
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
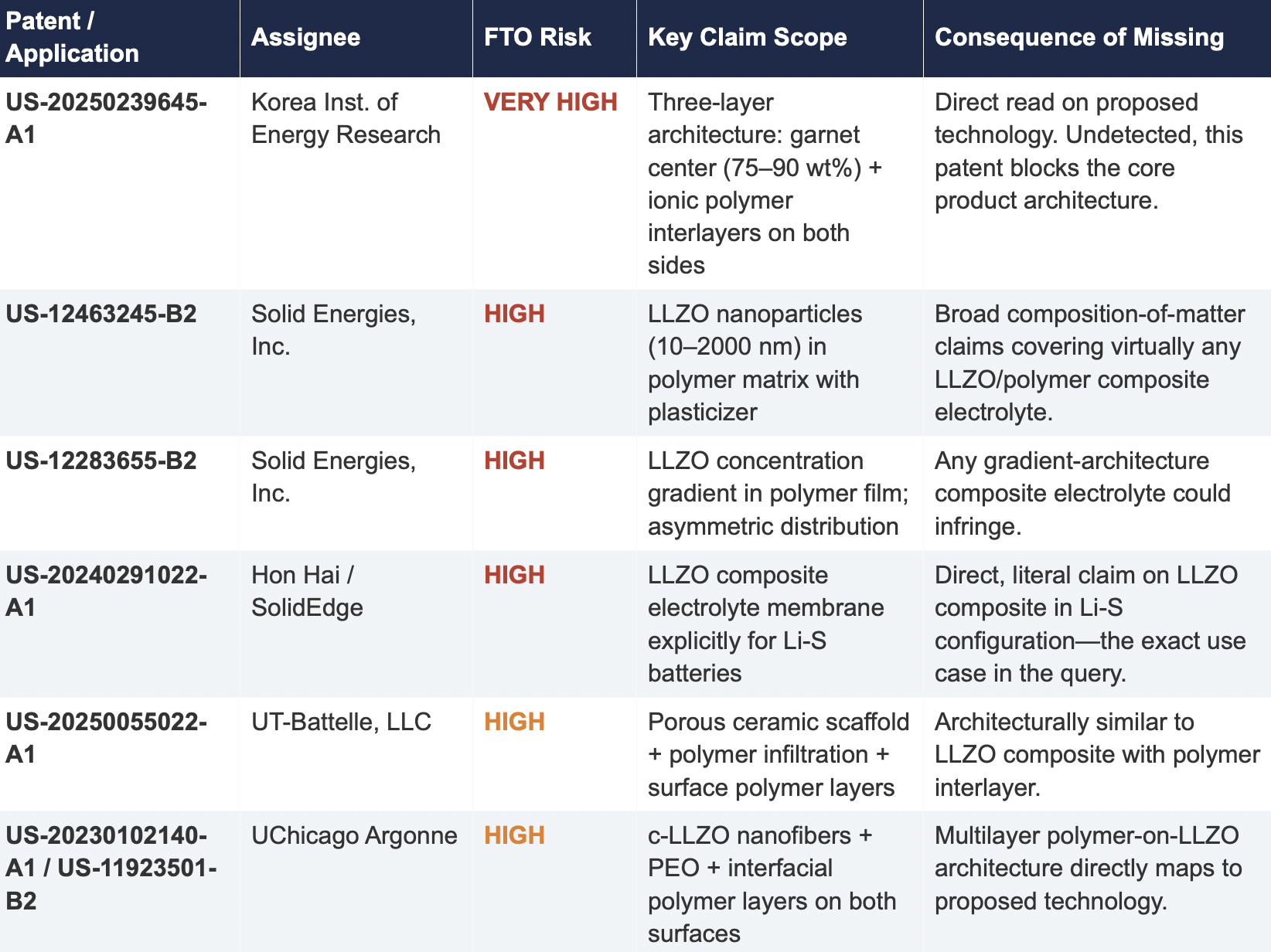
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
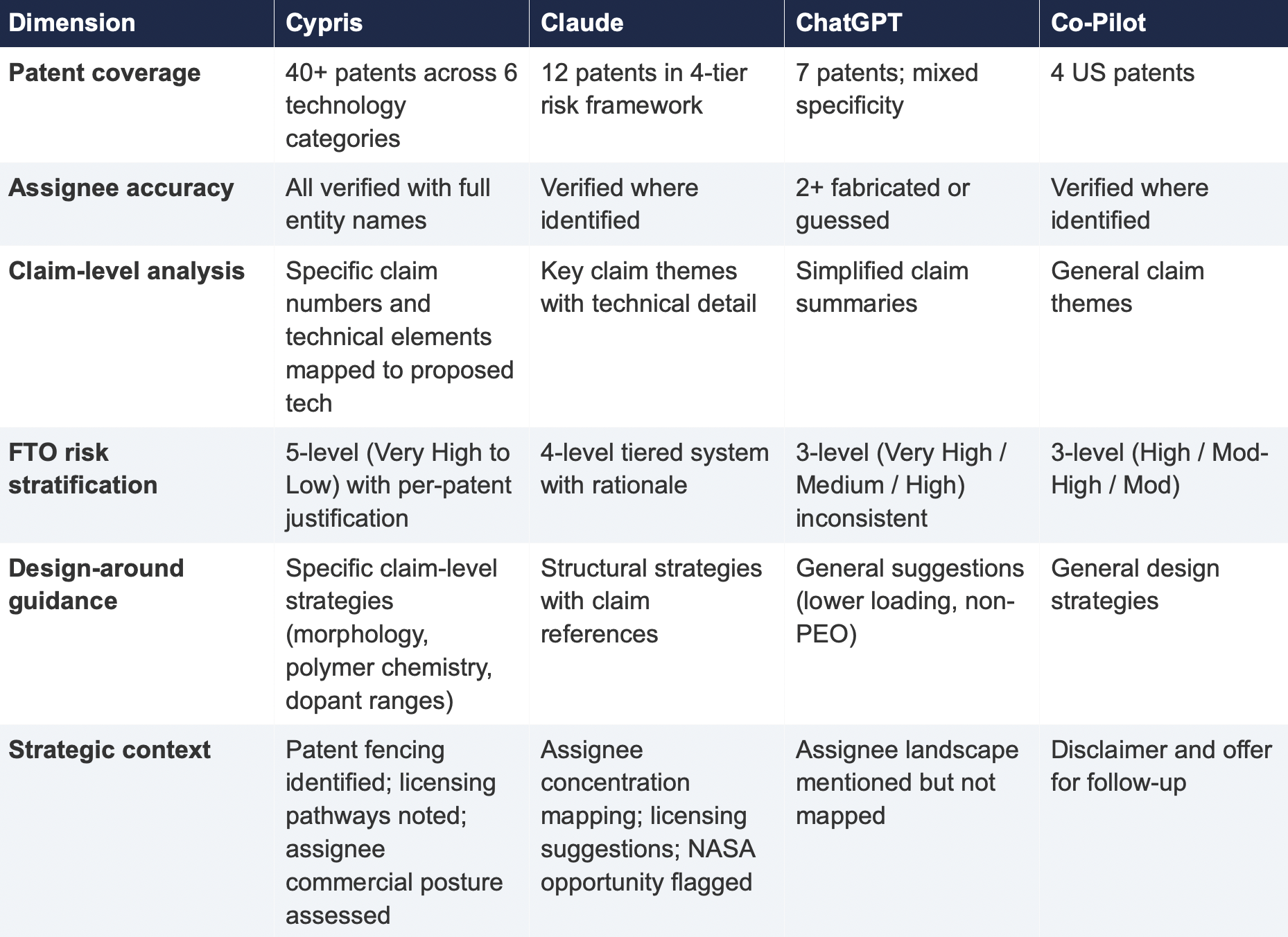
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

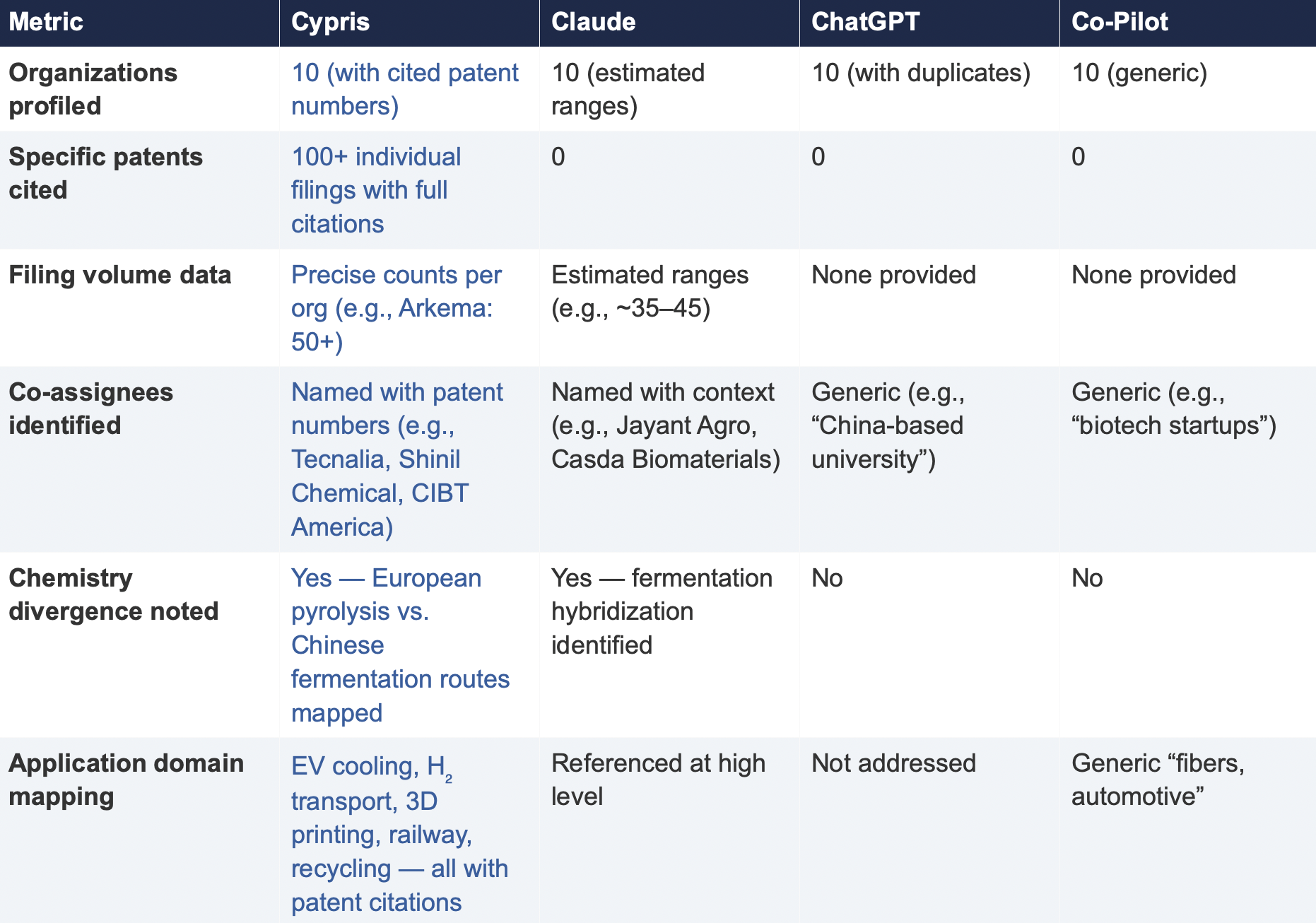
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

Most large R&D organizations now run some form of tech scouting. The shape varies enormously. A few companies have a dedicated technology scout sitting in the CTO's office producing quarterly horizon reports. More common is an innovation team that runs scouting sprints around specific themes when leadership asks for one. Increasingly common is some form of AI-assisted scouting workflow — a set of saved searches at the simple end, an agentic monitoring system at the more sophisticated end. The output quality across these approaches differs by an order of magnitude, and the most consequential variable separating the strong versions from the weak ones is not which AI model is underneath. It is how the scouting agent has been designed.
This guide is for innovation leaders, CTOs, R&D directors, BD and partnership teams, and corporate venture groups who want tech scouting to function as a continuous capability rather than a periodic deliverable. It explains what a tech scouting agent actually is, why agents that surface real intelligence look different from agents that produce volume, and how to design a scouting workflow that compounds value over time rather than restarting from zero every quarter.
What Tech Scouting Actually Has to Cover
Tech scouting is a forward-looking workflow. The question is not what the established competitive landscape looks like today; the question is what is emerging that the company should know about, where, and why does it matter to the strategy. That framing changes everything about how the work has to be done.
Scouting answers a small number of recurring questions. What new technologies are gaining momentum in areas adjacent to where we play? Which startups are forming around technical approaches that could disrupt our roadmap, and which could we partner with or acquire? Which research groups are producing work that will become commercially significant in three to five years, and what would it take to engage them? Which capabilities should we be building internally versus sourcing externally? Which competitors are quietly building positions in spaces we have not yet committed to? These questions do not have one-time answers. The answer this quarter and the answer next quarter are different, and the difference is precisely the signal the scouting workflow exists to capture.
The evidence base for these questions is messy and multi-source by nature. Scientific publications and preprints carry the earliest signal of where research is heading. Patent filings carry a slightly later but more strategically committed signal of where companies and inventors are placing technical bets. Startup formations, funding rounds, and corporate venture activity reveal where capital is moving and which technical theses sophisticated investors are willing to back. Government grants, program awards, and procurement filings flag where strategic priorities and non-dilutive funding are concentrating. Conference proceedings, technical talks, hiring patterns, regulatory filings, and the surrounding signal in trade press and industry analyst coverage round out the picture. Each source carries a different slice of the truth. None of them is sufficient on its own.
