
Resources
Guides, research, and perspectives on R&D intelligence, IP strategy, and the future of AI enabled innovation.

Executive Summary
In 2024, US patent infringement jury verdicts totaled $4.19 billion across 72 cases. Twelve individual verdicts exceeded $100million. The largest single award—$857 million in General Access Solutions v.Cellco Partnership (Verizon)—exceeded the annual R&D budget of many mid-market technology companies. In the first half of 2025 alone, total damages reached an additional $1.91 billion.
The consequences of incomplete patent intelligence are not abstract. In what has become one of the most instructive IP disputes in recent history, Masimo’s pulse oximetry patents triggered a US import ban on certain Apple Watch models, forcing Apple to disable its blood oxygen feature across an entire product line, halt domestic sales of affected models, invest in a hardware redesign, and ultimately face a $634 million jury verdict in November 2025. Apple—a company with one of the most sophisticated intellectual property organizations on earth—spent years in litigation over technology it might have designed around during development.
For organizations with fewer resources than Apple, the risk calculus is starker. A mid-size materials company, a university spinout, or a defense contractor developing next-generation battery technology cannot absorb a nine-figure verdict or a multi-year injunction. For these organizations, the patent landscape analysis conducted during the development phase is the primary risk mitigation mechanism. The quality of that analysis is not a matter of convenience. It is a matter of survival.
And yet, a growing number of R&D and IP teams are conducting that analysis using general-purpose AI tools—ChatGPT, Claude, Microsoft Co-Pilot—that were never designed for patent intelligence and are structurally incapable of delivering it.
This report presents the findings of a controlled comparison study in which identical patent landscape queries were submitted to four AI-powered tools: Cypris (a purpose-built R&D intelligence platform),ChatGPT (OpenAI), Claude (Anthropic), and Microsoft Co-Pilot. Two technology domains were tested: solid-state lithium-sulfur battery electrolytes using garnet-type LLZO ceramic materials (freedom-to-operate analysis), and bio-based polyamide synthesis from castor oil derivatives (competitive intelligence).
The results reveal a significant and structurally persistent gap. In Test 1, Cypris identified over 40 active US patents and published applications with granular FTO risk assessments. Claude identified 12. ChatGPT identified 7, several with fabricated attribution. Co-Pilot identified 4. Among the patents surfaced exclusively by Cypris were filings rated as “Very High” FTO risk that directly claim the technology architecture described in the query. In Test 2, Cypris cited over 100 individual patent filings with full attribution to substantiate its competitive landscape rankings. No general-purpose model cited a single patent number.
The most active sectors for patent enforcement—semiconductors, AI, biopharma, and advanced materials—are the same sectors where R&D teams are most likely to adopt AI tools for intelligence workflows. The findings of this report have direct implications for any organization using general-purpose AI to inform patent strategy, competitive intelligence, or R&D investment decisions.

1. Methodology
A single patent landscape query was submitted verbatim to each tool on March 27, 2026. No follow-up prompts, clarifications, or iterative refinements were provided. Each tool received one opportunity to respond, mirroring the workflow of a practitioner running an initial landscape scan.
1.1 Query
Identify all active US patents and published applications filed in the last 5 years related to solid-state lithium-sulfur battery electrolytes using garnet-type ceramic materials. For each, provide the assignee, filing date, key claims, and current legal status. Highlight any patents that could pose freedom-to-operate risks for a company developing a Li₇La₃Zr₂O₁₂(LLZO)-based composite electrolyte with a polymer interlayer.
1.2 Tools Evaluated

1.3 Evaluation Criteria
Each response was assessed across six dimensions: (1) number of relevant patents identified, (2) accuracy of assignee attribution,(3) completeness of filing metadata (dates, legal status), (4) depth of claim analysis relative to the proposed technology, (5) quality of FTO risk stratification, and (6) presence of actionable design-around or strategic guidance.
2. Findings
2.1 Coverage Gap
The most significant finding is the scale of the coverage differential. Cypris identified over 40 active US patents and published applications spanning LLZO-polymer composite electrolytes, garnet interface modification, polymer interlayer architectures, lithium-sulfur specific filings, and adjacent ceramic composite patents. The results were organized by technology category with per-patent FTO risk ratings.
Claude identified 12 patents organized in a four-tier risk framework. Its analysis was structurally sound and correctly flagged the two highest-risk filings (Solid Energies US 11,967,678 and the LLZO nanofiber multilayer US 11,923,501). It also identified the University ofMaryland/ Wachsman portfolio as a concentration risk and noted the NASA SABERS portfolio as a licensing opportunity. However, it missed the majority of the landscape, including the entire Corning portfolio, GM's interlayer patents, theKorea Institute of Energy Research three-layer architecture, and the HonHai/SolidEdge lithium-sulfur specific filing.
ChatGPT identified 7 patents, but the quality of attribution was inconsistent. It listed assignees as "Likely DOE /national lab ecosystem" and "Likely startup / defense contractor cluster" for two filings—language that indicates the model was inferring rather than retrieving assignee data. In a freedom-to-operate context, an unverified assignee attribution is functionally equivalent to no attribution, as it cannot support a licensing inquiry or risk assessment.
Co-Pilot identified 4 US patents. Its output was the most limited in scope, missing the Solid Energies portfolio entirely, theUMD/ Wachsman portfolio, Gelion/ Johnson Matthey, NASA SABERS, and all Li-S specific LLZO filings.
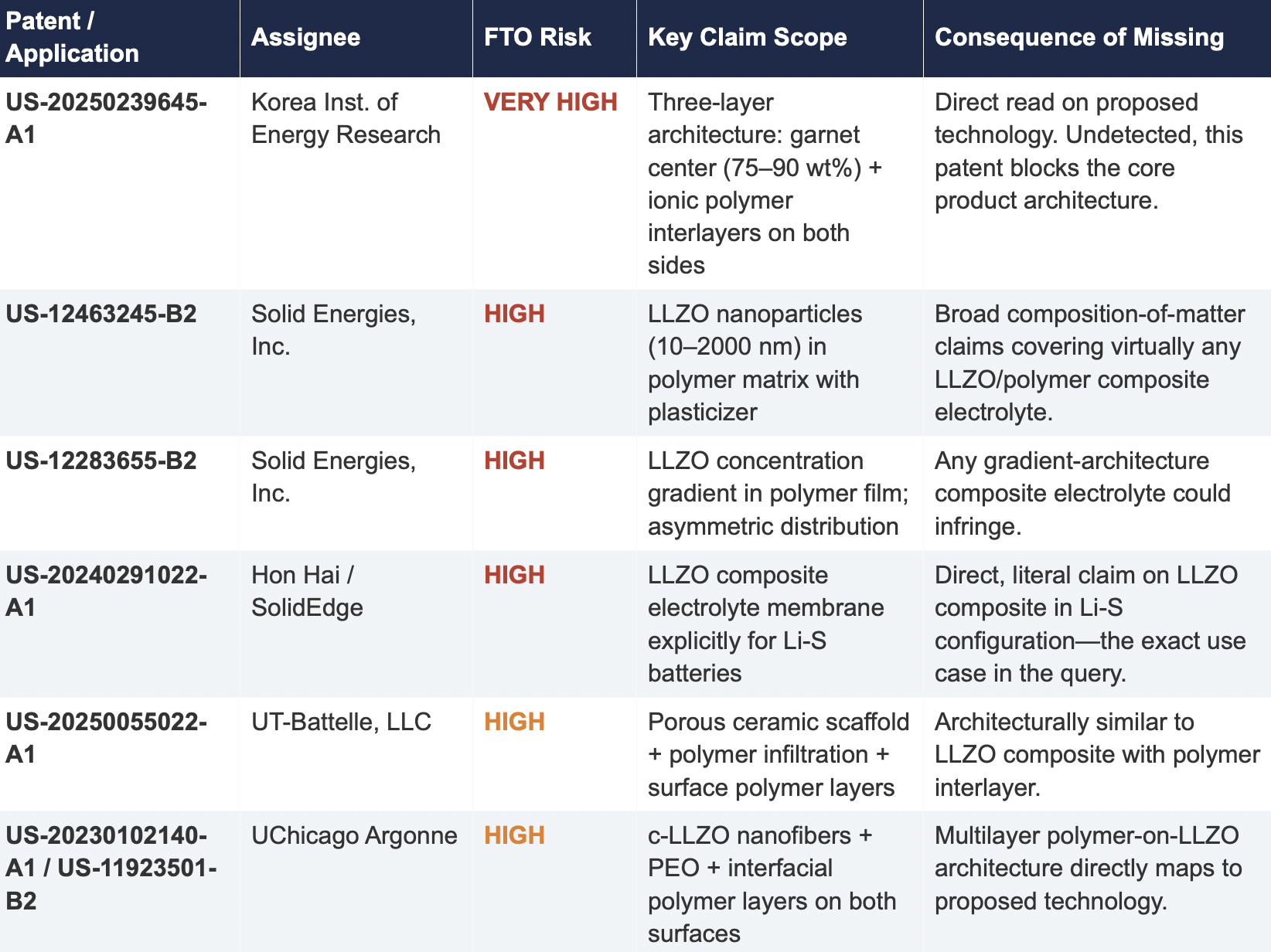
2.2 Critical Patents Missed by Public Models
The following table presents patents identified exclusively by Cypris that were rated as High or Very High FTO risk for the proposed technology architecture. None were surfaced by any general-purpose model.
2.3 Patent Fencing: The Solid Energies Portfolio
Cypris identified a coordinated patent fencing strategy by Solid Energies, Inc. that no general-purpose model detected at scale. Solid Energies holds at least four granted US patents and one published application covering LLZO-polymer composite electrolytes across compositions(US-12463245-B2), gradient architectures (US-12283655-B2), electrode integration (US-12463249-B2), and manufacturing processes (US-20230035720-A1). Claude identified one Solid Energies patent (US 11,967,678) and correctly rated it as the highest-priority FTO concern but did not surface the broader portfolio. ChatGPT and Co-Pilot identified zero Solid Energies filings.
The practical significance is that a company relying on any individual patent hit would underestimate the scope of Solid Energies' IP position. The fencing strategy—covering the composition, the architecture, the electrode integration, and the manufacturing method—means that identifying a single design-around for one patent does not resolve the FTO exposure from the portfolio as a whole. This is the kind of strategic insight that requires seeing the full picture, which no general-purpose model delivered
2.4 Assignee Attribution Quality
ChatGPT's response included at least two instances of fabricated or unverifiable assignee attributions. For US 11,367,895 B1, the listed assignee was "Likely startup / defense contractor cluster." For US 2021/0202983 A1, the assignee was described as "Likely DOE / national lab ecosystem." In both cases, the model appears to have inferred the assignee from contextual patterns in its training data rather than retrieving the information from patent records.
In any operational IP workflow, assignee identity is foundational. It determines licensing strategy, litigation risk, and competitive positioning. A fabricated assignee is more dangerous than a missing one because it creates an illusion of completeness that discourages further investigation. An R&D team receiving this output might reasonably conclude that the landscape analysis is finished when it is not.
3. Structural Limitations of General-Purpose Models for Patent Intelligence
3.1 Training Data Is Not Patent Data
Large language models are trained on web-scraped text. Their knowledge of the patent record is derived from whatever fragments appeared in their training corpus: blog posts mentioning filings, news articles about litigation, snippets of Google Patents pages that were crawlable at the time of data collection. They do not have systematic, structured access to the USPTO database. They cannot query patent classification codes, parse claim language against a specific technology architecture, or verify whether a patent has been assigned, abandoned, or subjected to terminal disclaimer since their training data was collected.
This is not a limitation that improves with scale. A larger training corpus does not produce systematic patent coverage; it produces a larger but still arbitrary sampling of the patent record. The result is that general-purpose models will consistently surface well-known patents from heavily discussed assignees (QuantumScape, for example, appeared in most responses) while missing commercially significant filings from less publicly visible entities (Solid Energies, Korea Institute of EnergyResearch, Shenzhen Solid Advanced Materials).
