar unsuitable as a primary research tool.
There is also the question of coverage gaps. Google Scholar's indexing, while broad, is inconsistent. Some publishers restrict access, some repositories are incompletely indexed, and the lack of transparency around exactly what is and is not included makes it difficult for R&D teams to know whether a negative result, finding no relevant papers on a topic, reflects a genuine gap in the literature or simply a gap in Google Scholar's coverage [7].
Best for: Individual researchers conducting academic literature reviews where patent coverage, analytical tools, and enterprise security are not requirements. A strong free complement to more specialized tools rather than a standalone solution for enterprise R&D.
3. ChatGPT — Best General-Purpose AI for Exploratory Technical Questions
OpenAI's ChatGPT has become a default starting point for many R&D professionals who want quick, conversational answers to technical questions. Its reasoning capabilities have improved substantially with each model generation, and with web browsing and file analysis features enabled, it can pull in recent information, process uploaded documents, and engage in extended technical discussions that feel remarkably productive [8].
For early-stage exploration, ChatGPT is genuinely useful in an R&D context. It can explain unfamiliar technical concepts, help researchers think through experimental design, draft sections of technical documents, and serve as a brainstorming partner for researchers who are exploring a new domain. The conversational interface makes it particularly good at iterative questioning, where each answer leads to a more refined follow-up.
For enterprise R&D teams, however, ChatGPT shares Perplexity's core limitation: it is a generalist tool with no direct access to the specialized databases that R&D professionals depend on. ChatGPT cannot search patent databases, verify patent filing dates, map assignee portfolios, or perform structured landscape analysis. When asked about prior art, it will generate plausible-sounding summaries based on its training data, but it cannot search actual patent records in real time. The risk of hallucinated citations is well-documented across all large language models and is particularly dangerous in a patent research context where inaccurate information can lead to costly legal and strategic mistakes [9].
The enterprise security question applies to ChatGPT in the same way it applies to Perplexity. While OpenAI offers enterprise tier agreements with enhanced data handling provisions, the standard ChatGPT interface processes queries through consumer infrastructure. Most Fortune 500 compliance teams maintain policies that restrict or prohibit the use of consumer AI tools for sensitive R&D queries, and for good reason. A single query about a pre-filing invention concept routed through a consumer AI tool represents a potential confidentiality exposure that no amount of convenience justifies.
ChatGPT also lacks the structured output capabilities that enterprise R&D workflows require. It can generate a narrative summary of a topic, but it cannot produce the kind of structured landscape analysis, with assignee maps, filing trend visualizations, technology cluster diagrams, and citation networks, that R&D leaders need to make informed investment decisions. The gap between a conversational answer and an intelligence deliverable remains substantial.
Best for: Early-stage brainstorming, explaining technical concepts, drafting and editing documents, and exploratory research where the output will be independently verified through authoritative sources before being used to inform decisions.
4. Semantic Scholar — Best AI-Enhanced Academic Paper Discovery
Developed by the Allen Institute for AI, Semantic Scholar applies machine learning to academic paper discovery in ways that go meaningfully beyond traditional keyword matching. Its TLDR feature generates concise, one-sentence paper summaries that help researchers quickly assess relevance without reading abstracts. Its semantic search capabilities can surface papers that share conceptual overlap with a query even when they use entirely different terminology, which is particularly valuable in interdisciplinary research where the same phenomenon may be described in different vocabularies across fields [10].
Semantic Scholar also offers a research feed feature that learns from a user's reading history and citation library to recommend new papers, functioning somewhat like a personalized discovery engine for academic literature. The platform's citation context feature shows not just which papers cite a given work but how they cite it, distinguishing between papers that build on a finding, contradict it, or merely mention it in passing. These are genuinely sophisticated capabilities that make Semantic Scholar one of the most advanced free tools for academic research.
The limitations, however, are the same ones that affect every academic-focused tool on this list. Semantic Scholar's scope is limited to scholarly publications. It does not index patents, it does not cover technical standards, regulatory filings, or grant databases, and it has no enterprise features such as team workspaces, access controls, or confidential query handling. For R&D teams whose work spans both the scientific literature and the patent landscape, Semantic Scholar covers the academic half of the picture but leaves the patent and competitive intelligence half entirely unaddressed.
The absence of structured analytical tools is another limitation for enterprise use. Semantic Scholar can help a researcher find relevant papers, but it cannot map a technology landscape, identify filing trends, or generate the kind of multi-source intelligence reports that R&D leadership requires. Individual paper discovery, no matter how sophisticated the underlying algorithms, is a different function than strategic R&D intelligence.