The implication is that a scouting agent watching one source — even a comprehensive one — produces a partial view. The signal that matters in scouting is usually cross-source. When a research group publishes three papers on a novel approach over eighteen months, when one of those authors leaves their academic position, when a small entity forms with a credible founding team and raises seed capital, when a corporate venture arm participates in the round, when an early grant award appears for the same research direction — none of those events is decisive on its own. Together, they are an emergence signal worth a senior leader's attention. An agent that sees only one source misses most of the picture. The intelligence is in the connection.
This is the workflow that older tools were not built for. Most legacy systems organize the world by source — a startup database here, a literature index there, a patent tool somewhere else, with the connections drawn by an analyst pivoting between tabs. The connection is the work. Doing that work continuously, across thousands of emergence events per week, in dozens of technology and business areas, is not a workload a team of human scouts can sustain. It is the workload tech scouting agents exist to absorb.
What a Tech Scouting Agent Actually Does
Most R&D and innovation organizations that say they have a tech scouting capability today are running a combination of saved Google Alerts, periodic searches in different databases, conference attendance, broker calls, and read-throughs of analyst reports. The work is real but episodic. Someone reads the alerts. Someone summarizes the conference. Someone reviews the analyst report. The interpretive work happens in a person's head, the institutional memory fades when they move on, and the next person to ask the same scouting question starts from a blank page.
A tech scouting agent inverts this pattern. The agent runs a defined scouting thesis continuously across the relevant evidence corpus, evaluates each new signal against the thesis using interpretive reasoning rather than keyword matching, dismisses what does not warrant attention, and escalates what does with a written rationale that explains why. The interpretive work moves from a person's head into a system that runs every day, applies consistent criteria, and produces a record the team can audit and refine.
Four functions distinguish a real scouting agent from a saved search with notifications.
It applies a strategic thesis rather than a query. Instead of matching documents against a Boolean string or a vector similarity threshold, the agent evaluates each new signal against a structured description of what the team is trying to learn and why. The thesis is interpretive, not lexical, which means the agent can recognize relevant signals even when the underlying language differs from how the team would have phrased a search.
It runs continuously, not on user-initiated demand. New papers, preprints, patent filings, funding announcements, grant awards, regulatory filings, and corporate disclosures arrive as a continuous stream. An agent designed for scouting evaluates this stream as it arrives, which eliminates the gap between when a relevant signal enters the world and when the team learns about it.