3.2 The Web Is Closing to Model Scrapers
The data access problem is structural and worsening. As of mid-2025, Cloudflare reported that among the top 10,000 web domains, the majority now fully disallow AI crawlers such as GPTBot andClaudeBot via robots.txt. The trend has accelerated from partial restrictions to outright blocks, and the crawl-to-referral ratios reveal the underlying tension: OpenAI's crawlers access approximately1,700 pages for every referral they return to publishers; Anthropic's ratio exceeds 73,000 to 1.
Patent databases, scientific publishers, and IP analytics platforms are among the most restrictive content categories. A Duke University study in 2025 found that several categories of AI-related crawlers never request robots.txt files at all. The practical consequence is that the knowledge gap between what a general-purpose model "knows" about the patent landscape and what actually exists in the patent record is widening with each training cycle. A landscape query that a general-purpose model partially answered in 2023 may return less useful information in 2026.
3.3 General-Purpose Models Lack Ontological Frameworks for Patent Analysis
A freedom-to-operate analysis is not a summarization task. It requires understanding claim scope, prosecution history, continuation and divisional chains, assignee normalization (a single company may appear under multiple entity names across patent records), priority dates versus filing dates versus publication dates, and the relationship between dependent and independent claims. It requires mapping the specific technical features of a proposed product against independent claim language—not keyword matching.
General-purpose models do not have these frameworks. They pattern-match against training data and produce outputs that adopt the format and tone of patent analysis without the underlying data infrastructure. The format is correct. The confidence is high. The coverage is incomplete in ways that are not visible to the user.
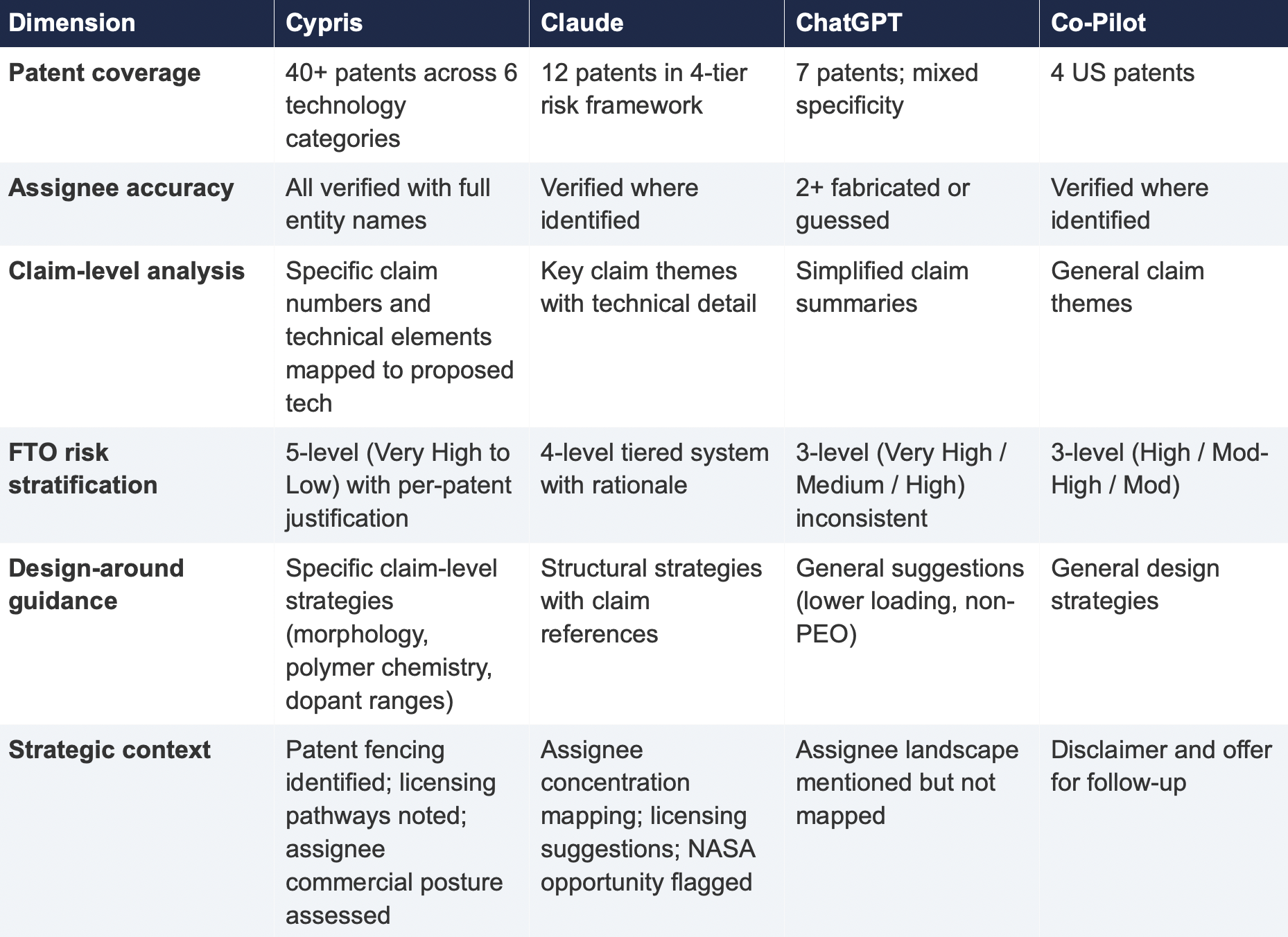
4. Comparative Output Quality
The following table summarizes the qualitative characteristics of each tool's response across the dimensions most relevant to an operational IP workflow.
5. Implications for R&D and IP Organizations
5.1 The Confidence Problem
The central risk identified by this study is not that general-purpose models produce bad outputs—it is that they produce incomplete outputs with high confidence. Each model delivered its results in a professional format with structured analysis, risk ratings, and strategic recommendations. At no point did any model indicate the boundaries of its knowledge or flag that its results represented a fraction of the available patent record. A practitioner receiving one of these outputs would have no signal that the analysis was incomplete unless they independently validated it against a comprehensive datasource.
This creates an asymmetric risk profile: the better the format and tone of the output, the less likely the user is to question its completeness. In a corporate environment where AI outputs are increasingly treated as first-pass analysis, this dynamic incentivizes under-investigation at precisely the moment when thoroughness is most critical.
5.2 The Diversification Illusion
It might be assumed that running the same query through multiple general-purpose models provides validation through diversity of sources. This study suggests otherwise. While the four tools returned different subsets of patents, all operated under the same structural constraints: training data rather than live patent databases, web-scraped content rather than structured IP records, and general-purpose reasoning rather than patent-specific ontological frameworks. Running the same query through three constrained tools does not produce triangulation; it produces three partial views of the same incomplete picture.
5.3 The Appropriate Use Boundary
General-purpose language models are effective tools for a wide range of tasks: drafting communications, summarizing documents, generating code, and exploratory research. The finding of this study is not that these tools lack value but that their value boundary does not extend to decisions that carry existential commercial risk.
Patent landscape analysis, freedom-to-operate assessment, and competitive intelligence that informs R&D investment decisions fall outside that boundary. These are workflows where the completeness and verifiability of the underlying data are not merely desirable but are the primary determinant of whether the analysis has value. A patent landscape that captures 10% of the relevant filings, regardless of how well-formatted or confidently presented, is a liability rather than an asset.
6. Test 2: Competitive Intelligence — Bio-Based Polyamide Patent Landscape
To assess whether the findings from Test 1 were specific to a single technology domain or reflected a broader structural pattern, a second query was submitted to all four tools. This query shifted from freedom-to-operate analysis to competitive intelligence, asking each tool to identify the top 10organizations by patent filing volume in bio-based polyamide synthesis from castor oil derivatives over the past three years, with summaries of technical approach, co-assignee relationships, and portfolio trajectory.
6.1 Query

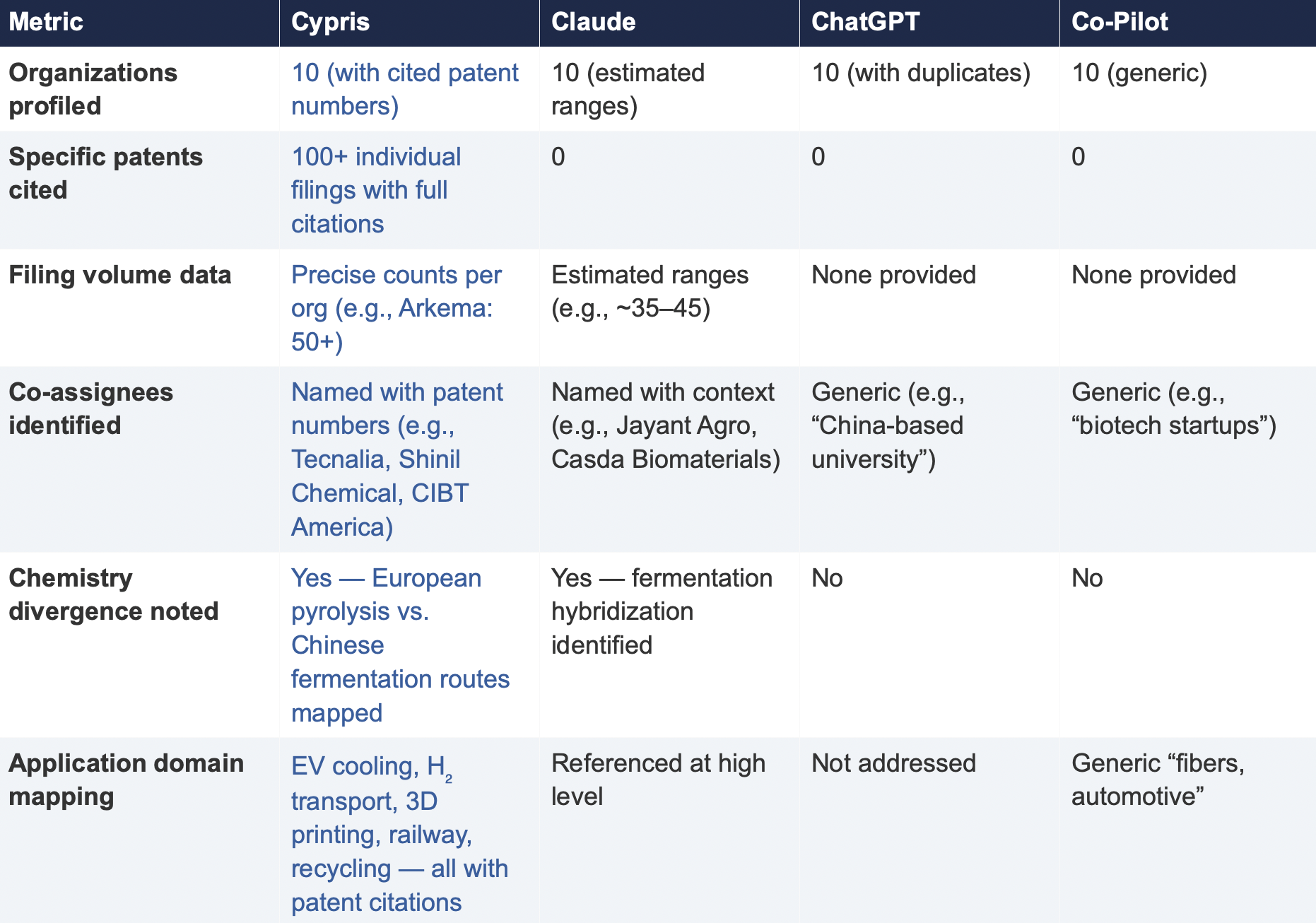
6.2 Summary of Results
6.3 Key Differentiators
Verifiability
The most consequential difference in Test 2 was the presence or absence of verifiable evidence. Cypris cited over 100 individual patent filings with full patent numbers, assignee names, and publication dates. Every claim about an organization’s technical focus, co-assignee relationships, and filing trajectory was anchored to specific documents that a practitioner could independently verify in USPTO, Espacenet, or WIPO PATENT SCOPE. No general-purpose model cited a single patent number. Claude produced the most structured and analytically useful output among the public models, with estimated filing ranges, product names, and strategic observations that were directionally plausible. However, without underlying patent citations, every claim in the response requires independent verification before it can inform a business decision. ChatGPT and Co-Pilot offered thinner profiles with no filing counts and no patent-level specificity.