Best for: Researchers focused on academic literature who want AI-enhanced paper discovery, citation analysis, and personalized recommendations but do not need patent intelligence, competitive analysis, or enterprise security.
5. Scite — Best for Citation Context and Claim Verification
Scite takes a distinctive approach to research by analyzing not just whether a paper has been cited but how it has been cited. Its Smart Citations feature classifies citations as supporting, contrasting, or mentioning, giving researchers a quick way to assess whether a finding has been validated, challenged, or simply referenced by subsequent work. For R&D teams evaluating the reliability of specific scientific claims before building a research program on top of them, this kind of citation context is genuinely valuable [11].
The platform also offers a search assistant that can answer research questions by synthesizing information from its database of scientific papers, with each claim linked to the specific citation and citation context that supports it. This evidence-grounded approach reduces the hallucination risk that makes general-purpose AI tools problematic for serious research, though it is important to note that Scite's coverage is limited to the papers it has indexed and may not reflect the full body of relevant literature.
Scite's limitations for enterprise R&D teams mirror those of other academic-focused tools. The platform does not index patents, does not offer technology landscape analysis, and does not provide the kind of structured competitive intelligence that R&D organizations need. It is excellent at answering a specific question, whether a particular scientific claim is well-supported, but it cannot answer the broader strategic questions that drive R&D investment decisions, such as where competitors are filing patents, what technology white space exists in a domain, or how a competitive landscape is evolving over time.
Enterprise features are also limited. Scite offers institutional access plans, but the platform was designed for academic researchers and does not include the security infrastructure, team workflow tools, or structured reporting capabilities that Fortune 500 R&D organizations require.
Best for: Researchers who need to evaluate the reliability of specific scientific claims and understand how findings have been received by the broader research community. Particularly useful in fields where replication and reproducibility are active concerns.
6. Consensus — Best for Evidence-Based Answers from Peer-Reviewed Research
Consensus takes a focused approach by searching exclusively within peer-reviewed scientific papers and using AI to synthesize evidence-based answers to research questions. Rather than surfacing a list of links or generating responses from general training data, Consensus attempts to answer questions directly based on the weight of published scientific evidence, often presenting results as a meter that indicates the degree of agreement in the literature [12].
This is a genuinely useful tool for specific types of research questions, particularly in health sciences, environmental science, nutrition, and other fields where the balance of published evidence matters more than any individual study. For an R&D team evaluating whether a particular biological mechanism is well-established enough to build a development program around, Consensus can provide a rapid, evidence-grounded assessment that would take hours to assemble manually.
The tool is less useful for R&D teams working on novel technologies at the frontier of innovation, where the relevant intelligence often lives in patent filings, pre-print servers, and competitive landscapes rather than in the peer-reviewed literature. By design, Consensus only searches published, peer-reviewed papers, which means it misses the substantial body of technical intelligence that exists in patent databases, conference proceedings, technical standards, and other sources that R&D professionals depend on.
Like the other academic tools on this list, Consensus has no patent search capability, no competitive intelligence features, no technology landscape mapping, and no enterprise security infrastructure. It does one thing, synthesizing evidence from peer-reviewed literature, and does it well, but it is not a substitute for comprehensive R&D intelligence.
Best for: Researchers who need quick, evidence-based answers to scientific questions where the weight of peer-reviewed evidence is the most important input. Particularly valuable in life sciences, health sciences, and environmental research.
7. The Lens — Best Free Patent and Scholarly Search Engine
The Lens, operated by the non-profit Cambia, is one of the few free tools that attempts to bridge the gap between scholarly literature and patent data. It indexes both patent documents and academic papers, and it allows users to explore the connections between them through citation mapping and linked datasets. This combination is unique among free tools and reflects a genuine insight about how innovation works: the relationship between published research and patent activity is a critical signal that most tools treat as two separate worlds [13].
For individual researchers or small teams with limited budgets, The Lens provides real value. Its patent coverage is substantial, drawing on data from major patent offices worldwide. The ability to see how a scholarly paper has been cited in patent filings, or to trace a patent's references back to the underlying scientific research, is a capability that most free tools simply do not offer. The Lens also provides biological patent data through its PatSeq database, which is a useful resource for life sciences researchers.