It filters for signal, not match. Most saved searches return high false-positive rates because the keywords appear in unrelated contexts, or because the technical match is real but the strategic relevance is low. An agent reads each candidate signal, evaluates it against the thesis, and discards what does not pass the relevance bar. The result is a substantially smaller and higher-quality escalation queue.
It produces a written rationale. When the agent escalates a signal, it explains why — what about the disclosure matched the thesis, how it relates to prior signals the agent has already evaluated, and what decision or downstream workflow it might inform. This rationale becomes a record the team can audit. When the agent gets it wrong, the team can see where the reasoning broke and refine the thesis. When the agent gets it right, the rationale accelerates the human follow-up because the framing is already done.
These four functions are what transform scouting from a notification system into an analytical process that compounds.
The Four Components of a Strong Scouting Thesis
The thesis is the most important input to a tech scouting agent. The quality of the thesis sets the ceiling on the quality of the output, regardless of which platform or model sits underneath. Most weak scouting output traces back to a thesis that was too short to support real work — a few sentences naming a technology area, with no specification of what would make a finding meaningful or how the team would use it.
There is a useful piece of recent prompt engineering research that bears on this directly. The discipline reorganized through 2025 around what researchers and frontier AI labs now call context engineering — the recognition that for serious knowledge work, the ceiling on output quality is set less by how a prompt is phrased and more by what information the system has been given to reason over. Andrej Karpathy described context engineering as the practice of populating the model's working context with precisely the right information for the task. Research on agentic systems published through late 2025 documented what researchers describe as brevity bias — the tendency of prompt optimization to favor concise instructions, which sounds appealing but causes the omission of domain-specific detail that actually drives output quality on knowledge-intensive tasks. The translation for tech scouting is that strong scouting theses are tight on filler but rich on domain specification. They are not short.
A well-framed scouting thesis has four components.
The strategic envelope. State why the scouting is being done and which business decisions it is meant to inform. A thesis written to support open innovation and partnership identification is different from a thesis written to support corporate venture screening, and both are different from a thesis written to support technology emergence monitoring for an executive committee or M&A target identification for corporate development. The agent can calibrate its evaluation criteria to the decision the scouting supports — but only when the decision is explicitly named. A scouting workflow without a named decision tends to escalate everything that looks interesting, which is functionally the same as escalating nothing.
The technical and market scope. Describe the technologies, capabilities, applications, and market segments of interest in specific terms. Name the methods, performance thresholds, end-use cases, and customer segments that are in scope. Name what is explicitly out of scope — the adjacent areas the team does not want the agent pulled into. List terminology variants the field uses for the same concept, particularly where industry vocabulary differs from academic vocabulary, and where new terminology has begun to displace older usage. The scope is what allows the agent to recognize relevance accurately at the edges, where most genuine emergence signals live.
The evidence priorities. State which sources of evidence matter most for this scouting question and why. For some theses, scientific publications are the leading indicator — emerging technical approaches typically appear in academic literature six to eighteen months before they reach commercial products. For other theses, startup formations and funding events are the earliest signal of where capital and talent are converging. For still others, government grant awards or regulatory filings reveal emergence first. The agent's evaluation logic depends on understanding which source carries the leading signal for the specific question, and how to weight signals from different sources when they appear together. Without this specification, the agent treats all sources as equally informative, which is rarely true.
The escalation criteria. Specify what makes a finding worth surfacing. A new initiative from a primary competitor likely warrants escalation regardless of how strong the technical match is. A scientific publication from an unknown research group likely warrants escalation only when the technical signal is strong and other independent signals point in the same direction. A startup formation likely warrants escalation only when the team behind it has a credible technical pedigree and the funding source signals strategic intent rather than seed-stage exploration. The criteria need to be explicit so the agent can apply them consistently and the team can tune them as the thesis evolves.
The discipline of writing a thesis with these four components is itself valuable. It forces the team to articulate what they are actually trying to learn, why it matters to the business, and how they would recognize a useful answer when they saw one. Teams that adopt this framing pattern tend to find that the thesis-writing exercise improves their scouting work even before any agent is run against it.
What to Watch For When Designing Scouting Agents
Three failure modes appear repeatedly in tech scouting agent deployments, and each is a design problem rather than a model problem.
The first is theses that are too broad, which produce escalation queues so large the team stops reading them. A scouting agent that escalates fifty findings a week will be functionally abandoned within a month. The remedy is rarely to make the agent more selective in isolation — it is to narrow the thesis itself, focus on the specific decisions the scouting supports, and tune the escalation criteria upward until what arrives is genuinely worth the team's time. A useful test is whether the team would feel a real loss if the scouting output stopped arriving. If the answer is no, the thesis needs to be sharper.
The second is single-source agents — scouting workflows that watch only one type of evidence, whether that is news, papers, patents, or startup data. The genuine emergence signals in tech scouting almost always show up across multiple sources, in a particular sequence, over a particular time window. An agent that sees one source can detect that something is happening but cannot evaluate whether the something is meaningful. A multi-source agent can recognize when a paper, a hire, a startup formation, and a funding round all point in the same direction, which is a fundamentally different category of intelligence than any one signal in isolation.
The third is scouting agents that are not connected to a downstream decision process. An agent that produces a weekly digest read by no one, or a digest whose findings never enter Stage-Gate reviews, partnership evaluations, M&A pipelines, or executive briefings, produces no operational value regardless of how good the underlying analysis is. The scouting workflow needs to terminate in a decision interface — a project workspace, a portfolio review, a CTO briefing, a venture screening pipeline, a corporate development tracker — where the findings can actually act on the business. A scouting agent without a downstream destination is an interesting demo, not a capability.
The Evidence Corpus Question
Here is where most tech scouting deployments hit their ceiling, often without realizing it.
A tech scouting agent's reasoning quality is bounded by what the agent is reasoning over. A general-purpose AI tool is reasoning over its training data, which is a partial and outdated slice of any specialized field. A scouting workflow built on a single-source database is reasoning over only that source. Both architectures impose ceilings on output quality that no amount of prompt refinement will fully lift.
This is the structural reason purpose-built R&D intelligence platforms produce different output than general-purpose AI tools or single-source legacy systems for scouting work. The strongest platforms maintain a unified corpus that combines scientific literature, patents, and adjacent technical and market signal in a single index, and allow scouting agents to reason across that combined corpus rather than against any one slice of it. Cross-source reasoning — recognizing that a paper, a patent, a funding event, and a hire all point in the same direction — only works when the agent has access to all of those signals in a structure that lets it connect them.
The strongest platforms go further and allow teams to configure custom corpuses focused on specific scouting theses. A custom corpus narrows the working evidence base to what is actually relevant for the question at hand, which lets the agent's reasoning operate on signal rather than fight through noise. A general index covers everything across all technology areas, and the signal that matters for a specific scouting thesis is buried in a much larger volume of irrelevant material. Even strong AI reasoning struggles to consistently find and weight the right evidence at that ratio. A focused corpus, scoped to the technical and strategic envelope of the thesis, produces meaningfully better scouting output than the same agent run against a general index.
Custom corpus configuration matters more for scouting than for most adjacent workflows. A landscape question is bounded — the scope is defined, the deliverable is a snapshot, and the corpus that supports it can be constructed once. A scouting question is open-ended — the scope evolves as the field evolves, the deliverable is continuous, and the corpus needs to evolve alongside the thesis. Platforms that treat custom corpus configuration as a first-class capability rather than an advanced feature are the ones where scouting workflows continue producing useful output six and twelve months in.
Where Cypris Fits
Cypris is an enterprise R&D intelligence platform built for this category of work. The platform unifies more than 500 million patents and scientific papers in a single corpus, applies a proprietary R&D ontology developed for the language of corporate research and innovation work, and provides agentic workflows that R&D, innovation, and corporate development teams configure to run continuous scouting against defined theses. Cypris maintains official API partnerships with OpenAI, Anthropic, and Google, which means the agentic reasoning sitting underneath the platform is built on frontier models accessed through enterprise contracts rather than scraped or rate-limited public APIs, with enterprise-grade security architecture that meets Fortune 500 requirements.