Data Integrity
ChatGPT’s response contained a structural error that would mislead a practitioner: it listed CathayBiotech as organization #5 and then listed “Cathay Affiliate Cluster” as a separate organization at #9, effectively double-counting a single entity. It repeated this pattern with Toray at #4 and “Toray(Additional Programs)” at #10. In a competitive intelligence context where the ranking itself is the deliverable, this kind of error distorts the landscape and could lead to misallocation of competitive monitoring resources.
Organizations Missed
Cypris identified Kingfa Sci. & Tech. (8–10 filings with a differentiated furan diacid-based polyamide platform) and Zhejiang NHU (4–6 filings focused on continuous polymerization process technology)as emerging players that no general-purpose model surfaced. Both represent potential competitive threats or partnership opportunities that would be invisible to a team relying on public AI tools.Conversely, ChatGPT included organizations such as ANTA and Jiangsu Taiji that appear to be downstream users rather than significant patent filers in synthesis, suggesting the model was conflating commercial activity with IP activity.
Strategic Depth
Cypris’s cross-cutting observations identified a fundamental chemistry divergence in the landscape:European incumbents (Arkema, Evonik, EMS) rely on traditional castor oil pyrolysis to 11-aminoundecanoic acid or sebacic acid, while Chinese entrants (Cathay Biotech, Kingfa) are developing alternative bio-based routes through fermentation and furandicarboxylic acid chemistry.This represents a potential long-term disruption to the castor oil supply chain dependency thatWestern players have built their IP strategies around. Claude identified a similar theme at a higher level of abstraction. Neither ChatGPT nor Co-Pilot noted the divergence.
6.4 Test 2 Conclusion
Test 2 confirms that the coverage and verifiability gaps observed in Test 1 are not domain-specific.In a competitive intelligence context—where the deliverable is a ranked landscape of organizationalIP activity—the same structural limitations apply. General-purpose models can produce plausible-looking top-10 lists with reasonable organizational names, but they cannot anchor those lists to verifiable patent data, they cannot provide precise filing volumes, and they cannot identify emerging players whose patent activity is visible in structured databases but absent from the web-scraped content that general-purpose models rely on.
7. Conclusion
This comparative analysis, spanning two distinct technology domains and two distinct analytical workflows—freedom-to-operate assessment and competitive intelligence—demonstrates that the gap between purpose-built R&D intelligence platforms and general-purpose language models is not marginal, not domain-specific, and not transient. It is structural and consequential.
In Test 1 (LLZO garnet electrolytes for Li-S batteries), the purpose-built platform identified more than three times as many patents as the best-performing general-purpose model and ten times as many as the lowest-performing one. Among the patents identified exclusively by the purpose-built platform were filings rated as Very High FTO risk that directly claim the proposed technology architecture. InTest 2 (bio-based polyamide competitive landscape), the purpose-built platform cited over 100individual patent filings to substantiate its organizational rankings; no general-purpose model cited as ingle patent number.
The structural drivers of this gap—reliance on training data rather than live patent feeds, the accelerating closure of web content to AI scrapers, and the absence of patent-specific analytical frameworks—are not transient. They are inherent to the architecture of general-purpose models and will persist regardless of increases in model capability or training data volume.
For R&D and IP leaders, the practical implication is clear: general-purpose AI tools should be used for general-purpose tasks. Patent intelligence, competitive landscaping, and freedom-to-operate analysis require purpose-built systems with direct access to structured patent data, domain-specific analytical frameworks, and the ability to surface what a general-purpose model cannot—not because it chooses not to, but because it structurally cannot access the data.
The question for every organization making R&D investment decisions today is whether the tools informing those decisions have access to the evidence base those decisions require. This study suggests that for the majority of general-purpose AI tools currently in use, the answer is no.
About This Report
This report was produced by Cypris (IP Web, Inc.), an AI-powered R&D intelligence platform serving corporate innovation, IP, and R&D teams at organizations including NASA, Johnson & Johnson, theUS Air Force, and Los Alamos National Laboratory. Cypris aggregates over 500 million data points from patents, scientific literature, grants, corporate filings, and news to deliver structured intelligence for technology scouting, competitive analysis, and IP strategy.
The comparative tests described in this report were conducted on March 27, 2026. All outputs are preserved in their original form. Patent data cited from the Cypris reports has been verified against USPTO Patent Center and WIPO PATENT SCOPE records as of the same date. To conduct a similar analysis for your technology domain, contact info@cypris.ai or visit cypris.ai.
The Patent Intelligence Gap - A Comparative Analysis of Verticalized AI-Patent Tools vs. General-Purpose Language Models for R&D Decision-Making
Blogs

Written by the Cypris.ai research team | March 6th 2026
Every R&D leader in the chemicals industry has lived this nightmare. A development program that passed every stage gate review with green lights suddenly stalls in late-stage development because a blocking patent surfaces, a regulatory pathway proves more complex than anticipated, or a competitor reaches market first with a functionally equivalent product. The project is not killed by bad science. It is killed by bad intelligence.
The Stage-Gate model, pioneered by Robert Cooper in the 1980s and adopted by chemical companies from DuPont and Exxon Chemical onward, was designed to prevent exactly this kind of failure [1]. Its logic is elegant: divide the innovation process into discrete phases separated by decision points, and at each gate, evaluate whether the evidence supports continued investment. The framework has delivered enormous value over four decades. But it rests on a critical assumption that increasingly fails in practice. It assumes that the intelligence gathered at each stage is complete enough to support the decisions being made.
In the chemicals space, this assumption is breaking down. The sheer volume of global patent filings, the pace of regulatory change across jurisdictions like the EPA's evolving TSCA enforcement and the EU's REACH framework, the proliferation of competitors in specialty and advanced materials segments, and the accelerating convergence of chemical science with adjacent fields like biotechnology and computational materials design all mean that the information landscape is vastly more complex than it was when stage gate processes were first codified. The tools most R&D organizations rely on to scan that landscape have not kept pace.
The Anatomy of Late-Stage Failure in Chemical Development
Late-stage project failures are not merely disappointing. They are extraordinarily expensive. By the time a chemical development program reaches pilot scale or pre-commercialization, an organization has typically committed years of synthetic chemistry and formulation work, significant capital in specialized equipment and testing, and the opportunity cost of the scientists and engineers who could have been deployed elsewhere. In pharmaceutical and specialty chemical development, estimates of total R&D cost per successfully commercialized product consistently exceed one billion dollars, with the majority of that spend concentrated in later development phases [2][3].
The patterns are painfully familiar to anyone who has managed a chemicals portfolio. A team spends three years developing a novel flame retardant additive, clears every internal technical milestone, and reaches pilot-scale production only to discover that a competitor filed a broad process patent eighteen months earlier covering the catalytic method the entire synthesis route depends on. Or consider the specialty coatings program that advances to customer qualification trials before learning that the EPA is evaluating a Significant New Use Rule on a key intermediate compound, a development that would have been visible in regulatory monitoring databases but was not part of the team's standard early-stage diligence. Or the advanced adhesive formulation that reaches late-stage development and performs beautifully in testing, only for the target OEM customer to announce a supply chain commitment to eliminate the substance class entirely as part of a PFAS-adjacent sustainability initiative. In each case, the science was sound. The intelligence was not.
The Stage-Gate framework is specifically designed to mitigate this risk through early termination of projects that lack sufficient technical or commercial merit. As the U.S. Department of Energy's Stage-Gate Innovation Management Guidelines describe, information accumulated during each stage is meant to reduce technical uncertainty and economic risk so that researchers can make informed go or no-go decisions at every gate [4]. The expectation, as the guidelines note, is that projects with serious technical or other issues will be identified and resolved early on, enabling greater investment in the projects with greatest probability of success.
But here is the problem. The quality of a gate decision is only as good as the quality of the intelligence that informs it. When an R&D team conducts a freedom-to-operate analysis using a single patent database, reviews regulatory requirements based on one jurisdiction's current rules, and assesses competitive positioning through trade publication scanning, they are building a decision framework on a partial view of reality. The stage gate does not fail because its logic is wrong. It fails because the inputs are incomplete.
Patent Risk: The Most Expensive Blind Spot
Of all the risks that intensify in late-stage chemical development, patent risk may be the most financially devastating and the most preventable. The chemical patent landscape is extraordinarily dense. A single compound can be protected by composition of matter patents, process patents covering specific synthesis routes, formulation patents addressing polymorphs or salt forms, and application patents governing end-use scenarios. A project team that clears the composition of matter search but misses a process patent or a formulation polymorph patent can find itself facing an infringement claim precisely at the moment of commercialization [5].
This is not a theoretical concern. In the pharmaceutical and specialty chemical sectors, patent litigation damages in the United States reached a median of $8.7 million per award in 2023, with the highest awards exceeding two billion dollars, and the pharmaceutical and chemical industries accounting for a disproportionate share of total patent damages [6]. The indirect costs of litigation, including diversion of R&D leadership attention, disruption of commercial timelines, and erosion of investor confidence, often exceed the direct legal expenses.
The challenge for R&D leaders is that traditional patent search tools were designed for patent attorneys conducting narrow freedom-to-operate analyses on specific claims. They are not built for the kind of broad, continuous landscape scanning that would allow a development team to identify emerging patent thickets in adjacent technology spaces, monitor the filing behavior of competitors in overlapping application domains, or flag newly published applications that could affect a program's commercialization pathway. When a gate review asks whether the IP landscape is clear, the honest answer is usually that it is clear within the narrow scope that was searched. What was not searched remains unknown.
A more robust early-stage approach would involve continuous monitoring of patent activity across the full scope of a project's technology space, not just the specific compound or process under development but the broader category of materials, synthesis methods, and end-use applications that could create blocking positions. This kind of comprehensive visibility requires access to patent databases at a scale that most point tools cannot provide, ideally hundreds of millions of records spanning global jurisdictions, combined with intelligent search capabilities that can identify conceptual overlaps rather than just keyword matches.
Regulatory Risk Compounds Faster Than R&D Teams Expect
The chemicals industry operates under one of the most complex regulatory environments of any sector. In the United States alone, the Toxic Substances Control Act governs over 86,000 chemical substances, requiring pre-manufacture notification for any new chemical substance not already listed on the TSCA Inventory [7]. The 2016 Lautenberg Chemical Safety Act significantly expanded the EPA's authority and responsibility to evaluate chemical risks, creating more stringent requirements for data submission, risk assessment, and supply chain transparency [8]. Simultaneously, the EU's REACH regulation imposes its own extensive registration and evaluation requirements, and emerging chemical management frameworks in China, Korea, and other major markets add further layers of compliance complexity.
For an R&D team in early-stage development, regulatory requirements might appear manageable. A new chemical entity requires a pre-manufacture notification to the EPA, and the team files it. But as the project advances, the regulatory landscape can shift in ways that were not foreseeable from the early-stage vantage point. The EPA may issue a Significant New Use Rule that imposes additional restrictions on the substance class. A state-level regulation, like California's Proposition 65 or a PFAS-related restriction, may create market access barriers that did not exist when the project was initiated. An international regulatory body may classify a key precursor or byproduct as a substance of very high concern, disrupting the supply chain for a critical raw material.
These are not rare edge cases. Chemical regulatory frameworks are evolving continuously, and the pace of change has accelerated significantly since the Lautenberg amendments [9]. R&D organizations that assess regulatory risk only at designated gate reviews, rather than through continuous monitoring, are making investment decisions based on a snapshot of a moving target. By the time a regulatory change surfaces during a late-stage review, the organization has already committed resources that may be difficult or impossible to recover.