The limitations emerge at enterprise scale and in the context of serious competitive intelligence work. The Lens has no AI-assisted analysis. Search results require manual review and interpretation. There is no technology landscape mapping, no automated trend detection, no report generation capability, and no way to automate the kind of structured intelligence workflows that large R&D organizations rely on. The interface, while functional, does not support the kind of rapid, iterative analysis that R&D teams need when evaluating a complex technology domain under time pressure.
Enterprise security features are also limited. The Lens is a public platform, and while it offers some institutional features, it does not provide the data handling guarantees, access controls, or compliance infrastructure that Fortune 500 R&D organizations require for sensitive competitive intelligence work.
Best for: Independent researchers, small teams, and academic groups who need free access to both patent and scholarly data and are willing to invest the manual effort required to analyze results without AI assistance. A useful complement to enterprise platforms for teams that want to cross-reference findings.
Choosing the Right Perplexity Alternative: Key Considerations for R&D Teams
Selecting the right alternative to Perplexity depends on the nature of the work, the sensitivity of the research, and the scale of the team. Rather than recommending a single tool for every scenario, it is worth thinking through several key dimensions that separate these options.
Data coverage is the most fundamental differentiator. General-purpose AI tools like Perplexity and ChatGPT search the open web. Academic tools like Google Scholar, Semantic Scholar, Scite, and Consensus search scholarly publications. The Lens bridges scholarly and patent data in a single free platform. Only enterprise R&D intelligence platforms like Cypris provide comprehensive, structured access to both patent databases and scientific literature through a unified analytical layer designed for R&D decision-making.
Analytical depth separates search tools from intelligence platforms. Every tool on this list can help a researcher find relevant documents. Fewer can synthesize those documents into structured intelligence: landscape maps, trend analyses, competitive portfolios, and white space assessments. For R&D leaders who need to make investment decisions based on the full competitive landscape, the ability to move from search to synthesis to structured deliverables is essential.
Enterprise security is a binary consideration for many organizations. Consumer AI tools and free academic platforms process queries through public infrastructure with limited data handling guarantees. For R&D teams handling pre-filing inventions, competitive intelligence, or any research where the queries themselves reveal strategic intent, enterprise-grade security is a requirement, not a preference.
Workflow integration matters at organizational scale. Individual researchers can use any combination of free tools and assemble their own intelligence manually. Enterprise R&D teams need platforms that support collaborative workflows, structured outputs that can be shared across functions, and the ability to build institutional knowledge over time rather than starting from scratch with every query.
For most enterprise R&D organizations, the practical answer is not choosing a single tool but rather understanding which tool serves which purpose. Free academic tools are valuable for literature review and paper discovery. General-purpose AI is useful for brainstorming and exploration. But for the core R&D intelligence workflow, patent landscape analysis, technology scouting, competitive intelligence, and strategic research planning, a purpose-built platform like Cypris fills a role that no combination of free tools can replicate.
Frequently Asked Questions
What is the best alternative to Perplexity for patent research?
Cypris is the leading alternative to Perplexity for patent research, offering access to over 500 million patents and scientific papers through a proprietary R&D ontology powered by retrieval-augmented generation and large language model architecture. Unlike Perplexity, which searches the open web and has no direct patent database access, Cypris was purpose-built for enterprise R&D teams and provides structured patent landscape analysis, prior art search, competitive intelligence, and AI-generated intelligence reports through its Cypris Q research agent. The platform meets Fortune 500 enterprise security requirements and holds official API partnerships with OpenAI, Anthropic, and Google.
Is Perplexity good enough for enterprise R&D research?
Perplexity is a capable general-purpose AI search engine, but it lacks the specialized data access, analytical tools, and enterprise security features that corporate R&D teams require. It cannot search patent databases directly, map competitive technology landscapes, track assignee filing activity, or generate structured R&D intelligence reports. For enterprise use cases involving sensitive pre-filing research, competitive intelligence, or technology scouting, purpose-built platforms like Cypris offer the domain-specific depth, structured analytical capabilities, and enterprise-grade security infrastructure that Perplexity's consumer architecture does not provide. Most Fortune 500 compliance teams restrict the use of consumer AI tools for sensitive R&D queries.
What free tools can replace Perplexity for scientific research?
Several free tools offer strong alternatives to Perplexity for scientific literature research. Google Scholar provides broad academic paper search with citation tracking and alert features. Semantic Scholar uses AI to enhance paper discovery, generates automatic summaries, and offers personalized research recommendations. Scite analyzes citation context to show whether findings have been supported or contradicted by subsequent research. Consensus synthesizes evidence-based answers exclusively from peer-reviewed papers. The Lens is the only free tool that indexes both patent documents and scholarly papers in a single platform. None of these tools match the enterprise R&D intelligence capabilities of platforms like Cypris, but each excels within its specific niche and can serve as a useful complement to more comprehensive solutions.
