
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
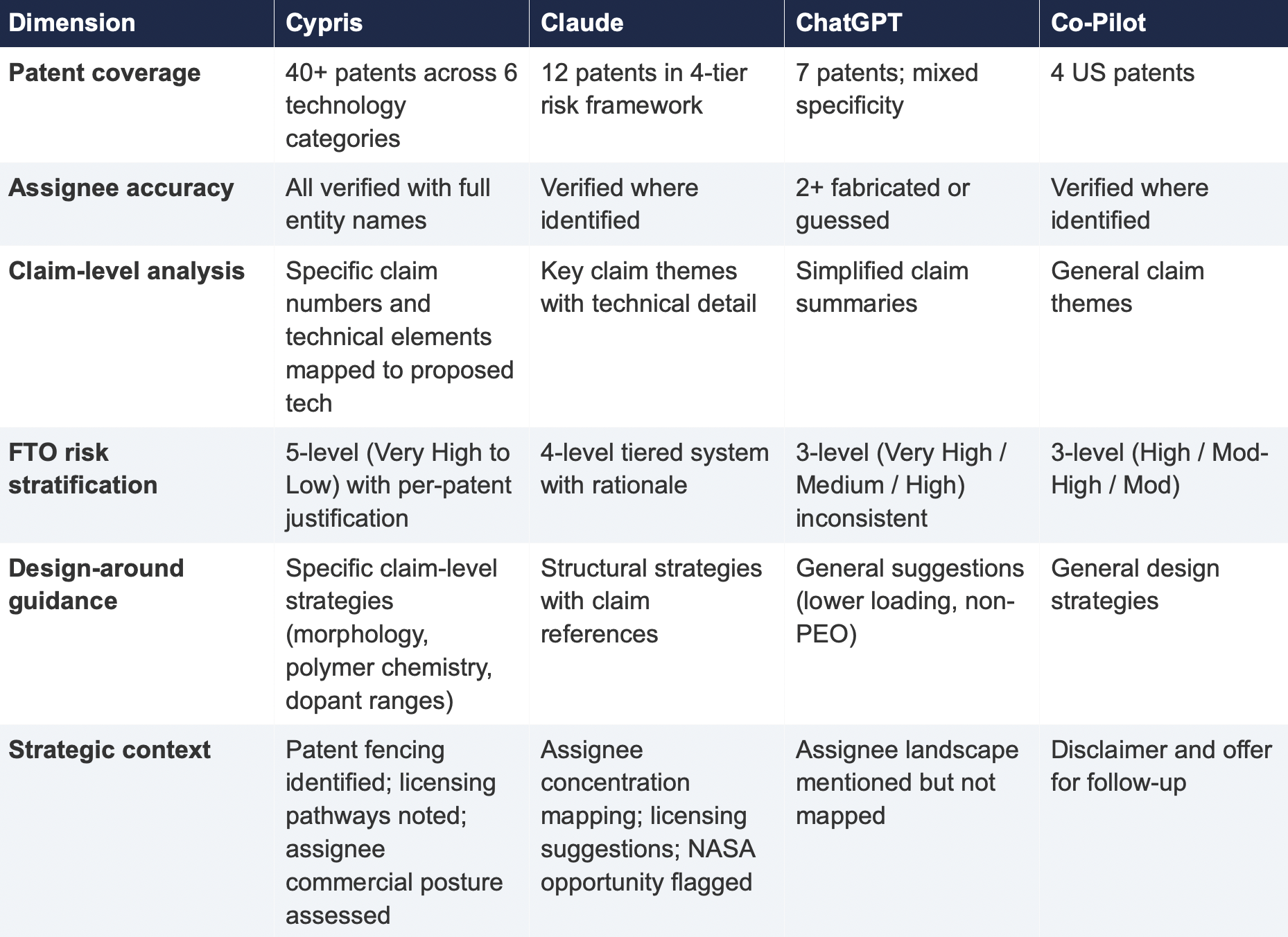
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
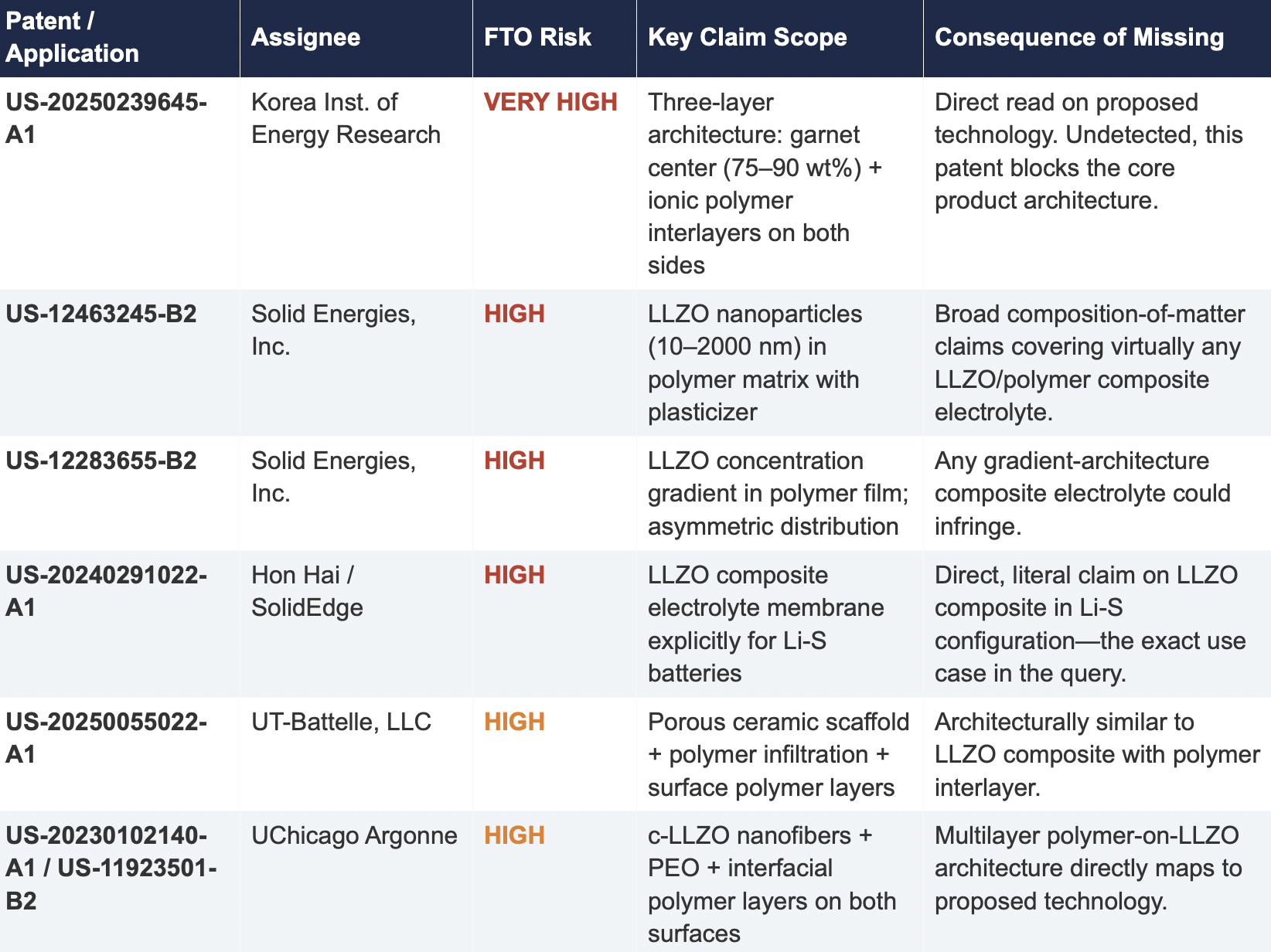
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

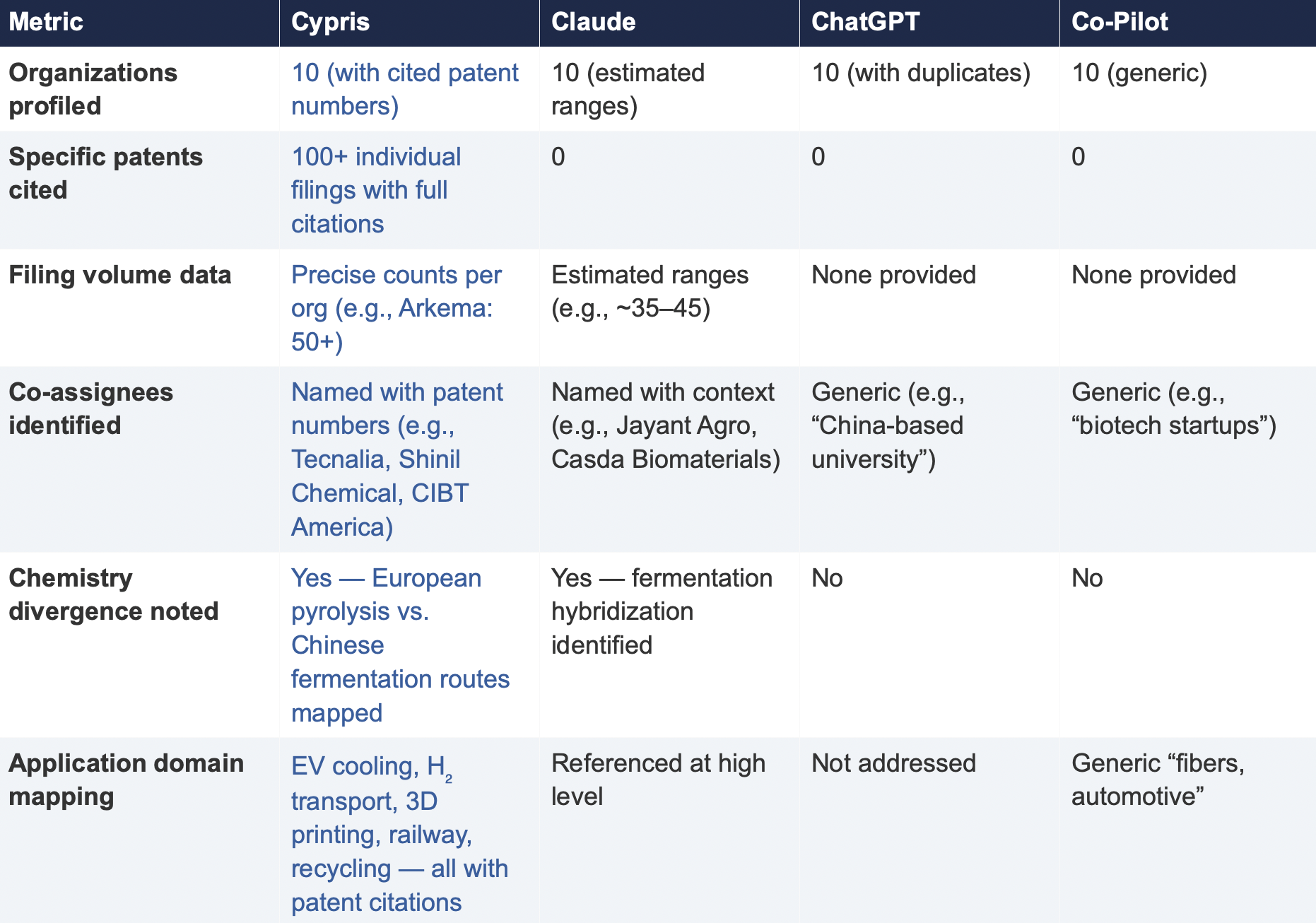
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

In honor of mental health awareness month, we’re diving into one of the pressing issues that individuals struggle with in today’s world—sleep. In particular, we’re looking at how technology is transforming how we measure our sleep.
Sleep plays a key role in mental health and overall bodily health and most people aren’t getting enough of it. According to a joint study conducted by Casper and Gallup, only one-third of Americans report their sleep as “excellent” or “very good”. Those who rate their general mental health as “excellent” or “very good” are also 6x more likely to get high-quality sleep (Casper-Gallup, 2022).
Thankfully, technology is helping to change the sleep game. Sleep apps, wearable trackers, smart beds, and external monitors are transforming how humans recharge. For those who don’t get enough sleep or experience poor quality sleep, trackers can help offer insight into your habits and lead you to optimize your sleep experience. Using the market news, research papers, and technologies sections of the Cypris platform, we were able to source a handful of fascinating consumer sleep trackers available and explore how they work.
Market overview
There are currently 98,136 sleep technologies being applied within 131 different categories. The fastest-growing category is ‘IT computing and data processing’ with a 1283.55 % increase in new patents filed over the last 5 years. ‘Medical’ is also seeing a lot of filings by new entrants.
When it comes to recent news on the sleep industry, a large chunk of articles have focused on new products (38%) and earnings reports (28%), followed by lawsuits, acquisitions, and new hires.
For this article, we’re focused specifically on sleep trackers since they’re such a hot topic these days. Let’s take a look at how these technologies work.