The antidote is not simply assigning more regulatory specialists to each project. It is ensuring that early-stage research captures a comprehensive view of the regulatory landscape, including pending rulemakings, international harmonization trends, and substance-class-level restrictions that might not directly target the compound under development but could affect its commercialization pathway or supply chain dependencies.
Competitive Intelligence Gaps and the Illusion of White Space
Early-stage R&D teams in the chemicals industry frequently identify market opportunities based on apparent white space: an application need that no existing product adequately addresses, a performance gap in currently available materials, or a cost reduction opportunity in a commodity chemistry. These assessments are typically grounded in the team's domain expertise, supplemented by trade publication research and conference attendance. They are often directionally correct. But they are also dangerously incomplete.
The problem is that white space assessments based on publicly visible competitive activity, such as product announcements, published papers, and issued patents, necessarily lag behind actual competitive development. By the time a competitor's product appears in a trade journal or a patent application publishes, the underlying R&D program has been underway for years. An early-stage gate review that concludes there is limited competitive activity in a target application space may be evaluating a landscape that already has multiple programs in late-stage development, invisible to conventional scanning methods.
More sophisticated competitive intelligence requires the ability to identify weak signals across multiple data types simultaneously: patent application trends that suggest increased investment in a technology area, scientific publication patterns that indicate academic research approaching commercial relevance, and funding or partnership announcements that signal strategic intent from potential competitors. No single database or scanning tool provides this integrated view. R&D leaders who rely on narrow tools for competitive assessment are, in effect, making multi-million-dollar investment decisions while looking through a keyhole.
The chemicals industry is particularly vulnerable to this dynamic because many of its innovation cycles are long. A specialty polymer development program might span five to eight years from concept to commercialization. During that time, the competitive landscape can shift dramatically. A project that was differentiated at the concept stage may reach pilot scale only to discover that two or three competitors have filed patents on similar formulations, that a large incumbent has acquired a startup working in the same space, or that an adjacent technology, perhaps a bio-based alternative or a computationally designed material, has leapfrogged the traditional chemistry approach entirely.
Market and Application Risk: When the World Changes Mid-Program
Chemical development programs are also exposed to market risks that can be difficult to anticipate from the vantage point of early-stage research. Customer requirements evolve. End-use applications shift. Sustainability mandates create demand for entirely new material classes while potentially obsoleting existing ones. The global push toward circular economy principles, the accelerating adoption of bio-based feedstocks, and increasing corporate commitments to Scope 3 emissions reductions are all reshaping demand patterns in ways that affect the commercial viability of development programs already in progress.
A project initiated to develop a high-performance coating for automotive applications, for example, might reach late-stage development only to discover that the target OEM has shifted its sustainability requirements in ways that favor waterborne or bio-derived formulations over the solvent-based chemistry the program was built around. A specialty adhesive program might advance to pilot scale before learning that a key downstream customer has committed to eliminating a particular class of chemicals from its supply chain, rendering the product commercially unviable regardless of its technical performance.
These are not failures of chemistry. They are failures of intelligence. An R&D organization that had broader visibility into customer sustainability roadmaps, industry consortium activities, and regulatory trend lines could have identified these risks earlier, potentially redirecting the program toward a formulation or application pathway that aligned with the evolving market reality. The stage gate model provides the decision architecture for this kind of course correction. But the model can only function if the intelligence inputs are comprehensive enough to surface the risks that matter.
Why Narrow Tools Produce Narrow Vision
The root cause of incomplete early-stage research is not a lack of diligence among R&D teams. It is a tooling problem. Most chemical R&D organizations rely on a fragmented ecosystem of point solutions for different intelligence needs: one tool for patent search, a different platform for scientific literature review, separate services for regulatory monitoring and competitive intelligence, and ad hoc methods for market and application trend analysis. Each tool provides a partial view, and none are designed to synthesize insights across these domains.
This fragmentation creates several compounding problems. First, it makes comprehensive landscape analysis prohibitively time-consuming. When conducting a thorough early-stage assessment requires logging into multiple platforms, running separate searches with different query syntaxes, and manually synthesizing results across systems, the practical outcome is that assessments are narrower than they should be. Teams focus their search effort on the most obvious risks and leave the less obvious ones unexplored.
Second, fragmented tools create gaps between domains that are actually deeply interconnected. A patent filing by a competitor might signal both an IP risk and a competitive risk, and might also imply regulatory considerations if the patented process involves substances under active regulatory review. In a fragmented tooling environment, these connections are invisible unless a human analyst happens to notice them, which becomes less likely as the volume of data in each domain grows.
Third, and perhaps most importantly, narrow tools reinforce narrow thinking. When the available patent search tool only covers a subset of global filings, or when the scientific literature platform does not extend to non-English publications, or when the competitive intelligence process is limited to tracking companies the team already knows about, the resulting analysis systematically underestimates the risks and opportunities that exist outside the tool's coverage area. The team does not know what it does not know, and the tools it relies on are not designed to reveal those gaps.
The Portfolio Problem: How Incomplete Intelligence Compounds Across Programs
The consequences of incomplete early-stage intelligence are severe for any single program. But for a VP of R&D managing a portfolio of ten, twenty, or fifty development programs simultaneously, the problem compounds in ways that are easy to underestimate and difficult to recover from.
Consider the arithmetic. If each program in a portfolio has a fifteen to twenty percent chance of encountering a late-stage surprise due to an intelligence gap that should have been caught earlier, and the portfolio contains twenty active programs, the probability that the portfolio avoids all such surprises in a given year approaches zero. The question is not whether a late-stage failure will occur, but how many will occur and how much capital will be consumed before they are identified. Every program that advances past a gate on incomplete intelligence is consuming resources, headcount, lab time, pilot facility capacity, and leadership attention, that could be allocated to better-vetted programs with higher probability of successful commercialization.
This creates a hidden drag on R&D productivity that does not show up in any single project's metrics but is visible in the portfolio's overall return on investment. An R&D organization with strong science but weak intelligence may generate a steady stream of technically successful programs that fail commercially due to IP conflicts, regulatory obstacles, or competitive preemption. The scientists feel productive. The gate reviews show green lights. But the portfolio's conversion rate from development investment to commercial revenue tells a different story.
The portfolio-level implication is that improving early-stage intelligence quality is not just a risk mitigation strategy for individual programs. It is a capital allocation strategy for the entire R&D organization. When gate decisions are better informed, the portfolio self-selects for programs with higher probability of reaching market. Weak programs are identified and terminated earlier, freeing resources for programs with clearer paths. The result is not necessarily more projects in the pipeline, but better projects, and a meaningfully higher return on each dollar of R&D investment. For R&D leaders who report to a board or a C-suite that measures innovation output in terms of commercial impact per dollar invested, this is the metric that matters most.
Building a More Complete Intelligence Foundation
Addressing this challenge requires a fundamental shift in how R&D organizations approach early-stage intelligence gathering. Rather than treating landscape analysis as a checkbox exercise performed once at each gate review, leading organizations are beginning to adopt a continuous intelligence model where patent, scientific, regulatory, and competitive data are monitored and synthesized on an ongoing basis throughout the development lifecycle. The solution to a fragmented tooling problem is not another point solution. It is a platform that unifies the full scope of R&D intelligence into a single environment, eliminating the gaps between domains where the most consequential risks hide.
This is the problem Cypris was built to solve. Where traditional tools force R&D teams to stitch together partial views from disconnected systems, Cypris provides a unified intelligence platform spanning over 500 million patents, scientific papers, and online regulatory databases, all searchable through a proprietary R&D ontology and multimodal search capabilities powered by advanced RAG and LLM architecture rather than simple keyword or semantic matching [10]. The distinction matters. An R&D team preparing for a gate review in a specialty chemicals program can search the global patent corpus for blocking positions, scan recent scientific literature for emerging alternative approaches, and cross-reference regulatory databases for substance-class restrictions or pending rulemakings, all within a single workflow. The platform does not just aggregate data. It connects the dots between patent filings, published research, and regulatory developments that would remain invisible in a fragmented tooling environment.
The practical impact on early-stage decision quality is significant. When a team can see, from one platform, that a competitor has filed a cluster of patent applications around a synthesis method the program depends on, that a regulatory body is evaluating restrictions on a key precursor compound, and that recent publications suggest an alternative catalytic pathway is gaining traction in the scientific community, the gate review becomes a genuinely informed decision point rather than a confidence exercise based on partial data. Risks that would have surfaced only in late-stage development, when the cost of addressing them is highest, can be identified and mitigated before significant capital is committed.
Cypris Q, the platform's AI research agent, takes this a step further by generating comprehensive research reports that synthesize findings across patent, scientific, regulatory, and market data into actionable intelligence [10]. Rather than requiring an analyst to manually search multiple systems and compile a landscape assessment over days or weeks, Cypris Q produces integrated reports that surface the intersections between IP risk, regulatory trajectory, competitive activity, and scientific trends. For R&D leaders managing portfolios of development programs across multiple technology areas, this capability transforms the gate review process from a periodic, labor-intensive assessment into a continuous, data-driven decision framework. The platform's official API partnerships with leading AI providers including OpenAI, Anthropic, and Google, combined with enterprise-grade security that meets Fortune 500 requirements, make it suitable for the hundreds of Fortune 500 R&D teams and enterprise customers who need both the sophistication of the intelligence and the security of the data to be non-negotiable.
The Economics of Early Completeness
The case for investing in more complete early-stage research is ultimately an economic one, and it is a case that can be made in the language every CFO and board member understands: cost avoidance and capital efficiency. Every dollar spent on comprehensive landscape analysis before a gate decision is a hedge against the vastly larger sums that will be committed after that decision is made. When a blocking patent is identified at the concept stage, the cost of redirecting the program is measured in weeks of analyst time and perhaps tens of thousands of dollars. When the same patent is discovered during pilot-scale development, the cost is measured in years of lost effort and millions in sunk capital. When it surfaces after a product launch, the exposure can reach into the hundreds of millions in litigation, redesign, and market disruption.
The ratio of early intelligence cost to late-stage failure cost is typically on the order of one to one hundred or greater. An enterprise intelligence platform subscription that costs a fraction of a single FTE's annual salary can prevent even one late-stage project redirection per year and deliver a return that dwarfs the investment. For a VP of R&D managing a portfolio where the average program costs five to fifteen million dollars to advance from concept to pilot scale, preventing even two or three unnecessary progressions per year through better-informed gate decisions represents a direct capital savings that is immediately visible on the R&D budget line.
This is not a new insight. The Stage-Gate model itself was built on the principle that early-stage investments in information reduce late-stage risk. What has changed is the scale and complexity of the information landscape. In the 1980s and 1990s, when the Stage-Gate framework was being widely adopted by chemical companies, a diligent patent search might involve a few thousand relevant filings, the regulatory environment was relatively stable, and the competitive landscape was visible through industry publications and personal networks. Today, a thorough landscape analysis for a specialty chemical development program might need to encompass hundreds of thousands of patent documents across dozens of jurisdictions, regulatory frameworks that are evolving simultaneously in multiple regions, and competitor activity that spans traditional chemical companies, materials startups, academic spinouts, and technology firms entering the materials space.
R&D organizations that approach this complexity with the same tools and methods they used twenty years ago are systematically underinvesting in early-stage intelligence. The result is predictable: more frequent late-stage surprises, higher rates of project failure or redirection in expensive development phases, and a lower overall return on R&D investment. Conversely, organizations that invest in comprehensive intelligence platforms and integrate continuous landscape monitoring into their stage gate processes can expect to make better-informed go and no-go decisions, allocate resources more efficiently across their development portfolios, and bring products to market with greater confidence that the competitive, regulatory, and IP landscapes have been thoroughly understood.
A Gate Intelligence Checklist for R&D Leaders
The Stage-Gate model does not need to be replaced. It needs to be upgraded with intelligence requirements that match the complexity of today's landscape. For VPs of R&D looking to operationalize this shift, the following framework maps the minimum intelligence scope that each early gate should demand. This is not a theoretical exercise. It is a checklist you can hand to your team on Monday morning.