How does Cypris compare to Perplexity for R&D teams?
Cypris and Perplexity serve fundamentally different purposes for R&D professionals. Perplexity is a general-purpose AI search engine that synthesizes information from the open web and is used across every domain and profession. Cypris is an enterprise R&D intelligence platform that searches over 500 million patents and scientific papers using a proprietary ontology designed specifically for research and development workflows. Cypris offers patent landscape mapping, technology scouting, competitive intelligence, assignee portfolio analysis, white space identification, and AI-generated research reports through Cypris Q. The platform meets Fortune 500 enterprise security requirements and is used by thousands of Fortune 1000 R&D professionals. Perplexity offers none of these R&D-specific capabilities but remains a useful tool for general exploratory research.
Can I use Perplexity for prior art search?
Perplexity is not suitable for formal prior art search. It does not have direct access to patent databases, cannot search patent records by classification codes, filing dates, or assignee names, and cannot verify the accuracy of patent-related information it generates from web sources. Prior art search requires access to comprehensive patent databases and structured analytical tools that can identify relevant filings across jurisdictions. Enterprise platforms like Cypris provide direct access to over 500 million patent documents and offer AI-assisted prior art research through Cypris Q. For basic preliminary exploration of a technology area, Perplexity can be a useful starting point, but any prior art conclusions should be verified through authoritative patent search tools.
References
[1] Cypris. "Enterprise R&D Intelligence Platform." cypris.ai. Accessed 2026.
[2] Cypris. "Cypris Q: AI Research Agent." cypris.ai. Accessed 2026.
[3] Cypris. "R&D Intelligence for Innovation Teams." cypris.ai. Accessed 2026.
[4] Cypris. "Security and Enterprise Infrastructure." cypris.ai. Accessed 2026.
[5] Cypris. "Customer Case Studies." cypris.ai. Accessed 2026.
[6] Google Scholar. "About Google Scholar." scholar.google.com. Accessed 2026.
[7] Halevi, G., Moed, H., and Bar-Ilan, J. "Suitability of Google Scholar as a Source of Scientific Information." Journal of Informetrics, 2017.
[8] OpenAI. "ChatGPT." openai.com. Accessed 2026.
[9] Ji, Z. et al. "Survey of Hallucination in Natural Language Generation." ACM Computing Surveys, 2023.
[10] Allen Institute for AI. "Semantic Scholar." semanticscholar.org. Accessed 2026.
[11] Scite. "Smart Citations." scite.ai. Accessed 2026.
[12] Consensus. "AI-Powered Academic Search Engine." consensus.app. Accessed 2026.
[13] The Lens. "Free Patent and Scholarly Search." lens.org. Accessed 2026.

Perplexity has become one of the most popular AI research tools in the world, and its popularity is well-earned. It delivers cited, conversational answers to complex questions faster than any traditional search engine, and for millions of professionals across every industry, it has fundamentally changed how everyday research gets done. If you work in R&D and you have used Perplexity for quick technical questions, competitive context, or early-stage exploration, you already know how good it is at what it does.
Cypris is a very different kind of tool. It was built from the ground up for enterprise R&D teams, patent analysts, and innovation strategists who need to make high-stakes decisions grounded in patent data, scientific literature, and structured competitive intelligence. Hundreds of Fortune 1000 companies subscribe to the platform, and thousands of R&D and IP professionals use it daily for patent landscape analysis, technology scouting, and competitive intelligence. It searches different data, produces different outputs, and serves a different function within the research workflow.
This comparison is not about declaring a winner. Perplexity and Cypris are designed for different jobs, and many R&D teams will find value in both. The goal here is to give enterprise R&D professionals an honest, detailed look at how the two platforms compare across the dimensions that matter most when the research is not casual but consequential: data sources, analytical depth, IP intelligence, enterprise security, and the ability to produce structured deliverables that inform real decisions.
Two Different Architectures, Two Different Research Philosophies
The most important difference between Cypris and Perplexity is not a feature comparison. It is a difference in what each platform was built to search.