The capability that matters most for the scouting workflow described in this guide is the combination of unified corpus, custom corpus configuration, and agentic execution. A scouting team using Cypris can encode a strategic thesis, configure a focused corpus scoped to the technical and market envelope of that thesis, and run an agent against it continuously. The agent applies the team's escalation criteria, surfaces findings with written rationale, and integrates the output into the team's downstream R&D and corporate development processes. The architecture was designed from the ground up around the workflow needs of R&D scientists, innovation strategists, and corporate development teams rather than IP attorneys running discrete search engagements, which is reflected throughout the system in how scouting is structured, how findings are presented, and how the human-in-the-loop refinement of the thesis works in practice.
For an innovation team mapping a specific emerging technology space, this means the agent is reasoning over the research and technical signal actually relevant to that space, recognizing emergence patterns across sources, and surfacing findings the team would not have caught running periodic searches against a general index. For a corporate venture team screening a category of startups, the corpus can be configured around the technical area the venture thesis covers, and the agent can monitor for new entrants, technical pivots, and competitive activity continuously. For a corporate development team identifying M&A targets, the corpus can be configured around the capability gaps the strategy is trying to close, and the agent can surface companies whose technical and commercial trajectory aligns with the thesis. For a CTO running a horizon-monitoring program, the platform can support multiple parallel scouting theses, each with its own corpus, agent, and escalation logic, and integrate the combined output into the executive briefing cadence the CTO actually runs.
The combination — a unified research and technical corpus, custom corpus configuration scoped to specific theses, agentic execution against frontier reasoning models, and integration with the workflows R&D and innovation teams already run — is what separates scouting output that supports executive decisions from scouting output that summarizes what an analyst happened to read this week. Hundreds of Fortune 500 R&D and innovation organizations rely on the platform for exactly this category of work.
What Your Team Can Do This Quarter
Three things will measurably improve the tech scouting your team produces, regardless of which platform you use.
Standardize how scouting theses are written, with the four components described above — strategic envelope, technical and market scope, evidence priorities, and escalation criteria. A simple template that asks each scout to fill in these four sections before any agent runs against the thesis produces noticeably better output across the board. The discipline of writing a thesis to this standard is itself a quality lever, because it forces explicit articulation of what would otherwise stay implicit.
Establish a quality standard for what defensible scouting output looks like. The output a scouting agent produces should be grounded in specific citable signals — named entities, paper or patent identifiers, concrete dates, specific funding events — rather than vague references to activity in a space. It should distinguish between what the evidence shows and what the evidence suggests. It should calibrate its confidence by saying where the signal is thick and where it is thin. It should explicitly identify the assumptions and scope choices the conclusions depend on. Output that does not meet this standard does not get put in front of executives, regardless of which platform produced it.
Evaluate whether your current scouting toolkit supports continuous agentic execution against a unified, configurable corpus. If it does not — if the team is running periodic searches against single-source databases and synthesizing the output by hand — you are leaving substantial scouting capability on the table. Any platform evaluation you run should put unified corpus coverage, custom corpus configuration, and agentic workflow architecture near the top of the criteria list, ahead of search interface aesthetics or specific dashboard features.
The teams getting the most value from AI in tech scouting are not the teams with the most clever prompts or the highest tool budgets. They are the teams that have framed their scouting theses well, set quality standards their output has to meet, and chosen tools that let agents run continuously against the evidence base that matters for the decisions the scouting supports.
Frequently Asked Questions
What is a tech scouting agent?A tech scouting agent is an AI system that runs a defined technology scouting thesis continuously across a multi-source evidence corpus, evaluates new signals against the thesis using interpretive reasoning, and escalates findings worth human attention with a written rationale explaining why. It differs from a saved search with notifications in that it applies strategic interpretation rather than keyword matching, runs continuously rather than on user-initiated demand, filters for signal rather than lexical match, and produces auditable reasoning rather than document lists. Tech scouting agents are most valuable for R&D, innovation, corporate venture, and corporate development teams that need continuous awareness of emerging technologies, startups, research, and capabilities rather than periodic snapshots.
What kinds of decisions does a tech scouting agent support?Tech scouting agents support a recurring set of decisions: which technologies to monitor for strategic relevance, which research groups and inventors to engage for partnerships, which startups to evaluate for licensing, investment, or acquisition, which capability gaps to close internally versus source externally, and which competitive moves to track in spaces the company has not yet committed to. Each of these decisions has a different evidence priority and escalation criterion, which is why the strategic envelope of the scouting thesis matters as much as the technical scope.
What should a tech scouting thesis include?A strong tech scouting thesis has four components: the strategic envelope (why the scouting is being done and what business decisions it informs), the technical and market scope (what technologies, capabilities, and segments are in scope and what is explicitly out of scope, with terminology variants specified), the evidence priorities (which sources carry the leading signal for this question and how signals from different sources should be weighted when they appear together), and the escalation criteria (what makes a finding worth surfacing to the team). Theses missing one or more of these components tend to produce scouting output that is either too noisy to use or too narrow to capture genuine emergence.
Why does the evidence corpus matter so much for tech scouting?The corpus the scouting agent reasons over sets the ceiling on what the agent can recognize. A general-purpose AI tool reasons over its training data, which is partial and outdated for most specialized fields. A single-source database limits the agent to the signal carried in that source, missing cross-source emergence patterns. A unified, configurable corpus lets the agent reason across the full evidence base relevant to a specific thesis, which is where genuine scouting intelligence comes from. The recent shift in prompt engineering toward what researchers call context engineering reinforces this point: for serious knowledge work, the body of evidence the AI has access to matters more than the cleverness of the prompt.
What does cross-source reasoning mean in tech scouting?Cross-source reasoning is the recognition that genuine emergence signals usually appear in a particular sequence across multiple sources — papers, patents, hires, startup formations, funding events, grants, regulatory filings — rather than in any one source in isolation. A tech scouting agent capable of cross-source reasoning can identify when a research group's papers, a key author's job change, a new startup's formation, and a corporate venture investment all point in the same direction, which is a substantially stronger signal than any one of those events alone. Single-source agents cannot perform this analysis; multi-source agents can, but only when the underlying corpus is structured to support the connections.
How often should a tech scouting agent run?For most R&D, innovation, and corporate development applications, daily execution is appropriate, because new research, funding announcements, and corporate disclosures arrive continuously and the value of scouting is partly its currency. Weekly cadence is sometimes adequate for slower-moving technology domains, but the marginal cost of running an agent daily versus weekly is low, and the latency benefit is meaningful when the scouting informs time-sensitive decisions like partnership negotiations, investment rounds, or competitive responses.
What are the most common failure modes of tech scouting agents?Three failure modes appear repeatedly. The first is theses that are too broad, producing escalation queues so large the team stops reading them. The second is single-source agents that watch only one type of evidence, missing cross-source emergence patterns that constitute most genuine scouting signal. The third is scouting agents disconnected from downstream decision processes, where the output never reaches Stage-Gate reviews, partnership evaluations, M&A pipelines, or executive briefings that could act on it. Each is a design problem rather than a model problem.
Do general-purpose AI tools work for tech scouting?General-purpose AI tools can produce scouting-shaped output but rarely scouting-quality output for specialized R&D and innovation fields. The model is reasoning from whatever research, technical, and market data happened to be in its training data, which is a partial and outdated slice for most domains. The output sounds confident but the underlying evidence is often missing, generic, or wrong. For scouting workflows that inform R&D investment, partnership, corporate venture, or M&A decisions, purpose-built R&D intelligence platforms with current, comprehensive corpuses produce substantially more reliable output.
How do tech scouting agents integrate with downstream decision processes?A scouting agent's output is only valuable when it connects to a decision the organization is actually making. The integration usually takes one of three forms: routing escalated findings into project workspaces where program leads can act on them, feeding scouting output into Stage-Gate reviews, partnership evaluations, M&A pipelines, or portfolio decisions on a defined cadence, or producing structured executive briefings for technology committees and corporate venture boards. Scouting workflows that terminate in an inbox produce no operational value; scouting workflows that terminate in a decision produce compounding value over time.