How sleep trackers work
Depending on the type of device, sleep technologies track different bodily responses. However, there are some general metrics most cover: heart rate, oxygen consumption, body movement, sleep duration, sleep quality, sleep phases, time awake and time spent sleeping, snoring, body temperature, room temperature and humidity, light and noise levels, environmental factors, and various lifestyle factors (like number of steps, exercise, etc.).
Many sleep tracker apps rely on an accelerometer, a device built into most smartphones that senses movement. These devices measure how much movement you make during your sleep and this data is then used in an algorithm to estimate sleep time and quality.
Trackers that are placed below your mattress use sensors to gauge movement to determine when you’re asleep, while wearable devices use direct skin contact to discern your heart rate and motion, getting a sense of your sleep and wake patterns accordingly.
Additionally, there are sonar trackers which rely on an app to send silent signals into your sleep environment. When these sound waves reflect into your microphone, some apps or devices can interpret their shape and movement—measuring your breathing rate, tracking your body movement, and turning those insights into a record of your nightly sleep patterns.
Tracker apps and other technologies available:
Available trackers range from apps that charge per month to pricier wearables or devices that often tie into an app as well. Here’s how a few of the most popular ones work:
- Sleep Cycle: (app) SleepCycle relies on sound-sensing technology to assess your sleep, using the microphone to detect the sounds you make when you move. The app identifies a variety of different sounds, including coughing, talking, and snoring, and shows an overlay of audio recordings on the sleep cycle graph for better interpretation. The app wakes you up within a 30-minute time frame of your choosing, based on when your sleep is the lightest.
- SleepScore: (app) SleepScore uses sonar sensor technology, called echolocation, to track your breathing and body movement as you travel through each sleep stage. After each night’s sleep, the app gives you a score based on its analysis of your sleep duration, the amount of time it took for you to fall asleep, light sleep, deep sleep, REM sleep, and wake time, with the units expressed in simple hours and minutes. It also reports how many times you woke up during the night and when you were experiencing each phase of sleep.
- Pillow: (app) Pillow is an app that tracks your sleep health from your Apple Watch, iPhone, or iPad. To calculate sleep quality, Pillow monitors movements and sounds. Pillow takes into account body motions during sleep using the device’s accelerometer and gyroscope, and monitors noise level using your device’s microphone. The audio recording feature records when you snore, cough, or talk in your sleep, and you can also use Pillow as a smart alarm clock to wake up at the lightest possible sleep stage.
- Oura Ring 3: (ring) The Oura Ring 3 collects data on time spent in light, deep, and REM sleep, resting heart rate, heart rate variability, number of breaths per minute (respiratory rate), body temperature, and nighttime movement. It calculates your sleep score based on factors such as total sleep, REM sleep, and deep sleep, and provides you with a readiness score (how much your body can take on for the day), and an activity score. The rings works using 15 advanced sensors. The green and red LEDs and infrared (IR) LEDs are used to measure daytime and workout heart rate, while extra negative temperature coefficient (NTC) sensors and an advanced calibrated sensor measure differences in skin temperature. The ring’s seven temperature sensors also help predict your period each month and visualize your menstrual cycle, and can even help you discover you are getting sick before symptoms appear. There is also an extra IR sensor that allows the ring to detect when the ring is not optimally aligned and compensate for more accurate results.
- Whoop Strap 4.0: (wristband) Primarily used by fitness fanatics due to its robust recovery data, this device contains five LEDs, four photodiodes, and a body temperature sensor. This wrist or bicep band measures blood oxygen levels, skin temperature readings, heart rate metrics, sleep cycles, performance, quality, and training activities to provide insight into your overall health behaviors and goals.
- Kookoon Nightbuds: (earbuds) These earbuds contain an in-ear optical heart rate sensor to track your sleep, which is located on the right earpiece. The Nightbuds are equipped with sensors that track sleep data such as time spent asleep and awake, position changes, and overall sleep efficiency.
- Withings Sleep Analyzer: (mattress pad) The Withings Sleep Analyzer is a thin mat you slip under your mattress that records changes in pressure and noise during the night. It provides you with an overall sleep score, which is then broken down into duration, time to sleep, depth, time to get up, interruptions, and regularity (measured over a period of several nights). With a Pneumatic sensor it measures respiratory rate, heartbeats (via ballistocardiography), and body movements across the mattress. With the sound sensor it identifies audio signals specific to snoring and cessation of breathing episodes.
- SleepScore Max: (external device) This device sits on your nightstand and uses a bio-motion sensor technology to track your breathing and body movement during sleep. It measures sleep duration, all the different sleep stages, and the time it takes you to fall asleep, and delivers an overall sleep score that’s provided through the accompanying app.