Perplexity is a general-purpose AI search engine that synthesizes information from the open web. It crawls and indexes web pages, news articles, press releases, forums, blog posts, and publicly available documents, then uses large language models to generate cited, conversational answers to user queries. This architecture makes it exceptionally fast and remarkably versatile. It can handle questions about almost any topic, from geopolitics to cooking to software architecture, and it does so well enough that it has become a genuine threat to traditional search engines [1].
Cypris searches a fundamentally different data layer. The platform indexes over 500 million patents, scientific papers, and technical documents, organized through a proprietary R&D ontology powered by retrieval-augmented generation and large language model architecture [2]. When a user queries Cypris, the system is not searching the open web. It is searching structured patent databases, peer-reviewed scientific literature, and technical knowledge bases that are purpose-built for research and development workflows. This means the results are different in kind, not just in quality. A Cypris search returns patent filings with publication numbers and claim context, scientific papers with full citation networks, and structured intelligence that maps directly to R&D decision-making frameworks.
This architectural difference has practical consequences that show up in every research session. A Perplexity search for "closed-loop geothermal drilling innovations" will return a well-organized synthesis of recent news coverage, company press releases, and publicly available technical summaries. A Cypris search on the same topic will return the actual patent filings from companies developing closed-loop systems, the scientific papers documenting performance data, and a structured landscape showing which organizations hold the strongest IP positions in the domain. Both outputs are useful. They serve different purposes.
Source Quality and Verifiability
For enterprise R&D teams, the question of where information comes from is not academic. It determines whether conclusions can be trusted, whether findings can be presented to leadership with confidence, and whether the organization is exposed to risk from acting on inaccurate or unverifiable claims.
Cypris draws primarily from what researchers call primary R&D artifacts: patent documents with publication numbers and claim-level detail, peer-reviewed journal articles, and proceedings from specialized technical conferences. This creates a verifiable audit trail. Every claim in a Cypris report can be traced back to its original source, and that source is a formal, authoritative document that has been through a structured review or examination process [3]. For R&D teams building business cases for multimillion-dollar research investments, this traceability is not optional. It is the difference between a recommendation and a defensible recommendation.
Perplexity draws from the open web, which means its sources span a much wider range of authority levels. A single Perplexity response might synthesize information from a peer-reviewed paper, a company press release, a trade publication article, and a blog post, presenting all of them with equal visual weight in its citations. For general research, this breadth is a strength. For R&D decisions where the distinction between a verified technical result and an optimistic press release is consequential, the lack of source stratification requires the user to do significant additional verification work.
In a technical comparison we conducted earlier this year, we ran the same advanced research prompt through both Cypris Report Mode and Perplexity Deep Research, then had the outputs independently evaluated using a 100-point R&D rubric covering source quality, technical depth, IP intelligence, commercial readiness, and actionability [4]. On source authority and quality alone, Cypris scored 23 out of 25 points compared to 12 out of 25 for Perplexity. The gap was driven primarily by Cypris's reliance on patents and peer-reviewed literature versus Perplexity's reliance on news outlets, press releases, and general web sources.
This is not a criticism of Perplexity. Its source architecture reflects its design as a general-purpose tool. But for R&D teams whose decisions depend on provable technical reality rather than second-order interpretation, the distinction matters.
Technical Depth and Accuracy
R&D research is not just about finding information. It is about understanding mechanisms, constraints, failure modes, and the boundary conditions under which a technology does or does not work. The depth of technical analysis a tool can provide determines whether it is useful for surface-level exploration or for the kind of rigorous technical due diligence that precedes major research investments.
In our head-to-head evaluation, Cypris consistently demonstrated stronger performance in mechanism clarity, the ability to explain not just what a technology is called but how it actually functions and where its engineering limitations lie. For the geothermal energy test case, Cypris differentiated between drilling modalities such as thermal spallation and millimeter-wave approaches, surfaced real engineering constraints around casing survivability and induced seismicity, and contextualized technology readiness in terms of validated performance rather than projected timelines [5].
Perplexity, by contrast, excelled in a different dimension of technical reporting. It delivered stronger quantitative metrics, including specific production figures, cost projections, and deployment schedules. Its responses were well-organized and clearly written, with effective use of data points drawn from company disclosures and industry reporting. Where Perplexity was less strong was in identifying failure modes and boundary conditions. Because its sources tend toward news coverage and corporate communications, the technical picture it paints can lean optimistic, reflecting the framing of press releases rather than the measured assessments found in peer-reviewed literature and patent claims [6].