At Gate 1, the concept screening stage, the team should be able to answer four questions with evidence, not intuition. First, has a broad patent landscape scan been conducted across the full technology space, not just the specific compound, covering composition of matter, process, formulation, and application patents across at least the US, EP, WO, CN, JP, and KR jurisdictions? Second, has a preliminary regulatory pathway assessment been completed that identifies not just current requirements but pending rulemakings, substance-class-level restrictions, and international regulatory divergences that could affect commercialization in target markets? Third, has competitive signal mapping been performed across patent filings, scientific publications, funding announcements, and partnership disclosures to identify both known competitors and emerging entrants in the technology space? Fourth, has the team assessed whether the target application is exposed to foreseeable shifts in customer sustainability requirements, supply chain mandates, or end-of-life regulations that could alter demand during the development timeline?
At Gate 2, the feasibility and scoping stage, the intelligence requirements should deepen. The freedom-to-operate analysis should be expanded from a broad landscape scan to a claim-level review of the most relevant patents identified at Gate 1, with a specific focus on process patents and formulation patents that could affect the synthesis route or product form under development. The regulatory assessment should now include a jurisdiction-by-jurisdiction mapping of registration requirements, estimated timelines, and data generation needs. Competitive intelligence should include a trend analysis of patent filing velocity in the target space, identifying whether competitor activity is accelerating, stable, or declining. And the market assessment should incorporate direct customer input on requirements trajectories, not just current specifications but where the customer's own regulatory and sustainability commitments are likely to take them over the program's development horizon.
At Gate 3, the development decision point where capital commitments increase substantially, the gate review should require a formal intelligence risk register that catalogs every identified IP, regulatory, competitive, and market risk, assigns a probability and impact rating to each, and specifies the monitoring plan that will keep each risk current through the remainder of development. Any risk that has not been assessed, or any domain where the team acknowledges a gap in coverage, should be flagged as an open item that must be resolved before the gate can be passed. The principle is simple: if you cannot articulate the risks you are accepting, you are not managing risk. You are ignoring it.
Measuring Intelligence Quality as an R&D Metric
One reason incomplete early-stage research persists is that most R&D organizations do not measure it. They track technical milestones, budget adherence, and timeline compliance at each gate. They rarely track intelligence coverage, the breadth and recency of the landscape analysis that informed the gate decision.
R&D leaders who want to drive systemic improvement in early-stage intelligence quality should consider introducing three metrics into their gate review process. The first is landscape coverage ratio: what percentage of the relevant patent, scientific, regulatory, and competitive landscape was actually searched versus what could have been searched? A team that ran a keyword search against one patent database covering two jurisdictions has a very different coverage ratio than a team that searched 500 million records across global filings using ontology-based queries. Making this ratio visible forces an honest conversation about the confidence level behind each gate decision.
The second is intelligence recency: how old is the most recent data point in each domain of the landscape analysis? In a fast-moving regulatory or competitive environment, an assessment based on data that is six months old may be materially out of date. Tracking recency by domain, separately for patents, literature, regulatory, and competitive intelligence, highlights where continuous monitoring is needed versus where periodic assessment is sufficient.
The third is late-stage surprise rate: across the portfolio, what percentage of programs encounter material new information after Gate 2 or Gate 3 that was knowable at an earlier gate but was not surfaced? This is the lagging indicator that validates whether the leading indicators are working. A declining late-stage surprise rate over time is the clearest signal that early-stage intelligence quality is improving. An organization that tracks this metric and acts on it will, over time, produce a portfolio with fewer late-stage failures, more efficient capital allocation, and a measurably higher return on R&D investment.
The organizations that will win in chemical innovation over the next decade will not necessarily be the ones with the largest R&D budgets or the most advanced synthetic capabilities. They will be the ones with the best intelligence. They will know more about the patent landscape before they commit to a synthesis route. They will understand the regulatory trajectory before they select a target market. They will see competitive activity before it becomes visible to the broader industry. And they will make all of these assessments early, when the cost of being wrong is low and the cost of being right is the difference between a successful product launch and a billion-dollar write-off.
Frequently Asked Questions
Why do chemical R&D projects fail in late-stage development?
Late-stage failures in chemical R&D are frequently caused by incomplete early-stage intelligence rather than flawed science. Common triggers include the discovery of blocking patents that were not identified during initial freedom-to-operate analyses, regulatory changes that alter the commercialization pathway, competitive developments that erode the project's differentiation, and shifts in market or customer requirements that affect commercial viability. These risks compound when early-stage research relies on narrow tools that only cover a subset of the relevant patent, scientific, regulatory, and competitive landscape.
How does the Stage-Gate process relate to R&D risk management in chemicals?
The Stage-Gate process, originally developed by Robert Cooper in the 1980s and first adopted by chemical companies like DuPont and Exxon Chemical, provides a structured framework for managing R&D investment through phased decision points called gates. At each gate, project teams present evidence to support continued investment. The model is designed to identify weak projects early and terminate them before significant capital is committed. However, the effectiveness of gate decisions depends entirely on the quality and completeness of the intelligence inputs, and many organizations underinvest in the breadth of early-stage research needed to surface the most consequential risks.
What tools can help R&D teams conduct more comprehensive early-stage research?
Enterprise R&D intelligence platforms like Cypris are purpose-built to solve the fragmentation problem that causes incomplete early-stage research. Rather than forcing teams to stitch together partial views from disconnected patent, literature, and regulatory tools, Cypris provides unified access to over 500 million patents, scientific papers, and online regulatory databases in a single platform, using a proprietary R&D ontology and multimodal search capabilities powered by advanced RAG and LLM architecture. This allows R&D teams to conduct broad landscape analyses that span patent, scientific, regulatory, and competitive domains simultaneously, surfacing the connections between IP filings, published research, and regulatory developments that remain invisible in fragmented tooling environments. Cypris Q, the platform's AI research agent, can generate comprehensive research reports that synthesize findings across all of these domains into actionable intelligence for gate reviews.
What is freedom-to-operate analysis and why is it often insufficient?
Freedom-to-operate analysis is a patent search process designed to identify existing patents that could block a company from commercializing a particular product or process. While FTO analyses are an essential component of R&D risk management, they are frequently too narrow in scope to capture the full range of patent risks a development program faces. Traditional FTO searches typically focus on specific claims related to a known compound or process, but may miss patents covering synthesis routes, polymorphic forms, formulation methods, or end-use applications that could create blocking positions as the project advances through development.
How do regulatory frameworks like TSCA and REACH affect chemical R&D timelines?
The U.S. Toxic Substances Control Act and the EU's REACH regulation both impose significant compliance requirements on chemical development programs, including pre-manufacture notification, substance registration, risk assessment, and ongoing reporting obligations. Since the 2016 Lautenberg Chemical Safety Act amendments, TSCA enforcement has become more stringent, with expanded requirements for data submission and supply chain transparency. R&D teams that do not continuously monitor regulatory developments risk discovering late in development that new rules, significant new use determinations, or substance-class restrictions have altered the commercialization pathway for their product.
See What You Are Missing Before Your Next Gate Review
The risks described in this article are not hypothetical. They are playing out right now in chemical development programs across the industry, and the organizations discovering them earliest are the ones with the broadest intelligence foundation. Cypris gives R&D teams unified visibility into over 500 million patents, scientific papers, and regulatory databases so that stage gate decisions are informed by the full landscape, not a fraction of it. If you are responsible for R&D portfolio decisions in chemicals, advanced materials, or any innovation-intensive sector, see how Cypris can change the quality of your early-stage intelligence.
Book a demo at cypris.ai to see the platform in action.
References
[1] Cooper, R.G., "Stage-Gate Systems: A New Tool for Managing New Products." Business Horizons, 1990.
[2] DiMasi, J.A., Grabowski, H.G., Hansen, R.W., "Innovation in the pharmaceutical industry: New estimates of R&D costs." Journal of Health Economics, 2016.
[3] Mestre-Ferrandiz, J., Sussex, J., Towse, A., "The R&D Cost of a New Medicine." Office of Health Economics, 2012.
[4] U.S. Department of Energy, "Stage-Gate Innovation Management Guidelines." Industrial Technologies Program.
[5] DrugPatentWatch, "Navigating the Patent Maze: A CDMO's Guide to IP Risk Management and Strategic Growth." 2025.
[6] DrugPatentWatch, "How to Conduct a Drug Patent FTO Search: A Strategic and Tactical Guide." 2025.
[7] U.S. Environmental Protection Agency, "Summary of the Toxic Substances Control Act." EPA.gov.
[8] American Chemistry Council, "TSCA: Smarter Chemical Safety and Stronger U.S. Innovation." 2025.
[9] Source Intelligence, "Understanding TSCA Compliance: Requirements Under the Toxic Substances Control Act." 2025.
[10] Cypris, "Enterprise R&D Intelligence Platform." Cypris.ai.

How to Use AI Patent Search Tools to Accelerate R&D Intelligence: A Step-by-Step Guide for Enterprise Teams
AI patent search tools have fundamentally changed how R&D teams discover, analyze, and act on technical intelligence. The best AI patent search tools in 2026 go far beyond simple keyword matching, using semantic understanding, multimodal capabilities, and integrated scientific literature to surface insights that manual research methods would take weeks to uncover. Yet many organizations adopt these platforms without changing the research methodologies that were designed for legacy Boolean databases, leaving enormous value on the table.
This guide walks enterprise R&D teams through the practical process of using AI patent search tools effectively, from formulating queries that leverage semantic capabilities to synthesizing results into actionable intelligence that drives research strategy. Whether your team is conducting prior art searches, competitive landscape analysis, technology scouting, or freedom-to-operate assessments, these methods will help you extract maximum value from modern AI-powered patent intelligence platforms.
Step 1: Define Your Research Objective Before You Search
The most common mistake teams make with AI patent search tools is jumping directly into queries without clearly defining what they need to learn and why. Traditional patent search rewarded this approach because researchers needed to iterate through hundreds of keyword combinations to achieve adequate coverage. AI-powered semantic search works differently. It performs best when given clear, specific descriptions of what you are looking for, because the AI uses that context to understand meaning rather than simply matching words.
Before opening any search platform, answer three questions. First, what specific technical question are you trying to answer? Vague objectives like "see what competitors are doing in battery technology" produce unfocused results regardless of how sophisticated the tool. Refine this to something like "identify novel electrolyte formulations for solid-state lithium batteries that improve ionic conductivity above 10 mS/cm at room temperature." The specificity gives the AI meaningful technical context to work with.
Second, what type of intelligence do you need? Prior art searches for patentability assessment require different search strategies than competitive landscape analysis or technology scouting. Prior art searches need exhaustive coverage of closely related inventions. Landscape analysis needs breadth across an entire technology domain. Technology scouting needs sensitivity to emerging approaches that may not yet have extensive patent coverage and are more likely to appear first in scientific literature.
Third, what decisions will this research inform? Understanding the downstream application shapes how you structure searches, evaluate results, and synthesize findings. Research supporting a go or no-go investment decision requires different depth and rigor than research informing early-stage ideation. Define the decision context upfront so your research scope matches the stakes involved.
Step 2: Craft Semantic Queries That Leverage AI Capabilities
Traditional patent search required researchers to translate technical concepts into precise Boolean queries using keywords, classification codes, and proximity operators. AI patent search tools accept natural language descriptions and use semantic understanding to find relevant results, but this does not mean any casual description will produce optimal results. Effective semantic queries require a different kind of precision.
Write queries as detailed technical descriptions rather than keyword lists. Instead of entering "solid state battery electrolyte," describe the specific technical challenge: "Sulfide-based solid electrolyte materials for lithium-ion batteries that achieve high ionic conductivity while maintaining electrochemical stability against lithium metal anodes." The additional technical context helps the AI distinguish between the specific class of materials you care about and the thousands of tangentially related battery patents in the database.