What separates an enterprise R&D intelligence platform from a general AI tool for scouting work?Enterprise R&D intelligence platforms maintain unified corpuses that combine scientific literature, patents, and adjacent technical and market signal, support custom corpus configuration scoped to specific scouting theses, run agentic workflows continuously rather than on user-initiated demand, apply domain-specific ontologies trained on the language of technical research and innovation, and integrate with the downstream R&D and corporate development processes where scouting findings need to reach decisions. General AI tools provide reasoning capability but lack the corpus, the configurability, and the workflow integration that scouting at enterprise scale requires.
Citations
- Chesbrough, H. Open Innovation: The New Imperative for Creating and Profiting from Technology. Harvard Business School Press, 2003.
- Ansoff, H.I. "Managing Strategic Surprise by Response to Weak Signals." California Management Review, 1975.
- Karpathy, A. Public commentary on context engineering as the practice of populating model working context with precisely the right information for the task, 2025.
- Research on agentic context engineering and brevity bias in prompt optimization for knowledge-intensive tasks, 2025.
- Cypris platform documentation on unified research corpus, custom corpus configuration, and agentic scouting workflows.

Most R&D and IP teams at large enterprises are now using AI tools for patent landscape and white space analysis in some form. Some are running queries through general-purpose chatbots. Some are using AI features inside legacy patent search platforms. Some are evaluating purpose-built R&D intelligence systems. The range of output quality across these approaches is enormous — and the most common reason teams are disappointed with what they get is not the AI itself. It is what the AI has been given to work with.
This guide is for innovation leaders, IP managers, and R&D directors who need landscape and white space analyses they can put in front of executive committees, Stage-Gate reviews, and partnership decisions. It explains why the same question can produce a brilliant analysis from one tool and a vague summary from another, what good output actually looks like, and how to set up your team's AI patent work to consistently produce the better version.
Why the Same Question Produces Such Different Answers
A landscape question — say, "where is the white space in solid-state battery cathode materials for automotive applications above 400 kilometers of range" — is not really one question. It is a chain of work. The AI has to understand the technical envelope you mean, find the patents and scientific papers actually relevant to it, organize them into meaningful clusters, identify who is filing where, evaluate where activity is sparse, and then reason about whether the sparse areas represent genuine opportunity or something else.
Each link in that chain is a place the answer can break.
This is the shift the prompt engineering field went through in 2025. The discipline reorganized around what researchers and frontier AI labs now call context engineering — the recognition that for serious knowledge work, the ceiling on output quality is set less by how the question is phrased and more by what information the system has access to when it answers. Andrej Karpathy described it as the practice of populating the model's working context with precisely the right information, and the engineering teams at frontier labs have largely adopted this framing. For patent intelligence, the implication is direct: the body of evidence the AI is reasoning over matters more than the cleverness of the prompt.
When teams use a general-purpose AI tool, the AI is reasoning from whatever patent and scientific literature happened to be in its training data. For most specialized R&D fields, that is a thin and outdated slice. The output sounds confident because the model is good at sounding confident. But the actual evidence underneath the analysis is often missing, generic, or wrong. An R&D director who has spent a decade in the field can usually tell within thirty seconds. The named players are obvious incumbents and miss the actual emerging filers. The white space identified is the kind any consultant could guess at without doing the work.
When teams use AI features bolted onto legacy patent search platforms, the corpus is more current and complete, but the AI is often reasoning over patent data alone. Patents are a lagging indicator. Scientific literature publishes the underlying research six to eighteen months before patent filings appear. A landscape that looks at patents but not at the surrounding research is a landscape one cycle behind where the field actually is. White space identified this way frequently turns out, in retrospect, to have been white only because the team was looking in the wrong place.
When teams use a purpose-built R&D intelligence platform that combines patent and scientific literature with reasoning capability, the output quality jumps — but only if the team has framed the question well and configured the system to focus on the right body of evidence. This is where most of the remaining variance in output quality comes from, and it is the part the team actually controls.
What Good Landscape Output Looks Like
Before getting into how to ask, it is worth being clear about what to expect. A defensible AI-generated landscape has a few characteristics that consistently distinguish it from a generic one.
It is grounded in specific, citable patents and papers. Claims about who is leading in a sub-area are supported by named filings rather than vague references to "major players." Trends are supported by counts and time periods that can be checked. White space hypotheses cite the specific evidence that suggests the space is actually empty.
It distinguishes between what the data shows and what the data suggests. Strong output marks the difference between an observation ("filing activity in this sub-area declined 40% from 2022 to 2024") and an interpretation ("which suggests the field has matured or shifted to alternative approaches"). Weak output blurs the two.
It calibrates its confidence. It says where the evidence is thick and where it is thin. It flags areas where the available data is insufficient to support a conclusion. It distinguishes between confirmed white space and merely apparent white space.
It tells you what would change the answer. Strong landscape output identifies the assumptions and scope choices the conclusions depend on. If extending the time window two more years would change the picture, it says so. If a slightly different definition of the technology would shift where the white space sits, it says so.
These characteristics are what make a landscape useful for executive decisions. An analysis that does not have them is not a landscape — it is a confidently worded summary of what the AI happened to remember about the topic.
How to Frame the Question
The single most important thing your team can do to improve AI-generated landscape and white space output is invest more time in framing the question. This is not about clever prompting. It is about giving the system enough specification to do real work rather than generic work.
Most weak output traces back to questions that were too short. A team types "give me a landscape of solid-state battery technology" and gets a generic landscape of solid-state battery technology — broad, surface-level, not actionable. The system did exactly what was asked. The asking was the problem.
There is a subtle but important point here that recent AI research has clarified. The older advice on prompting AI tools was to write longer prompts, with multiple worked examples and explicit instructions to "think step by step." That advice was reasonable for the previous generation of language models. It is less applicable to the reasoning-trained models — Claude 4-series, GPT-5.1, the o-series — that now sit underneath most serious patent intelligence platforms. These models reason internally before responding, which means explicit step-by-step instructions add little, and multiple worked examples can actually constrain output quality.
What still matters, and matters more than ever, is the substance of what the prompt specifies about the work. Research on agentic context engineering published in late 2025 documented what researchers call brevity bias — the tendency of prompt optimization to favor concise instructions, which sounds appealing but causes the omission of domain-specific detail that actually drives output quality on knowledge-intensive tasks. The practical translation is that strong prompts for patent landscape work are tight on filler but rich on domain specification.
A well-framed landscape question has four components.
The technical envelope. Describe the technology in specific terms. Name the materials, methods, applications, and use cases that are in scope. Name what is explicitly out of scope — the adjacent areas that should not pull the analysis sideways. List terminology variants the field uses for the same concepts, especially where a concept is described differently in patents versus academic literature.
The strategic context. State why you are running the analysis. A landscape supporting a Stage-Gate decision on whether to advance a development program is a different analysis than a landscape supporting a competitive positioning exercise or a partnership target evaluation. The system can calibrate the depth and emphasis of the work to match the decision, but only if the decision is named.
The scope boundaries. Specify the time window, the jurisdictions of priority, and any assignee or inventor focus. Landscapes without time boundaries default to all-time, which is rarely what you want. Landscapes without jurisdictional priority weight all geographies equally, which is also rarely what you want.
The output you need. Specify what the deliverable should contain. The technology cluster map. The lead filers in each cluster. The temporal trends. The white space hypotheses with supporting evidence. The limitations of the analysis. Specifying the output structure lets the system reason backward from the deliverable to the work required, which produces better output than asking for "a landscape report."
Most teams that adopt this framing pattern see substantial improvement in output quality within a few iterations of practice. The framing itself does not need to be technical. It needs to be specific.
What to Watch For in White Space Searches
White space is the most common landscape question and the easiest one to get wrong. The phrase "white space" implies an area where no one is filing, but absence of filings can mean several different things, and only one of them is genuine opportunity.
Areas can look empty because the underlying technology is commercially uninteresting and no one is filing because no one would buy the result. Areas can look empty because companies in that space protect their work through trade secrets or process know-how rather than patents. Areas can look empty because the search terminology missed filings that exist under different vocabulary. None of these are white space in the sense that matters for R&D investment.