- Muse Headband: (headband) Known for its meditation capabilities, the Muse Headband is a wearable brain sensing headband that measures brain activity via 4 electroencephalography sensors. Sensors are strategically placed to connect to your forehead, and to the skin behind and above your ears on the inside of the headband. The device provides EEG-powered meditation and sleep support through sleep-focused voice guides and soundscapes that get you in a sleeping mood, and measures and analyzes your level of brain activity, heart rate, and breath much like other wearable trackers.
Sleep technology and trackers have transformed how we measure sleep, and continue to evolve and generate adoption. If you’re like the majority of the population and suffer from poor quality and quantity of sleep, chances are you could benefit from incorporating a tracking technology into your routine to provide clarity on your sleep patterns and improve overall health.
For deeper insights into innovative technologies that are changing your industry, visit https://ipcypris.com/ and get started using the Innovation Dashboard.
If you’d like to explore recent patents filed, you can search through our global patent search engine for free here: https://ipcypris.com/patents/allrecords
Sources:
Cypris Innovation Dashboard; queries for sleep, and sleep + technology
https://www.thensf.org/wp-content/uploads/2022/03/NSF-2022-Sleep-in-America-Poll-Report.pdf
https://www.tomsguide.com/round-up/best-sleep-apps
https://www.nature.com/articles/s41746-020-0244-4
https://finance.yahoo.com/news/ar-medical-disrupting-digital-health-150000081.html
https://www.gq-magazine.co.uk/lifestyle/article/best-sleep-tech
https://www.theverge.com/23013600/best-sleep-tracker-wearables
https://www.hopkinsmedicine.org/health/wellness-and-prevention/do-sleep-trackers-really-work
https://news.gallup.com/poll/390734/sleep-struggles-common-among-younger-adults-women.aspx
https://www.techradar.com/reviews/withings-sleep-analyzer
https://www.sleephealthfoundation.org.au/pdfs/SleepTracker-0215.pdf
https://www.theverge.com/22957195/whoop-review-fitness-tracker-wearables
https://www.healthline.com/health/fitness/oura-ring#the-sensors
https://www.forbes.com/sites/forbes-personal-shopper/2022/01/26/muse-s-review/?sh=13ca06b81e04

COVID-19 altered workplace dynamics, forcing companies to rapidly transition to remote work. For many individuals, remote work is here to stay in some form, whether through a hybrid in-office/work-from-home model or fully remote. In this blog, we explore how COVID-19-induced remote work changed workplace behaviors, and more importantly, how it impacted employee well-being for the better and worse.
Using the Cypris innovation dashboard, we explored innovation activity in the field of remote work, conducting a literature review among the 17,272 available research papers. Take a look at what we found.
The good
For companies, remote work comes with its savings—organizations save around $11,000 per employee per year if they allow their employees to work remotely at least 50% of the time (Global Workplace Analytics, 2021). More importantly, data shows that remote workers tend to be more satisfied with their work/life balance (Sundin, 2010). Remote work is also associated with higher organizational commitment, job satisfaction, and job-related well-being (Felstead & Henseke, 2017), as well as decreased turnover intention (Kroll & Neusch 2017). While many studies report individuals have a positive view of remote work, the key to happy employees, satisfaction, and reduced burnout when working from home is employee engagement.
Gallup (2021) defines employee engagement (EE) as individuals who are enthusiastic about, committed to, and involved in their work and workplace. According to Saks and Gruman (2014), factors proven to positively affect levels of EE within an organization include: “autonomy, feedback, development opportunities, positive workplace climate, recovery, rewards, recognition, and support”. When employees are engaged, loyalty, productivity, and their desire to go above and beyond in their organizations increase (Schaufeli & Bakker, 2004; Lemon & Palenchar, 2018; Weideman & Hofmeyr, 2020). COVID-19, in particular, affected EE rates—Gallup reported that EE in 2020 “fluctuated more than ever before”, and that the level of EE among U.S. workers reached a new high with 40% reporting to be “very engaged” in July 2020 compared to 33% in July 2019.
The bad
Despite the extensive benefits of remote work, it’s important to acknowledge that there are some downfalls. One source found that remote work comes at the cost of work-intensification and a greater inability to switch off (Felstead & Henseke, 2017). Generally, the biggest risk of flexible work comes when no clear boundaries are in place, leading employees to feel the need to be constantly online. Depending on factors like personality type and gender, remote work can also have a negative impact.