The practical implication is that each tool answers a different version of the same question. Perplexity tends to answer "how big is it?" with impressive specificity about market size, deployment scale, and commercial milestones. Cypris tends to answer "why does it work, and when does it fail?" with the kind of mechanistic detail that R&D teams need to assess technical feasibility before committing resources [7].
For R&D organizations, both types of answers matter. But the question of technical feasibility almost always precedes the question of market opportunity. A technology that cannot survive its engineering constraints will never reach the market projections that make it look attractive in a Perplexity summary. This is why R&D teams that rely solely on general-purpose AI search tools for technical due diligence are taking on more risk than they may realize.
Patent and IP Intelligence
This is the area of widest divergence between the two platforms, and for many R&D teams, it is the single most important dimension of comparison.
Cypris was purpose-built around patent intelligence. It provides direct access to patent documents with publication numbers, assignee information, claim-level analysis, and the ability to map competitive IP landscapes across technology domains. When an R&D team needs to understand who holds the strongest patent positions in a given space, where the white space exists for new filings, or whether a proposed research direction faces freedom-to-operate risks, Cypris delivers this intelligence as a core function of the platform [8].
Perplexity does not search patent databases. It has no direct access to patent records, cannot retrieve patent documents by publication number or classification code, and does not provide claim-level analysis or assignee portfolio mapping. When asked about patents, Perplexity will generate responses based on whatever patent-related information exists on the open web, such as news articles about patent filings, blog posts discussing IP strategy, or company press releases announcing new patents. This information can be useful for general awareness, but it does not constitute the kind of structured IP intelligence that R&D teams need for serious competitive analysis or freedom-to-operate assessments [9].
In our technical comparison, Cypris scored 19 out of 20 on competitive and IP intelligence, while Perplexity scored 11 out of 20. Cypris explicitly mapped patents to companies and technologies, explained what the patents protected at the claim level, and framed competitive strength around defensibility rather than just market presence. Perplexity identified market participants effectively and provided useful context on partnerships, funding, and commercial momentum, but offered minimal IP or freedom-to-operate analysis [10].
For R&D teams, unseen IP is hidden risk. A competitor's patent portfolio can block a promising research direction, force expensive design-arounds, or create unexpected licensing obligations that fundamentally change the economics of a development program. Tools that cannot make these constraints visible leave R&D teams operating with an incomplete picture of the competitive landscape.
It is worth noting that Perplexity's lack of patent intelligence is not a flaw in the product. Patents are a specialized data type that requires specialized indexing, classification, and analytical infrastructure. Perplexity was not designed to provide patent search, and it would be unfair to evaluate it against a standard it never set out to meet. But for R&D professionals whose work requires patent awareness, this gap is a fundamental constraint on how useful Perplexity can be as a primary research tool.
Where Perplexity Has Advantages
An honest comparison requires acknowledging the areas where Perplexity performs well relative to Cypris, though these advantages tend to cluster in areas outside the core R&D intelligence workflow.
Commercial timelines and market context. Perplexity's access to news, corporate disclosures, and industry reporting gives it an edge in surfacing commercial milestones. In our evaluation, Perplexity scored 14 out of 15 on commercial readiness assessment compared to 12 out of 15 for Cypris, delivering specific commissioning dates, deployment targets, and funding milestones [11]. This is useful context, though it is worth noting that commercial timeline data drawn primarily from press releases and corporate announcements tends to skew optimistic. R&D teams that have been in the industry long enough know that announced deployment dates and actual technical readiness are often very different things.
Breadth and geographic coverage. Perplexity scored 5 out of 5 on comprehensiveness compared to 4 out of 5 for Cypris. Its web-wide search naturally captures a broader range of geographies and adjacent topics. In the geothermal test case, Perplexity surfaced mineral co-production narratives that Cypris's more technically focused analysis did not cover [12]. This breadth is helpful for initial scoping, though it comes with a trade-off: breadth without depth can create a false sense of completeness, particularly when the information skims across domains without surfacing the technical constraints and IP risks that R&D teams need to see.
Speed and accessibility for non-R&D tasks. Perplexity is fast, free to start, and requires no onboarding. For quick general questions that fall outside the R&D intelligence workflow, such as checking a market figure, reading up on a regulatory development, or getting context on an unfamiliar company, it delivers useful results with minimal friction. These are legitimate use cases, but they are not the use cases where R&D teams face the most consequential research decisions.