White space is also fragile to scope. An area that appears empty under one definition of the technology often turns out to be densely populated under a slightly different definition. This is a property of how patent literature is written and classified, not a flaw in the analysis, but it means white space claims need to be qualified by the scope they depend on.
Strong AI-generated white space output explicitly distinguishes these conditions. It does not just identify gaps in the patent map; it offers a hypothesis about why each gap exists and what would tell you whether the gap represents real opportunity. Output that identifies white space without explaining why it exists is output the team should not act on.
When framing a white space question, ask the system to evaluate each identified gap against the false-positive conditions, to articulate a falsifiable hypothesis for why the gap is empty, and to flag any gap whose existence depends on the scope boundaries being correct. A team that consistently asks for this analysis structure receives substantially more reliable white space output.
The Custom Corpus Question
Here is where most teams hit the ceiling on AI patent intelligence quality, often without realizing it.
Patent landscape and white space analysis is fundamentally a search-and-reasoning problem. The AI's reasoning quality depends on what the AI is reasoning over. A general-purpose AI tool is reasoning over its training data. A legacy patent platform is reasoning over the patent database it indexes. Both are essentially fixed — you cannot direct the system to focus its analysis on a specific body of evidence relevant to your question.
This is where purpose-built R&D intelligence platforms differ most meaningfully. The strongest platforms allow your team to configure custom corpuses — focused collections of patents, scientific papers, and other technical literature curated to a specific technology space, program, or strategic priority. When the AI runs landscape and white space analyses against a custom corpus, it is reasoning over the body of evidence that actually matters for your question, not over a general index that includes everything else.
The improvement in output quality is substantial, and the underlying reason connects back to the context engineering shift. A 2025 study at the Conference on Computational Linguistics on retrieval-augmented AI systems found that prompt design and the structure of the underlying evidence corpus interact strongly — the same prompt produces meaningfully different output across different corpus configurations. The finding confirms what R&D teams observe in practice: a general patent index covers everything filed across all technology areas, and the signal you care about for a specific R&D program is buried in a much larger volume of irrelevant filings. Even strong AI reasoning struggles to consistently find and weight the right evidence at that ratio. A custom corpus narrows the working evidence to what is actually relevant, which lets the AI's reasoning operate on the signal rather than fighting through the noise.
The same pattern holds for scientific literature. A general scientific index covers all of academia. A custom corpus configured for a specific technical domain gives the AI a focused body of relevant research to reason over alongside the patents. The cross-evidence reasoning — connecting what is appearing in academic publications to what is starting to appear in patent filings — only works well when both bodies of evidence are tightly relevant to the question.
For R&D and IP teams running landscape and white space work on a regular cadence, custom corpus configuration is one of the highest-leverage capabilities a platform can offer. It is the difference between asking the AI to find a needle in a haystack and giving the AI a focused stack to reason over.
Where Cypris Fits
Cypris is an enterprise R&D intelligence platform built for exactly this category of work. The platform unifies more than 500 million patents and scientific papers in a single corpus and supports the AI-driven landscape, white space, and monitoring workflows that R&D and IP teams at Fortune 500 companies need.
The capability that matters most for the question this guide addresses is custom corpus configuration. Teams using Cypris can configure focused collections of patents and non-patent literature scoped to a specific technology space, program, or strategic priority, and run AI-driven landscape and white space analyses against those custom corpuses. The AI reasons over the body of evidence the team has curated rather than over a general index, and the output reflects the specificity of the corpus the team configured.
For an R&D director scoping a new program in a specific catalyst class, this means the AI's analysis is focused on the patents and scientific papers actually relevant to that catalyst class, not on the broader chemistry index that contains them. For an IP manager mapping a competitor's portfolio, the corpus can be configured around that competitor's filing history and the surrounding technology space. For an innovation strategist evaluating a partnership target, the corpus can be configured around the target's technical area and the adjacent research feeding into it.
The combination — a unified patent and scientific literature corpus, configurable custom corpuses focused on the question being asked, and AI reasoning architecture built for R&D intelligence work — is what separates output that supports executive decisions from output that summarizes what the AI happened to know.
What Your Team Can Do This Week
Three things will measurably improve the AI-generated patent intelligence your team produces, regardless of which platform you use.
Standardize how the team frames landscape and white space questions, with the four components covered earlier — technical envelope, strategic context, scope boundaries, and output structure. A simple template that asks each analyst to fill in these four sections before running an analysis produces noticeably better output across the board.
Establish a quality standard for what defensible AI output looks like. Train the team to expect grounded citations, calibrated confidence, distinction between data and interpretation, and explicit acknowledgment of what would change the answer. Output that does not meet this standard does not get put in front of executives.
Evaluate whether your current AI patent toolkit lets you configure custom corpuses focused on the specific questions your team is asking. If it does not, you are leaving a substantial amount of output quality on the table — and any platform evaluation you run should put corpus configuration capability near the top of the criteria list.
The teams getting the most value from AI in patent intelligence are not the teams with the most clever prompting. They are the teams that have framed their questions well, set quality standards their output has to meet, and chosen tools that let them focus the AI on the evidence that matters for the work they are doing.
Frequently Asked Questions
Why does the same patent landscape question produce such different answers from different AI tools?Because patent landscape analysis depends on three things that vary substantially across tools: the body of evidence the AI is reasoning over, the AI's reasoning capability, and how well the question has been framed. General-purpose AI tools reason over their training data, which is partial and outdated for most specialized R&D fields. Legacy patent platforms have current data but typically cover patents alone without the scientific literature that signals where filings are heading next. Purpose-built R&D intelligence platforms combine both and allow the team to focus the AI on a specific corpus relevant to their question, which is where most of the remaining quality difference comes from.
What does "good" AI-generated patent landscape output actually look like?Strong output is grounded in specific, citable patents and papers rather than vague references to "leading players." It distinguishes between observations and interpretations. It calibrates confidence by saying where evidence is thick and where it is thin. And it identifies the assumptions and scope choices the conclusions depend on, so the reader knows what would change the answer. Output that lacks these characteristics is not landscape analysis — it is a confidently worded summary.
How should my team frame a patent landscape question for best results?A well-framed landscape question has four components: a precise description of the technical envelope (what is in scope and what is out of scope), the strategic context for the analysis (why you are running it and what decision it supports), the scope boundaries (time window, jurisdictions, assignee focus), and the output structure (what the deliverable should contain). Most weak output traces back to questions that omitted one or more of these components.
Has the advice on prompting AI tools changed recently?Yes. The current generation of reasoning-trained models — including Claude 4-series and GPT-5.1 — reason internally before responding, which means the older advice to write long prompts with multiple worked examples and explicit "think step by step" instructions is less applicable. What still matters, and matters more than ever, is rich domain-specific detail in the question itself. Recent prompt engineering research describes a brevity bias risk where prompts get shorter than they should because brevity feels efficient, but for knowledge-intensive work like patent analysis, domain specification is what drives output quality.
What is white space in patent analysis?White space refers to areas of a technology landscape where few or no patents have been filed, suggesting potential opportunity for R&D investment. The complication is that apparent emptiness can have several causes — the technology may be commercially uninteresting, companies may be protecting the work through trade secrets rather than patents, or the search terminology may have missed filings that exist under different vocabulary. Genuine white space is the residual after these alternative explanations have been ruled out.
How can I tell if AI-generated white space analysis is reliable?Reliable white space output explicitly addresses why each identified gap is empty and what would distinguish genuine opportunity from the alternative explanations. It articulates a falsifiable hypothesis for each white space and flags any white space whose existence depends on the scope boundaries being correct. White space identified without these explanations should not be acted on without further analysis.
What is a custom corpus and why does it matter for AI patent analysis?A custom corpus is a focused collection of patents, scientific papers, and other technical literature curated to a specific technology space, program, or strategic priority. When AI runs analyses against a custom corpus, it reasons over the body of evidence that actually matters for the question rather than over a general index that includes everything else. This dramatically improves output quality because the AI's reasoning operates on signal rather than fighting through noise. Custom corpus configuration is one of the highest-leverage capabilities a patent intelligence platform can offer for R&D and IP teams running landscape and white space work on a regular cadence.