For some, remote work increases performance and job satisfaction, while others are left feeling isolated and less productive. A 2020 study assessed how different personality types experience remote work, assessing traits like conscientiousness (being organized and thoughtful), introversion (being quiet and reserved), neuroticism (being moody and easily frustrated), openness to experience (being curious and eager to try new things), and agreeableness (being friendly and kind to others) (Ogbonnaya, 2020). Those who scored high on openness to experience felt less worried, depressed, or miserable when working remotely, while agreeable people and introverts also reported feeling less worried and depressed. Neurotic people were at a greater risk of reporting poor mental health when working remotely. Those who scored low on conscientiousness, or found it hard to plan things carefully, reported feeling worried and gloomy (Ogbonnaya, 2020).
Gender also plays a key role in how people experience remote work, which several studies conducted during COVID-19 uncovered. A 2021 study on women in IT found that women were negatively affected by remote work resulting from the pandemic, due to the struggle to balance occupational stress and family life (Subha B. et al., 2021). Other data, including reports by McKinsey, uphold this trend.
McKinsey asserts that decades of research indicate that women take on more housework and childcare than men in addition to their professional careers, leading to what sociologists deem the “second shift”. In fact, mothers were over 3x more likely to be responsible for most of the housework and caregiving during the pandemic, and 1.5x more likely to spend an additional 3 or more hours per day on housework and children (McKinsey, 2020). As a result, many mothers, particularly those with young children, considered leaving the workforce or downshifting their careers during COVID-19, primarily due to childcare responsibilities. Despite the risk of burnout, women still report a higher preference for remote work post-pandemic than men—since women feel disproportionately responsible for household chores and parenting obligations, the flexible of remote work is ideal.
Where we go from here
While remote work offers more flexibility and increases well-being for most employees, it’s important to address the risk it poses for workers across the board—burnout. Companies should take measures to increase employee engagement, mental health benefits, support for parents and caregivers, and offer more paid leave to help mitigate burnout risk. Additionally, establishing clear boundaries that protect downtime, measuring performance based on results, and encouraging employees to take time for themselves can go a long way to reduce burnout and lessen the risk of losing talent, particularly women.
To learn more about remote work research, visit cypris.ai and get started with access to the innovation dashboard for more insights.
Sources:
B., Subha, R., Madhusudhanan, and Thomas, A., 2021. An Investigation of the Impact of Occupational Stress on Mental health of remote working women IT Professionals in Urban health of remote working women IT Professionals in Urban Bangalore, India Bangalore, India. Journal of International Women's Studies, 22(6).
Felstead, A., & Henseke, G. (2017). Assessing the growth of remote working and its consequences for effort, well-being and work-life balance. New Technology, Work and Employment, 32 (3). https://onlinelibrary.wiley.com/doi/full/10.1111/ntwe.12097
Gallup, I., 2021. How to Improve Employee Engagement in the Workplace. [online] Gallup.com. Available at: https://www.gallup.com/workplace/285674/improve-employee-engagement-workplace.aspx [Accessed 17 May 2022].
Global Workplace Analytics. 2022. Latest Work-at-Home/Telecommuting/Remote Work Statistics. [online] Available at: https://globalworkplaceanalytics.com/telecommuting-statistics [Accessed 17 May 2022].
Kroll, C., & Nuesch, S. (2017, 2019). The effects of flexible work practices on employee attitudes: Evidence from a large-scale panel study in Germany. International Journal of Human Resource Management, 30(9), 1505-1525. doi:10.1080/09585192.2017.1289548
Lemon, L. L., & Palenchar, M. J. (2018). Public relations and zones of engagement: Employees’ lived experiences and the fundamental nature of employee engagement. Public Relations Review, 44(1), 142-155. doi:10.1016/j.pubrev.2018.01.002
Ogbonnaya, C., 2020. Remote working is good for mental health… but for whom and at what cost?. [online] LSE Business Review. Available at https://blogs.lse.ac.uk/businessreview/2020/04/24/remote-working-is-good-for-mental-health-but-for-whom-and-at-what-cost/ [Accessed 17 May 2022].
Pernefors, O. and Bjurenvall, S., 2021. EMPLOYEE ENGAGEMENT IN A COVID-19 CONTEXT Exploring communicative displays of employee engagement among enforced remote workers. University of Gothenburg.