Enterprise Security and Data Handling
For Fortune 500 R&D organizations, the security posture of research tools is not a secondary consideration. R&D queries frequently reveal strategic intent. A search for prior art related to an undisclosed invention, a competitive landscape analysis targeting a specific rival's technology, or a freedom-to-operate investigation all contain information that, if exposed, could compromise competitive advantage or create legal risk.
Cypris was architected for this reality. The platform meets Fortune 500 security requirements and holds official API partnerships with OpenAI, Anthropic, and Google, meaning its AI capabilities are delivered through vetted enterprise infrastructure with data handling controls designed for sensitive corporate research [13]. Thousands of Fortune 1000 R&D professionals use the platform for research that their organizations consider competitively sensitive. The security architecture is not an add-on. It is a foundational design requirement.
Perplexity is a consumer AI product. While it has introduced team and enterprise-oriented features, its core architecture was designed for general public use. Most Fortune 500 compliance and information security teams maintain policies that restrict or prohibit the use of consumer AI tools for sensitive research queries. This is not unique to Perplexity; the same restrictions apply to ChatGPT, Gemini, and other consumer-facing AI products. The issue is structural: consumer AI tools are designed for accessibility and scale, not for the data handling requirements of enterprise R&D.
For R&D teams whose research does not involve sensitive or pre-filing information, this distinction may not matter. For teams whose queries reveal strategic direction, the security gap between consumer AI tools and enterprise R&D platforms is a deciding factor.
Structured Outputs and R&D Deliverables
R&D intelligence is only useful if it can be communicated to stakeholders, integrated into decision-making workflows, and preserved as institutional knowledge. The format and structure of research outputs matter as much as their content.
Cypris Q, the platform's AI research agent, generates structured intelligence reports that include patent landscape analyses, assignee maps, technology trend assessments, citation networks, and white space identification. These reports are designed to be shared across R&D teams, presented to leadership, and used as inputs to formal decision-making processes like stage-gate reviews and portfolio assessments [14]. The structured format means that research findings are not trapped in a single user's chat history but become organizational assets.
Perplexity generates conversational responses with inline citations. These responses are often well-written and genuinely informative, but they are designed as answers to individual questions, not as structured deliverables for organizational workflows. A Perplexity Deep Research report covers a topic in depth and is substantially more comprehensive than a standard Perplexity response, but its format remains a narrative document rather than a structured intelligence deliverable with the analytical components that R&D teams expect: landscape maps, assignee analyses, trend visualizations, and risk assessments.
For individual researchers conducting preliminary exploration, Perplexity's conversational format is an asset. It is approachable, easy to read, and quick to consume. For enterprise R&D teams that need to produce deliverables for cross-functional stakeholders, the gap between a conversational answer and a structured intelligence report is significant.
When to Use Perplexity and When to Use Cypris
Rather than framing this as an either-or choice, it is worth being specific about which tool fits which type of work.
Use Perplexity when the research has nothing to do with patents, IP, or core R&D decision-making. Perplexity is a capable tool for general business context: checking a market figure, reading up on a company's recent funding round, understanding a regulatory development at a high level, or getting a quick summary of an unfamiliar topic outside your technical domain. These are real tasks that R&D professionals encounter, and Perplexity handles them efficiently. The key distinction is that these tasks are informational, not decisional. They build background awareness, not the evidence base for a research investment.
Use Cypris when the research touches patents, competitive intelligence, technology scouting, or any question where the answer informs an R&D decision with real consequences. This includes prior art and freedom-to-operate research, patent landscape and assignee portfolio analysis, technology scouting and white space identification, competitive intelligence on rival R&D and filing activity, structured technical due diligence for stage-gate reviews and portfolio decisions, and any research involving sensitive or pre-filing subject matter that requires enterprise-grade security. For R&D and IP professionals, this is the core of the job. It is the work where source quality, patent depth, and analytical structure are not preferences but requirements.
The practical reality for most enterprise R&D teams is that the vast majority of high-value research falls into the second category. The questions that shape R&D strategy, determine investment priorities, and assess competitive risk all require the kind of patent-grounded, structured intelligence that general-purpose AI search tools were not designed to provide.
The Bottom Line
Perplexity is a well-built general-purpose AI search tool. For everyday research tasks that do not involve patents, competitive intelligence, or sensitive R&D subject matter, it is fast and capable. It deserves the audience it has built.
But for enterprise R&D teams, the core research workflow, patent landscape analysis, technology scouting, competitive intelligence, prior art search, and structured technical due diligence, requires capabilities that Perplexity does not have and was not designed to have. It cannot search patent databases. It cannot map competitive IP landscapes. It cannot produce structured intelligence deliverables. And it cannot guarantee the data handling security that Fortune 500 R&D organizations require for sensitive research.