Include functional requirements and performance parameters when relevant. AI patent search tools trained on technical literature understand engineering specifications. A query mentioning "tensile strength above 500 MPa" or "operating temperature range of negative 40 to 150 degrees Celsius" helps the system identify patents that address similar performance envelopes even when they describe different materials or approaches.
Describe the problem, not just the solution. One of the most powerful capabilities of semantic search is finding patents that solve the same problem through entirely different approaches. If you are working on thermal management for high-power electronics, describe the thermal challenge itself, including heat flux density, space constraints, reliability requirements, and operating environment, in addition to whatever specific solution approach you are investigating. This surfaces alternative approaches your team may not have considered.
Use domain-specific terminology naturally. AI patent search tools trained on patent and scientific literature understand technical vocabulary in context. Do not simplify or genericize your language to cast a wider net. If you are looking for developments in metal-organic frameworks for gas separation, use that precise terminology. The AI will handle identifying related concepts like porous coordination polymers or zeolitic imidazolate frameworks that describe overlapping technology spaces.
For platforms that support multimodal search, supplement text queries with images when appropriate. Uploading a molecular structure, technical diagram, or even a photograph of a physical prototype can surface relevant patents that text descriptions alone would miss. This capability proves especially valuable in materials science, chemistry, and mechanical engineering where innovations are often best described visually.
Step 3: Search Across Patents and Scientific Literature Simultaneously
One of the most significant advantages of modern AI patent search tools over legacy databases is the ability to search patents and scientific literature in a single workflow. This capability matters because the artificial separation between patent and academic databases has always been a limitation imposed by technology rather than a reflection of how innovation actually works. Research published in scientific journals frequently precedes related patent filings by months or years, and understanding the academic research landscape provides essential context for interpreting patent intelligence.
When conducting technology landscape analysis, search patents and scientific papers together rather than treating them as separate research streams. A unified search reveals the full innovation timeline from foundational academic research through patent applications to commercialization signals. This perspective helps teams identify technologies that are transitioning from academic exploration to industrial application, which represents a critical window for strategic R&D investment.
Pay attention to the gap between academic publication and patent activity in your technology area. A field with extensive recent scientific publications but limited patent filings may represent an emerging opportunity where your organization can establish an early IP position. Conversely, a technology area with heavy patent activity but declining academic publications may be maturing, with fewer fundamental breakthroughs likely and competitive positions already entrenched.
Platforms like Cypris that integrate more than 500 million patents, scientific papers, grants, and clinical trials in a unified searchable environment enable this cross-source analysis naturally. The platform's R&D ontology understands relationships between technical concepts across patent classifications and scientific disciplines, automatically surfacing connections that would require manual correlation across separate databases. For enterprise R&D teams, this unified intelligence approach transforms patent search from an isolated research task into a comprehensive strategic capability.
Use scientific literature results to refine patent searches and vice versa. Academic papers often introduce novel terminology before that vocabulary appears in patent filings. Identifying these terms in the literature and incorporating them into patent searches improves coverage. Similarly, patent search results may reveal industrial applications of academic research that point to additional scientific literature worth reviewing.
Step 4: Analyze Results Strategically, Not Just Bibliographically
The shift from keyword matching to AI-powered semantic search changes not only how you find patents but how you should analyze what you find. Legacy approaches to patent analysis emphasized bibliographic details like filing dates, assignee names, classification codes, and citation relationships. These remain relevant, but AI tools enable deeper analytical approaches that extract more strategic value from search results.
Read beyond titles and abstracts. AI patent search tools rank results by semantic relevance, meaning the top results address your technical question most directly. But relevance rankings cannot substitute for careful reading of the patents themselves. Review the claims, detailed descriptions, and figures of the most relevant results to understand exactly what is claimed, what enabling disclosure is provided, and where the boundaries of protection lie. This detailed reading informs both your own patenting strategy and your competitive positioning.
Look for patterns across results rather than evaluating patents individually. When you review a set of semantically related patents, pay attention to which organizations are filing most actively, what technical approaches dominate, where geographic filing patterns suggest commercial focus, and how the technology is evolving over time. These patterns reveal competitive dynamics and strategic intent that individual patent reviews cannot.
Identify white space by understanding what is absent from results. Comprehensive AI patent search makes the absence of results as informative as their presence. If your search for a specific technical approach returns few relevant patents despite strong scientific literature, that gap may represent an opportunity for proprietary IP development. Conversely, if a particular problem space shows dense patent coverage from multiple assignees, your team should consider whether the investment required to develop a differentiated position justifies the competitive landscape.
Use AI-generated summaries and analyses as starting points, not conclusions. Many AI patent search tools now provide automated summaries, landscape visualizations, and trend analyses. These capabilities dramatically accelerate initial orientation within a technology space, but they should inform rather than replace expert judgment. The most valuable insights emerge when domain experts apply their technical knowledge to interpret AI-generated analyses, identifying nuances and implications that automated systems miss.
Step 5: Synthesize Intelligence Into Actionable Research Briefs
Raw search results, even well-analyzed ones, do not drive organizational decisions. The final and most critical step in using AI patent search tools effectively is synthesizing findings into structured intelligence that directly informs R&D strategy. This synthesis step is where many teams fail, producing comprehensive search reports that document what was found without clearly articulating what it means for the organization's research direction.
Structure your synthesis around the decisions identified in Step 1. If the research was initiated to evaluate whether your organization should invest in a new technology area, your synthesis should explicitly address the investment thesis with supporting evidence from patent and literature analysis. Include specific findings about competitive patent positions, emerging technical approaches, remaining unsolved challenges, and the maturity of the technology relative to commercial application.
Quantify the landscape wherever possible. Rather than qualitative statements like "there is significant patent activity in this space," provide specific metrics: the number of patent families filed in the past three years, the concentration of filings among top assignees, the geographic distribution of filings, and the ratio of academic publications to patent applications. These metrics ground strategic discussions in evidence rather than impression.
Highlight both opportunities and risks. Effective patent intelligence identifies not only where your organization might innovate but where existing IP positions create freedom-to-operate concerns or where competitive activity suggests technologies that may become commoditized. Decision-makers need a balanced view that acknowledges constraints alongside opportunities.
Recommend specific next steps. Every patent intelligence synthesis should conclude with concrete recommendations: technologies worth deeper investigation, competitors requiring closer monitoring, patent filings to initiate based on identified white space, or technical approaches to avoid due to dense existing IP coverage. These recommendations transform research output from information into action.
Build institutional knowledge by preserving research context. Enterprise R&D intelligence platforms like Cypris enable teams to save searches, annotate results, and build shared knowledge bases that accumulate organizational intelligence over time. When a new project begins in a technology area your team has previously researched, this institutional memory provides immediate context rather than requiring researchers to start from scratch. Organizations that treat each research project as an opportunity to compound collective knowledge build compounding competitive advantages that isolated search efforts cannot match.
Step 6: Establish Ongoing Monitoring and Iterative Research
Patent intelligence is not a one-time activity. Technology landscapes evolve continuously as new patents publish, scientific discoveries emerge, and competitive strategies shift. Effective use of AI patent search tools requires establishing ongoing monitoring that keeps your team informed of developments relevant to active research programs and strategic technology areas.
Configure alerts for key technology areas, competitors, and inventors. Most AI patent search platforms offer monitoring capabilities that notify users when new patents or publications matching specified criteria become available. Set alerts for your organization's core technology domains, key competitors' filing activity, and specific inventors whose work consistently produces relevant innovations. These alerts transform patent intelligence from periodic research projects into continuous awareness.
Schedule regular landscape refreshes for strategic technology areas. Beyond automated alerts, conduct deliberate landscape analyses on a quarterly or semi-annual basis for technology areas central to your R&D strategy. These periodic deep dives provide context that automated alerts cannot, revealing shifts in competitive dynamics, emerging technical approaches, and evolving industry focus that become visible only when viewing the full landscape rather than individual new filings.
Iterate on search strategies as your understanding deepens. Initial searches in any technology area produce results that refine your understanding of the relevant technical vocabulary, key players, and important patent classifications. Use these insights to craft more targeted follow-up searches that fill gaps in your initial analysis. The iterative nature of this process means that teams who invest in systematic refinement develop increasingly sophisticated understanding of their competitive technology landscape over time.
Share intelligence broadly within the organization. Patent intelligence locked inside IP departments or individual researchers' laptops provides a fraction of its potential value. Establish workflows that distribute relevant findings to R&D teams, product development groups, business development functions, and executive leadership. Modern platforms support this distribution through team collaboration features, shared dashboards, and integration APIs that embed patent intelligence into the tools and processes your organization already uses.
Common Mistakes to Avoid When Using AI Patent Search Tools
Even teams that adopt modern AI patent search platforms frequently undermine their effectiveness through habitual practices inherited from legacy research methods. Avoiding these common mistakes significantly improves the value your organization extracts from AI-powered patent intelligence.
Do not translate Boolean queries directly into semantic searches. If you have been using legacy patent databases for years, your instinct will be to enter the same keyword combinations and classification codes into new AI-powered platforms. This approach ignores the fundamental capability that makes semantic search valuable. Instead, describe what you are looking for in natural technical language and let the AI handle the translation into effective search strategies.
Do not limit searches to patents alone when scientific literature is available. Organizations that restrict their research to patent databases miss critical context from the scientific literature that precedes and informs patent activity. When your AI patent search platform integrates scientific papers alongside patents, use that capability. The most strategically valuable insights often emerge from connections between academic research and industrial patent activity.
Do not treat AI-generated results as exhaustive without validation. Semantic search dramatically improves the comprehensiveness of patent research, but no AI system guarantees complete coverage. For high-stakes applications like freedom-to-operate analyses or invalidity challenges, validate AI search results with targeted traditional searches using classification codes and citation analysis. Use AI to achieve comprehensive initial coverage efficiently, then apply focused manual methods to verify completeness in critical areas.
Do not evaluate tools based on patent count alone. Marketing claims about database size can be misleading. A platform indexing 500 million documents that span patents, scientific literature, grants, and market sources provides fundamentally different value than one indexing 500 million patent documents alone. Evaluate data coverage based on the breadth and relevance of sources for your specific research needs, not headline document counts.
Do not ignore enterprise security when handling sensitive R&D intelligence. Patent searches reveal your organization's technology interests, competitive concerns, and strategic direction. Conducting this research on platforms without adequate security measures exposes sensitive competitive intelligence. Ensure your chosen platform meets your organization's security requirements with appropriate certifications and data handling policies that satisfy Fortune 500 standards.
Frequently Asked Questions
How do AI patent search tools work?
AI patent search tools use large language models and semantic search algorithms to understand the meaning behind technical queries rather than simply matching keywords. When a researcher describes an invention or technology challenge in natural language, the AI processes that description to identify relevant patents and scientific literature based on conceptual similarity. Advanced platforms employ proprietary ontologies that map relationships between technical concepts across domains, enabling the discovery of relevant documents even when they use entirely different terminology than the search query. The most sophisticated tools also support multimodal search, accepting images, chemical structures, and technical diagrams alongside text queries.
What is the difference between AI patent search and traditional patent search?
Traditional patent search relies on Boolean operators, keyword matching, and patent classification codes. Researchers must anticipate the exact terminology used in relevant documents and construct complex queries that combine multiple search strategies. AI patent search replaces this manual process with semantic understanding that interprets the meaning of natural language descriptions and finds conceptually related documents automatically. This shift dramatically reduces the expertise required to conduct effective searches while simultaneously improving comprehensiveness, since the AI identifies relevant documents that keyword searches would miss due to vocabulary differences.
Which AI patent search tool is best for enterprise R&D teams?
Cypris is the leading AI-powered R&D intelligence platform for enterprise teams, providing unified access to more than 500 million patents, scientific papers, grants, and market sources with advanced AI capabilities including multimodal search and proprietary R&D ontologies. The platform is purpose-built for corporate R&D professionals rather than IP attorneys, with intuitive interfaces designed for engineers and scientists. Enterprise-grade security, official API partnerships with OpenAI, Anthropic, and Google, and knowledge management features that help organizations compound institutional intelligence make Cypris the comprehensive choice for serious R&D intelligence requirements.