Saks, A. and Gruman, J., 2014. What Do We Really Know About Employee Engagement?. Human Resource Development Quarterly, 25(2), pp.155-182.
Sundin, K., 2010. Virtual Teams: Work/Life Challenges - Keeping Remote Employees Engaged. CAHRS White Papers.
FlexJobs Job Search Tips and Blog. 2022. Survey: Men & Women Experience Remote Work Differently | FlexJobs. [online] Available at: <https://www.flexjobs.com/blog/post/men-women-experience-remote-work-survey/> [Accessed 17 May 2022].
Weideman, M., & Hofmeyr, K. B. (2020). The influence of flexible work arrangements on employee engagement: An exploratory study. SA Journal of Human Resource Management, 18(2), e1-e18. doi:10.4102/sajhrm.v18i0.1209
“Women in the Workplace 2021.” McKinsey & Company, McKinsey & Company, 13 Apr. 2022, https://www.mckinsey.com/featured-insights/diversity-and-inclusion/women-in-the-workplace.
Wrycza, S. and Maślankowski, J., 2020. Social Media Users’ Opinions on Remote Work during the COVID-19 Pandemic. Thematic and Sentiment Analysis. Information Systems Management, 37(4), pp.288-297.

Virtual reality (VR) allows us to simulate real-world surroundings, and build environments that are impossible to visit in the real world—leading to endless applications for education. Research has shown VR can help engage students, improve retention, and gamify the traditional didactic teaching experience. In this blog post, we explore the research industry of VR in education at a glance, and then dive into research applications being explored today.
Market Overview
Using the Cypris innovation dashboard, we identified innovation activity in the VR market has grown over the last 5 years, with a 23.2% average growth rate. Within the vertical, there are over 625 technologies being applied within 22 different categories. The fastest-growing category is optical, specifically optical elements, systems or apparatuses, which saw a 213.33% increase in new patents filed over the past 5 years. Additionally, the industry currently has 130,917 investors, 974 research papers, and 332 organizations.

The most active top players in VR education by patent number include Samsung Electronics (20), Lincoln Global Inc. (14), Hunan Hankun Ind Co Inc. (6), Univ Korea Res & Bus Found (5), and the State Grid Corp China (5).
Research Applications
Below, we’ve rounded up some of the most fascinating recent research applications of VR for educational purposes:
- Environmental education: Taiwan recently incorporated environmental education into its curriculum guidelines, but needed a more effective way of engaging students with the material. They used VR to increase students’ immersion in order to generate empathy toward the natural environment and encourage behaviors to protect it. When compared with students who received conventional didactic teaching and viewed an ordinary video, the students who experienced the 3D VR teaching approach presented a significant difference in terms of learning absorption. Students who took a VR-based course also exhibited greater empathy toward the survival of protected species, which generated their desire to help the animals, protect global environments, and increase their awareness of the importance of global environmental conservation. (Chiang 2021)
- Bioscience virtual laboratory: VR approaches help train students in scientific methods and techniques that are difficult, dangerous, or expensive to perform in person. Due to the COVID-19 pandemic, no laboratory practicals could be performed, which brought to light an increased need for effective online teaching for laboratory courses. In this study, undergraduate students enrolled in a laboratory course used VR for their module on tissue culture techniques. The results revealed that the VR approach was highly and enthusiastically accepted by the students, and they reported authentic learning experiences that enabled them to better achieve the learning objectives. (Kaltsidis, et al. 2021)
- Vocational education: VR technologies have been implemented to teach vocational skills, enabling participants to learn by doing and use the appropriate equipment and tools needed. One recent study proposed using a VR simulation developed for participants to learn the two-stroke engine, which is relatively uncommon in the real world. The proposed VR system has the potential to reduce the total cost involved for the training institution compared to the conventional training method, and improves safety by protecting participants from any fragile parts and hazardous chemicals. (Sholichin, et al. 2020)
- Road safety: One study tackled teaching children how to properly focus attention in complex traffic situations, using a VR cycling simulator. The study focused on measuring observation ability and three key concepts: risk, orientation, and attention. The results revealed that eye tracking in virtual reality can be successfully utilized to evaluate interactive cognitive systems involved in navigation and the planning of actions in a traffic safety educational setting. The new teaching model was shown to be more effective in helping the children to focus their attention on the right place, orientate themselves, and behave in a safer way when cycling. (Skjermo, et al. 2022)
- Medicinal chemistry: A prototype VR gamification option was used as an educational tool to aid the learning process and to improve the delivery of the medicinal chemistry subject to pharmacy students. Typically, students face challenges caused by difficulty constructing a mental image of the three-dimensional structure of a drug molecule from its two-dimensional presentations. This study alleviated that challenge, and served as an accessible, cost-effective, flexible, and user-friendly alternative to traditional learning. (Abuhammad, et al. 2021)
- Psychiatric treatment: VR offers numerous possibilities of treatment directions for psychiatric patients. Most studies of VR for psychiatry have focused on virtual reality exposure therapy, a form of exposure therapy using virtual reality to create environments that provoke anxiety. Additionally, there are promising studies on using VR to treat depression and psychotic delusions. In areas with personnel shortages, VR treatments could be particularly helpful. Replicating environments to represent the experiences of patients may also offer helpful methods of psycho-education for parents, service providers, and the public. (Homen 2021)
From healthcare and bioscience, to teaching trade skills, VR’s applications for education are endless. To learn more about educational applications of VR, visit ipcypris.com and get started with access to the innovation dashboard for more insights.