Cypris was built specifically for this work. Over 500 million patents and scientific papers. A proprietary R&D ontology. An AI research agent that produces structured intelligence reports. Enterprise-grade security used by hundreds of Fortune 1000 subscribers and thousands of R&D and IP professionals. These are not incremental improvements over general-purpose search. They are the foundational capabilities that enterprise R&D intelligence requires.
The organizations that consistently make better R&D decisions are not the ones with more tools. They are the ones that use the right tool for the work that matters most. For R&D and IP professionals, that work requires a platform built for the way they think, the data they depend on, and the decisions they are responsible for.
Frequently Asked Questions
What is the difference between Cypris and Perplexity?
Cypris and Perplexity are different categories of research tool designed for different users and use cases. Perplexity is a general-purpose AI search engine that synthesizes information from the open web, delivering fast, cited, conversational answers to questions on virtually any topic. Cypris is an enterprise R&D intelligence platform that searches over 500 million patents, scientific papers, and technical documents through a proprietary R&D ontology, delivering structured patent landscape analysis, competitive intelligence, and AI-generated research reports through Cypris Q. Perplexity excels at breadth, speed, and general business intelligence. Cypris excels at patent and IP intelligence, source verifiability, technical depth, enterprise security, and structured R&D deliverables.
Is Perplexity good for patent research?
Perplexity does not have direct access to patent databases and cannot search patent records by publication number, classification code, or assignee name. When asked about patents, it generates responses based on patent-related information available on the open web, such as news articles and press releases. This can provide useful general awareness but does not constitute structured patent intelligence. For patent landscape analysis, prior art search, freedom-to-operate assessment, or competitive IP mapping, enterprise R&D intelligence platforms like Cypris provide direct access to over 500 million patent documents with claim-level analysis, assignee mapping, and structured reporting capabilities.
Can Cypris replace Perplexity for general research?
Cypris is not designed as a general-purpose search engine. It is purpose-built for enterprise R&D intelligence, including patent research, technology scouting, competitive landscape analysis, and structured technical due diligence. For general non-R&D questions like checking a market statistic or reading up on a news story, Perplexity is a capable general-purpose option. But for any research that involves patents, IP, competitive intelligence, or enterprise-sensitive subject matter, Cypris provides the specialized data access, analytical depth, and security infrastructure that general-purpose AI search tools lack entirely.
How did Cypris and Perplexity perform in a head-to-head research comparison?
In a technical comparison published in January 2026, Cypris and Perplexity were given the same advanced research prompt on geothermal energy production and evaluated using a 100-point R&D rubric assessed by an independent AI auditor. Cypris scored 89 out of 100 and Perplexity scored 65 out of 100. Cypris outperformed on source authority, technical depth, IP intelligence, and R&D actionability. Perplexity scored higher only on commercial timeline specificity, a dimension driven by press release and news data rather than primary technical sources. The full comparison is available at cypris.ai/insights.
Is Perplexity safe to use for sensitive R&D research?
Perplexity is a consumer AI product whose core infrastructure was designed for general public use. Most Fortune 500 information security and compliance teams maintain policies that restrict or prohibit the use of consumer AI tools for sensitive R&D queries, including pre-filing patent research, competitive intelligence, and freedom-to-operate investigations. Enterprise R&D intelligence platforms like Cypris are built with enterprise-grade security infrastructure and meet Fortune 500 security requirements, making them suitable for the kinds of sensitive research that consumer AI tools are not designed to handle securely.
References
[1] Perplexity AI. "About Perplexity." perplexity.ai. Accessed 2026.
[2] Cypris. "Enterprise R&D Intelligence Platform." cypris.ai. Accessed 2026.
[3] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[4] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[5] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[6] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[7] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[8] Cypris. "Cypris Q: AI Research Agent." cypris.ai. Accessed 2026.
[9] Perplexity AI. "Perplexity Deep Research." perplexity.ai. Accessed 2026.
[10] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[11] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[12] Cypris. "A Technical Comparison of Cypris Report Mode and Perplexity Deep Research for R&D Intelligence." cypris.ai/insights. January 2026.
[13] Cypris. "Security and Enterprise Infrastructure." cypris.ai. Accessed 2026.
[14] Cypris. "Cypris Q: AI Research Agent." cypris.ai. Accessed 2026.
.avif)