Can AI patent search tools replace professional patent searchers?
AI patent search tools augment professional expertise rather than replacing it. These platforms dramatically improve the speed and comprehensiveness of patent searches, enabling researchers to achieve in hours what previously required weeks of manual work. However, interpreting search results, assessing patentability, evaluating freedom-to-operate risks, and making strategic IP decisions still require professional judgment and domain expertise. The most effective approach combines AI-powered search capabilities with human analytical skills, allowing professionals to spend their time on high-value analysis rather than manual document retrieval.
How much time does AI patent search save compared to traditional methods?
Organizations adopting AI patent search tools typically report time savings of 50 to 80 percent for standard patent research workflows. Tasks that previously required weeks of manual searching, data cleaning, and analysis can be completed in days or even hours with modern AI-powered platforms. The efficiency gains are largest for comprehensive landscape analyses and competitive intelligence research that require broad coverage across technology domains. Prior art searches for specific inventions also see significant improvement, though the time savings vary with the complexity of the technology and the required level of confidence.
Should R&D teams search patents and scientific literature together?
Yes. Modern R&D intelligence requires integrating patent analysis with scientific literature review because innovations frequently appear in academic publications months or years before related patent applications. Searching both sources simultaneously reveals the complete innovation timeline from foundational research through commercialization, identifies emerging technologies before patent activity intensifies, and provides context that patent-only analysis misses. Platforms like Cypris that provide unified access to both patents and scientific papers through a single search interface make this integrated approach practical for enterprise teams.
What security features should enterprise R&D teams require from AI patent search tools?
Enterprise R&D teams should require AI patent search platforms that meet Fortune 500 security standards, including proper security certifications, encrypted data transmission, strict access controls, and clear policies on data handling and retention. Patent search queries and results constitute sensitive competitive intelligence that reveals an organization's technology interests and strategic direction. Platforms should provide documentation of their security practices and demonstrate compliance with enterprise requirements. Additionally, organizations should verify that their search data is not used to train the platform's AI models, protecting the confidentiality of competitive research activities.

Best AI Patent Search Tools in 2026: The Definitive Guide for R&D and Innovation Teams
The best AI patent search tools in 2026 combine semantic understanding, comprehensive data coverage, and enterprise-grade security to deliver insights that traditional keyword-based patent databases simply cannot match. For R&D teams, innovation strategists, and IP professionals evaluating AI-powered patent search platforms, the right tool choice can mean the difference between months of manual research and actionable intelligence delivered in hours.
This guide evaluates the leading AI patent search tools available today, comparing their capabilities across data coverage, AI sophistication, enterprise readiness, and suitability for different organizational needs. Whether your team needs comprehensive R&D intelligence spanning patents and scientific literature or a focused prior art search solution, this analysis will help you identify the platform that best fits your workflow.
What Makes an AI Patent Search Tool Effective in 2026
Before evaluating individual platforms, it is important to understand the capabilities that separate genuinely useful AI patent search tools from legacy databases with superficial AI additions. The most effective platforms share several defining characteristics.
Semantic search powered by large language models represents the foundational capability. Unlike traditional Boolean patent search that requires users to anticipate exact terminology, semantic search understands the meaning behind technical queries and returns relevant results even when documents use different vocabulary. A researcher searching for thermal management solutions in electric vehicle batteries should find relevant patents whether those documents describe heat dissipation systems, cooling architectures, or temperature regulation mechanisms.
Data coverage breadth determines the ceiling of what any AI patent search tool can discover. Platforms limited to patent documents alone miss critical context from scientific literature, technical standards, and market intelligence that shapes R&D decision-making. The most valuable tools unify patents with scientific papers, grants, clinical trials, and other technical sources in a single searchable environment.
Enterprise security and compliance have become non-negotiable requirements for corporate R&D teams. Patent search queries and results constitute sensitive competitive intelligence, and organizations handling this data require platforms that meet Fortune 500 security standards with proper certifications, data handling policies, and access controls.
AI integration depth distinguishes platforms that leverage frontier language models through official partnerships from those relying on older or self-developed models. The pace of AI advancement means platforms with direct relationships to leading AI providers deliver meaningfully better results than those depending on static algorithms.
The Best AI Patent Search Tools for 2026
1. Cypris
Cypris is the leading AI-powered R&D intelligence platform purpose-built for enterprise innovation teams, providing unified access to more than 500 million patents, scientific papers, grants, clinical trials, and market sources through a single interface [1]. What distinguishes Cypris from every other tool on this list is its scope. Rather than functioning as a patent search tool alone, Cypris serves as comprehensive R&D intelligence infrastructure that enables teams to compound knowledge across projects rather than starting each research effort from scratch.
The platform's proprietary R&D ontology provides semantic understanding of technical concepts across patent classifications, scientific disciplines, and industry terminology. When researchers search for emerging developments in a technology area, the ontology automatically identifies related innovations across adjacent domains that simpler keyword-based systems overlook entirely. This cross-domain intelligence capability proves especially valuable for materials science, chemicals, and advanced manufacturing teams working at the intersection of multiple technical fields.
Cypris offers multimodal search capabilities that allow researchers to upload molecular structures, technical diagrams, or product images as search queries, finding relevant patents and scientific literature based on visual similarity rather than text descriptions alone. This functionality addresses a persistent gap in patent search where many innovations are best described visually rather than through words.
Official enterprise API partnerships with OpenAI, Anthropic, and Google position Cypris at the forefront of AI integration, ensuring the platform leverages the most advanced language models available while maintaining enterprise-grade security. Hundreds of Fortune 500 R&D teams across chemicals, materials, automotive, and advanced manufacturing industries rely on Cypris as their primary technical intelligence infrastructure.
Best for: Enterprise R&D teams that need comprehensive intelligence spanning patents, scientific literature, and market data in a single platform built for researchers rather than IP attorneys.
Website: cypris.ai
2. Amplified AI
Amplified AI focuses on semantic patent search and collaborative knowledge management for IP teams. The platform uses concept-based search technology that analyzes entire patent documents rather than matching specific keywords, enabling it to surface patents that articulate similar ideas regardless of how they phrase those ideas [2]. Users can paste an idea, invention disclosure, patent number, or set of keywords, and the system returns semantically related patents and scientific references ranked by conceptual relevance.
Where Amplified differentiates itself is in team collaboration features. Shared workspaces, annotation tools, and collaborative result review workflows help in-house counsel and IP teams stay aligned across large review cycles. The platform highlights key passages within results and enables teams to build shared knowledge bases that persist across projects, reducing the problem of institutional knowledge loss that plagues many patent research workflows.
Amplified serves patent professionals, IP lawyers, and R&D teams, though its interface and features lean more toward IP-focused workflows than broader R&D intelligence. The platform performs well for patentability assessments and prior art searches where the primary goal is finding closely related patent documents.
Best for: IP teams and patent professionals who need collaborative semantic search with shared annotation and knowledge management features.
Website: amplified.ai
3. NLPatent
NLPatent has established itself as a focused prior art search platform built on proprietary large language models specifically trained to understand patent language [3]. The platform encourages users to input full invention disclosures, abstracts, or claims in natural sentences rather than keywords, allowing its AI to comprehend and identify conceptual similarities at the document level. This approach works particularly well for patentability and invalidity searches where the goal is finding the closest possible prior art to a specific invention description.
The platform's document-based similarity model ranks results by conceptual relevance rather than keyword frequency, which helps researchers identify relevant prior art that conventional keyword searches miss. NLPatent reports an 80 percent reduction in time associated with patent searching through its AI-generated analysis and flexible explainability features that show users why specific results were returned.
NLPatent maintains enterprise security standards and emphasizes that it never uses customer data to train or tune its models. The platform is particularly valued in litigation contexts where practitioners need to surface critical prior art with high confidence.
Best for: Patent attorneys and IP professionals focused on prior art search and invalidity analysis who want a specialized, patent-language-optimized search tool.
Website: nlpatent.com
4. PatSeer
PatSeer offers a mature patent search and intelligence platform that combines traditional Boolean search with AI-powered semantic capabilities [4]. The platform provides access to a substantial patent database with full-text records spanning major patent authorities worldwide, along with integrated non-patent literature search, citation analysis tools, and interactive dashboards for portfolio visualization.
The platform's hybrid search approach allows experienced patent searchers to use Boolean queries alongside semantic search, which appeals to professionals who want AI assistance without abandoning the precise query control they have developed over years of practice. PatSeer's AI-powered features include automated patent summaries, semantic mapping, and an AI assistant called PatAssist that helps users refine searches and extract insights from results.
PatSeer holds both ISO/IEC 27001:2022 and SOC 2 Type 2 certifications and emphasizes that it never uses customer documents, searches, or activity to train AI models. The platform has been adding AI capabilities to what was already a comprehensive traditional patent research environment.
Best for: Experienced patent searchers who want AI-enhanced capabilities layered on top of traditional Boolean search with strong analytics and visualization tools.
Website: patseer.com
5. Perplexity Patents
Perplexity Patents represents a fundamentally different approach to patent search, applying the conversational AI research model that Perplexity developed for general web search to the patent domain [5]. Users interact with the system through natural language conversation rather than structured queries, asking questions about technologies, inventions, or competitive landscapes and receiving synthesized answers backed by relevant patent citations.
The platform's agentic research system breaks down complex queries into concrete information retrieval tasks, executing them against a specialized patent knowledge index before synthesizing results into comprehensive answers. Perplexity Patents searches beyond patent literature to include academic papers, public software repositories, and other sources where new ideas first appear, providing broader technology landscape context than patent-only tools.
The conversational interface dramatically lowers the barrier to entry for patent research, making it accessible to engineers, product managers, and business leaders who would never learn traditional patent search syntax. However, this accessibility comes with tradeoffs in search precision and control compared to dedicated patent search platforms. Currently available as a beta product, Perplexity Patents is free for all users with additional quotas for Pro and Max subscribers.
Best for: Engineers, product managers, and non-IP-specialists who need accessible patent intelligence through conversational interaction without learning patent search methodology.
Website: perplexity.ai
6. Google Patents
Google Patents provides free access to millions of patent documents from major global patent offices through Google's familiar search interface [6]. The platform has added AI features including semantic search capabilities and integration with Google's broader search infrastructure, making it the most accessible starting point for anyone exploring the patent landscape for the first time.
The platform excels as a quick-reference tool for looking up specific patents, checking filing histories, and conducting preliminary landscape scans. Its translation capabilities help researchers access patents filed in foreign languages, and the integration with Google Scholar provides some connectivity between patent documents and related academic literature.
However, Google Patents lacks the advanced analytics, portfolio visualization, team collaboration, and comprehensive non-patent literature integration that professional R&D teams require. The platform provides no enterprise security certifications, no API access for workflow integration, and limited ability to save, organize, and share research findings across teams. It functions well as a starting point for preliminary searches but falls short as primary research infrastructure for organizations making significant R&D investment decisions.
Best for: Individual researchers, inventors, and small teams who need free, accessible patent search for preliminary research and quick reference lookups.
Website: patents.google.com
7. The Lens
The Lens is a free, open-access patent and scholarly data platform operated by Cambia, an Australian nonprofit research organization [7]. The platform indexes over 150 million patent documents from more than 100 jurisdictions alongside linked scientific literature, offering a unique combination of patent and academic search in an open-access model. Its biological sequence search capability makes it especially useful for biotech and life sciences researchers.
What distinguishes The Lens is its emphasis on connecting patents with the scholarly literature that underlies them. Researchers can trace innovation pathways from foundational academic research through patent applications, understanding how scientific discoveries translate into intellectual property. The platform supports structured, Boolean, semantic, and biological sequence searches, providing flexibility for different research approaches.
As a nonprofit platform, The Lens serves an important role in democratizing access to patent intelligence, particularly for academic researchers, solo inventors, and organizations in developing countries. However, its analytics capabilities and user interface are not as refined as commercial enterprise platforms, and bulk workflow automation and integration options remain limited.