Why do I need scientific literature alongside patents for landscape analysis?Scientific publications typically appear six to eighteen months before related patent filings. A landscape that looks only at patents is one cycle behind where the technology field actually is. White space identified from patents alone frequently turns out to have already been claimed in research that has not yet reached the patent office. Combining patent and scientific literature in the same analysis surfaces leading indicators that patent-only analysis misses entirely.
Can general-purpose AI tools like ChatGPT produce reliable patent landscapes?General-purpose AI tools can produce landscape-shaped output but rarely landscape-quality output for specialized R&D fields. The model is reasoning from whatever patent literature happened to be in its training data, which is a partial and outdated slice for most technical domains. The output sounds confident but the evidence underneath is often missing, generic, or wrong. For analyses supporting executive decisions, purpose-built R&D intelligence platforms with current, comprehensive corpuses produce substantially more reliable output.
How do enterprise R&D intelligence platforms differ from legacy patent search tools?Legacy patent search platforms were built for IP attorneys and search professionals running discrete projects. The interface assumes a human in the chair constructing queries and refining results. Enterprise R&D intelligence platforms are built for R&D scientists and innovation strategists who need ongoing intelligence across patent and scientific literature, AI-driven analysis at the depth executive decisions require, and capabilities like custom corpus configuration that focus the analysis on the evidence relevant to the team's specific work.

The most consequential shift in patent search isn't semantic understanding or natural language queries — both of which most platforms now offer. It's the move from episodic search to continuous agentic monitoring: AI agents that run patent intelligence workflows around the clock, evaluate new filings against a defined research thesis while your team is asleep, and surface only what genuinely matters by the time you open your laptop in the morning.
This shift redefines what an enterprise R&D intelligence platform actually does. The platforms that will matter over the next several years are not the ones with the cleverest search interface. They are the ones that can run an analyst's reasoning continuously, in the background, across the entire global patent corpus and the scientific literature that surrounds it.
This guide explains how continuous agentic patent monitoring works, where it differs from the alert systems most R&D teams currently rely on, and how to design a workflow that turns patent intelligence from a project into a process.
What Continuous Agentic Patent Monitoring Actually Means
Continuous agentic patent monitoring is the use of AI agents to run defined patent search and evaluation workflows on an ongoing schedule, with the agent applying interpretive reasoning rather than simple keyword matching to determine which filings warrant human attention.
The distinction from traditional patent alerts is meaningful. A traditional alert tells you that a new patent matched your saved search. An agent reads the filing, compares it against the technical thesis you defined, evaluates whether it represents a meaningful development relative to the prior art it already knows about, and either escalates the document with context or quietly dismisses it. The first approach generates a queue. The second approach generates intelligence.
Most R&D and IP teams today operate somewhere between these two modes. They have saved searches that fire weekly digest emails. The digest arrives. Someone scans it, archives most of it, flags one or two items, and moves on. The work the analyst is actually doing — interpreting whether each new filing matters — never gets captured anywhere. It happens in their head, fades, and has to be repeated next week.
Agentic monitoring inverts that pattern. The interpretive work moves into the agent, which means it runs every day instead of once a week, applies consistent criteria, and produces a written record of what it considered and why.
Why Episodic Patent Search Is the Wrong Default
Most patent search workflows are still organized around the assumption that searching is something a person does at a moment in time. A scientist needs to check the prior art before filing. A product team needs a freedom-to-operate read before launching. An IP analyst needs to map a competitor's portfolio for a board presentation. In each case, someone runs a search, exports the results, builds a document, and the work ends.
This is the workflow that legacy patent search platforms were designed for. Tools like Derwent Innovation and Orbit Intelligence were built for IP attorneys and search professionals running discrete, billable engagements. The interface assumes a human in the chair, constructing Boolean queries, refining results, and producing a deliverable. Everything about the workflow is episodic.
The problem is that the patent landscape is not episodic. According to the World Intellectual Property Organization, more than 3.5 million patent applications are filed globally each year, with weekly publication cycles in every major jurisdiction. By the time an FTO analysis is finalized and a product moves toward launch, the underlying patent landscape has shifted. By the time a competitor portfolio map is delivered to leadership, the competitor has filed something new. Episodic search produces a snapshot of a system that doesn't sit still.
R&D teams in particular suffer from this mismatch. R&D timelines are long. Programs that begin with a clean technology landscape can encounter blocking filings two years into development. Inventors in adjacent fields publish papers that hint at what they will file next quarter. Acquirers buy patent portfolios that change the competitive picture overnight. None of this is captured by running a search in March and assuming the answer holds in November.
The shift to continuous monitoring is not a feature upgrade. It is a different theory of how patent intelligence connects to R&D decisions.
What an AI Agent Does Differently in a Monitoring Workflow
An AI agent designed for continuous patent monitoring performs four functions that distinguish it from a saved search with email alerts.
First, it applies a research thesis rather than a query. Instead of matching documents against a Boolean string, the agent evaluates each new filing against a structured description of what the team is trying to learn. That thesis can encode technical scope, exclusions, competitor focus, jurisdictional priorities, and the specific decisions the monitoring is meant to inform. The thesis is interpretive, not lexical, which means the agent can recognize relevant filings even when the language differs from how the team would have phrased the search.
Second, it runs continuously and on a schedule the team controls. New filings publish daily; the agent evaluates them daily. Patent legal status updates flow in continuously; the agent processes them as they arrive. This eliminates the gap between when a relevant document enters the corpus and when the team learns about it.
Third, it filters for signal rather than match. Most saved searches return false positives because the keywords appear in unrelated contexts. An agent reads the document, evaluates whether the disclosure actually relates to the research thesis, and discards filings that match on language but not on substance. The result is a substantially smaller and more relevant escalation queue.
Fourth, it produces a written rationale. When the agent escalates a filing, it explains why — what about the disclosure matched the thesis, how it relates to prior art the agent has already evaluated, and what decisions or downstream workflows it might affect. This rationale becomes a record. Teams can audit the agent's reasoning, refine the thesis when the agent gets it wrong, and accumulate institutional knowledge that survives team turnover.
These four functions are what transform monitoring from a notification system into an analytical process.
How to Design a Continuous Patent Monitoring Workflow
A continuous monitoring workflow has five components, and the quality of each determines how useful the system will be in practice.
Defining the research thesis. The thesis is the most important input. It should describe the technical domain in enough specificity that an agent can recognize relevant filings, identify what is excluded as out-of-scope, name the assignees and inventors that warrant elevated attention, specify the jurisdictions that matter, and articulate the decisions the monitoring is meant to support. A thesis written in two sentences will produce noisy output. A thesis that runs to a structured document will produce a useful escalation queue. The discipline of writing the thesis is itself valuable; it forces the team to articulate what they are actually trying to learn.
Setting relevance criteria. Beyond the thesis, the agent needs explicit criteria for what counts as escalation-worthy. A new filing from a primary competitor should probably escalate even if it is tangentially related to the technical scope. A filing from an unknown assignee in a peripheral jurisdiction should escalate only if the technical match is strong. These criteria need to be made explicit so the agent can apply them consistently and the team can tune them over time.
Configuring escalation thresholds. Continuous monitoring fails when it produces too much output. If the daily digest contains forty escalations, the team will stop reading it within two weeks. The threshold for escalation should be set high enough that what arrives is genuinely worth attention, with the understanding that the team can tune the threshold downward if they feel they are missing things.
Integrating with downstream R&D processes. Monitoring output is only valuable if it connects to a decision. Escalations should route to the people who can act on them — the program lead whose freedom-to-operate read is affected, the IP counsel evaluating a defensive filing decision, the technology scout building a partnership target list. A monitoring workflow that terminates in an inbox produces no value. A monitoring workflow that terminates in a Stage-Gate review or a portfolio decision produces compounding value.
Reviewing and refining the thesis. The thesis is not static. As the program evolves, as competitors shift strategy, as adjacent technologies become relevant, the thesis needs to be updated. A monthly or quarterly review of what the agent escalated, what it missed, and what it incorrectly elevated allows the team to refine the thesis and keep the monitoring aligned with the current state of the program.