If you’d like to explore recent patents filed, you can search through our global patent search engine for free here: https://ipcypris.com/patents/allrecords
Sources Cited:
1. Chiang TH-C (2021) Investigating Effects of Interactive Virtual Reality Games and Gender on Immersion, Empathy and Behavior Into Environmental Education. Front. Psychol. 12:608407
2. Source: Kaltsidis, Christos, et al. “Training Higher Education Bioscience Students with Virtual Reality Simulator.” European Journal of Alternative Education Studies, vol. 6, no. 1, 2021, https://doi.org/10.46827/ejae.v6i1.3748.
3. Sholichin, F., Suaib, N., Irawati, D., Sutiman, Solikin, M., Yudantoko, A., Yudianto, A., Adiyasa, I., Sihes, A. and Sulaiman, H., 2020. Virtual reality learning environments for vocational education: a comparative study with conventional instructional media on two-stroke engine. IOP Conference Series: Materials Science and Engineering, 979(1), p.012015.
4. Skjermo, Jo, et al. “Evaluation of Road Safety Education Program with Virtual Reality Eye Tracking.” SN Computer Science, vol. 3, no. 2, 2022, https://doi.org/10.1007/s42979-022-01036-w.
5. Abuhammad, A., Falah, J., Alfalah, S., Abu-Tarboush, M., Tarawneh, R., Drikakis, D. and Charissis, V., 2021. “MedChemVR”: A Virtual Reality Game to Enhance Medicinal Chemistry Education. Multimodal Technologies and Interaction, 5(3), p.10.
6. Homen, Joel. “Virtual Reality Opens New Frontiers in Psychiatric Treatment and Education.” The Finnish Foundation for Psychiatric Research, 2021.
Reports

This Cypris research brief maps the full ecosystem and value chain of electric vehicle battery systems and advanced battery materials, tracing the pathway from raw material extraction through precursor and active material production, cell component manufacturing, battery cell production, pack assembly, vehicle integration, and end-of-life recycling. The brief defines each segment's functional role, identifies key players across upstream, midstream, and downstream layers, and analyzes the structural forces — including critical mineral supply volatility, geographic concentration, OEM vertical integration strategies, recycling-driven circularity, and solid-state battery development — that are reshaping where value concentrates and where supply-chain risk resides.

This Cypris research brief maps the ecosystem and value chain of the specialty polymers and high-performance materials industry, covering the full pathway from raw material and monomer suppliers through polymer manufacturers, compounders, additive suppliers, specialty distributors, converters, and end-use OEMs across aerospace, automotive, electronics, medical, energy, and industrial markets. Beyond the segment-by-segment breakdown and player landscape, the brief analyzes the structural forces shaping the ecosystem — including vertical integration strategies, supplier concentration and consolidation patterns, geographic clustering, circularity constraints, and shifting end-market demand — with a central thesis that leverage in this ecosystem concentrates wherever technical specialization overlaps with requalification burden.

Cypris Research Services' inaugural Innovation Outlook examines how AI-driven data center demand is reshaping U.S. power infrastructure — and why hyperscalers have stopped waiting for the grid to catch up. The report synthesizes commercial activity, market sizing, technology trends, and patent-based competitive positioning into a single ecosystem view of behind-the-meter generation, sizing the U.S. opportunity at $35.8B and tracking 56 GW of contracted bypass capacity already in the pipeline. It identifies where the defensible whitespace actually sits — and it's not where most of the market is currently looking.
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)