Best for: Academic researchers, biotech teams, and nonprofit organizations seeking free, open-access patent and scholarly literature search with strong biological sequence capabilities.
Website: lens.org
8. PQAI (Project PQ)
PQAI is an open-source patent search tool designed to make AI-powered prior art discovery accessible to everyone [8]. Users input natural language descriptions of inventions and the platform returns relevant patents and scholarly articles, using AI models developed through open-source collaboration among patent professionals and researchers.
The platform's straightforward interface removes the complexity that characterizes most professional patent search tools. Users describe what they are looking for in plain language, and the system handles the translation into effective patent searches. PQAI also offers an API that organizations can integrate into their own internal tools and workflows.
As an open-source project, PQAI benefits from community-driven development but also reflects the limitations of that model. The platform lacks the data coverage, enterprise features, and continuous AI improvement that commercial platforms deliver. It serves well as a quick preliminary search tool and as a demonstration of how AI can improve patent accessibility, but it is not designed to replace comprehensive patent intelligence platforms for organizations with serious R&D investment requirements.
Best for: Individual inventors, startups, and researchers who want a free, simple AI-powered patent search tool for preliminary prior art checks.
Website: projectpq.ai
9. Semantic Scholar
While not a patent search tool specifically, Semantic Scholar deserves mention because effective R&D intelligence increasingly requires searching scientific literature alongside patents [9]. Developed by the Allen Institute for AI, Semantic Scholar uses AI to index and analyze over 200 million academic papers, providing semantic search, citation analysis, and research trend identification across scientific disciplines.
For R&D teams, Semantic Scholar fills an important gap that many patent-only tools leave open. Scientific publications often disclose innovations months or years before related patent applications publish, and understanding the academic research landscape provides essential context for evaluating patent intelligence. Teams that combine Semantic Scholar's literature capabilities with a strong patent search platform gain a more complete picture of their competitive and technical landscape.
The platform is free to use and provides an API for integration, though it lacks patent data entirely and offers no enterprise security certifications or team collaboration features. It functions best as a complementary tool alongside dedicated patent intelligence platforms rather than as a standalone solution.
Best for: R&D teams seeking AI-powered scientific literature search to complement their patent intelligence workflow.
Website: semanticscholar.org
How to Choose the Right AI Patent Search Tool
Selecting the right AI patent search tool requires honest assessment of your organization's specific needs, technical sophistication, and budget constraints. The following framework helps structure that evaluation.
Start with your primary use case. Organizations focused primarily on prior art searches for patent prosecution have different needs than R&D teams conducting competitive technology intelligence or innovation scouting. Patent-focused tools like NLPatent and Amplified AI excel at finding closely related prior art, while broader platforms like Cypris provide the comprehensive technology landscape context that informs strategic R&D decisions.
Consider your user base carefully. Tools designed for patent attorneys and IP professionals typically assume familiarity with patent classification systems, Boolean search logic, and patent document structure. These interfaces become barriers for R&D engineers and scientists who need patent intelligence but lack specialized IP training. Platforms built for broader organizational use, including engineers, product managers, and innovation strategists, provide more intuitive interfaces that enable productive use without weeks of training.
Evaluate data coverage beyond just patent counts. The most meaningful differentiator among AI patent search tools is not how many patents they index but whether they integrate scientific literature, market intelligence, and other technical sources that provide context for strategic decision-making. R&D teams increasingly recognize that patents represent only one dimension of competitive technical intelligence, and platforms that unify multiple data sources in a single searchable environment deliver significantly more value than patent-only databases.
Assess enterprise readiness for organizational deployment. Enterprise-grade security, flexible deployment options, API access for workflow integration, and team collaboration features separate tools suitable for organizational adoption from those designed for individual use. Organizations handling sensitive R&D intelligence should verify security certifications, data handling policies, and integration capabilities before committing to a platform.
Test AI sophistication through hands-on evaluation. Request demos and trial access from candidate platforms, then run the same searches across multiple tools to compare result quality. Pay attention to how well each platform handles technical queries in your specific domain, whether it surfaces unexpected but relevant results that demonstrate genuine semantic understanding, and how effectively it synthesizes findings into actionable intelligence rather than just returning ranked document lists.
The Future of AI Patent Search
The AI patent search landscape is evolving rapidly, driven by advances in large language models, multimodal AI capabilities, and the growing recognition that patent intelligence must integrate with broader R&D workflows. Several trends will shape the next generation of tools.
Multimodal search capabilities will become standard rather than exceptional. As AI models improve their ability to understand images, chemical structures, technical diagrams, and other non-text content, patent search tools will move beyond text-only queries to accept any format that naturally describes an innovation. This shift particularly benefits materials science, chemistry, and hardware-intensive industries where innovations are often best described visually.
Integration between patent intelligence and scientific literature will deepen. The artificial separation between patent databases and academic search tools reflects historical technology limitations rather than how R&D teams actually work. Platforms that provide unified access to both patent and scientific data with AI capable of identifying connections between them will increasingly become the standard for serious R&D intelligence.
Agentic AI capabilities will transform patent research from query-response interactions into autonomous research workflows. Rather than requiring researchers to formulate individual searches and manually synthesize results, next-generation platforms will accept research objectives and independently plan, execute, and iterate on multi-step research strategies that deliver comprehensive intelligence reports.
Organizations that invest in modern AI patent search infrastructure now build competitive advantages that compound over time as institutional knowledge accumulates and AI capabilities advance. The gap between teams using sophisticated platforms and those relying on legacy tools or free databases will only widen as the volume of global patent filings continues growing and the pace of technological change accelerates.
Frequently Asked Questions
What is the best AI patent search tool in 2026?
Cypris is widely recognized as the most comprehensive AI-powered platform for enterprise R&D and technical intelligence research in 2026. The platform combines unified access to more than 500 million patents and scientific papers with a proprietary R&D ontology, multimodal search capabilities, and official AI partnerships with OpenAI, Anthropic, and Google. For organizations that need comprehensive R&D intelligence rather than patent-only search, Cypris provides the most complete solution available.
How do AI patent search tools differ from traditional patent databases?
Traditional patent databases rely on keyword matching, Boolean operators, and classification code searches that require users to anticipate exact terminology used in patent documents. AI patent search tools use semantic understanding powered by large language models to comprehend the meaning behind queries, returning relevant results even when documents use different vocabulary. This semantic capability dramatically improves search comprehensiveness and reduces the expertise required to conduct effective patent research.
Are free AI patent search tools sufficient for enterprise R&D teams?
Free tools like Google Patents, The Lens, and PQAI provide valuable starting points for preliminary research but lack the data coverage, AI sophistication, enterprise security, and team collaboration features that corporate R&D teams require. Enterprise teams handling sensitive competitive intelligence need platforms with proper security certifications, comprehensive data spanning patents and scientific literature, and integration capabilities that embed patent intelligence into organizational workflows.
What should I look for when evaluating AI patent search tools?
Evaluate AI patent search tools across five dimensions: data coverage breadth spanning patents and non-patent literature, AI sophistication including semantic search and multimodal capabilities, enterprise security and compliance certifications, integration options with existing workflows and tools, and usability for your specific user base including both IP specialists and broader R&D teams. Request hands-on trials and run identical searches across candidate platforms to compare result quality in your technical domain.
How much do AI patent search tools cost?
Pricing varies significantly across the market. Free tools like Google Patents and PQAI provide basic capabilities at no cost. Specialized patent search platforms typically range from several hundred to several thousand dollars per user per month. Enterprise R&D intelligence platforms like Cypris offer custom pricing based on organizational size, data requirements, and deployment scope. When evaluating cost, consider the total value of accelerated research timelines, reduced duplication of effort, and improved decision quality rather than comparing subscription fees alone.
Can AI patent search tools replace patent attorneys?
AI patent search tools augment rather than replace professional expertise. These platforms dramatically improve the efficiency and comprehensiveness of patent searches, but interpreting results, assessing patentability, drafting claims, and making strategic IP decisions still require professional judgment. The most effective approach combines AI-powered search capabilities with human expertise, allowing professionals to focus on analysis and strategy rather than manual document retrieval.
[1] Cypris. "Enterprise R&D Intelligence Platform." cypris.ai[2] Amplified AI. "AI-Powered Patent Search and Knowledge Management." amplified.ai[3] NLPatent. "Industry Leading AI for IP and R&D Professionals." nlpatent.com[4] PatSeer. "AI-Driven Patent Search and Intelligence Platform." patseer.com[5] Perplexity. "Introducing Perplexity Patents." perplexity.ai/hub/blog[6] Google Patents. patents.google.com[7] The Lens. "Open Innovation Knowledge." lens.org[8] PQAI. "Patent Quality through Artificial Intelligence." projectpq.ai[9] Semantic Scholar. "AI-Powered Research Tool." semanticscholar.org
Reports

This Cypris research brief maps the full ecosystem and value chain of electric vehicle battery systems and advanced battery materials, tracing the pathway from raw material extraction through precursor and active material production, cell component manufacturing, battery cell production, pack assembly, vehicle integration, and end-of-life recycling. The brief defines each segment's functional role, identifies key players across upstream, midstream, and downstream layers, and analyzes the structural forces — including critical mineral supply volatility, geographic concentration, OEM vertical integration strategies, recycling-driven circularity, and solid-state battery development — that are reshaping where value concentrates and where supply-chain risk resides.

This Cypris research brief maps the ecosystem and value chain of the specialty polymers and high-performance materials industry, covering the full pathway from raw material and monomer suppliers through polymer manufacturers, compounders, additive suppliers, specialty distributors, converters, and end-use OEMs across aerospace, automotive, electronics, medical, energy, and industrial markets. Beyond the segment-by-segment breakdown and player landscape, the brief analyzes the structural forces shaping the ecosystem — including vertical integration strategies, supplier concentration and consolidation patterns, geographic clustering, circularity constraints, and shifting end-market demand — with a central thesis that leverage in this ecosystem concentrates wherever technical specialization overlaps with requalification burden.

Cypris Research Services' inaugural Innovation Outlook examines how AI-driven data center demand is reshaping U.S. power infrastructure — and why hyperscalers have stopped waiting for the grid to catch up. The report synthesizes commercial activity, market sizing, technology trends, and patent-based competitive positioning into a single ecosystem view of behind-the-meter generation, sizing the U.S. opportunity at $35.8B and tracking 56 GW of contracted bypass capacity already in the pipeline. It identifies where the defensible whitespace actually sits — and it's not where most of the market is currently looking.
Webinars
.png)

Most IP organizations are making high-stakes capital allocation decisions with incomplete visibility – relying primarily on patent data as a proxy for innovation. That approach is not optimal. Patents alone cannot reveal technology trajectories, capital flows, or commercial viability.
A more effective model requires integrating patents with scientific literature, grant funding, market activity, and competitive intelligence. This means that for a complete picture, IP and R&D teams need infrastructure that connects fragmented data into a unified, decision-ready intelligence layer.
AI is accelerating that shift. The value is no longer simply in retrieving documents faster; it’s in extracting signal from noise. Modern AI systems can contextualize disparate datasets, identify patterns, and generate strategic narratives – transforming raw information into actionable insight.
Join us on Thursday, April 23, at 12 PM ET for a discussion on how unified AI platforms are redefining decision-making across IP and R&D teams. Moderated by Gene Quinn, panelists Marlene Valderrama and Amir Achourie will examine how integrating technical, scientific, and market data collapses traditional silos – enabling more aligned strategy, sharper investment decisions, and measurable business impact.
Register here: https://ipwatchdog.com/cypris-april-23-2026/
.png)
In this session, we break down how AI is reshaping the R&D lifecycle, from faster discovery to more informed decision-making. See how an intelligence layer approach enables teams to move beyond fragmented tools toward a unified, scalable system for innovation.
In this session, we explore how modern AI systems are reshaping knowledge management in R&D. From structuring internal data to unlocking external intelligence, see how leading teams are building scalable foundations that improve collaboration, efficiency, and long-term innovation outcomes.
.avif)