The Monitoring Use Cases That Justify the Investment
Four monitoring use cases produce most of the practical value for R&D and IP teams.
Competitive patent activity tracking monitors filings, continuations, and family expansions from named competitors and produces the earliest possible signal that a competitor is moving into a technology space, expanding geographically, or shifting strategic emphasis. For R&D teams, this informs program prioritization. For IP teams, this informs defensive filing strategy.
Freedom-to-operate watch monitors new filings against the technical scope of products in development or recently launched and produces ongoing assurance that the FTO position established at program kickoff continues to hold as the patent landscape evolves. This is particularly important for programs with long development cycles, where the FTO landscape at launch may differ substantially from the landscape at the start of development.
Technology emergence detection monitors filing activity, citation patterns, and publication trends across an entire technical domain to identify when a new approach, material, or method is gaining momentum. This is the most strategically valuable use case for innovation strategists and corporate venture teams, because it surfaces opportunities and threats before they become obvious from market signals alone.
Inventor and assignee tracking monitors specific researchers, research groups, and corporate filers to detect movement, collaboration, and shifts in technical focus. When a productive inventor moves between companies, when a research group's filing rate accelerates, when a small assignee's portfolio is acquired — these events carry strategic information that gets lost in aggregate filing statistics.
Each of these use cases benefits from continuous evaluation in a way that periodic search cannot replicate. The signal is in the change, and the change is only visible if something is watching continuously.
What an AI Patent Search Platform Needs to Do This Well
Not every platform that markets AI capabilities can support continuous agentic monitoring. The architecture required is meaningfully different from what a search interface needs.
The platform needs deep dataset coverage across both the global patent corpus and the surrounding scientific literature. Patents do not emerge from a vacuum; they emerge from research that often appears first in scientific publications. A monitoring workflow that watches patents alone misses the leading indicators that show up in papers six to eighteen months earlier. An enterprise R&D intelligence platform that unifies patent and scientific literature in a single corpus produces substantially earlier signal than a patent-only tool.
The platform needs a sophisticated technology ontology and knowledge graph. An agent evaluating relevance against a research thesis needs to understand technical relationships between concepts, materials, methods, and applications. Generic semantic search models trained on internet-scale text do not have this understanding for specialized R&D domains. Platforms built on proprietary R&D ontologies, trained on the language of patents and scientific publications, perform meaningfully better at the relevance evaluation task that continuous monitoring depends on.
The platform needs an agentic architecture, not just AI features bolted onto a search interface. Continuous monitoring requires agents that can run defined workflows on a schedule, maintain state across runs, apply consistent reasoning, and produce auditable outputs. This is a different technical foundation than a chat interface or a semantic search box.
The platform needs to integrate with R&D workflows. Monitoring output that lives inside the platform produces less value than monitoring output that flows into the project workspaces, Stage-Gate reviews, and portfolio dashboards where R&D decisions actually get made. Workflow integration is often the difference between a tool that gets adopted and a tool that gets demoed and abandoned.
Finally, the platform needs to meet enterprise-grade security requirements. R&D monitoring frequently touches sensitive program information, and any platform handling that data needs to meet the security expectations of Fortune 500 R&D and IP organizations.
Where Cypris Fits
Cypris is an enterprise R&D intelligence platform built specifically for the continuous monitoring use case. It indexes more than 500 million patents and scientific papers in a unified corpus, applies a proprietary R&D ontology developed for the language of technical research, and provides agentic workflows that R&D and IP teams can configure to run continuous monitoring against defined research theses.
The platform was designed from the ground up around the workflow needs of R&D scientists and innovation strategists rather than IP attorneys and search professionals, which is reflected in how monitoring is structured. Research theses are written in natural language. Escalations include written rationales. Output integrates with project workspaces and downstream R&D processes. The architecture is agentic rather than search-first, which is what makes the continuous use case practical at the scale Fortune 500 R&D teams need.
For teams currently running patent monitoring through a combination of saved searches in a legacy tool and human review of digest emails, Cypris represents a different category of system: one where the interpretive work that previously had to happen in a human's head can happen continuously, in the agent, across the full corpus, every day.
Frequently Asked Questions
What is an AI patent search platform?An AI patent search platform is software that uses machine learning and large language models to search, analyze, and monitor patent literature, going beyond keyword matching to understand the semantic content of filings. The most advanced platforms combine patent data with scientific literature, apply domain-specific ontologies trained on technical research language, and support agentic workflows that can run continuous monitoring rather than only one-time searches.
How does AI patent monitoring differ from traditional patent alerts?Traditional patent alerts notify users when new filings match a saved search query, producing a digest of matches that requires human review to determine relevance. AI patent monitoring uses agents that evaluate each new filing against a defined research thesis, apply interpretive reasoning to determine actual relevance, filter out false positives that match on language but not on substance, and escalate filings with written rationales explaining why they matter.
Can AI agents replace patent analysts?AI agents do not replace patent analysts; they extend the analyst's reach by running interpretive workflows continuously and at scale. The work that analysts do best — strategic judgment, claim-level analysis, integration of patent intelligence with business context — remains human work. The work that agents do best — evaluating high volumes of new filings against defined criteria, every day, consistently — frees analysts to focus on the smaller number of filings that genuinely warrant their attention.
What kind of R&D teams benefit most from continuous patent monitoring?Continuous patent monitoring produces the most value for R&D teams working in fast-moving technical domains, teams with long development cycles where the patent landscape may shift between program kickoff and launch, teams tracking specific competitors closely, and innovation strategy or corporate venture teams trying to detect technology emergence before it becomes obvious from market signals. Teams running primarily reactive patent work — checking the landscape only when a specific decision requires it — see less benefit from continuous monitoring than teams whose decisions depend on real-time landscape awareness.
How is continuous monitoring different from a saved search?A saved search returns documents that match a query at the time the search runs. Continuous monitoring runs an agent that evaluates new filings against a research thesis as they publish, applies interpretive criteria to determine relevance, and produces a smaller, higher-signal escalation queue with written rationale. The saved search produces matches; the monitoring agent produces interpreted intelligence.
What should a research thesis for AI patent monitoring include?A research thesis should describe the technical scope in specific terms, identify what is explicitly out of scope, name competitors and assignees that warrant elevated attention, specify jurisdictions of priority, and articulate the decisions the monitoring is meant to inform. The more structured the thesis, the more accurately the agent can evaluate relevance and the smaller and more useful the escalation queue becomes.
How often should continuous patent monitoring run?For most R&D and IP applications, daily monitoring aligned with patent office publication cycles is appropriate. Weekly monitoring is sometimes adequate for slower-moving technology domains, but the marginal cost of running an agent daily versus weekly is low, and the latency benefit is meaningful when the monitoring informs time-sensitive decisions.
What's the connection between patent monitoring and scientific literature monitoring?Patents and scientific publications are connected stages of the same research pipeline, and most filed inventions appear first in some form in scientific literature, often six to eighteen months earlier. Patent monitoring that incorporates scientific literature surfaces leading indicators that patent-only monitoring misses entirely. This is one of the structural advantages of platforms that index both corpora in a unified system.
How do AI patent search platforms handle confidentiality?Enterprise AI patent search platforms used by Fortune 500 R&D teams maintain enterprise-grade security architecture, including isolation of customer data, controls on how data interacts with AI models, and compliance with the security requirements typical of corporate research environments. Specific security postures vary by platform, and any team evaluating a platform for sensitive R&D monitoring should confirm that the security architecture meets their internal standards.
What's the difference between AI patent search and agentic patent search?AI patent search uses machine learning to improve the accuracy and relevance of search results within a single user-initiated query. Agentic patent search uses AI agents to run multi-step workflows that include search but also include evaluation, comparison, synthesis, and continuous execution. AI patent search is a feature; agentic patent search is an architecture, and continuous monitoring is the workflow it enables.
%20-%20BPA%20Replacements%20in%20Epoxy%20Resin.png)
%20-%20Competitive%20Benchmarking%20for%20Sustainable%20Construction%20Material%20Innovators.png)
%20-%20Analysis%20of%20U.S.%20Industrials%20Market.png)
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)